Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Nutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen einer Datenquelle mit Amazon Redshift Redshift-Daten (Konsole)
Die Amazon ML-Konsole bietet zwei Möglichkeiten, eine Datenquelle mit Amazon Redshift Redshift-Daten zu erstellen. Sie können eine Datenquelle erstellen, indem Sie den Assistenten zum Erstellen von Datenquellen ausführen, oder, falls Sie bereits eine aus Amazon Redshift Redshift-Daten erstellte Datenquelle haben, können Sie die ursprüngliche Datenquelle kopieren und ihre Einstellungen ändern. Das Kopieren einer Datenquelle ermöglicht Ihnen die einfache Erstellung mehrerer ähnlicher Datenquellen.
Informationen zum Erstellen einer Datenquelle mithilfe der API finden Sie unter. CreateDataSourceFromRedshift
Weitere Information zu den Parametern der folgenden Verfahren finden Sie unter Erforderliche Parameter für den Assistenten Datenquelle erstellen.
Erstellen einer Datenquelle (Konsole)
Verwenden Sie den Assistenten „Datenquelle erstellen“, um Daten aus Amazon Redshift in eine Amazon ML-Datenquelle zu entladen.
So erstellen Sie eine Datenquelle aus Daten in Amazon Redshift
Öffnen Sie die Amazon Machine Learning Learning-Konsole unter https://console.aws.amazon.com/machinelearning/
. -
Wählen Sie im Amazon ML-Dashboard unter Entitäten die Option Create new... , und wählen Sie dann Datasource.
-
Wählen Sie auf der Seite Eingabedaten Amazon Redshift aus.
-
Geben Sie im Assistenten „Datenquelle erstellen“ unter Cluster-ID den Namen des Clusters ein.
-
Geben Sie unter Datenbankname den Namen der Amazon Redshift Redshift-Datenbank ein.
-
Geben Sie im Feld Datenbank-Benutzername den Benutzernamen für die Datenbank ein.
-
Geben Sie im Feld Datenbankpasswort das Passwort für die Datenbank ein.
-
Wählen Sie unter IAM-Rolle Ihre IAM-Rolle. Wenn Sie noch keine haben, wählen Sie Neue Rolle erstellen aus. Amazon ML erstellt eine IAM-Amazon Redshift-Rolle für Sie.
-
Um Ihre Amazon Redshift Redshift-Einstellungen zu testen, wählen Sie Test Access (neben IAM-Rolle). Wenn Amazon ML mit den bereitgestellten Einstellungen keine Verbindung zu Amazon Redshift herstellen kann, können Sie nicht weiter eine Datenquelle erstellen. Hilfe zur Problembehebung finden Sie unter Fehlersuche.
-
Geben Sie unter SQL-Abfrage die SQL-Abfrage ein.
-
Wählen Sie unter Schemaposition aus, ob Amazon ML ein Schema für Sie erstellen soll. Wenn Sie selbst ein Schema erstellt haben, geben Sie den Amazon S3 S3-Pfad zu Ihrer Schemadatei ein.
-
Geben Sie für den Amazon S3 S3-Staging-Speicherort den Amazon S3 S3-Pfad zu dem Bucket ein, in den Amazon ML die aus Amazon Redshift entladenen Daten ablegen soll.
-
(Optional) Geben Sie unter Datenquellenname einen Namen für die Datenquelle ein.
-
Wählen Sie Überprüfen. Amazon ML überprüft, ob es eine Verbindung zu Ihrer Amazon Redshift Redshift-Datenbank herstellen kann.
-
Überprüfen Sie auf der Seite Schema die Datentypen für alle Attribute und korrigieren Sie sie falls erforderlich.
-
Klicken Sie auf Weiter.
-
Wenn Sie diese Datenquelle verwenden möchten, um ein ML-Modell zu erstellen oder auszuwerten, wählen Sie für Beabsichtigen Sie, dieses Datenset für die Erstellung oder Auswertung eines ML-Modells zu verwenden? die Antwort Ja. Wenn Sie Ja gewählt haben, wählen Sie die Zeile für die Ziele. Weitere Informationen über Ziele finden Sie unter Das targetAttributeName Feld verwenden.
Wenn Sie diese Datenquelle mit einem Modell verwenden möchten, das Sie bereits erstellt haben, um Voraussagen zu erstellen, wählen Sie Nein.
-
Klicken Sie auf Weiter.
-
Wählen Sie für Enthalten Ihre Daten eine ID? die Antwort Nein, wenn Ihre Daten keine Zeilen-ID enthalten.
Wenn Ihre Daten eine Zeilen-ID enthalten, wählen Sie Ja. Weitere Information zu Zeilen-IDs finden Sie unter Verwenden des Felds rowID.
-
Wählen Sie Überprüfen aus.
-
Prüfen Sie auf der Seite Prüfen Ihre Einstellungen und wählen Sie Fertig.
Nachdem Sie eine Datenquelle erstellt haben, können Sie diese folgendermaßen verwenden: create an ML model. Wenn Sie bereits ein Modell erstellt haben, können Sie mit der Datenquelle evaluate an ML model oder generate predictions.
Kopieren einer Datenquelle (Konsole)
Wenn Sie eine Datenquelle erstellen möchten, die einer vorhandenen Datenquelle ähnelt, können Sie die Amazon ML-Konsole verwenden, um die ursprüngliche Datenquelle zu kopieren und ihre Einstellungen zu ändern. Sie können sich beispielsweise dafür entscheiden, mit einer vorhandenen Datenquelle zu beginnen und dann das Datenschema so zu ändern, dass es Ihren Daten besser entspricht, die SQL-Abfrage ändern, die zum Entladen von Daten aus Amazon Redshift verwendet wird, oder einen anderen AWS Identity and Access Management (IAM) -Benutzer für den Zugriff auf den Amazon Redshift Redshift-Cluster angeben.
