Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Grundlagen der Argumentation
Ein Agent für grundlegendes Denken ist die einfachste Form der agentischen KI, die als Antwort auf eine Anfrage logische Folgerungen oder Entscheidungen trifft. Es akzeptiert Eingaben von Benutzern oder Systemen und verarbeitet Abfragen und generiert Antworten mithilfe strukturierter Eingabeaufforderungen.
Dieses Muster ist nützlich für Aufgaben, die eine einstufige Argumentation, Klassifizierung oder Zusammenfassung auf der Grundlage eines bestimmten Kontextes erfordern. Es verwendet keinen Arbeitsspeicher, keine Tools oder Statusverwaltung, wodurch es zustandslos, leichtgewichtig und in großen Workflows gut zusammensetzbar ist.
Architektur
In der folgenden Abbildung wird der Ablauf eines Argumentationsmittels dargestellt:
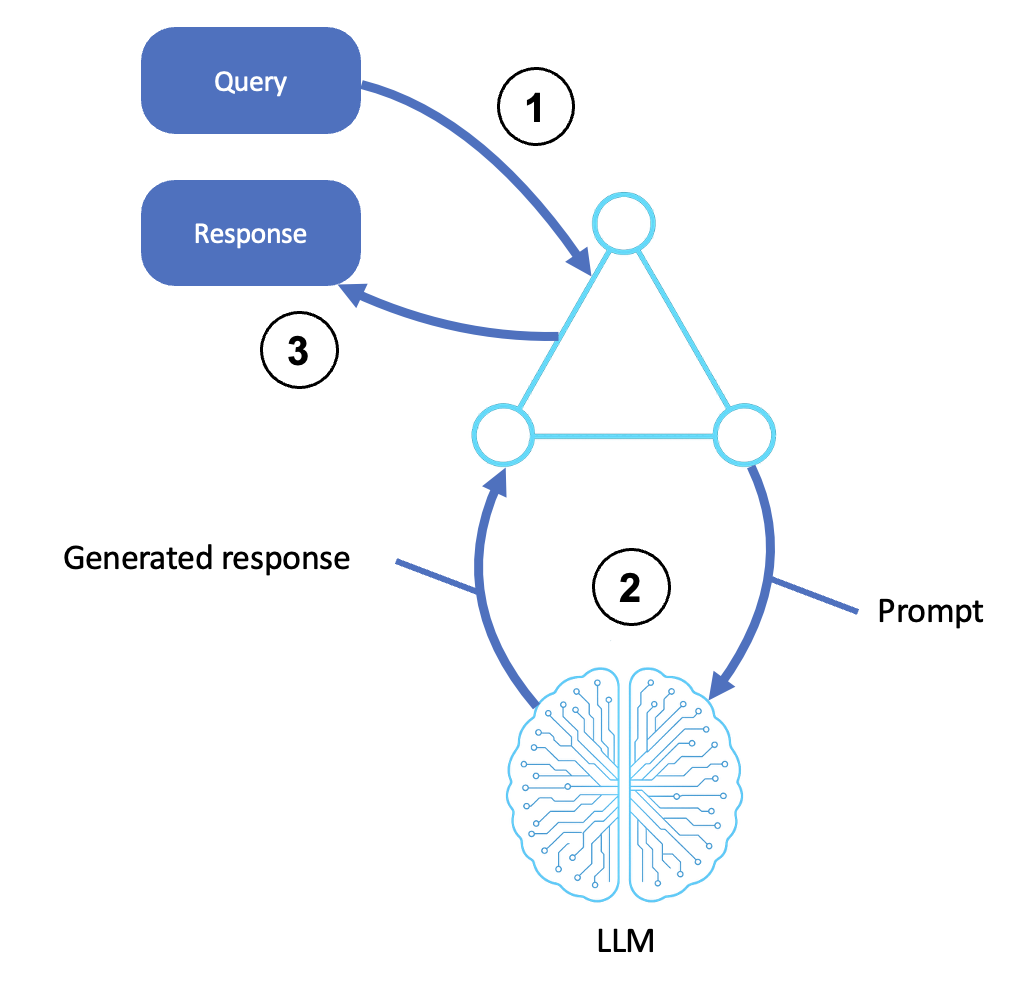
Description
-
Empfängt eine Eingabe
-
Ein Benutzer, ein System oder ein Upstream-Agent sendet eine Anfrage oder Anweisung.
