Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfiguration eines Ziels für eine Zero-ETL-Integration
AWS Glue Bei der Konfiguration eines Ziels für eine Zero-ETL-Integration stehen mehrere Optionen zur Verfügung. Das Ziel kann ein verschlüsseltes Amazon Redshift Data Warehouse oder eine Lakehouse-Architektur von Amazon SageMaker sein.
Bevor Sie das Ziel für die Null-ETL-Integration auswählen, müssen Sie eine der folgenden Zielressourcen konfigurieren. Folgende sind Konfigurationsoptionen für ein Ziel in einer Null-ETL-Integration:
Ein Allzweck-Amazon S3-Bucket, der die Lakehouse-Architektur von Amazon SageMaker verwendet. Siehe Konfiguration eines S3-Bucket-Ziels für allgemeine Zwecke.
Ein Amazon S3 Tables-Bucket, der die Lakehouse-Architektur von Amazon SageMaker verwendet. Siehe Konfiguration eines Amazon S3 Tables-Bucket-Ziels.
Ein Amazon Redshift verwalteter Speicher, der die Lakehouse-Architektur von Amazon SageMaker verwendet. Siehe Konfiguration eines Amazon Redshift Verwaltetes Speicherziel.
Ein Amazon Redshift Data Warehouse, das durch einen Redshift-Namespace identifiziert wird. Siehe Konfiguration eines Amazon Redshift Data Warehouse-Ziel.
Anmerkung
Sie können das Ziel einer Null-ETL-Integration nach der Erstellung nicht ändern.
Konfiguration eines S3-Bucket-Ziels für allgemeine Zwecke
In diesem Abschnitt werden die Voraussetzungen und Einrichtungsschritte für die Konfiguration eines S3-Buckets für allgemeine Zwecke als Speicher für Ihr Ziel in einer Zero-ETL-Integration unter Verwendung der Lakehouse-Architektur von Amazon beschrieben. SageMaker
Bevor Sie eine Zero-ETL-Integration mit der Lakehouse-Architektur von Amazon SageMaker mithilfe von Allzweck-S3-Speicher erstellen, müssen Sie die folgenden Einrichtungsaufgaben ausführen:
Richten Sie eine Datenbank ein AWS Glue
Geben Sie die RBAC-Richtlinie für den Katalog an.
Erstellen einer IAM-Zielrolle
Ordnen Sie die Zielrolle, KMS (optional) und Verbindung (optional) der Zielressource zu
(Optional) Konfigurieren Sie die Eigenschaften der Zieltabelle
Einrichten eines AWS Glue Datenbank
So richten Sie im Datenkatalog eine Zieldatenbank mit einem Amazon S3 S3-Allzweck-Bucket-Speicherort ein:
Wählen Sie auf der Startseite der AWS Glue Konsole unter Datenkatalog die Option Datenbank aus.
Wählen Sie oben rechts Datenbank hinzufügen aus. Wenn Sie bereits eine Datenbank erstellt haben, stellen Sie sicher, dass der Speicherort mit dem Amazon-S3-URI für die Datenbank festgelegt ist.
Geben Sie einen Namen und einen Speicherort ein (Amazon-S3-URI). Der Speicherort ist für die Null-ETL-Integration erforderlich. Anschließend klicken Sie auf Datenbank erstellen.
Anmerkung
Der Allzweck-Amazon S3-Bucket muss sich in derselben Region wie die AWS Glue Datenbank befinden.
Informationen zum Erstellen einer neuen Datenbank in AWS Glue finden Sie unter Erste Schritte mit dem Datenkatalog.
Sie können die Datenbank in AWS Glue auch mit der create-database-CLI erstellen. Beachten Sie, dass der LocationUri in --database-input erforderlich ist.
Optimieren von Iceberg-Tabellen
Sobald eine Tabelle AWS Glue in der Zieldatenbank erstellt wurde, können Sie die Komprimierung aktivieren, um Abfragen in Amazon Athena zu beschleunigen. Informationen zum Einrichten der Ressourcen (IAM-Rolle) zur Komprimierung finden Sie unter Voraussetzungen für die Tabellenoptimierung.