So kopieren und ändern Sie eine Amazon Redshift Redshift-Datenquelle
Öffnen Sie die Amazon Machine Learning Learning-Konsole unter https://console.aws.amazon.com/machinelearning/
. -
Wählen Sie im Amazon ML-Dashboard unter Entitäten die Option Create new... , und wählen Sie dann Datasource.
-
Auf der Seite Eingabedaten für Wo sind Ihre Daten? , wählen Sie Amazon Redshift. Wenn Sie bereits eine Datenquelle haben, die aus Amazon Redshift Redshift-Daten erstellt wurde, haben Sie die Möglichkeit, Einstellungen aus einer anderen Datenquelle zu kopieren.
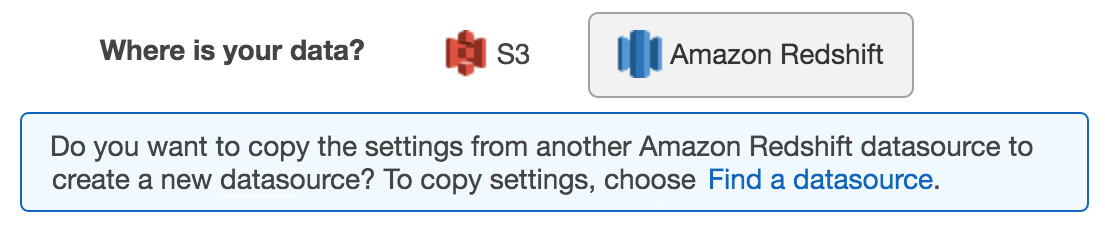
Wenn Sie noch keine Datenquelle haben, die aus Amazon Redshift Redshift-Daten erstellt wurde, wird diese Option nicht angezeigt.
-
Wählen Sie Eine Datenquelle suchen.
-
Wählen Sie die Datenquelle aus, die Sie kopieren möchten, und wählen Sie Einstellungen kopieren. Amazon ML füllt die meisten Datenquelleneinstellungen automatisch mit Einstellungen aus der ursprünglichen Datenquelle aus. Das Passwort für die Datenbank, der Speicherort des Schemas und der Name der Datenquelle werden nicht von der ursprünglichen Datenquelle kopiert.
-
Ändern Sie die automatisch vorgenommenen Einstellungen nach Bedarf. Wenn Sie beispielsweise die Daten ändern möchten, die Amazon ML aus Amazon Redshift entlädt, ändern Sie die SQL-Abfrage.
-
Geben Sie im Feld Datenbankpasswort das Passwort für die Datenbank ein. Amazon ML speichert Ihr Passwort nicht und verwendet es auch nicht wieder, daher müssen Sie es immer angeben.
-
(Optional) Für den Speicherort des Schemas wählt Amazon ML vorab Ich möchte, dass Amazon ML ein empfohlenes Schema für Sie generiert. Wenn Sie bereits ein Schema erstellt haben, wählen Sie Ich möchte das Schema verwenden, das ich in Amazon S3 erstellt und gespeichert habe, und geben Sie den Pfad zu Ihrer Schemadatei in Amazon S3 ein.
-
(Optional) Geben Sie unter Datenquellenname einen Namen für die Datenquelle ein. Andernfalls generiert Amazon ML einen neuen Datenquellennamen für Sie.
-
Wählen Sie Überprüfen. Amazon ML überprüft, ob es eine Verbindung zu Ihrer Amazon Redshift Redshift-Datenbank herstellen kann.
-
(Optional) Wenn Amazon ML das Schema für Sie abgeleitet hat, überprüfen Sie auf der Seite Schema die Datentypen für alle Attribute und korrigieren Sie sie gegebenenfalls.
-
Klicken Sie auf Weiter.
-
Wenn Sie diese Datenquelle verwenden möchten, um ein ML-Modell zu erstellen oder auszuwerten, wählen Sie für Beabsichtigen Sie, dieses Datenset für die Erstellung oder Auswertung eines ML-Modells zu verwenden? die Antwort Ja. Wenn Sie Ja gewählt haben, wählen Sie die Zeile für die Ziele. Weitere Informationen über Ziele finden Sie unter Das targetAttributeName Feld verwenden.
Wenn Sie diese Datenquelle mit einem Modell verwenden möchten, das Sie bereits erstellt haben, um Voraussagen zu erstellen, wählen Sie Nein.
-
Klicken Sie auf Weiter.
-
Wählen Sie für Enthalten Ihre Daten eine ID? die Antwort Nein, wenn Ihre Daten keine Zeilen-ID enthalten.
Wenn Ihre Daten eine Zeilen-ID enthalten, wählen Sie Ja und wählen Sie die Zeile aus, die Sie als ID verwenden möchten. Weitere Information zu Zeilen-IDs finden Sie unter Verwenden des Felds rowID.
-
Wählen Sie Überprüfen aus.
-
Überprüfen Sie die Einstellungen und klicken Sie anschließend auf Fertig.
Nachdem Sie eine Datenquelle erstellt haben, können Sie diese folgendermaßen verwenden: create an ML model. Wenn Sie bereits ein Modell erstellt haben, können Sie mit der Datenquelle evaluate an ML model oder generate predictions.
