Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen ereignisgesteuerter Architekturen mit Lambda
Ein Ereignis ist alles, was das Ausführen einer Lambda-Funktion auslöst. Ereignisse können eine Lambda-Funktion auf zwei Arten auslösen: durch direkten Aufruf (Push) und durch Zuordnungen von Ereignisquellen (Pull).
Viele AWS Dienste können Ihre Lambda-Funktionen direkt aufrufen. Diese Services leiten Ereignisse an Ihre Lambda-Funktion weiter. Ereignisse, die Funktionen auslösen, können fast alles sein, von einer HTTP-Anfrage über API Gateway, einem durch eine EventBridge Regel verwalteten Zeitplan, einem AWS IoT Ereignis oder einem Amazon S3 S3-Ereignis. Bei der Zuordnung von Ereignisquellen ruft Lambda aktiv Ereignisse aus einer Warteschlange oder einem Stream ab (Pull). Sie konfigurieren Lambda so, dass Lambda nach Ereignissen von einem unterstützten Service sucht, und Lambda kümmert sich um die Abfrage und den Aufruf Ihrer Funktion.
Wenn Ereignisse an Ihre Funktion übergeben werden, sind sie im JSON-Format strukturiert. Die JSON-Struktur variiert je nach Service, von dem sie generiert wird, und dem Ereignistyp. Während Standardaufrufe von Lambda-Funktionen bis zu 15 Minuten dauern können, eignet sich Lambda am besten für kurze Aufrufe, die eine Sekunde oder weniger dauern. Dies gilt insbesondere für ereignisgesteuerte Architekturen, bei denen jede Lambda-Funktion als Mikroservice behandelt wird, der für die Ausführung eines engen Satzes spezifischer Befehle verantwortlich ist.
Anmerkung
Event-driven Architekturen kommunizieren über verschiedene Systeme hinweg mithilfe von Netzwerken, was zu variabler Latenz führt. Für Workloads, die eine sehr geringe Latenz erfordern, wie z. B. Handelssysteme in Echtzeit, ist dieses Design möglicherweise nicht die beste Wahl. Für hoch skalierbare und verfügbare Workloads oder solche mit unvorhersehbaren Datenverkehrsmustern können ereignisgesteuerte Architekturen jedoch eine effektive Möglichkeit bieten, diese Anforderungen zu erfüllen.
Themen
Vorteile einer ereignisgesteuerten Architektur
Lambda unterstützt zwei Aufrufmethoden in ereignisgesteuerten Architekturen:
-
Direkter Aufruf (Push-Methode): AWS Dienste lösen Lambda-Funktionen direkt aus. Beispiel:
-
Amazon S3 löst eine Funktion aus, wenn eine Datei hochgeladen wird.
-
API Gateway löst eine Funktion aus, wenn es eine HTTP-Anfrage empfängt.
-
-
Zuordnung von Ereignisquellen (Pull-Methode): Lambda ruft Ereignisse ab und ruft Funktionen auf. Beispiel:
-
Lambda ruft Nachrichten aus einer Amazon-SQS-Warteschlange ab und ruft eine Funktion auf.
-
Lambda liest Datensätze aus einem DynamoDB-Stream und ruft eine Funktion auf.
-
Beide Methoden tragen zu den Vorteilen von ereignisgesteuerten Architekturen bei, wie unten beschrieben.
Polling und Webhooks durch Ereignisse ersetzen
Viele traditionelle Architekturen verwenden Polling- und Webhook-Mechanismen, um den Status zwischen verschiedenen Komponenten zu kommunizieren. Das Abrufen von Aktualisierungen kann sehr ineffizient sein, da es eine Verzögerung zwischen der Verfügbarkeit neuer Daten und der Synchronisierung mit nachgelagerten Diensten gibt. Webhooks werden nicht immer von anderen Microservices unterstützt, in die Sie sich integrieren möchten. Sie erfordern möglicherweise auch benutzerdefinierte Autorisierungs- und Authentifizierungskonfigurationen. In beiden Fällen ist es schwierig, diese Integrationsmethoden ohne zusätzliche Arbeit der Entwicklungsteams bedarfsgerecht zu skalieren.
