Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Planung der Notfallwiederherstellung
Disaster Recovery (DR) ist ein wichtiger Service für die Geschäftskontinuität und Einhaltung von Vorschriften in Unternehmen. AMS arbeitet mit Ihnen zusammen, um Sie bei der Planung, Implementierung und Wartung Ihrer DR-Strategie auf AMS zu unterstützen.
Die AMS-Landezone (LZ) mit mehreren Konten und Einzelkonten bietet native Multi-AZ-Hochverfügbarkeit für AMS-Infrastrukturkomponenten, die den meisten Katastrophenschutzszenarien gerecht werden. Je nach geografischer Abdeckung Ihres Unternehmens benötigen Sie jedoch möglicherweise regionalen Schutz. Für regionsübergreifende Verfügbarkeit und DR ist ein weiteres AMS-Konto in einer anderen Region erforderlich (dies gilt sowohl für die landing zone mit mehreren Konten als auch für die landing zone mit einem Konto).
AMS orientiert sich an den DR-Richtlinien von AWS, wie in diesem Blog Rapidly Recovery mission-Critical Systems in a Disaster
Mehrere Standorte (oder hochverfügbar)
Warmer Bereitschaftsmodus
Pilotlicht
Backup und Backup
Diese Optionen und deren AMS-Unterstützung werden in den folgenden Abschnitten beschrieben.
Multi-site oder hochverfügbar (HA)
Die HA-Lösung wird in der Regel durch die integrierten Funktionen der Anwendung bereitgestellt, z. B. Clustering oder synchrone Replikation. Benutzer werden sowohl zu Prod als auch zu Nodes weitergeleitet. HA/DR DNS verweist entweder direkt oder über einen Elastic Load Balancer (ELB) auf die Knoten.
Ihr AMS Cloud Architect (CA) wird im Rahmen Ihrer Well-Architected-Review und der DR-Planung mit Ihnen zusammenarbeiten.
HA DR nutzt anwendungs- und AWS systemeigene Dienste und Funktionen, wie in der folgenden Grafik dargestellt:
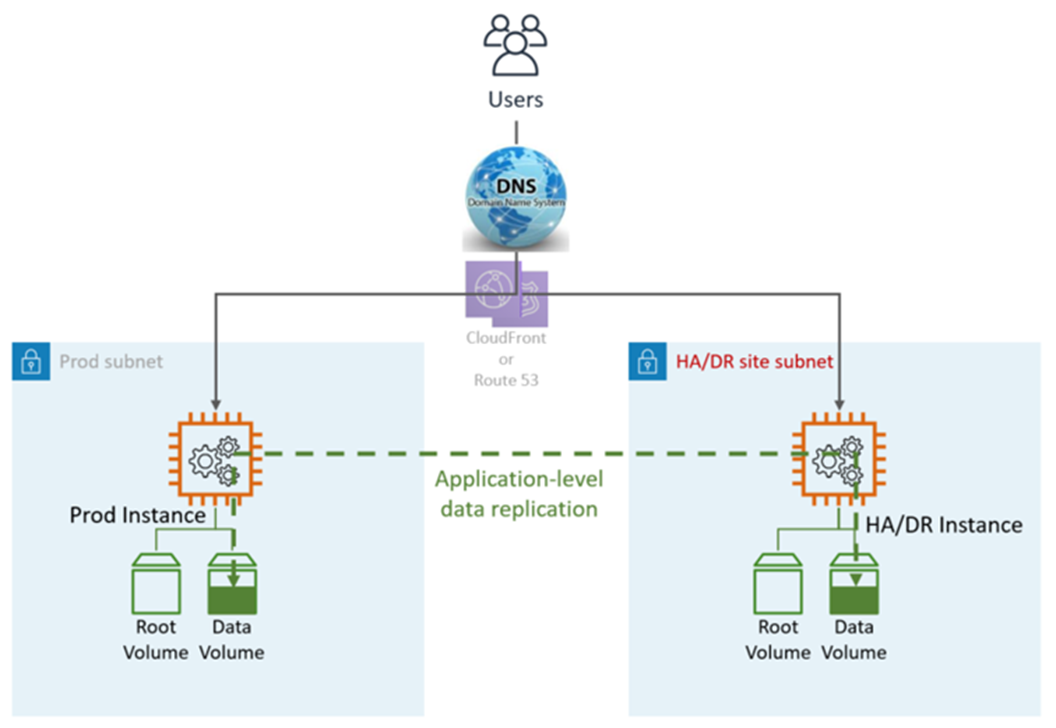
Der DR-Site kann sich am selben oder einem anderen AWS-Region Standort befinden.