Weitere Informationen zum Einrichten der Komprimierung für die durch die Integration erstellte AWS Glue Tabelle finden Sie unter Optimieren von Iceberg-Tabellen.
Bereitstellen einer RBAC-Richtlinie (Resource Based Access – ressourcenbasierter Zugriff) für den Katalog
Für Integrationen, die eine AWS Glue Datenbank verwenden, fügen Sie der Katalog-RBAC-Richtlinie die folgenden Berechtigungen hinzu, um Integrationen zwischen Quelle und Ziel zu ermöglichen.
Anmerkung
Bei kontoübergreifenden Integrationen müssen sowohl der Benutzer, der die Integrationsrollenrichtlinie erstellt, als auch die Katalogressourcenrichtlinie die Ressource zulassen. glue:CreateInboundIntegration Für dasselbe Konto ist entweder eine Ressourcenrichtlinie oder eine Rollenrichtlinie ausreichend, die glue:CreateInboundIntegration für die Ressource zulässt. In beiden Szenarien muss glue.amazonaws.com jedoch glue:AuthorizeInboundIntegration erlaubt sein.
Sie können unter Datenkatalog auf die Katalogeinstellungen zugreifen. Geben Sie dann die folgenden Berechtigungen ein und geben Sie die fehlenden Informationen ein.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Erstellen einer IAM-Zielrolle
Erstellen Sie eine IAM-Zielrolle mit den folgenden Berechtigungen und Vertrauensstellungen:
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Fügen Sie die folgende Vertrauensrichtlinie hinzu, damit der AWS Glue Dienst die Rolle übernehmen kann:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Ordnen Sie die Zielrolle KMS (optional) und Verbindung (optional) der Zielressource zu
Ordnen Sie die obige Zielrolle der Zielressource, d. h. AWS Glue Datenbank, zu. Optional können KMS zum Verschlüsseln der Daten vor dem Speichern in der Ziel-Eisbergtabelle und Verbindungs-ARN für den Zugriff auf den S3-Bucket für die AWS Glue Zieldatenbank konfiguriert werden. Auf diese Weise können AWS Glue Sie mithilfe der bereitgestellten Rolle auf Daten am S3-Zielstandort zugreifen und optional mit dem bereitgestellten KMS-Schlüssel verschlüsseln. Wenn der Ziel-S3-Bucket so konfiguriert ist, dass er über eine bestimmte VPC zugänglich ist, kann der Verbindungs-ARN zugeordnet werden, damit die Verarbeitung innerhalb dieser VPC ausgeführt werden kann. AWS Glue Weitere Informationen zum Einrichten einer VPC finden Sie unter Erstellen einer VPC.
Oder mit der AWS Glue CLI//API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(Optional) Konfigurieren Sie die Eigenschaften der Zieltabelle
Optional können die Eigenschaften der Zieltabelle für die Zieltabellen konfiguriert werden, die mit dem Ziel synchronisiert werden sollen.
Sie können diese Einstellungen im Abschnitt Ausgabeeinstellungen des Workflows zur Integrationserstellung in der AWS Glue Konsole konfigurieren:

Wenn Sie Benutzerdefinierte Partitionsschlüssel angeben auswählen, können Sie Partitionsschlüssel und ihre Funktions- und Konvertierungsspezifikationen konfigurieren:

Wenn sich Quelle und Ziel in demselben Konto befinden, kann diese Konfiguration als Teil des Workflows zur Integrationserstellung über die Benutzeroberfläche der AWS Glue Konsole vorgenommen werden. Befindet sich das Ziel jedoch in einem anderen Konto, muss diese Konfiguration abgeschlossen sein, bevor die Integration erstellt werden kann. Wenn Sie die CLI oder API verwenden, sollte dies vor dem Aufrufen der Create-Integration API erfolgen, auch wenn sich Quelle und Ziel im selben Konto befinden. AWS Glue Die Konsolen-Benutzeroberfläche kapselt nur diesen API-Aufruf für dasselbe Kontenszenario.
Wenn dies nicht konfiguriert ist, werden beim Synchronisieren der Tabelle Standardwerte verwendet. Diese Konfiguration kann auch jederzeit nach der Erstellung der Integration geändert werden.