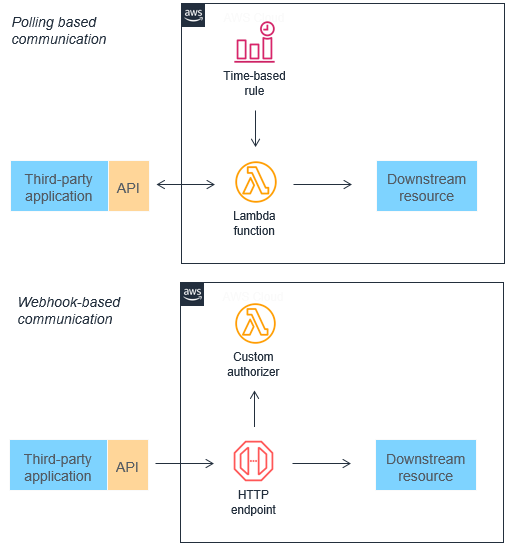
Diese beiden Mechanismen können durch Ereignisse ersetzt werden, die gefiltert, weitergeleitet und an nachgelagerte Microservices weitergeleitet werden können. Dieser Ansatz kann zu einem geringeren Bandbreitenverbrauch, einer geringeren CPU-Auslastung und potenziell niedrigeren Kosten führen. Diese Architekturen können auch die Komplexität verringern, da jede Funktionseinheit kleiner ist und oft weniger Code enthalten ist.
Event-driven Architekturen können es auch einfacher machen, Systeme zu entwerfen, die nahezu in Echtzeit laufen, und Unternehmen helfen, sich von der stapelbasierten Verarbeitung zu verabschieden. Ereignisse werden zu dem Zeitpunkt erzeugt, an dem sich der Zustand der Anwendung ändert. Der benutzerdefinierte Code eines Microservices sollte daher so konzipiert sein, dass er die Verarbeitung eines einzelnen Ereignisses verarbeiten kann. Da die Skalierung durch den Lambda-Dienst erfolgt, kann diese Architektur einen erheblichen Anstieg des Datenverkehrs ohne Änderung des benutzerdefinierten Codes bewältigen. Mit der Zunahme von Ereignissen wächst auch die Datenverarbeitungsschicht, die die Ereignisse verarbeitet.
Reduzierung der Komplexität
Microservices ermöglichen es Entwicklern und Architekten, komplexe Arbeitsabläufe zu vereinfachen. Ein E-Commerce-Monolith kann beispielsweise in Auftragsannahme- und Zahlungsprozesse mit separaten Inventar-, Fulfillment- und Buchhaltungsdienstleistungen unterteilt werden. Was in einem Monolith komplex zu verwalten und zu orchestrieren sein könnte, wird zu einer Reihe von entkoppelten Diensten, die asynchron mit Ereignissen kommunizieren.
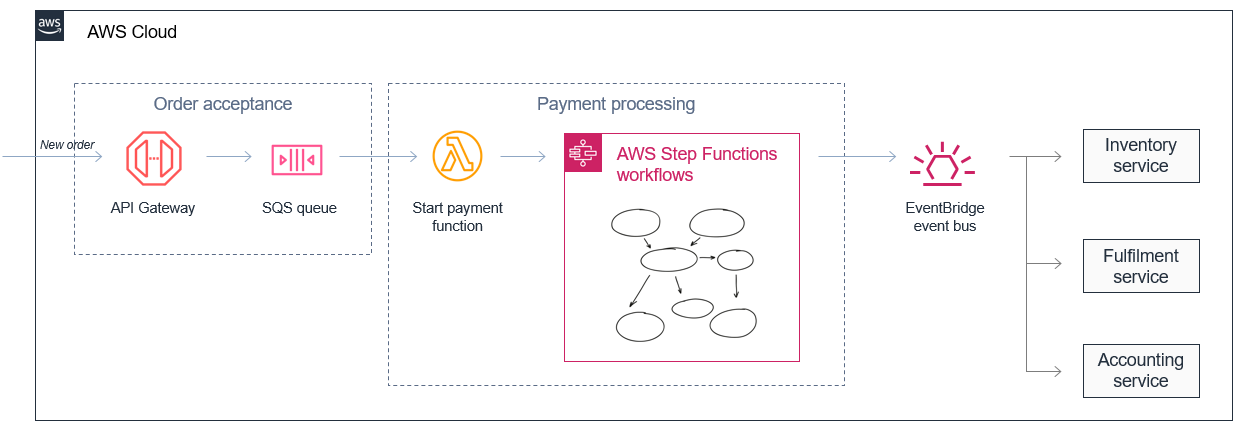
Dieser Ansatz ermöglicht auch die Zusammenstellung von Diensten, die Daten mit unterschiedlichen Geschwindigkeiten verarbeiten. In diesem Fall kann ein Microservice für die Auftragsannahme große Mengen eingehender Bestellungen speichern, indem er die Nachrichten in einer Amazon SQS SQS-Warteschlange zwischenspeichert.