Anmerkung
In einer anderen Region (Cross-Region) wird es eine andere Active Directory-Umgebung geben.
DR-Schritte (Failover): Automatischer Failover, es sind keine manuellen Schritte erforderlich. Im Falle eines Fehlers in der primären LZ werden die Benutzer automatisch zum Knoten umgeleitet. DR/HA Dies wird sowohl durch die DNS- als auch durch die Anwendungskonfiguration erreicht.
HA DR-Metriken:
Recovery Point Objective (RPO): <5 Minuten
Wiederherstellungszeitziel und (RTO): <5 Minuten
Wartungsaufwand: Hoch (In beiden Umgebungen sind synchrone Änderungen erforderlich, z. B. Anwendungskonfiguration, Patching, SG oder ALB, Zertifikate usw.).
Kosten: Hoch
Warmer Bereitschaftsmodus
Der Begriff „Warm-Standby“ wird verwendet, um ein Disaster-Recovery-Szenario (DR) zu beschreiben, bei dem eine verkleinerte Version der Umgebung in der Cloud ausgeführt wird.
Die Datenreplikation erfolgt über die Anwendungsebene, in der Regel asynchron, auf eine Online-Instanz, während die übrigen Instanzen (z. B. Anwendungs- und Webebene) möglicherweise ausgeschaltet werden, um Kosten zu sparen. Benutzer werden nur zur Produktionsseite weitergeleitet. Andere AWS Ressourcen wie Elastic Load Balancer (ELB) können ebenfalls vorab am DR-Standort bereitgestellt werden.
Ihr AMS Cloud Architect (CA) wird im Rahmen Ihrer Well-Architected-Review und der DR-Planung mit Ihnen zusammenarbeiten.
Warm Standby DR nutzt anwendungs- und AWS systemeigene Dienste und Funktionen, wie in der folgenden Grafik dargestellt:
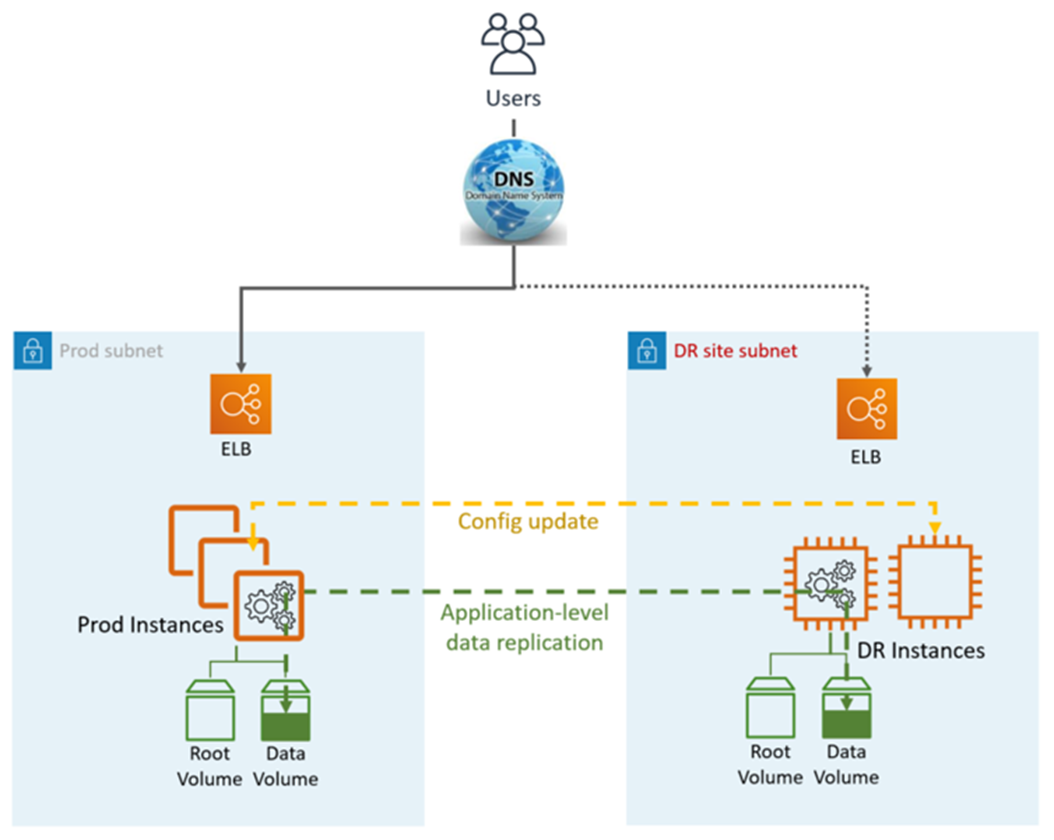
