Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entdecke Spuren
Die Seite „Discover Traces“ bietet eine spezielle Oberfläche für die Untersuchung verteilter Trace-Daten in Ihrem OpenSearch Service-Observability-Workspace. Sie können RED-Metriken (Rate, Fehlerrate, Dauer) für Ihre Services einsehen, Trace-Spans mit facettierter Filterung durchsuchen und einzelne Spans und Traces detailliert untersuchen, um Leistungsprobleme zu diagnostizieren. Die Seite unterstützt auch die Korrelation von Traces mit zugehörigen Protokolldaten.
So greifen Sie auf die Traces-Seite zu
Erweitern Sie in Ihrem Observability-Workspace in der linken Navigationsleiste die Option Discover und wählen Sie Traces aus.

Konfiguration von Trace-Datensätzen
Bevor Sie Trace-Daten untersuchen können, müssen Sie einen Traces-Datensatz konfigurieren. Sie können einen Datensatz automatisch oder manuell erstellen.
Automatische Datensatzerstellung
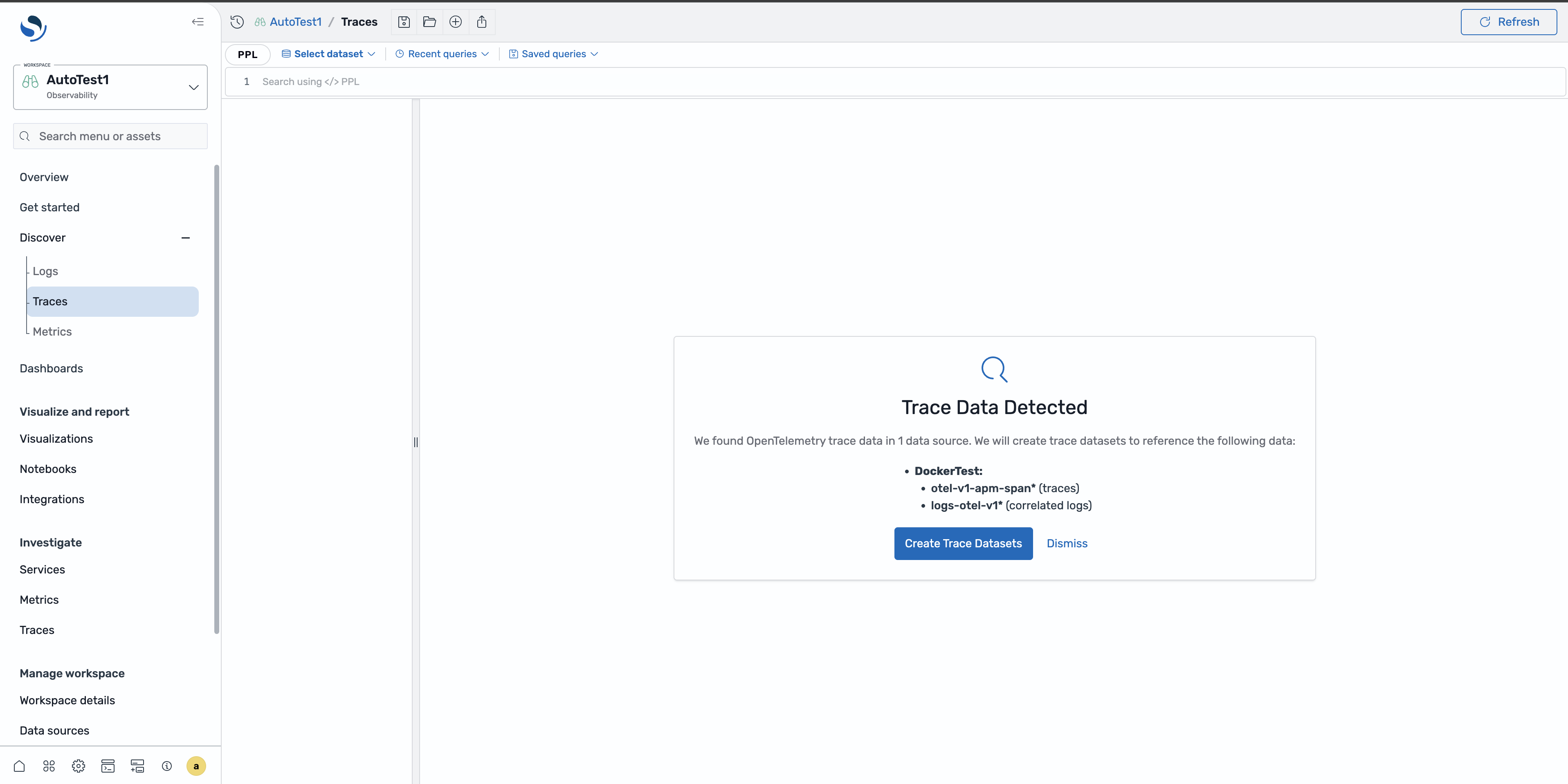
Wenn Sie zum ersten Mal zur Seite „Traces entdecken“ navigieren und in Ihrer Domain Trace-Daten vorhanden sind, werden Sie auf der Seite aufgefordert, automatisch einen Datensatz zu erstellen. Wählen Sie Datensatz erstellen, um die Standardkonfiguration zu akzeptieren.