Ein Zahlungsabwicklungsservice, der aufgrund der Komplexität der Zahlungsabwicklung in der Regel langsamer ist, kann einen stetigen Strom von Nachrichten aus der Amazon SQS-Warteschlange entgegennehmen. Er kann komplexe Wiederholungsversuche und Fehlerbehandlungslogik mithilfe von AWS Step Functions aktiven Zahlungsabläufen für Hunderttausende von Bestellungen orchestrieren und diese koordinieren.
Alternativer Ansatz: Für die Orchestrierung mit Standard-Programmiersprachen können Sie langlebige Lambda-Funktionen verwenden. Mit dauerhaften Funktionen können Sie die Auftragsannahme, die Zahlungsabwicklung und die Benachrichtigungslogik mit automatischem Checkpoint und automatischem Wiederholungsversuch in Code schreiben. Dieser Ansatz funktioniert gut, wenn der Workflow hauptsächlich Lambda-Funktionen umfasst und Sie es vorziehen, die Orchestrierungslogik im Code beizubehalten.
Verbesserung der Skalierbarkeit und Erweiterbarkeit
Microservices generieren Ereignisse, die in der Regel in Messaging-Diensten wie Amazon SNS und Amazon SQS veröffentlicht werden. Diese verhalten sich wie ein elastischer Puffer zwischen Microservices und helfen bei der Skalierung, wenn der Datenverkehr zunimmt. Dienste wie Amazon EventBridge können dann Nachrichten je nach Inhalt des Ereignisses filtern und weiterleiten, wie in den Regeln definiert. Infolgedessen sind ereignisbasierte Anwendungen skalierbarer und bieten eine größere Redundanz als monolithische Anwendungen.
Dieses System ist außerdem in hohem Maße erweiterbar, so dass andere Teams die Features erweitern und neue Features hinzufügen können, ohne dass dies Auswirkungen auf die Microservices für die Auftrags- und Zahlungsabwicklung hat. Durch die Veröffentlichung von Ereignissen mithilfe EventBridge dieser Anwendung lässt sie sich in bestehende Systeme wie den Inventar-Microservice integrieren, ermöglicht aber auch die Integration jeder future Anwendung als Event-Consumer. Die Produzenten von Ereignissen haben keine Kenntnis über die Konsumenten von Ereignissen, was zur Vereinfachung der Logik des Mikrodienstes beitragen kann.
Trade-offs ereignisgesteuerter Architekturen
Variable Latenzzeit
Im Gegensatz zu monolithischen Anwendungen, die möglicherweise alles innerhalb desselben Speicherbereichs auf einem einzigen Gerät verarbeiten, kommunizieren ereignisgesteuerte Anwendungen netzwerkübergreifend. Dieses Design führt zu einer variablen Latenzzeit. Es ist zwar möglich, Anwendungen so zu entwickeln, dass die Latenzzeit minimiert wird, aber monolithische Anwendungen können fast immer auf Kosten der Skalierbarkeit und Verfügbarkeit für eine geringere Latenzzeit optimiert werden.
Workloads, die eine konsistente Leistung mit geringer Latenz erfordern, wie z. B. Hochfrequenz-Handelsanwendungen in Banken oder die Submillisekunden-Automatisierung von Robotern in Lagerhäusern, sind keine guten Kandidaten für eine ereignisgesteuerte Architektur.
Letztendliche Datenkonsistenz
Ein Ereignis stellt eine Zustandsänderung dar und da zu einem bestimmten Zeitpunkt viele Ereignisse durch verschiedene Dienste in einer Architektur fließen, sind solche Workloads oft irgendwann konsistent
Einige Workloads enthalten eine Kombination von Anforderungen, die eventuell konsistent (z. B. Gesamtaufträge in der aktuellen Stunde) oder stark konsistent (z. B. aktueller Bestand) sind. Für Workloads, die eine hohe Datenkonsistenz erfordern, gibt es Architekturmuster, die dies unterstützen. Beispiel:
-
DynamoDB kann strikt konsistente Lesevorgänge bereitstellen, manchmal mit einer höheren Latenz, wodurch ein höherer Durchsatz als im Standardmodus verbraucht wird. DynamoDB kann auch Transaktionen unterstützen, um die Datenkonsistenz aufrechtzuerhalten.
-
Sie können Amazon RDS für Features verwenden, die ACID-Eigenschaften
benötigen, obwohl relationale Datenbanken weniger skalierbar sind als ein NoSQL-Datenbanken wie DynamoDB. Amazon-RDS-Proxy kann dabei helfen, das Verbindungspooling und die Skalierung von kurzlebigen Verbrauchern wie Lambda-Funktionen zu verwalten.
Event-based Architekturen basieren in der Regel auf einzelnen Ereignissen und nicht auf großen Datenmengen. Im Allgemeinen sind Workflows so konzipiert, dass sie die Schritte eines einzelnen Ereignisses oder Ausführungsablaufs verwalten, anstatt mehrere Ereignisse gleichzeitig zu bearbeiten. In Serverless-Systemen wird die Echtzeit-Ereignisverarbeitung der Batch-Verarbeitung vorgezogen: Batches sollten durch viele kleinere inkrementelle Aktualisierungen ersetzt werden. Dies kann zwar die Verfügbarkeit und Skalierbarkeit von Workloads verbessern, macht es aber auch schwieriger für Ereignisse, andere Ereignisse zu erkennen.
Rückgabe von Werten an Anrufer
In vielen Fällen sind ereignisbasierte Anwendungen asynchron. Das bedeutet, dass Anruferdienste nicht auf Anfragen von anderen Diensten warten, bevor sie mit anderen Aufgaben fortfahren. Dies ist eine grundlegende Eigenschaft ereignisgesteuerter Architekturen, die Skalierbarkeit und Flexibilität ermöglicht. Dies bedeutet, dass die Übergabe von Rückgabewerten oder des Ergebnisses eines Workflows komplexer ist als bei synchronen Ausführungsabläufen.
Die meisten Lambda-Aufrufe in Produktionssystemen sind asynchron und reagieren auf Ereignisse von Diensten wie Amazon S3 oder Amazon SQS. In diesen Fällen ist der Erfolg oder Misserfolg der Verarbeitung eines Ereignisses oft wichtiger als die Rückgabe eines Wertes. Features wie Warteschlangen für unzustellbare Nachrichten (DLQs) in Lambda stellen sicher, dass Sie fehlgeschlagene Ereignisse identifizieren und erneut versuchen können, ohne den Aufrufer benachrichtigen zu müssen.
Dienst- und funktionsübergreifendes Debugging
Die Fehlersuche in ereignisgesteuerten Systemen unterscheidet sich ebenfalls von einer monolithischen Anwendung. Da verschiedene Systeme und Services Ereignisse weitergeben, ist es nicht möglich, den genauen Zustand mehrerer Services beim Auftreten von Fehlern zu erfassen und zu reproduzieren. Da jeder Dienst- und Funktionsaufruf über separate Protokolldateien verfügt, kann es komplizierter sein, festzustellen, was mit einem bestimmten Ereignis passiert ist, das einen Fehler verursacht hat.
Es gibt drei wichtige Voraussetzungen für den Aufbau eines erfolgreichen Debugging-Ansatzes in ereignisgesteuerten Systemen. Erstens ist ein robustes Protokollierungssystem von entscheidender Bedeutung. Dieses wird AWS dienstübergreifend bereitgestellt und von Amazon CloudWatch in Lambda-Funktionen eingebettet. Zweitens muss in diesen Systemen sichergestellt werden, dass jedes Ereignis eine Transaktionskennung hat, die bei jedem Schritt während einer Transaktion protokolliert wird, um die Suche nach Protokollen zu erleichtern.
Schließlich ist es sehr empfehlenswert, das Parsing und die Analyse von Protokollen mit Hilfe eines Debugging- und Überwachungsdienstes wie AWS X-Ray zu automatisieren. Dies kann Protokolle über mehrere Lambda-Aufrufe und -Dienste hinweg verbrauchen, wodurch es viel einfacher wird, die Ursache von Problemen zu ermitteln. Ausführliche Informationen zur Verwendung zur Fehlerbehebung finden Sie in der Anleitung X-Ray zur Fehlerbehebung.
Anti-patterns in Lambda-based ereignisgesteuerten Anwendungen
Vermeiden Sie beim Aufbau ereignisgesteuerter Architekturen mit Lambda die folgenden gängigen Anti-Patterns. Diese Muster funktionieren, können aber die Kosten und die Komplexität erhöhen.
Der Lambda-Monolith
Bei vielen Anwendungen, die von herkömmlichen Servern, wie Amazon-EC2-Instanzen oder Elastic-Beanstalk-Anwendungen migriert werden, führen Entwickler ein „Lift and Shift“ von bestehendem Code aus. Dies führt häufig zu einer einzigen Lambda-Funktion, die die gesamte Anwendungslogik enthält, die für alle Ereignisse ausgelöst wird. Bei einer einfachen Webanwendung würde eine monolithische Lambda-Funktion alle API-Gateway-Routen verwalten und mit allen erforderlichen nachgelagerten Ressourcen integrieren.
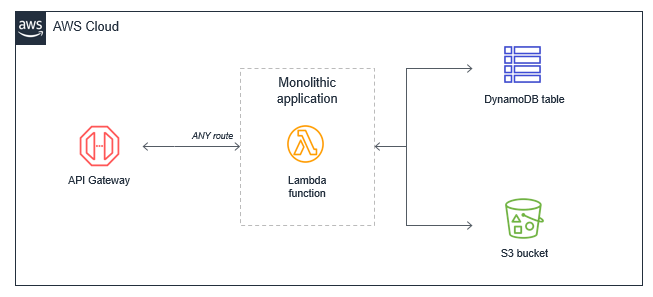
Dieser Ansatz hat mehrere Nachteile:
-
Paketgröße — Die Lambda-Funktion ist möglicherweise viel größer, da sie den gesamten möglichen Code für alle Pfade enthält, wodurch die Ausführung des Lambda-Dienstes langsamer wird.
-
Es ist schwierig, die geringste Berechtigung durchzusetzen: Die Ausführungsrolle der Funktion muss Berechtigungen für alle Ressourcen gewähren, die für alle Pfade benötigt werden, sodass die Berechtigungen sehr weit gefasst sind. Dies ist ein Sicherheitsproblem. Viele Pfade im funktionalen Monolithen benötigen nicht alle erteilten Berechtigungen.
-
Schwieriger zu aktualisieren: In einem Produktionssystem sind Upgrades für eine einzelne Funktion riskanter und können dazu führen, dass die gesamte Anwendung nicht mehr funktioniert. Das Upgrade eines einzelnen Pfads in der Lambda-Funktion ist ein Upgrade der gesamten Funktion.
-
Schwieriger zu warten: Es ist schwieriger, mehrere Entwickler an dem Dienst arbeiten zu lassen, da es sich um ein monolithisches Code-Repository handelt. Es erhöht auch die kognitive Belastung der Entwickler und erschwert es, eine angemessene Testabdeckung für Code zu schaffen.
-
Schwieriger, Code wiederzuverwenden: Es kann schwieriger sein, wiederverwendbare Bibliotheken von Monolithen zu trennen, was die Wiederverwendung von Code erschwert. Je mehr Projekte Sie entwickeln und unterstützen, desto schwieriger wird es, den Code zu unterstützen und die Geschwindigkeit Ihres Teams zu erhöhen.
-
Schwieriger zu testen: Mit zunehmender Anzahl von Codezeilen wird es immer schwieriger, für alle möglichen Kombinationen von Eingaben und Einstiegspunkten in der Codebasis einen Modultest durchzuführen. Es ist generell einfacher, Modultests für kleinere Dienste mit weniger Code zu implementieren.
Die bevorzugte Alternative besteht darin, die monolithische Lambda-Funktion in einzelne Microservices aufzuteilen und eine einzelne Lambda-Funktion einer einzigen, klar definierten Aufgabe zuzuordnen. In dieser einfachen Webanwendung mit einigen API-Endpunkten kann die resultierende Microservice-basierte Architektur auf den API-Gateway-Routen basieren.
