Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Prompt-Ansätze zum visuellen Verständnis
Anmerkung
Diese Dokumentation bezieht sich auf Amazon Nova Version 1. Informationen dazu, wie Sie in Amazon Nova 2 zu multimodalem Verständnis beitragen können, finden Sie unter Multimodale Eingaben veranlassen.
Die folgenden Ansätze helfen Ihnen dabei, bessere Prompts für Amazon Nova zu erstellen.
Auf die Platzierung kommt es an
Wir empfehlen Ihnen, Mediendateien (wie Bilder oder Videos) vor dem Hinzufügen von Dokumenten zu platzieren, gefolgt von Ihrem Anleitungstext oder Ihren Prompts, um das Modell anzuleiten. Bilder, die nach dem Text platziert oder von Text durchsetzt sind, funktionieren zwar immer noch ausreichend, wenn es der Anwendungsfall zulässt, ist jedoch die Struktur {media_file}–then–{text} der bevorzugte Ansatz.
Die folgende Vorlage kann verwendet werden, um Mediendateien bei der visuellen Erfassung vor Text zu platzieren.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
Keine Struktur befolgt |
Optimierter Prompt |
|
|---|---|---|
Benutzer |
Erkläre, was in dem Bild [Image1.png] passiert. |
[Image1.png] Erkläre, was passiert in dem Bild? |
Mehrere Mediendateien mit Bildverarbeitungskomponenten
In Fällen, in denen Sie mehrere Mediendateien pro Runde bereitstellen, versehen Sie bitte jedes Bild mit einer nummerierten Beschriftung. Wenn Sie beispielsweise zwei Bilder verwenden, beschriften Sie sie mit Image
1: und Image 2:. Wenn Sie drei Videos verwenden, beschriften Sie sie mit Video
1:, Video 2: und Video 3:. Sie benötigen keine Zeilenumbrüche zwischen Bildern oder zwischen Bildern und dem Prompt.
Die folgende Vorlage kann verwendet werden, um mehrere Mediendateien zu platzieren:
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
Nicht optimierter Prompt |
Optimierter Prompt |
|---|---|
|
Beschreibe, was du auf dem zweiten Bild siehst. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] Beschreibe, was du auf dem zweiten Bild siehst. |
|
Ist das zweite Bild im beigefügten Dokument beschrieben? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] Ist das zweite Bild im beigefügten Dokument beschrieben? |
Aufgrund der umfangreichen Kontexttoken der Mediendateitypen kann es vorkommen, dass der zu Beginn des Prompts angegebene System-Prompt in bestimmten Fällen nicht berücksichtigt wird. In diesem Fall empfehlen wir Ihnen, alle Systemanweisungen in Benutzerrunden zu verschieben und die allgemeine Richtlinie {media_file}-dann-{text} zu befolgen. Dies hat keine Auswirkungen auf das System-Prompting mit RAG, Agenten oder die Toolnutzung.
Verwenden Sie Benutzeranweisungen, um die Befolgung von Anweisungen für visuelle Verständnisaufgaben zu verbessern.
Für das Verständnis von Videos ist die Anzahl der Token im Kontext für die Empfehlungen in Auf die Platzierung kommt es an von großer Bedeutung. Verwenden Sie den System-Prompt für allgemeinere Dinge wie Ton und Stil. Wir empfehlen, die Videoanweisungen als Teil des Benutzer-Prompts beizubehalten, um die Leistung zu verbessern.
Die folgende Vorlage kann für verbesserte Anweisungen verwendet werden:
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
Genau wie bei Text empfehlen wir, Bilder und Videos zu chain-of-thought beantragen, um bessere Leistungen zu erzielen. Wir haben außerdem empfohlen, die chain-of-thought Anweisungen in der Systemaufforderung zu platzieren und andere Anweisungen in der Benutzereingabeaufforderung beizubehalten.
Wichtig
Das Modell Amazon Nova Premier ist ein Modell mit höherer Intelligenz aus der Amazon-Nova-Familie, das komplexere Aufgaben bewältigen kann. Wenn Ihre Aufgaben fortgeschrittenes chain-of-thought Denken erfordern, empfehlen wir Ihnen, die unter Geben Sie Amazon Nova Zeit zum Nachdenken (chain-of-thought) bereitgestellte Vorlage für Eingabeaufforderungen zu verwenden. Dieser Ansatz kann dazu beitragen, die Analytik- und Problemlösungsfähigkeiten des Modells zu verbessern.
Few-Shot-Beispiele
Genau wie bei Textmodellen empfehlen wir, dass Sie Beispiele für Bilder angeben, um das Verständnis von Bildern zu verbessern (Beispiele für Videos können aufgrund der single-video-per-inference Einschränkungen nicht bereitgestellt werden). Es wird empfohlen, die Beispiele im Benutzer-Prompt nach der Mediendatei zu platzieren, anstatt sie im System-Prompt bereitzustellen.
| 0-Schuss | 2-Schuss | |
|---|---|---|
| Benutzer | [Bild 1] | |
| Assistent | Die Beschreibung von Bild 1 | |
| Benutzer | [Bild 2] | |
| Assistent | Die Beschreibung von Bild 2 | |
| Benutzer | [Image 3] Erkläre, was auf dem Bild passiert |
[Image 3] Erkläre, was auf dem Bild passiert |
Begrenzungsrahmenerkennung
Wenn Sie die Koordinaten der Begrenzungsrahmen für ein Objekt ermitteln müssen, können Sie das Amazon-Nova-Modell verwenden, um Begrenzungsrahmen auf einer Skala von [0, 1 000) auszugeben. Nachdem Sie diese Koordinaten erhalten haben, können Sie sie als Nachbearbeitungsschritt auf der Grundlage der Bildabmessungen skalieren. Ausführlichere Informationen zur Durchführung dieses Nachbearbeitungsschritts finden Sie im Handbuch bildbasiertes Grounding mit Amazon Nova
Im Folgenden finden Sie einen Beispiel-Prompt für die Erkennung von Begrenzungsrahmen:
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
Reichhaltigere Ausgaben oder Stil
Die Ausgabe zum Verstehen von Videos kann sehr kurz sein. Wenn Sie längere Ausgaben wünschen, empfehlen wir, eine Persona für das Modell zu erstellen. Sie können diese Persona anweisen, auf die von Ihnen gewünschte Weise zu antworten, ähnlich wie bei der Verwendung der Systemrolle.
Weitere Änderungen der Antworten können mit One-Shot- und Few-Shot-Techniken erreicht werden. Geben Sie Beispiele dafür, wie eine gute Antwort aussehen sollte, und das Modell kann Aspekte davon nachahmen und gleichzeitig Antworten generieren.
Dokumentinhalte in Markdown extrahieren
Amazon Nova Premier verfügt über verbesserte Funktionen zum Verstehen von in Dokumenten eingebetteten Diagrammen und ist in der Lage, Inhalte aus komplexen Bereichen wie wissenschaftlichen Arbeiten zu lesen und zu verstehen. Außerdem bietet Amazon Nova Premier eine verbesserte Leistung beim Extrahieren von Dokumentinhalten und kann diese Informationen in den Formaten Markdown-Tabelle und Latex ausgeben.
Das folgende Beispiel enthält eine Tabelle in einem Bild sowie einen Prompt für Amazon Nova Premier, den Inhalt des Bildes in eine Markdown-Tabelle zu konvertieren. Nachdem die Markdown-Tabelle (oder Latex Representation) erstellt wurde, können Sie Tools verwenden, um den Inhalt in JSON oder eine andere strukturierte Ausgabe zu konvertieren.
Make a table representation in Markdown of the image provided.
