Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Offline-Migrationsprozess: Apache Cassandra zu Amazon Keyspaces
Offline-Migrationen eignen sich, wenn Sie sich Ausfallzeiten für die Durchführung der Migration leisten können. In Unternehmen ist es üblich, Wartungsfenster für Patches, große Releases oder Ausfallzeiten für Hardware-Upgrades oder größere Upgrades vorzusehen. Die Offline-Migration kann dieses Fenster verwenden, um Daten zu kopieren und den Anwendungsdatenverkehr von Apache Cassandra zu Amazon Keyspaces umzuschalten.
Die Offline-Migration reduziert die Anzahl der Änderungen an der Anwendung, da sie nicht gleichzeitig mit Cassandra und Amazon Keyspaces kommunizieren muss. Außerdem kann bei unterbrochenem Datenfluss der exakte Status kopiert werden, ohne dass Mutationen beibehalten werden.
In diesem Beispiel verwenden wir Amazon Simple Storage Service (Amazon S3) als Staging-Bereich für Daten während der Offline-Migration, um Ausfallzeiten zu minimieren. Sie können die Daten, die Sie im Parquet-Format in Amazon S3 gespeichert haben, mithilfe des Spark-Cassandra-Connectors und automatisch in eine Amazon Keyspaces-Tabelle importieren. AWS Glue Der folgende Abschnitt gibt einen allgemeinen Überblick über den Prozess. Codebeispiele für diesen Prozess finden Sie auf Github
Der Offline-Migrationsprozess von Apache Cassandra zu Amazon Keyspaces mithilfe von Amazon S3 AWS Glue erfordert die folgenden AWS Glue Jobs.
Ein ETL-Job, der CQL-Daten extrahiert, transformiert und in einem Amazon S3 S3-Bucket speichert.
Ein zweiter Job, der die Daten aus dem Bucket in Amazon Keyspaces importiert.
Ein dritter Job zum Importieren inkrementeller Daten.
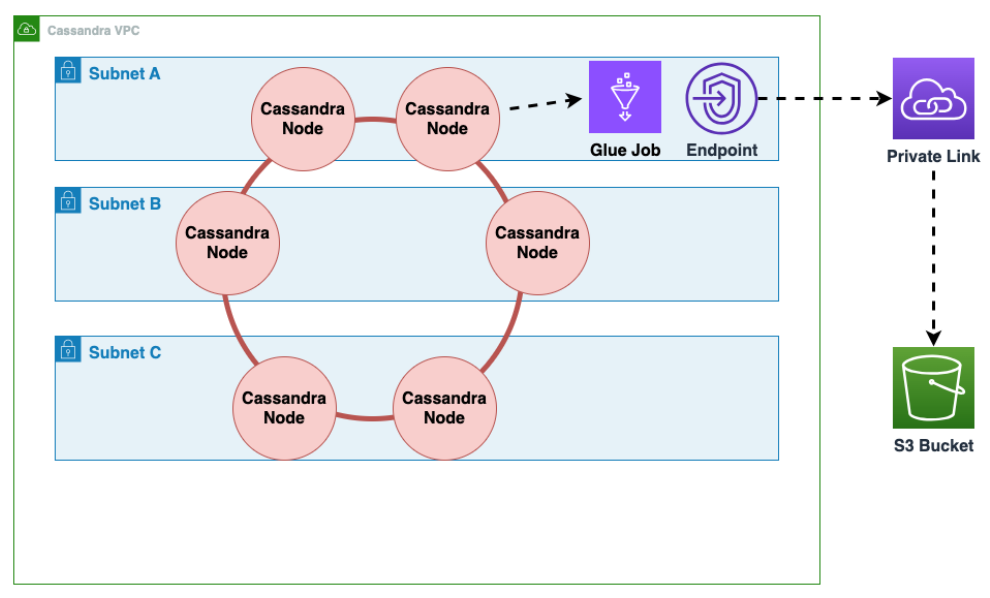
So führen Sie eine Offline-Migration von Cassandra, die auf Amazon EC2 in einer Amazon Virtual Private Cloud läuft, zu Amazon Keyspaces durch
Zuerst exportieren Sie AWS Glue Tabellendaten aus Cassandra im Parquet-Format und speichern sie in einem Amazon S3 S3-Bucket. Sie müssen einen AWS Glue Job mithilfe eines AWS Glue Connectors zu einer VPC ausführen, auf der sich die Amazon EC2 EC2-Instance befindet, auf der Cassandra ausgeführt wird. Anschließend können Sie mit dem privaten Amazon S3 S3-Endpunkt Daten im Amazon S3 S3-Bucket speichern.
Das folgende Diagramm veranschaulicht diese Schritte.
Mischen Sie die Daten im Amazon S3 S3-Bucket, um die Datenrandomisierung zu verbessern. Gleichmäßig importierte Daten ermöglichen einen stärker verteilten Datenverkehr in der Zieltabelle.
Dieser Schritt ist erforderlich, wenn Daten aus Cassandra mit großen Partitionen (Partitionen mit mehr als 1000 Zeilen) exportiert werden, um Tastenkombinationen beim Einfügen der Daten in Amazon Keyspaces zu vermeiden. Hotkey-Probleme treten
WriteThrottleEventsin Amazon Keyspaces auf und führen zu einer längeren Ladezeit.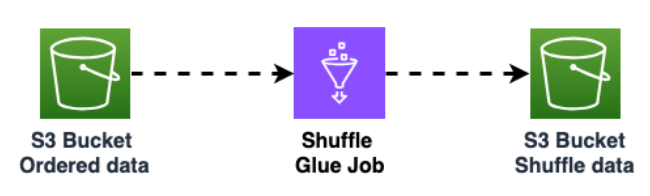
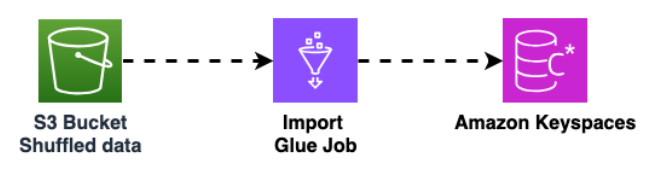
Verwenden Sie einen anderen AWS Glue Job, um Daten aus dem Amazon S3 S3-Bucket in Amazon Keyspaces zu importieren. Die gemischten Daten im Amazon S3 S3-Bucket werden im Parquet-Format gespeichert.
Weitere Informationen zum Offline-Migrationsprozess finden Sie im Workshop Amazon Keyspaces
