Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Daten mithilfe von Amazon OpenSearch Ingestion in eine Domain aufnehmen
Dieses Tutorial zeigt Ihnen, wie Sie Amazon OpenSearch Ingestion verwenden, um eine einfache Pipeline zu konfigurieren und Daten in eine Amazon OpenSearch Service-Domain aufzunehmen. Eine Pipeline ist eine Ressource, die OpenSearch Ingestion bereitstellt und verwaltet. Sie können eine Pipeline verwenden, um Daten für nachgelagerte Analysen und Visualisierungen in OpenSearch Service zu filtern, anzureichern, zu transformieren, zu normalisieren und zu aggregieren.
Dieses Tutorial führt Sie durch die grundlegenden Schritte, um eine Pipeline schnell zum Laufen zu bringen. Umfassendere Anweisungen finden Sie unterPipelines erstellen.
In diesem Tutorial führen Sie die folgenden Schritte durch:
Im Rahmen des Tutorials erstellen Sie die folgenden Ressourcen:
-
Eine Domäne mit dem Namen
ingestion-domain, in die die Pipeline schreibt -
Eine Pipeline mit dem Namen
ingestion-pipeline
Erforderliche Berechtigungen
Um dieses Tutorial abschließen zu können, muss Ihrem Benutzer oder Ihrer Rolle eine identitätsbasierte Richtlinie mit den folgenden Mindestberechtigungen angehängt sein. Diese Berechtigungen ermöglichen es Ihnen, eine Pipeline-Rolle zu erstellen und eine Richtlinie anzuhängen (iam:Create*undiam:Attach*), eine Domäne (es:*) zu erstellen oder zu ändern und mit Pipelines zu arbeiten (). osis:*
Schritt 1: Erstellen Sie die Pipeline-Rolle
Erstellen Sie zunächst eine Rolle, die die Pipeline für den Zugriff auf die OpenSearch Service-Domänensenke übernimmt. Sie werden diese Rolle später in diesem Tutorial in die Pipeline-Konfiguration aufnehmen.
Um die Pipeline-Rolle zu erstellen
-
Öffnen Sie die AWS Identity and Access Management Konsole unter https://console.aws.amazon.com/iamv2/
. -
Wählen Sie Richtlinien und dann Richtlinie erstellen aus.
-
In diesem Tutorial werden Sie Daten in eine Domain mit dem Namen aufnehmen
ingestion-domain, die Sie im nächsten Schritt erstellen werden. Wählen Sie JSON aus und fügen Sie die folgende Richtlinie in den Editor ein.your-account-idWenn Sie Daten in eine bestehende Domain schreiben möchten,
ingestion-domainersetzen Sie sie durch den Namen Ihrer Domain.Anmerkung
Der Einfachheit halber verwenden wir in diesem Tutorial eine umfassende Zugriffsrichtlinie. In Produktionsumgebungen empfehlen wir jedoch, dass Sie eine restriktivere Zugriffsrichtlinie auf Ihre Pipeline-Rolle anwenden. Ein Beispiel für eine Richtlinie, die die erforderlichen Mindestberechtigungen bereitstellt, finden Sie unterAmazon OpenSearch Ingestion-Pipelines Zugriff auf Domains gewähren.
-
Wählen Sie Weiter, dann Weiter und geben Sie Ihrer Richtlinie einen Namen für Pipeline-Policy.
-
Wählen Sie Richtlinie erstellen aus.
-
Erstellen Sie als Nächstes eine Rolle und fügen Sie ihr die Richtlinie hinzu. Wählen Sie Roles (Rollen) und anschließend Create role (Rolle erstellen).
-
Wählen Sie Benutzerdefinierte Vertrauensrichtlinie und fügen Sie die folgende Richtlinie in den Editor ein:
-
Wählen Sie Weiter aus. Suchen Sie dann nach der Pipeline-Richtlinie (die Sie gerade erstellt haben) und wählen Sie sie aus.
-
Wählen Sie Weiter und geben Sie der Rolle einen Namen. PipelineRole
-
Wählen Sie Rolle erstellen aus.
Merken Sie sich den Amazon-Ressourcennamen (ARN) der Rolle (z. B.arn:aws:iam::). Sie benötigen ihn, wenn Sie Ihre Pipeline erstellen.your-account-id:role/PipelineRole
Schritt 2: Erstellen Sie eine Domain
Erstellen Sie zunächst eine Domain mit dem Nameningestion-domain, in die Daten aufgenommen werden sollen.
