Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überführung Amazon Redshift Redshift-Daten in die AWS Glue Data Catalog
Sie können Analysedaten in Amazon Redshift Redshift-Data Warehouses im AWS Glue Data Catalog (Datenkatalog) verwalten und Amazon S3-Data Lakes und Amazon Redshift Redshift-Data Warehouses vereinheitlichen. Amazon Redshift ist ein vollständig verwalteter Data-Warehouse-Service im Petabyte-Bereich in der Cloud. AWS Ein Amazon-Redshift-Data-Warehouse ist eine Sammlung von Datenverarbeitungsressourcen, den so genannten Knoten, die zu Gruppen, den so genannten Clustern, zusammengefasst werden. In jedem Cluster wird eine Amazon-Redshift-Engine ausgeführt, und er enthält mindestens eine Datenbank.
In Amazon Redshift können Sie von Amazon Redshift bereitgestellte Cluster und serverlose Namespaces erstellen und diese im Datenkatalog registrieren. Auf diese Weise können Sie Daten in Amazon Redshift Managed Storage (RMS) und Amazon S3 S3-Buckets vereinheitlichen und auf Daten von Apache Iceberg-kompatiblen Analyse-Engines zugreifen.
Durch die Registrierung von Namespaces und Clustern können Sie Zugriff auf Daten gewähren, ohne sie kopieren oder verschieben zu müssen. Weitere Informationen zur Registrierung von Clustern und Namespaces in Amazon Redshift finden Sie unter Registrierung von Amazon Redshift Redshift-Clustern und Namespaces in der. AWS Glue Data Catalog
In Amazon Redshift können Sie Daten über Datashares oder durch die Registrierung von Namespaces und Clustern bei Data Catalog gemeinsam nutzen. Bei Datashares, die auf der Ebene einzelner Datenbankobjekte betrieben werden, müssen Sie die gemeinsame Nutzung für jede Tabelle oder Ansicht aktivieren. Im Gegensatz dazu funktioniert die Veröffentlichung von Namespaces auf Cluster- oder Namespace-Ebene. Wenn Sie einen Cluster oder Namespace im Datenkatalog registrieren, werden alle darin enthaltenen Datenbanken und Tabellen automatisch gemeinsam genutzt, ohne dass Sie die gemeinsame Nutzung für einzelne Objekte konfigurieren müssen.
Im Datenkatalog können Sie für jeden Namespace oder Cluster einen Verbundkatalog erstellen. Ein Katalog wird als Verbundkatalog bezeichnet, wenn er auf eine Entität außerhalb des Datenkatalogs verweist. Tabellen und Ansichten im Amazon Redshift Redshift-Namespace werden als einzelne Tabellen im Datenkatalog aufgeführt. Sie können Datenbanken und Tabellen im Verbundkatalog mit ausgewählten IAM-Prinzipalen und SAML-Benutzern innerhalb desselben Kontos oder in einem anderen Konto mit Lake Formation teilen. Sie können auch Zeilen- und Spaltenfilterausdrücke verwenden, um den Zugriff auf bestimmte Daten einzuschränken. Weitere Informationen finden Sie unter Datenfilterung und Sicherheit auf Zellebene in Lake Formation.
Der Datenkatalog unterstützt eine dreistufige Metadatenhierarchie, die Kataloge, Datenbanken und Tabellen (und Ansichten) umfasst. Wenn Sie einen Namespace beim Datenkatalog registrieren, wird die Amazon Redshift Redshift-Datenhierarchie der dreistufigen Hierarchie des Datenkatalogs wie folgt zugeordnet:
-
Der Amazon Redshift Redshift-Namespace wird zu einem mehrstufigen Katalog im Datenkatalog.
Die zugehörige Amazon Redshift Redshift-Datenbank ist als Katalog im Datenkatalog registriert.
-
Das Amazon Redshift Redshift-Schema wird zu einer Datenbank im Datenkatalog.
-
Die Amazon Redshift Redshift-Tabelle wird zu einer Tabelle im Datenkatalog.
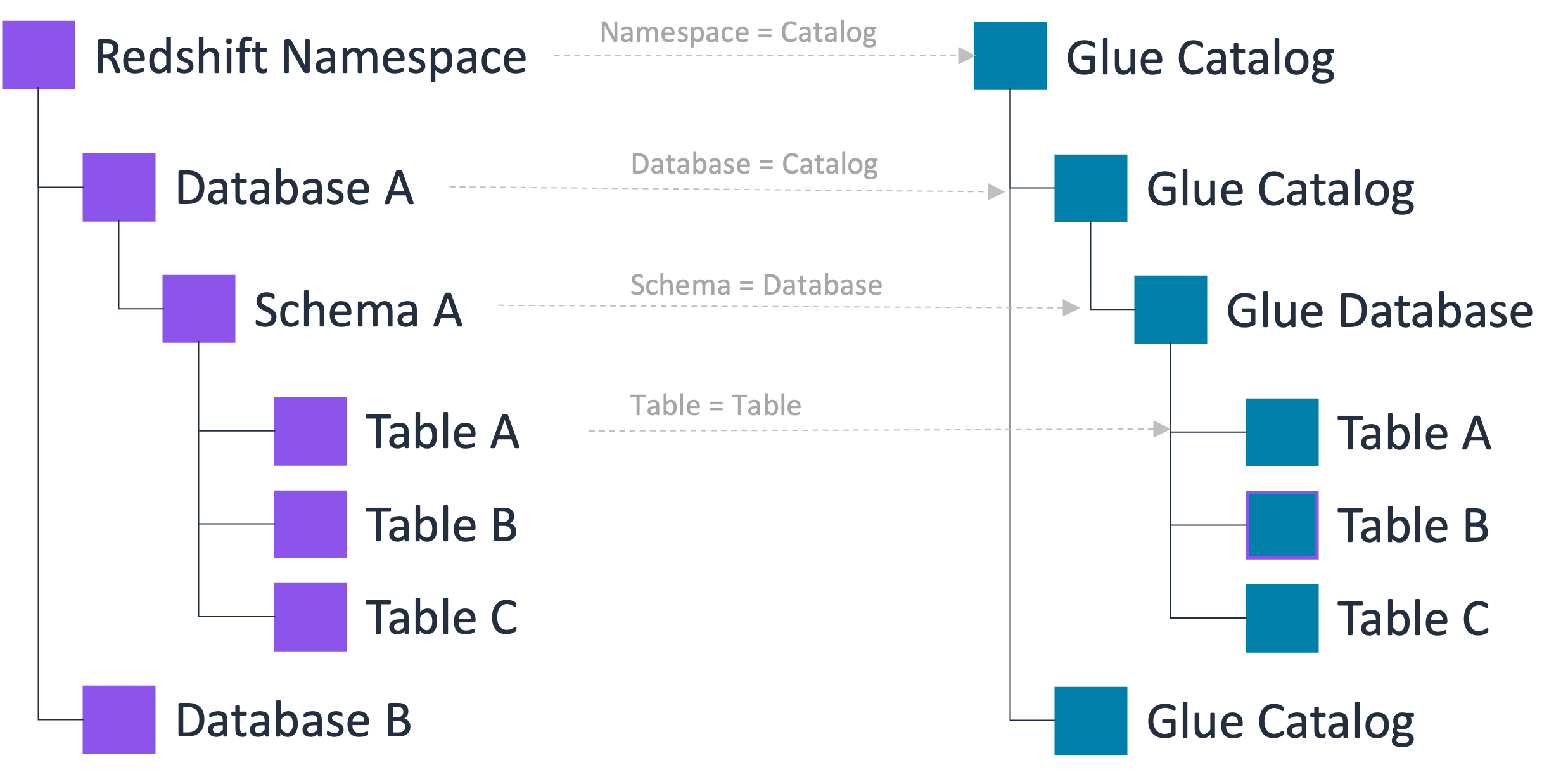
Mit dieser dreistufigen Metadatenhierarchie können Sie auf Amazon Redshift Redshift-Tabellen zugreifen, indem Sie die dreiteilige Notation „catalog1/catalog2.database.table“ im Datenkatalog verwenden. Außerdem können Datenteams dieselbe Organisation beibehalten, die Amazon Redshift für die Organisation von Tabellen innerhalb des Data Catalog-Kontos verwendet.
In Lake Formation können Sie die Daten von Amazon Redshift mithilfe einer detaillierten Zugriffskontrolle für die Datenkatalogressourcen sicher verwalten. Mit dieser Integration können Sie analytische Daten aus einem einzigen Katalog mit einem gemeinsamen Zugriffskontrollmechanismus verwalten, sichern und abfragen.
Einschränkungen finden Sie unter Einschränkungen für die Übertragung von Amazon Redshift Redshift-Data Warehouse-Daten in AWS Glue Data Catalog.
Themen
Wichtigste Vorteile
Die Registrierung von Amazon Redshift Redshift-Clustern und -Namespaces mit den AWS Glue Data Catalog und die Vereinheitlichung von Daten in Amazon S3 S3-Data Lakes und Amazon Redshift Redshift-Data Warehouses bietet die folgenden Vorteile:
Einheitliches Abfrageerlebnis — Fragen Sie Ihre von Amazon Redshift verwalteten Daten und Daten in den Amazon S3 S3-Buckets mit einer beliebigen mit Apache Iceberg kompatiblen Abfrage-Engine ab, z. B. Amazon EMR Serverless und Amazon Athena, ohne Daten verschieben oder kopieren zu müssen.
-
Konsistenter Datenzugriff für alle Services — Sie müssen Datenbank- und Tabellennamen in Ihren Daten-Pipelines nicht aktualisieren, wenn Sie von verschiedenen AWS Analysediensten aus auf dieselben föderierten Datenquellen zugreifen, da die Datenquellen im Datenkatalog registriert sind.
Präzise Zugriffskontrolle — Sie können Lake Formation Formation-Berechtigungen anwenden, um den Zugriff auf die Verbunddatenquellen mithilfe detaillierter Zugriffssteuerungsberechtigungen zu verwalten.
Rollen und Zuständigkeiten
| Rolle | Verantwortung |
| Clusteradministrator für Amazon Redshift Producer |
Registriert den Cluster oder Namespace im Datenkatalog. |
| Administrator von Lake Formation für den Data Lake |
Nimmt die Cluster- oder Namespace-Einladung an, erstellt Verbundkataloge und gewährt anderen Prinzipalen Zugriff auf die Verbundkataloge. |
| Lake Formation Administrator (nur lesbar) | Erkennt den Verbundkatalog und fragt Amazon Redshift Redshift-Tabellen im Verbundkatalog ab. |
| Rolle bei der Datenübertragung |
Amazon Redshift übernimmt in Ihrem Namen die Übertragung von Daten zum und vom Amazon S3 S3-Bucket. |
Im Folgenden sind die wichtigsten Schritte aufgeführt, um Benutzern Zugriff auf einen Amazon Redshift Redshift-Namespace zu gewähren:
-
In Amazon Redshift registriert der Producer-Cluster-Administrator einen Cluster oder Namespace im Datenkatalog.
-
Der Data Lake-Administrator akzeptiert die Namespace-Einladung vom Amazon Redshift Producer-Cluster-Administrator und erstellt einen Verbundkatalog im Datenkatalog.
Nach Abschluss dieses Schritts können Sie den Amazon Redshift Redshift-Namespace-Katalog im Datenkatalog verwalten.
-
Erteilen Sie Benutzern Berechtigungen für Kataloge, Datenbanken und Tabellen. Sie können den gesamten Namespace-Katalog oder eine Teilmenge von Tabellen für Benutzer desselben Kontos oder eines anderen Kontos gemeinsam nutzen.