Der DR-Standort kann sich auf demselben oder einem anderen Standort befinden. AWS-Region
Anmerkung
In einer anderen Region (Cross-Region) wird es eine andere Active Directory-Umgebung geben.
DR (Failover) -Schritte:
Unterbrechen Sie die Datenreplikation und machen Sie die Dateninstanz am DR-Standort zum Master
Aktualisieren Sie die Anwendungskonfiguration nach Bedarf (neue IP, Servername usw.)
Leiten Sie DNS zur DR-Site (ELB) um
AD-Abhängigkeiten, falls erforderlich (Dienstkonten, SPNs, GPOs usw.)
HA DR-Metriken:
Recovery Point Objective (RPO): <1 Stunde
Recovery Time Objective und (RTO): <1 Stunde (abhängig von der Anzahl der Instanzen und der Orchestrierung)
Wartungsaufwand: Hoch (In beiden Umgebungen sind synchrone Änderungen erforderlich, z. B. Anwendungskonfiguration, Patching, Sicherheitsgruppen (SG) oder Application Load Balancer (ALB), Zertifikate usw.).
Kosten: Mittel
Pilot light
Bei diesem Disaster Recovery-Ansatz (DR) replizieren Sie einen Teil Ihrer Prod-Umgebung für eine begrenzte Anzahl von Kerndiensten. Ein kleiner Teil Ihrer Infrastruktur läuft ständig und synchronisiert gleichzeitig veränderbare Daten (wie Datenbanken oder Dokumente), während andere Teile Ihrer Infrastruktur ausgeschaltet sind und nur während Tests verwendet werden. Im Gegensatz zu einem Backup- und Recovery-Ansatz müssen Sie sicherstellen, dass Ihre wichtigsten Kernelemente bereits konfiguriert sind und in der DR-Landezone (der Kontrolllampe) ausgeführt werden.
Ihr AMS Cloud Architect wird im Rahmen Ihrer Well-Architected-Review und der DR-Planung mit Ihnen zusammenarbeiten.