Navigieren Sie zu https://console.aws.amazon.com/aos/Hause
-
Läuft OpenSearch 1.0 oder höher oder Elasticsearch 7.4 oder höher
-
Verwendet öffentlichen Zugriff
-
Verwendet keine differenzierte Zugriffskontrolle
Anmerkung
Diese Anforderungen sollen die Einfachheit dieses Tutorials gewährleisten. In Produktionsumgebungen können Sie eine Domain mit VPC-Zugriff and/or mithilfe einer fein abgestuften Zugriffskontrolle konfigurieren. Informationen zur Verwendung einer differenzierten Zugriffskontrolle finden Sie unter Zuordnen der Pipeline-Rolle.
Die Domäne muss über eine Zugriffsrichtlinie verfügen, die Berechtigungen für die OpenSearchIngestion-PipelineRole IAM-Rolle gewährt. Diese wird vom OpenSearch Dienst im nächsten Schritt für Sie erstellt. Die Pipeline übernimmt diese Rolle, um Daten an die Domänensenke zu senden.
Stellen Sie sicher, dass die Domäne über die folgende Zugriffsrichtlinie auf Domänenebene verfügt, die der Pipeline-Rolle Zugriff auf die Domäne gewährt. Ersetzen Sie die Region und die Konto-ID durch Ihre eigene:
Weitere Informationen zum Erstellen von Zugriffsrichtlinien auf Domänenebene finden Sie unter. Ressourcenbasierte Richtlinien
Wenn Sie bereits eine Domäne erstellt haben, ändern Sie deren bestehende Zugriffsrichtlinie, um die oben genannten Berechtigungen für bereitzustellen. OpenSearchIngestion-PipelineRole
Schritt 3: Erstellen Sie eine Pipeline
Jetzt, da Sie eine Domain haben, können Sie eine Pipeline erstellen.
So erstellen Sie eine Pipeline
-
Wählen Sie in der Amazon OpenSearch Service-Konsole im linken Navigationsbereich Pipelines aus.
-
Wählen Sie Create pipeline (Pipeline erstellen) aus.
-
Wählen Sie die Leere Pipeline und dann Blueprint auswählen aus.
-
In diesem Tutorial erstellen wir eine einfache Pipeline, die das HTTP-Quell-Plugin
verwendet. Das Plugin akzeptiert Protokolldaten in einem JSON-Array-Format. Wir geben eine einzelne OpenSearch Service-Domain als Senke an und nehmen alle Daten in den application_logsIndex auf.Wählen Sie im Menü Quelle die Option HTTP aus. Geben Sie für den Pfad /logs ein.
-
Der Einfachheit halber konfigurieren wir in diesem Tutorial den öffentlichen Zugriff für die Pipeline. Wählen Sie für Quellnetzwerkoptionen die Option Öffentlicher Zugriff aus. Informationen zur Konfiguration des VPC-Zugriffs finden Sie unterKonfiguration des VPC-Zugriffs für Amazon OpenSearch Ingestion-Pipelines.
-
Wählen Sie Weiter aus.
-
Geben Sie als Prozessor Datum ein und wählen Sie Hinzufügen aus.
-
Aktivieren Sie „Ab dem Zeitpunkt des Eingangs“. Behalten Sie für alle anderen Einstellungen die Standardwerte bei.
-
Wählen Sie Weiter aus.
-
Konfigurieren Sie die Senkendetails. Wählen Sie als OpenSearch Ressourcentyp Managed Cluster aus. Wählen Sie dann die OpenSearch Dienstdomäne aus, die Sie im vorherigen Abschnitt erstellt haben.
Geben Sie als Indexname application_logs ein. OpenSearch Ingestion erstellt diesen Index automatisch in der Domain, falls er noch nicht existiert.
-
Wählen Sie Weiter aus.
-
Geben Sie der Pipeline den Namen Ingestion-Pipeline. Behalten Sie die Standardeinstellungen für die Kapazitätseinstellungen bei.
-
Wählen Sie für Pipeline-Rolle die Option Neue Servicerolle erstellen und verwenden aus. Die Pipeline-Rolle stellt die erforderlichen Berechtigungen für eine Pipeline bereit, um in die Domänensenke zu schreiben und aus Pull-basierten Quellen zu lesen. Wenn Sie diese Option auswählen, ermöglichen Sie OpenSearch Ingestion, die Rolle für Sie zu erstellen, anstatt sie manuell in IAM zu erstellen. Weitere Informationen finden Sie unter Rollen und Benutzer in Amazon OpenSearch Ingestion einrichten.
-
Geben Sie als Suffix für den Namen der Servicerolle den Wert ein. PipelineRole In IAM wird die Rolle das Format haben.
arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole -
Wählen Sie Weiter aus. Überprüfen Sie Ihre Pipeline-Konfiguration und wählen Sie Pipeline erstellen aus. Es dauert 5—10 Minuten, bis die Pipeline aktiv wird.