Manuelle Datensatzerstellung
Um einen Traces-Datensatz manuell zu erstellen, folgen Sie den Schritten unterUm einen Traces-Datensatz zu erstellen. Bei der manuellen Erstellung haben Sie die Kontrolle über das Indexmuster, das Zeitstempelfeld und den Datensatznamen.
Spurendaten untersuchen
Die Seite Discover Traces enthält die folgenden Komponenten für die Untersuchung Ihrer Trace-Daten.
-
RED-Metriken — Anzeigerate (Anfragen pro Sekunde), Fehlerrate (Prozentsatz fehlgeschlagener Anfragen) und Dauer (Latenzperzentile) für den ausgewählten Datensatz. Diese Metriken werden basierend auf Ihrem Zeitfilter aktualisiert.
-
Facettierte Felder — Filtern Sie Trace-Spans nach Dienstname, Vorgang, Statuscode und anderen Span-Attributen. Wählen Sie Werte im Bereich „Facettenfelder“ aus, um Ihre Ergebnisse einzugrenzen.
-
Span-Tabelle — Durchsuchen Sie einzelne Bereiche mit Spalten für Trace-ID, Span-ID, Dienstname, Vorgang, Dauer und Status. Sie können nach einer beliebigen Spalte sortieren und die Zeilen erweitern, um die Span-Details zu sehen.
Einen bestimmten Zeitraum anzeigen
Um Details für einen bestimmten Bereich anzuzeigen, wählen Sie die Span-Zeile in der Span-Tabelle aus. Ein Flyout-Fenster mit den Span-Attributen, Ressourcenattributen und Ereignisinformationen wird geöffnet.

Seite mit den Trace-Details
Um den vollständigen Trace anzuzeigen, wählen Sie den Trace-ID-Link in der Span-Tabelle oder im Flyout-Fenster aus. Auf der Trace-Detailseite wird ein Wasserfalldiagramm angezeigt, das alle Spans in der Trace, ihre zeitlichen Beziehungen und die gesamte Trace-Dauer zeigt. Sie können einzelne Bereiche erweitern, um ihre Attribute anzuzeigen und Engpässe zu identifizieren.

Korrelation von Traces mit Protokollen
Wenn Sie eine Korrelation zwischen einem Traces-Datensatz und einem Logs-Datensatz konfigurieren, können Sie zugehörige Log-Einträge direkt auf der Seite „Traces entdecken“ anzeigen. Hinweise zum Erstellen von Korrelationen finden Sie unterKorrelationen.