Pilot Light DR nutzt anwendungs- und AWS systemeigene Dienste und Funktionen, wie in der folgenden Grafik dargestellt:
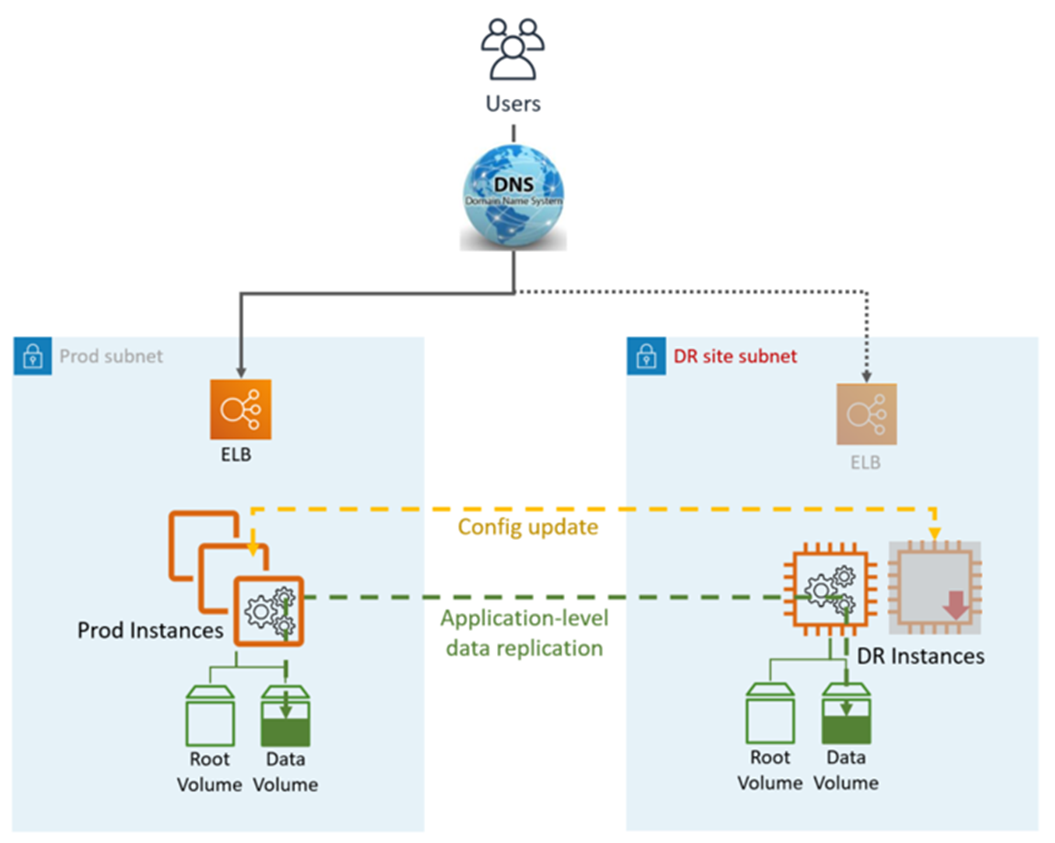
Der DR-Standort kann sich auf demselben oder einem anderen Standort befinden. AWS-Region
Anmerkung
In einer anderen Region (Cross-Region) wird es eine andere Active Directory-Umgebung geben.
DR (Failover) -Schritte:
Unterbrechen Sie die Datenreplikation und machen Sie die Dateninstanz am DR-Standort zum Master
Starten Sie die ausgeschalteten Instanzen und die Infrastruktur
Aktualisieren Sie die Anwendungskonfiguration nach Bedarf (neue IP, Servername usw.)
Fügen Sie die Instanzen nach Bedarf zum ELB hinzu
Leiten Sie DNS zur DR-Site (ELB) um
AD-Abhängigkeiten, falls erforderlich (Dienstkonten, SPNs, GPOs usw.)
DR-Metriken von Pilot Light:
Recovery Point Objective (RPO): <1 Stunde
Recovery Time Objective und (RTO): ~1 Stunde (abhängig von der Anzahl der Instanzen und der Orchestrierung)
Wartung: Mittel
Kosten: Mittel
Backup und Wiederherstellung
Dieser einfache und kostengünstige Disaster Recovery (DR) -Ansatz sichert Ihre Daten und Anwendungen von überall in der DR-Landing landing zone, um sie bei der Wiederherstellung nach einem Notfall zu verwenden.
Ihr AMS Cloud Architect arbeitet im Rahmen Ihrer Backup- und DR-Planung mit Ihnen zusammen.