Schritt 4: Nehmen Sie einige Beispieldaten auf
Wenn der Pipeline-Status lautetActive, können Sie damit beginnen, Daten in die Pipeline aufzunehmen. Sie müssen alle HTTP-Anfragen an die Pipeline mit Signature Version 4 signieren. Verwenden Sie ein HTTP-Tool wie Postman
Anmerkung
Der Principal, der die Anfrage signiert, muss über die IAM-Berechtigung verfügen. osis:Ingest
Rufen Sie zunächst die Aufnahme-URL von der Seite mit den Pipeline-Einstellungen ab:
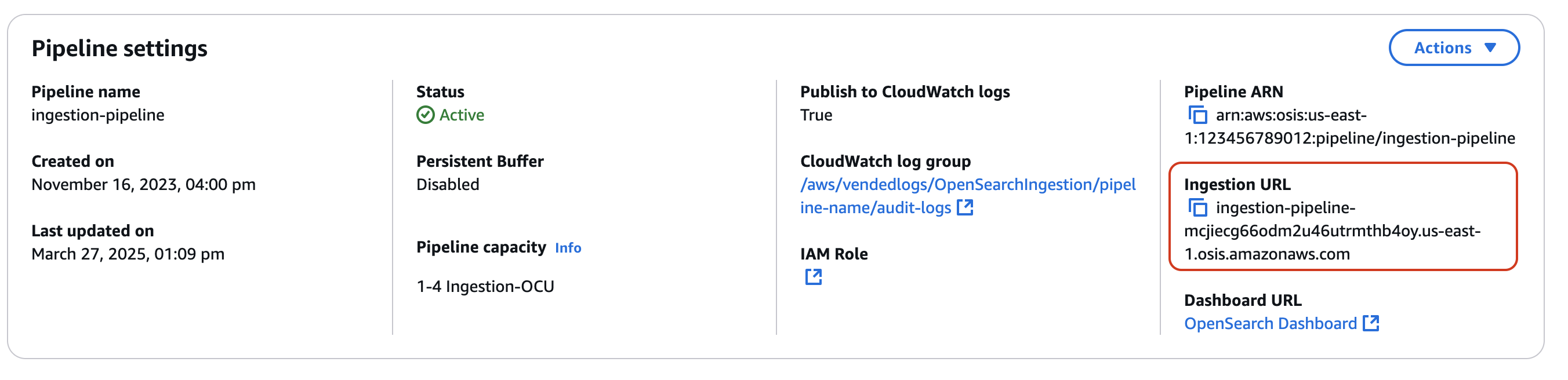
Nehmen Sie dann einige Beispieldaten auf. Die folgende Anfrage verwendet awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Sie sollten eine 200 OK Antwort sehen. Wenn Sie einen Authentifizierungsfehler erhalten, liegt das möglicherweise daran, dass Sie Daten von einem anderen Konto als dem der Pipeline aufnehmen. Siehe Behebung von Problemen mit Berechtigungen.
Fragen Sie nun den application_logs Index ab, um sicherzustellen, dass Ihr Protokolleintrag erfolgreich aufgenommen wurde:
awscurl --service es --regionus-east-1\ -X GET \ https://search-ingestion-domain.us-east-1.es.amazonaws.com/application_logs/_search | json_pp
Beispielantwort:
{ "took":984, "timed_out":false, "_shards":{ "total":1, "successful":5, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"application_logs", "_type":"_doc", "_id":"z6VY_IMBRpceX-DU6V4O", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2022-10-21T21:00:25.502Z" } } ] } }
Behebung von Problemen mit Berechtigungen
Wenn Sie die Schritte im Tutorial befolgt haben und immer noch Authentifizierungsfehler auftreten, wenn Sie versuchen, Daten aufzunehmen, liegt das möglicherweise daran, dass sich die Rolle, die in eine Pipeline schreibt, in einer anderen Rolle befindet AWS-Konto als die Pipeline selbst. In diesem Fall müssen Sie eine Rolle erstellen und übernehmen, die Ihnen speziell das Ingestieren von Daten ermöglicht. Detaillierte Anweisungen finden Sie unter Bereitstellung von kontenübergreifendem Zugriff auf Datenerfassung.
Zugehörige Ressourcen
In diesem Tutorial wurde ein einfacher Anwendungsfall für die Aufnahme eines einzelnen Dokuments über HTTP vorgestellt. In Produktionsszenarien konfigurieren Sie Ihre Client-Anwendungen (wie Fluent Bit, Kubernetes oder OpenTelemetry Collector) so, dass Daten an eine oder mehrere Pipelines gesendet werden. Ihre Pipelines werden wahrscheinlich komplexer sein als das einfache Beispiel in diesem Tutorial.
Informationen zu den ersten Schritten zur Konfiguration Ihrer Clients und zur Datenaufnahme finden Sie in den folgenden Ressourcen:
