Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Parallelisierung und Scatter-Gather-Muster
Viele fortgeschrittene Denk- und Generierungsaufgaben — wie das Zusammenfassen großer Dokumente, die Bewertung mehrerer Lösungswege oder der Vergleich verschiedener Perspektiven — profitieren von der parallel Ausführung von Eingabeaufforderungen. Herkömmliche sequentielle Workflows reichen nicht aus, wenn Skalierbarkeit, Reaktionsfähigkeit und Fehlertoleranz erforderlich sind. Um dieses Problem zu lösen, kann die LLM-basierte Parallelisierung mithilfe eines ereignisgesteuerten Scatter-Gather-Musters neu konzipiert werden, bei dem Aufgaben dynamisch an autonome Agenten verteilt und die Ergebnisse intelligent synthetisiert werden.
Das folgende Diagramm ist ein Beispiel für einen LLM-Parallelisierungs-Workflow:
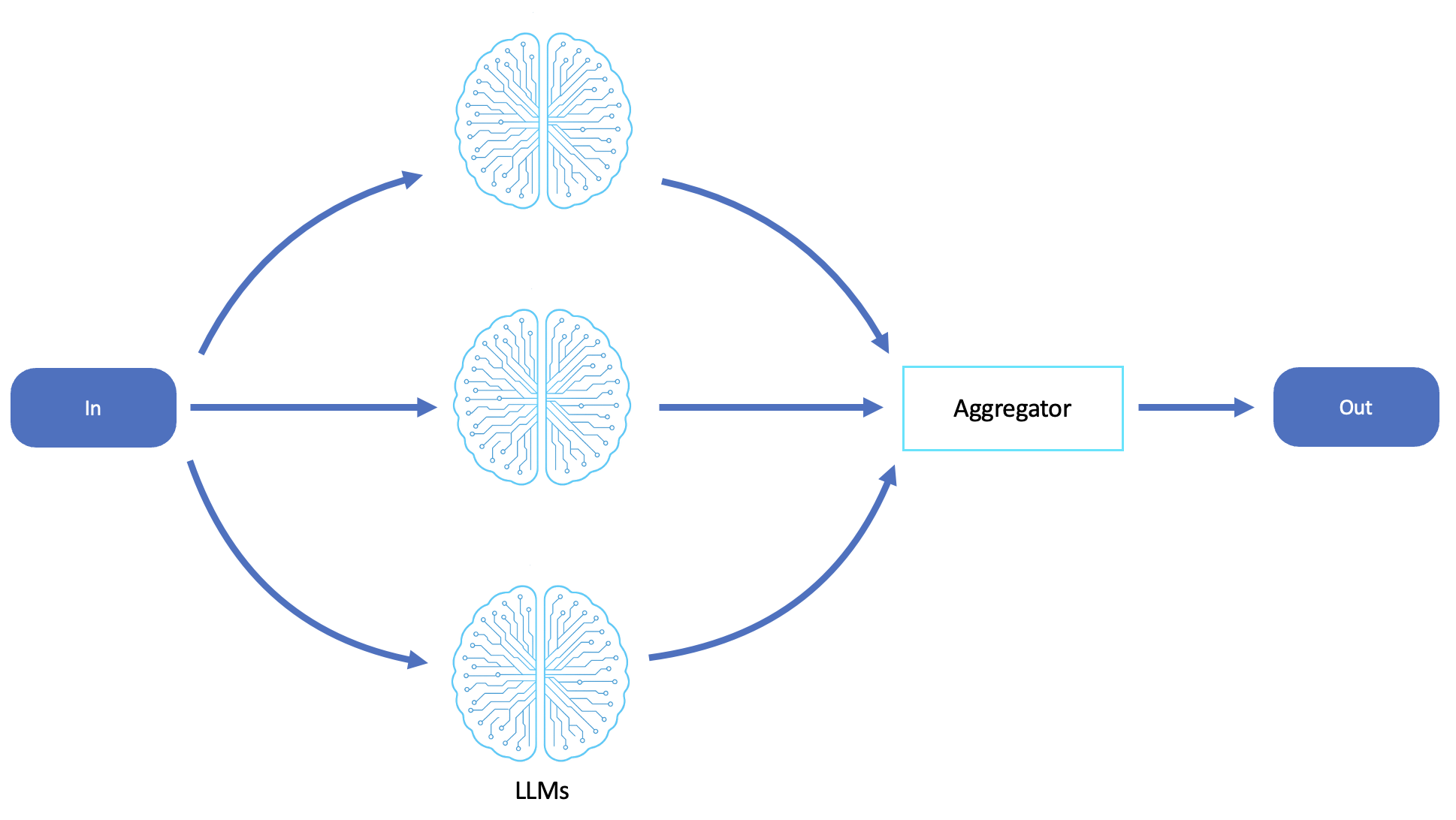
Verstreuen und sammeln
In verteilten Systemen sendet ein Scatter-Gather-Muster Aufgaben parallel an mehrere Dienste oder Verarbeitungseinheiten, wartet auf ihre Antworten und aggregiert dann die Ergebnisse zu einer konsolidierten Ausgabe. Im Gegensatz zu Fan-Out wird Scatter-Gathering koordiniert, weil es Antworten erwartet und in der Regel Logik anwendet, um Ergebnisse zu kombinieren, zu vergleichen und auszuwählen.