Backup and Restore DR verwendet automatisierte Tools und Prozesse von AMS, wie in der folgenden Grafik dargestellt:
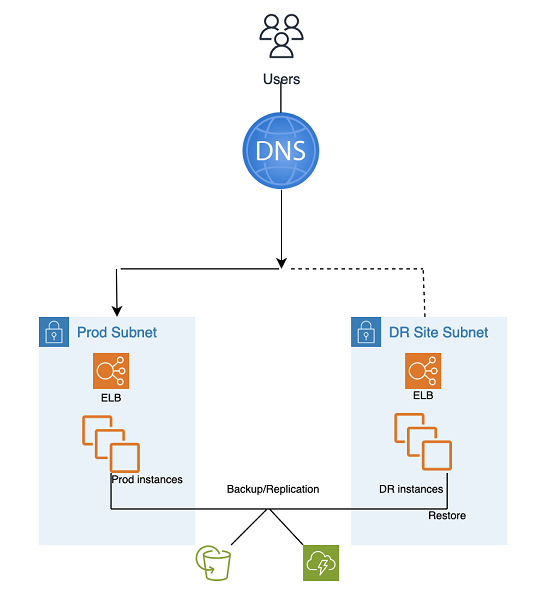
Zwei Sicherungs- und Replikationsmethoden können verwendet werden:
EBS-Snapshot (Recovery Point Objective (RPO) > 1 Stunde), auch bekannt als „EBS“
AWS Elastic Disaster Recovery (Recovery Point Objective (RPO) ~ 0,25 Stunden), auch bekannt als „DRS“
Die DR-Site kann sich in derselben oder in einer anderen befinden. AWS-Region
Anmerkung
Eine andere Region (Cross-Region) hat eine andere Active Directory-Umgebung.
DR (Failover) -Schritte:
Stellen Sie die Instanzen aus Snapshots wieder her (zweistufiger Vorgang, wobei zuerst die Platzhalterinstanz verwendet wird)
Aktualisieren Sie die Anwendungskonfiguration (neue IP, Servername usw.)
Richten Sie nach Bedarf eine andere Infrastruktur ein (SG, ELB usw.)
Leiten Sie DNS zur DR-Site (ELB) um
Aktualisieren oder stellen Sie bei Bedarf AD-Abhängigkeiten wieder her (Dienstkonten, Dienstprinzipalnamen (SPNs), Gruppenrichtlinienobjekte (GPOs) usw.)
DR-Metriken für Backup und Wiederherstellung:
Recovery Point Objective (RPO): > 1 Stunde oder ~0,25 Stunden (abhängig von der ausgewählten Lösung — EBS oder DRE)
Recovery Time Objective und (RTO): ~1 Stunde (abhängig von der Anzahl der Instanzen und der Orchestrierung)
Wartungsaufwand: Hoch (In beiden Umgebungen sind synchrone Änderungen erforderlich, z. B. Anwendungskonfiguration, Patching, Sicherheitsgruppen oder Anwendungs-Loadbalancer, Zertifikate usw.