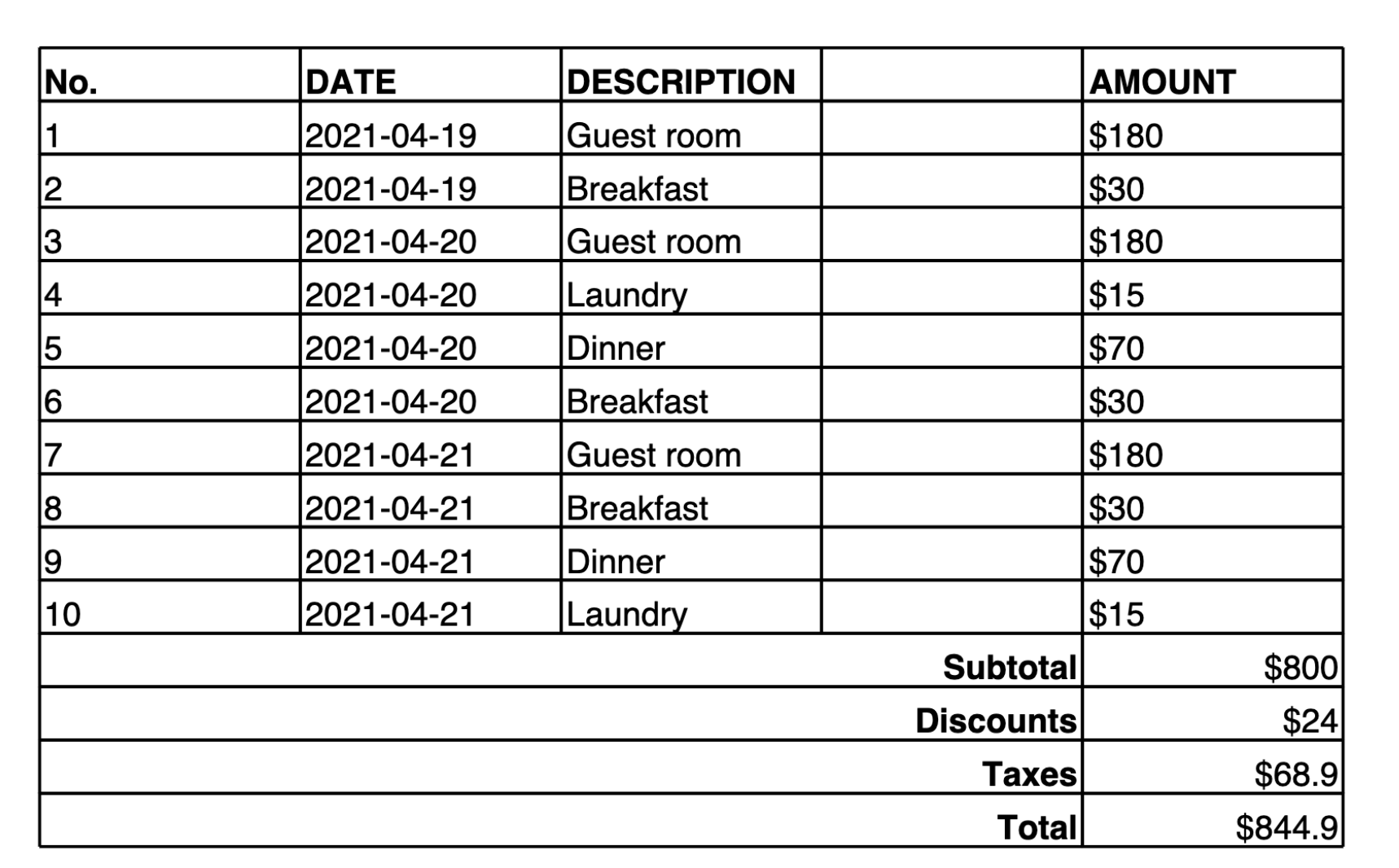
Hier ist die Ausgabe, die das Modell liefert:
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
Diese Ausgabe verwendet eine benutzerdefinierte Tabellennotation, wobei sie || als Spaltentrennzeichen und && als Zeilentrennzeichen verwendet.
Einstellungen von Inferenzparametern für das visuelle Verständnis
Für Anwendungsfälle im Bereich Bildverarbeitung empfehlen wir, mit den Inferenzparametern temperature, eingestellt auf 0, und topK, eingestellt auf 1 zu beginnen. Nachdem Sie die Ausgabe des Modells beobachtet haben, können Sie die Inferenzparameter dann je nach Anwendungsfall anpassen. Diese Werte hängen in der Regel von der Aufgabe und der benötigten Varianz ab. Erhöhen Sie die Temperatureinstellung, um mehr Variationen in den Antworten zu erzielen.
Videoklassifizierung
Um Videoinhalte effektiv in geeignete Kategorien zu sortieren, geben Sie Kategorien an, die das Modell zur Klassifizierung verwenden kann. Beachten Sie den folgenden Beispiel-Prompt:
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
Videos taggen
Amazon Nova Premier bietet verbesserte Funktionen zum Erstellen von Video-Tags. Die besten Ergebnisse erzielen Sie, wenn Sie die folgende Anweisung verwenden, um durch Kommas getrennte Tags anzufordern: „Verwende Kommas, um die einzelnen Tags zu trennen“. Hier ist ein Beispiel-Prompt:
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
Umfassende Untertitelung von Videos
Amazon Nova Premier bietet erweiterte Funktionen zur Bereitstellung von detaillierten Untertiteln – ausführliche Textbeschreibungen, die für mehrere Segmente innerhalb des Videos generiert werden. Hier ist ein Beispiel-Prompt:
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