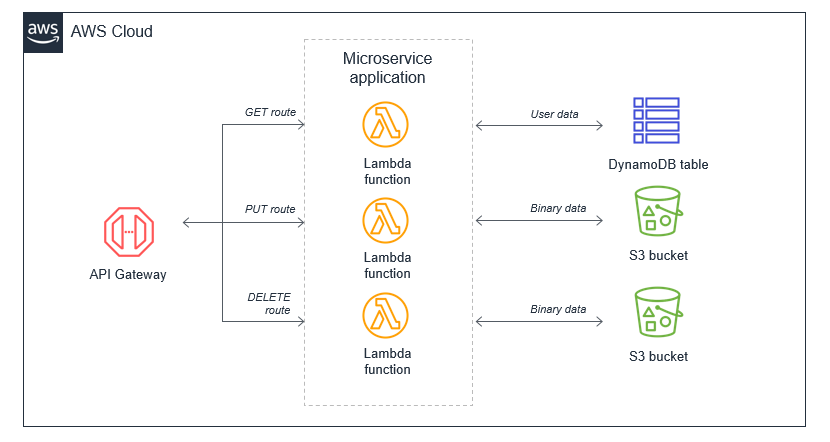
Rekursive Muster, die außer Kontrolle geratene Lambda-Funktionen verursachen
AWS Dienste generieren Ereignisse, die Lambda-Funktionen aufrufen, und Lambda-Funktionen können Nachrichten an Dienste senden. AWS Im Allgemeinen sollte sich der Dienst oder die Ressource, die eine Lambda-Funktion aufruft, von dem Dienst oder der Ressource unterscheiden, an den die Funktion ausgibt. Wenn dies nicht verwaltet wird, kann dies zu Endlosschleifen führen.
Zum Beispiel schreibt eine Lambda-Funktion ein Objekt in ein Amazon S3-Objekt, das wiederum dieselbe Lambda-Funktion über ein Put-Ereignis aufruft. Durch den Aufruf wird ein zweites Objekt in den Bucket geschrieben, das dieselbe Lambda-Funktion aufruft:
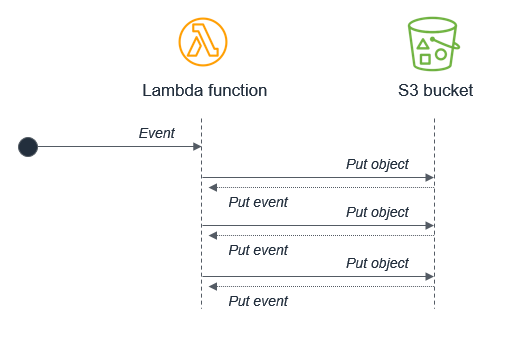
Während das Potenzial für Endlosschleifen in den meisten Programmiersprachen vorhanden ist, hat dieses Anti-Pattern das Potenzial, mehr Ressourcen in Serverless-Anwendungen zu verbrauchen. Sowohl Lambda als auch Amazon S3 skalieren automatisch auf der Grundlage des Datenverkehrs, sodass die Schleife dazu führen kann, dass Lambda skaliert, um die gesamte verfügbare Parallelität zu nutzen, und Amazon S3 schreibt weiterhin Objekte und generiert mehr Ereignisse für Lambda.
In diesem Beispiel wird S3 verwendet, aber das Risiko von rekursiven Schleifen besteht auch bei Amazon SNS, Amazon SQS, DynamoDB und anderen Diensten. Sie können die rekursive Schleifenerkennung verwenden, um dieses Anti-Pattern zu finden und zu vermeiden.
Lambda-Funktionen, die Lambda-Funktionen aufrufen
Funktionen ermöglichen die Kapselung und die Wiederverwendung von Code. Die meisten Programmiersprachen unterstützen das Konzept des synchronen Aufrufs von Funktionen innerhalb einer Codebasis. Wenn die Funktion einen Fehler zurückgibt, gibt die Funktion eine Antwort zurück.
Anmerkung
Während Lambda-Funktionen, die direkt andere Lambda-Funktionen aufrufen, aus Kosten- und Komplexitätsgründen im Allgemeinen ein Anti-Pattern darstellen, gilt dies nicht für langlebige Funktionen, die speziell dafür konzipiert sind, mehrstufige Workflows zu orchestrieren, indem sie andere Funktionen aufrufen.