-
Die Eingabe wird an die Agenten-Shell oder die Orchestrierungsebene übergeben.
-
Dieser Schritt umfasst die Vorverarbeitung, die Erstellung von Vorlagen für Eingabeaufforderungen und die Identifizierung der Ziele.
-
-
Ruft das LLM auf
-
Der Agent wandelt die Anfrage in eine strukturierte Aufforderung um und sendet sie an ein LLM (z. B. über Amazon Bedrock).
-
Das LLM generiert auf der Grundlage der Aufforderung eine Antwort, wobei vorab geschultes Wissen und Kontext verwendet werden.
-
Das generierte Ergebnis kann Argumentationsschritte (Gedankenkette), endgültige Antworten oder Ranglisten beinhalten.
-
-
Gibt eine Antwort zurück
-
Die generierte Ausgabe wird an die Schnittstelle des Agenten weitergeleitet.
-
Dies kann Formatierung, Nachbearbeitung oder eine API-Antwort beinhalten.
-
Capabilities
-
Unterstützt natürliche Sprache oder strukturierte Eingabe
-
Nutzt schnelle Technik, um das Verhalten zu steuern
-
Zustandslos und skalierbar
-
Kann in UI, CLI, APIs und Pipelines eingebettet werden
Einschränkungen
-
Kein Gedächtnis oder Geschichtsbewusstsein
-
Keine Interaktion mit externen Tools oder Datenquellen
-
Beschränkt auf das, was der LLM zum Zeitpunkt der Schlussfolgerung weiß
Häufige Anwendungsfälle
-
Konversationsfragen und Antworten
-
Erläuterungen und Zusammenfassungen der Richtlinien
-
Leitlinien für die Entscheidungsfindung
-
Leichte und automatisierte Chatbot-Abläufe
-
Klassifizierung, Kennzeichnung und Bewertung
Implementierungsleitfaden
Sie können die folgenden Tools und Dienste verwenden, um ein grundlegendes Argumentationsinstrument zu erstellen:
-
Amazon Bedrock für LLM-Aufrufe (Anthropic, AI21, Meta)
-
Amazon API Gateway oder AWS Lambda um es als zustandslosen Microservice verfügbar zu machen
-
Rufen Sie Vorlagen auf, die im Parameter Store, AWS Secrets Manager, oder als Code gespeichert sind
Zusammenfassung
Das grundlegende Argumentationsmittel ist aufgrund seiner einfachen Struktur von grundlegender Bedeutung. Es verfügt über Kernfunktionen, die Ziele in Argumentationswege umwandeln, die zu intelligenten Ergebnissen führen. Dieses Muster ist häufig der Ausgangspunkt für fortgeschrittene Muster, wie z. B. toolbasierte Agenten und Agenten, die Retrieval-Augmented Generation (RAG) verwenden. Es ist auch eine zuverlässige und modulare Komponente großer Workflows.
Agentin RAG
Retrieval-augmented Generierung (RAG) ist eine Technik, die das Abrufen von Informationen mit der Textgenerierung kombiniert, um genaue und kontextbezogene Antworten zu erhalten. RAG ermöglicht es Agenten, relevante externe Informationen abzurufen, bevor sie das LLM in Anspruch nehmen. Es erweitert das effektive Gedächtnis und die Argumentationsgenauigkeit eines Agenten, indem es seine Entscheidungen auf aktuelle, sachliche oder domänenspezifische Informationen stützt. Im Gegensatz zu staatenlosen LLMs, die sich ausschließlich auf vortrainierte Gewichte verlassen, verfügt RAG über eine externe Wissenssuchebene, die Eingabeaufforderungen dynamisch an den Kontext anpasst.
Architektur
Die Logik des RAG-Musters wird in der folgenden Abbildung veranschaulicht:
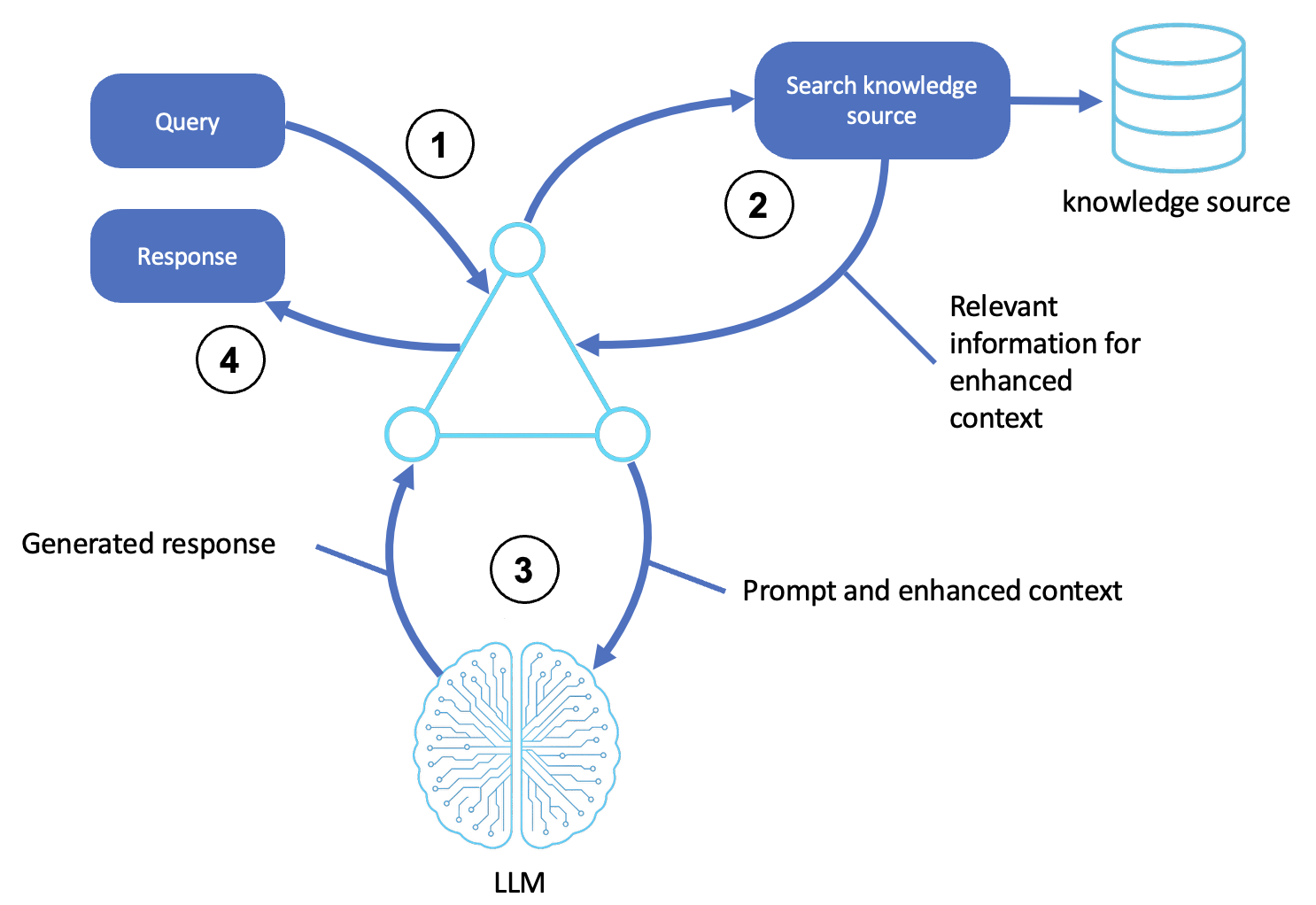
Description
-
Empfängt eine Anfrage
-
Ein Benutzer oder ein Upstream-System sendet eine Anfrage oder ein Ziel an den Agenten.
-
Die Agenten-Shell akzeptiert die Anfrage und formatiert sie als Aufforderung zur Begründung.
-
-
Durchsucht eine externe Quelle
-
Der Agent identifiziert Konzepte und Absichten anhand der Abfrage.
-
Er fragt mithilfe der semantischen Suche oder des Stichwortabgleichs eine Wissensquelle ab, z. B. einen Vektorspeicher, eine Datenbank oder einen Dokumentenindex.
-
Die relevantesten Passagen, Dokumente oder Entitäten werden zur Verwendung im nächsten Schritt abgerufen.
-
-
Generiert eine kontextuelle Antwort
-
Der Agent erweitert die Eingabeaufforderung um die abgerufenen Informationen und bildet so eine kontexterweiterte Eingabe für das LLM.
-
Das LLM verarbeitet alle Eingaben mithilfe von generativem Denken (z. B. Gedankenkette oder Reflexion), um eine genaue Antwort zu erhalten.
-
-
Gibt die endgültige Ausgabe zurück
-
Der Agent bereitet die Ausgabe vor, indem er sie in alle Kommunikationskopfzeilen oder erforderlichen Formatierungen verpackt und sie dann an den Benutzer oder das aufrufende System zurückgibt.
-
(Optional) Die abgerufenen Dokumente und die LLM-Ausgabe können protokolliert, bewertet und für future Abfragen im Speicher gespeichert werden.
-
Capabilities
-
Fact-grounded Ausgabe auch in Long-Tail- oder unternehmensspezifischen Domänen
-
Speichererweiterung ohne Feinabstimmung des Modells
-
Dynamischer Kontext, der auf jeder Abfrage und jedem Benutzerstatus basiert
-
Vollständig kompatibel mit Vektordatenbanken, semantischen Indizes und Metadatenfilterung
Häufige Anwendungsfälle
-
Wissensassistenten für Unternehmen
-
Bots zur Einhaltung gesetzlicher Vorschriften
-
Copiloten für den Kundensupport
-
Search-enhanced Chatbots
-
Agenten für die Dokumentation für Entwickler
Implementierungsleitfaden
Verwenden Sie die folgenden Tools und Dienste, um einen Agenten zu erstellen, der RAG verwendet:
-
Amazon Bedrock für LLM-Aufruf
-
Amazon Kendra oder Amazon Aurora für Dokumentation oder strukturierte Datensuche OpenSearch
-
Amazon Simple Storage Service (Amazon S3) für die Aufbewahrung von Dokumenten
-
AWS Lambda um Suche, Eingabeaufforderung und LLM-Inferenz zu orchestrieren
-
Knowledge-based Integrationen mit Agenten (mithilfe von Speicher-Plugins, semantischen Retrievern oder Amazon Bedrock)
Zusammenfassung
Agent RAG verbindet statisches Modelldenken mit dynamischer Intelligenz aus der realen Welt. Es gibt Agenten die Möglichkeit, nachzuschlagen, was sie nicht wissen, Antworten aus abgerufenem Wissen zu synthetisieren und zuverlässige, überprüfbare Antworten zu erstellen.
RAG-Muster sind eine Grundlage für die Entwicklung intelligenter Agenten, die den Wissenszugang ohne Umschulung skalieren können. Es ist oft ein Vorläufer für komplexere Orchestrierungsmuster, die den Einsatz von Tools, die Planung und das Langzeitgedächtnis beinhalten.