Kosten: Mittel
Katastrophenschutz für EC2 mit EBS-Snapshots auf AMS
Voraussetzungen:
AMS Prod Landezone (Quelle)
AMS DR-Landezone (DR-Ziel)
EBS-Snapshots sind für EC2-Instances aktiviert ()AWS Backup
Lösung für die Snapshot-Replikation:
Cross AZ: Nicht zutreffend — EBS-Snapshots sind standardmäßig innerhalb der Region hochverfügbar
Cross-Region: AWS Backup
Das folgende Diagramm stellt den EC2-Wiederherstellungsprozess von EBS-Snapshots auf AMS dar:
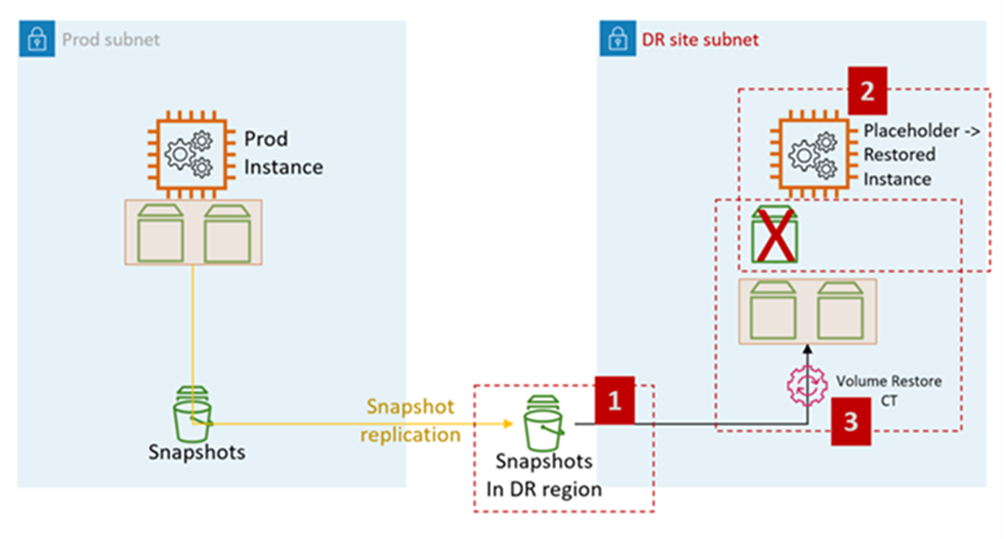
EC2-DR-Schritte auf AMS:
Rufen Sie einen RFC auf, um die EBS-Snapshots mit dem Zielkonto zu teilen (für DR erforderlich). Cross-Region
: Verwaltung, Erweiterte Stack-Komponenten, EBS-Snapshot, Teilen
Erstellen Sie einen Platzhalter-EC2-AMS-Stack im Zielsubnetz (DR-Site-Subnetz). Es wird empfohlen, den Stack mithilfe von CFN-Ingestion zu erstellen, da der Kunde die Schritte der Zuweisung von Sicherheitsgruppen und anderen (wie dem Hinzufügen der Instance zu einem ELB) im selben Stack kombinieren kann.
Typ ändern: Bereitstellung, Aufnahme, Stapel aus Vorlage, Erstellen CloudFormation
Rufen Sie einen RFC auf, um die Wiederherstellung des EC2-Stack-Volumes durchzuführen.
Typ ändern: Management, Advanced Stack Components, EC2-Instance-Stack, Volumes wiederherstellen.
Das CT stellt die Volumes aus den in Schritt 1 geteilten Snapshots wieder her und fügt sie der in Schritt 2 erstellten Platzhalterinstanz hinzu.
CT-Funktionalität zur Volumenwiederherstellung:
Fahren Sie die Platzhalterinstanz herunter
Stellen Sie Volumes aus den Snapshots wieder her
Tauschen Sie die Volumes aus
Starten Sie die Instanz
Verlasse die alte Domain
Ändern des Hostnamens
Starten Sie neu. AMS-Bootstrap-Skripte verbinden die Instance beim Start mit der Zieldomäne (DR)
CT-Eingabe für die Wiederherstellung des Volumens:
InstanceId (Platzhalter-Instanz-ID)
RootDeviceSnapshotId, der EBS-Snapshot für das wiederhergestellte Root-Volume
KMSKeyId, die KMS-Schlüssel-ID (ARN), um alle wiederhergestellten Volumes auf der EC2-Instance zu verschlüsseln
DeviceNames, bis zu 25 (optional)
SnapshotIds, bis zu 25 (optional). Liste der Snapshots der wiederherzustellenden Volumes
Notfallschutz für EC2 mit Elastic Disaster Recovery auf AMS
Voraussetzungen:
AMS Prod Landing Zone (Quelle)
AMS DR-Landezone (DR-Ziel)
Sie müssen zuerst den Elastic Disaster Recovery Service für alle Anwendungen initialisieren AWS-Regionen , in denen Sie ihn verwenden möchten.
Erstellen Sie eine IAM-Rolle in Ihrer DR landing zone (LZ) für den Zugriff auf die Elastic Disaster Recovery-Konsole.
Wichtig: Ein SSM-Dokument wird als Aktion nach dem Start innerhalb von DRS erstellt. Diese Aktion muss auf all Ihren Servern in den PostLaunch Einstellungen aktiviert sein.
Die Zielinstanz (Platzhalter) muss einen Tag-Schlüssel haben: „AWSDRS“, Wert: "“. AllowLaunchingIntoThisInstance Die Platzhalterinstanz muss sich im Status „Gestoppt“ befinden. Andernfalls kann AMS die Platzhalter-Instance nicht unter den Starteinstellungen auswählen und Elastic Disaster Recovery kann die Wiederherstellung nicht auf der Platzhalter-Instance durchführen.
Ein Diagramm des Einrichtungs- und Wiederherstellungsprozesses von Elastic Disaster Recovery für EC2 auf AMS finden Sie unter Allgemeine Architektur AWS Elastic Disaster Recovery (AWS DRS).
EC2-DR-Schritte mit Elastic Disaster Recovery auf AMS:
Erstellen Sie einen Platzhalter-EC2-AMS-Stack im Zielsubnetz (DR-Site-Subnetz) mit den richtigen Tags. Weitere Informationen finden Sie im vorherigen Abschnitt. Wir empfehlen die Verwendung von CFN-Ingestion zur Erstellung des Stacks, da Sie die Schritte des Zuweisens von Sicherheitsgruppen und des Kennzeichnens der Instance, des EBS-Volumes und anderer Elemente (wie das Hinzufügen der Instance zu einem ELB) im selben Stack kombinieren können.
Typ ändern: Bereitstellung, Aufnahme, Stapel aus Vorlage, Erstellen CloudFormation
Stoppen Sie die Platzhalterinstanz.
Typ ändern: Verwaltung, Erweiterte Stack-Komponenten, EC2-Instanz, Stopp
Falls nicht in Schritt 1, kennzeichnen Sie die Platzhalter-Instance und ihr EBS-Volume mit dem Schlüssel: „AWSDRS“, Wert: "“. AllowLaunchingIntoThisInstance
Typ ändern: Verwaltung, Erweiterte Stack-Komponenten, Tag, Update.
Verwenden Sie die Platzhalterinstanz aus Schritt 1 als Ziel unter Instanz-ID starten, DRS-Starteinstellungen für den Quellserver. Initiieren Sie den Instance Recovery Drill von der Elastic Disaster Recovery-Konsole für den Quellserver aus.
Anmerkung
Die Platzhalter-Instance-Volumes werden im Konto beibehalten. Um diese Volumes zu löschen, reichen Sie am Ende des Disaster Recovery-Vorgangs einen Änderungstyp Management | Advanced Stack Components | EBS Volume | Delete (ct-3e3h8u0sp5z80) ein.
Elastic Disaster Recovery-Wiederherstellungs-Workflow:
Die Zielinstanz (Platzhalter) muss sich im Status „Gestoppt“ befinden
Tauschen Sie die Volumes aus und löschen Sie das Quell-Stammvolume (Platzhalter)
Starten Sie die Instanz
Führen Sie die Post-Launch-Aktionen aus, um die folgenden Aufgaben abzuschließen:
Aktivieren Sie den SSM-Agenten.
Tauschen Sie die Volumes aus und löschen Sie das Quell-Stammvolume (Platzhalter).
Starten Sie die Instanz
Führen Sie das PostLaunchScript SSM-Dokument aus. Dieses Dokument enthält folgende Funktionen:
Verlässt die alte Domain.
Ändert den Hostnamen.
Starten Sie neu. AMS-Bootstrap-Skripts verbinden die Instance beim Start mit der Zieldomäne (DR).