Wenn dies auf einem herkömmlichen Server oder einer virtuellen Instance geschieht, wechselt der Scheduler des Betriebssystems zu einer anderen verfügbaren Arbeit. Ob die CPU zu 0 % oder zu 100 % läuft, hat keinen Einfluss auf die Gesamtkosten der Anwendung, da Sie für die Fixkosten des Besitzes und des Betriebs eines Servers zahlen.
Dieses Modell eignet sich häufig nicht gut für die Serverless-Entwicklung. Nehmen wir zum Beispiel eine einfache E-Commerce-Anwendung, die aus drei Lambda-Funktionen besteht, die eine Bestellung verarbeiten:
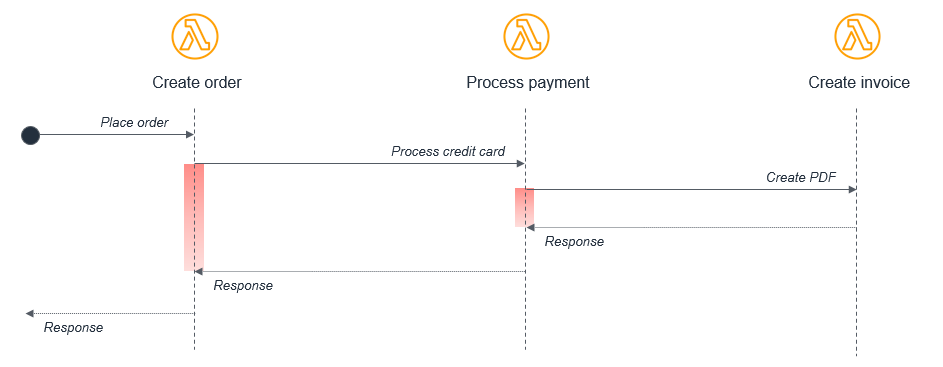
In diesem Fall ruft die Funktion Bestellung erstellen die Funktion Zahlung bearbeiten auf, die wiederum die Funktion Rechnung erstellen aufruft. Dieser synchrone Ablauf kann zwar innerhalb einer einzelnen Anwendung auf einem Server funktionieren, führt aber in einer verteilten serverlosen Architektur zu mehreren vermeidbaren Problemen:
-
Kosten: Bei Lambda zahlen Sie für die Dauer eines Aufrufs. In diesem Beispiel laufen während der Ausführung der Funktion Rechnung erstellen zwei weitere Funktionen in einem Wartezustand, der im Diagramm in Rot dargestellt ist.
-
Fehlerbehandlung: Bei verschachtelten Aufrufen kann die Fehlerbehandlung viel komplexer werden. Ein Fehler in Rechnung erstellen kann beispielsweise dazu führen, dass die Funktion „Zahlung verarbeiten“ die Belastung rückgängig macht, oder es wird stattdessen der Vorgang „Rechnung erstellen“ erneut versucht.
-
Enge Verknüpfung: Die Bearbeitung einer Zahlung dauert in der Regel länger als die Erstellung einer Rechnung. Bei diesem Modell wird die Verfügbarkeit des gesamten Workflows durch die langsamste Funktion eingeschränkt.
-
Skalierung: Die Gleichzeitigkeit aller drei Funktionen muss gleich sein. In einem stark frequentierten System wird dadurch mehr Gleichzeitigkeit verwendet, als andernfalls erforderlich wäre.
Bei Serverless-Anwendungen gibt es zwei gängige Ansätze, um dieses Muster zu vermeiden. Verwenden Sie zunächst eine Amazon-SQS-Warteschlange zwischen Lambda-Funktionen. Wenn ein nachgeschalteter Prozess langsamer ist als ein vorgeschalteter Prozess, hält die Warteschlange die Nachrichten dauerhaft fest und entkoppelt die beiden Funktionen. In diesem Beispiel würde die Funktion Bestellung erstellen eine Nachricht in einer Amazon SQS SQS-Warteschlange veröffentlichen, und die Funktion Zahlung verarbeiten verarbeitet Nachrichten aus der Warteschlange.
Der zweite Ansatz besteht darin, AWS Step Functions zu verwenden. Bei komplexen Prozessen mit mehreren Arten von Fehlern und Wiederholungslogik können Schrittfunktionen dazu beitragen, den Umfang des benutzerdefinierten Codes zu reduzieren, der für die Orchestrierung des Workflows erforderlich ist. Infolgedessen orchestriert Step Functions die Arbeit und behandelt Fehler und Wiederholungen zuverlässig und die Lambda-Funktionen enthalten nur Geschäftslogik.
Synchrones Warten innerhalb einer einzigen Lambda-Funktion
Stellen Sie sicher, dass potenziell gleichzeitige Aktivitäten nicht synchron innerhalb einer einzelnen Lambda-Funktion geplant werden. Eine Lambda-Funktion könnte beispielsweise in einen S3-Bucket und dann in eine DynamoDB-Tabelle schreiben:
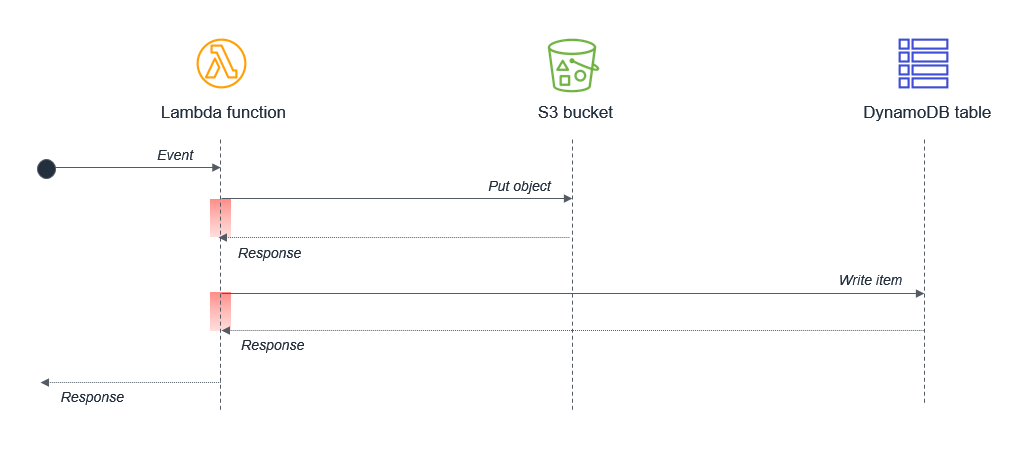
In diesem Design sind die Wartezeiten zusammengesetzt, weil die Aktivitäten sequentiell sind. In Fällen, in denen die zweite Aufgabe von der Fertigstellung der ersten Aufgabe abhängt, können Sie die Gesamtwartezeit und die Ausführungskosten verringern, indem Sie zwei separate Lambda-Funktionen verwenden:
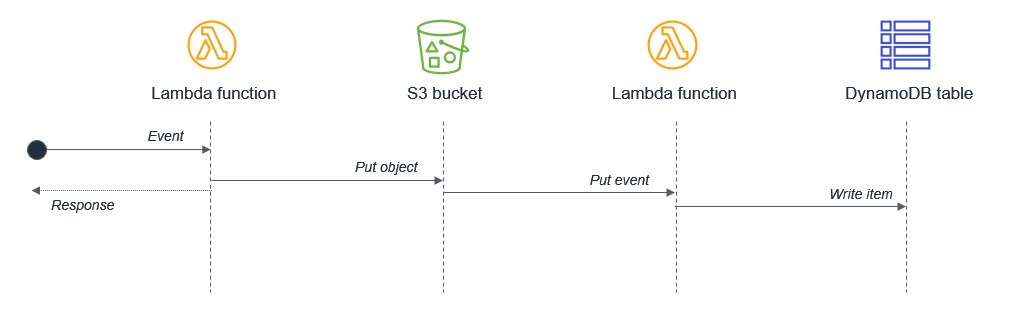
In diesem Design reagiert die erste Lambda-Funktion sofort, nachdem das Objekt in den Amazon-S3-Bucket gestellt wurde. Der S3-Dienst ruft die zweite Lambda-Funktion auf, die dann Daten in die DynamoDB-Tabelle schreibt. Dieser Ansatz minimiert die Gesamtwartezeit bei der Ausführung von Lambda-Funktionen.