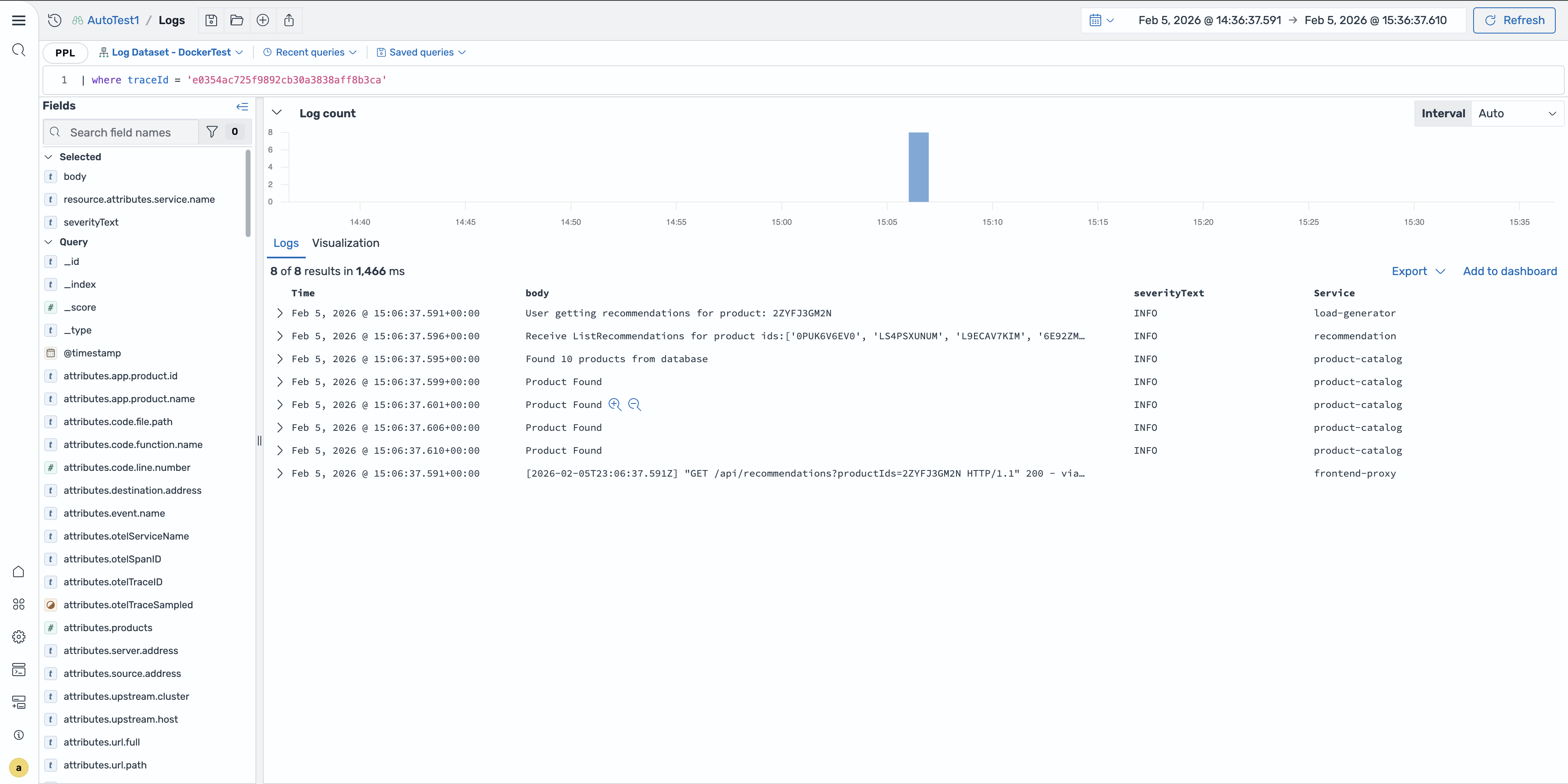
Verwandte Protokolle anzeigen
Wählen Sie im Flyout mit den Span-Details oder auf der Trace-Detailseite die Registerkarte Verwandte Logs aus, um Logeinträge anzuzeigen, die der Trace-ID, dem Servicenamen und dem Zeitraum des Spans entsprechen. Diese Korrelation hilft Ihnen zu verstehen, was während der Span-Ausführung in Ihrer Anwendung passiert ist.

Protokollumleitung mit Kontext
Sie können von einem Trace-Bereich direkt zur Seite Discover Logs navigieren, wobei der entsprechende Kontext erhalten bleibt. Wählen Sie im Bereich „Verwandte Logs“ die Option „In Logs anzeigen“, um die Seite „Discover Logs“ zu öffnen, auf der die Abfrage bereits ausgefüllt ist und nach der Trace-ID und dem Zeitraum des Spans gefiltert wird.
Abfragen von Ablaufverfolgungen mithilfe von PPL
Sie können PPL verwenden, um Trace-Daten direkt abzufragen. PPL verkettet Befehle mithilfe des Pipe-Zeichens, um Span-Daten zu filtern, zu transformieren und zu aggregieren.
Im folgenden Beispiel werden die 10 langsamsten Traces gefunden:
source = otel-v1-apm-span-* | where durationInNanos > 5000000000 | fields traceId, serviceName, name, durationInNanos | sort - durationInNanos | head 10
Im folgenden Beispiel werden Fehler nach Service gezählt:
source = otel-v1-apm-span-* | where status.code = 2 | stats count() as errorCount by serviceName | sort - errorCount
Im folgenden Beispiel werden Traces für einen bestimmten Dienst gefunden:
source = otel-v1-apm-span-* | where serviceName = 'checkout-service' | where parentSpanId = '' | sort - startTime | head 20