Zu den gängigen Implementierungen für Parallelisierung und Scatter-Gather gehören die folgenden:
-
AWS Step Functions einen Status für die parallel Aufgabenausführung zuordnen
-
AWS Lambda mit Parallelität, Koordination der Ergebnisse mehrerer aufgerufener Funktionen
-
Amazon EventBridge mit Korrelations IDs - und Aggregationsworkflows
-
Benutzerdefiniertes Controller-Muster zur Verwaltung von Fan-Outs und zur Erfassung von Ergebnissen mithilfe von Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB oder Warteschlangen
Das folgende Diagramm ist ein Beispiel für Scatter-Gather:
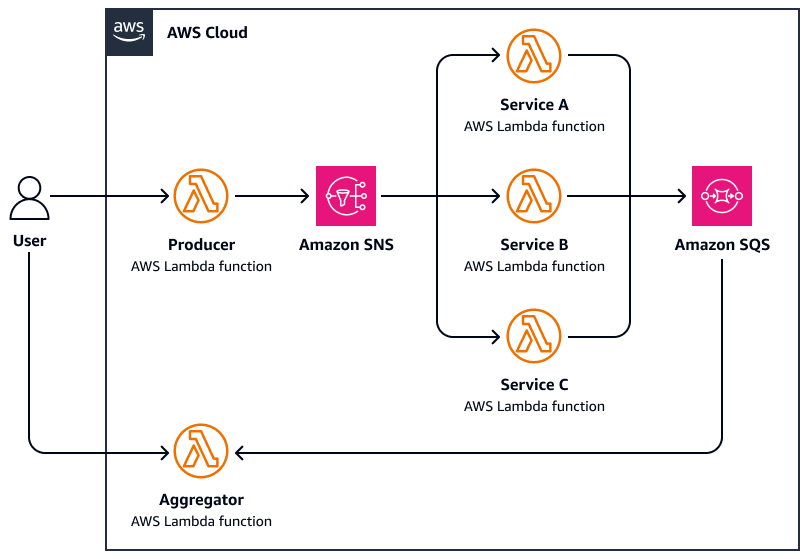
-
Ein Benutzer sendet eine Anfrage an eine zentrale Koordinatorfunktion, die die Aufgabe verteilt, indem sie parallel Nachrichten zu einem Amazon Simple Notification Service (Amazon SNS) -Thema veröffentlicht.
-
Jede Nachricht enthält Aufgabenmetadaten und wird an einen Facharbeiter weitergeleitet. AWS Lambda
-
Jeder Worker verarbeitet AWS Lambda unabhängig die ihm zugewiesene Unteraufgabe (z. B. das Abfragen einer externen API, das Verarbeiten eines Dokuments und das Analysieren von Daten).
-
Die Ergebnisse werden auf eine gemeinsame Speicherebene wie Amazon Simple Queue Service (Amazon SQS) geschrieben.
-
Die Aggregatorfunktion wartet, bis alle Antworten abgeschlossen sind, und führt dann Folgendes aus:
-
Sammelt und aggregiert die Ergebnisse (führt beispielsweise Zusammenfassungen zusammen und wählt die besten Treffer aus)
-
Sendet eine endgültige Antwort oder löst einen nachgelagerten Workflow aus
-
Zu den häufigsten Anwendungsfällen für Scatter-Gather-Muster gehören:
-
Föderierte Suche
-
Suchmaschinen für Preisvergleiche
-
Aggregierte Datenanalyse
-
Inferenz mit mehreren Modellen
LLM-basierte Parallelisierung (Scatter-Gather-Kognition)
In Agentensystemen spiegelt die Parallelisierung stark das Scatter-Gather-Verfahren wider, indem Teilaufgaben auf mehrere LLM-Aufrufe oder -Agenten verteilt werden, die jeweils unabhängig voneinander einen Teil des Problems lösen. Die zurückgegebenen Ergebnisse werden durch einen Aggregationsprozess gesammelt und synthetisiert, bei dem es sich häufig um einen anderen LLM- oder Controller-Agenten handelt.
Parallelisierung der Agenten
-
Ein Agent reicht die Anfrage „Zusammenfassung der Erkenntnisse aus diesen 10 Berichten“ ein.
-
Es verteilt die Berichte auf 10 parallel LLM-Zusammenfassungsaufgaben.
-
Wenn er alle Zusammenfassungen zurückgibt, geht der Agent wie folgt vor:
-
Fasst Zusammenfassungen zu einem einheitlichen Briefing zusammen
-
Identifiziert Themen oder Widersprüche
-
Sendet die synthetisierte Ausgabe an den Benutzer
-
Dieser agentische Workflow ermöglicht skalierbares, modulares und adaptives paralleles Denken. Dies ist ideal für Anwendungsfälle, die einen hohen kognitiven Durchsatz erfordern.
Das folgende Diagramm ist ein Beispiel für die Parallelisierung von Agenten:
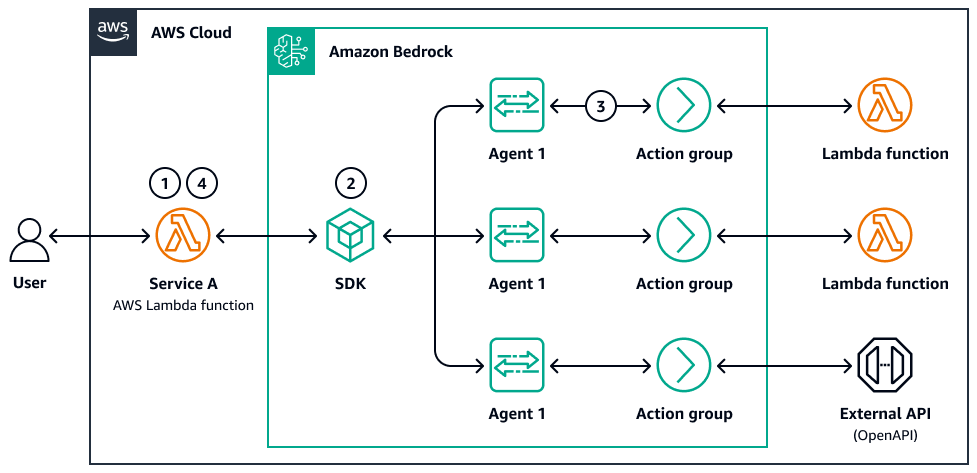
-
Ein Benutzer reicht eine mehrteilige Abfrage oder einen Dokumentensatz ein.
-
Eine Controller AWS Lambda - oder Schrittfunktion verteilt die Unteraufgaben. Jede Aufgabe ruft einen Amazon Bedrock LLM-Aufruf oder -Subagent mit eigener Aufforderung auf.
-
Wenn die Aufrufe und Unteraufgaben abgeschlossen sind, werden die Ergebnisse gespeichert (z. B. in Amazon S3 oder im Speicherspeicher), und ein Aggregationsschritt führt die Ausgaben zusammen, vergleicht oder filtert sie.
-
Das System sendet die endgültige Antwort an den Benutzer oder den nachgeschalteten Agenten zurück.
Dieses System verfügt über eine verteilte Argumentationsschleife mit Rückverfolgbarkeit, Fehlertoleranz und optionaler Ergebnisgewichtungs- oder Auswahllogik.
Imbissbuden
Die Agentenparallelisierung verwendet Scatter-Gather-Muster, um LLM-Aufgaben zu verteilen, was eine parallel Verarbeitung und eine intelligente Ergebnissynthese ermöglicht.