Anmerkung
Wenn diese Eigenschaft nach der Erstellung der Integration aktualisiert wird, kann dies zu einer vollständigen Resynchronisierung der Tabelle führen, wenn die aktualisierte Konfiguration mit der vorhandenen Konfiguration in Konflikt steht. Zum Beispiel die Aktualisierung der Tabelle, bei der die Verschachtelung aufgehoben wird, von '' auf No-Unnest 'Full-Unnest' oder das Ändern der Partitionsspalte.
Verwenden von CLI oder API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
Nachdem Sie die Lakehouse-Architektur von Amazon SageMaker mit dem allgemeinen Amazon S3 S3-Bucket-Speicher konfiguriert haben, können Sie mit Konfigurieren der Integration mit Ihrem Ziel dem Abschluss der Integrationseinrichtung fortfahren.
Konfiguration eines Amazon S3 Tables-Bucket-Ziels
In diesem Abschnitt werden die Voraussetzungen und Einrichtungsschritte für die Konfiguration von Amazon S3 S3-Tabellen als Ziel für Ihre Zero-ETL-Integration unter Verwendung der Lakehouse-Architektur von Amazon beschrieben. SageMaker
Bevor Sie eine Null-ETL-Integration mit Amazon S3 Tables als Ziel erstellen, müssen Sie die folgenden Einrichtungsschritte durchführen:
Amazon S3 S3-Tabellen, Bucket (und Integration von Analysediensten) einrichten
Geben Sie die RBAC-Richtlinie für den Katalog an.
Erstellen einer IAM-Zielrolle
Ordnen Sie die Zielrolle, KMS (optional) und Verbindung (optional) der Zielressource zu
(Optional) Konfigurieren Sie die Eigenschaften der Zieltabelle
Amazon S3 S3-Tabellen-Bucket einrichten (mit Integration von Analysediensten)
Erstellen Sie einen Amazon-S3-Tables-Bucket in Ihrem Konto, indem Sie den Anweisungen unter Erste Schritte mit Amazon S3 Tables folgen.
Aktivieren Sie Analytics-Integrationen mit Ihrem S3-Table Bucket, indem Sie diese Anweisungen befolgen: AWS Services in Amazon S3 S3-Tabellen integrieren.
Dadurch wird ein neuer S3-Table Katalog in AWS Lake Formation erstellt.
Geben Sie die RBAC-Richtlinie für den Katalog an.
Die folgenden Berechtigungen müssen der RBAC-Richtlinie für den Katalog hinzugefügt werden, um Integrationen zwischen der Quelle und dem Amazon-S3-Tables-Katalogziel zu ermöglichen.
Die Ressourcenrichtlinie für den AWS Glue Zielkatalog muss AWS Glue Serviceberechtigungen für enthalten. AuthorizeInboundIntegration Darüber hinaus sind CreateInboundIntegration Berechtigungen entweder für den Quellprinzipal, der die Integration erstellt, oder für die AWS Glue Zielressourcenrichtlinie erforderlich.
Anmerkung
Für ein kontenübergreifendes Szenario müssen sowohl die Quellprinzipal- als auch die AWS Glue Zielkatalog-Ressourcenrichtlinie glue:CreateInboundIntegration Berechtigungen für die Ressource enthalten.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Anmerkung
s3tablescatalogs3tablescatalog.
Erstellen einer IAM-Zielrolle
Erstellen Sie eine IAM-Zielrolle mit den folgenden Berechtigungen und Vertrauensstellungen:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Fügen Sie der IAM-Zielrolle die folgende Vertrauensrichtlinie hinzu, damit der AWS Glue Service sie übernehmen kann:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Anmerkung
Stellen Sie sicher, dass es in der S3-Tables Bucket-Ressourcenrichtlinie keine explizite DENY-Anweisung für diese IAM-Zielrolle gibt. Eine explizite DENY-Anweisung würde alle ALLOW-Berechtigungen außer Kraft setzen und verhindern, dass die Integration ordnungsgemäß funktioniert.
Ordnen Sie die Zielrolle, KMS (optional) und Connection (optional) der Zielressource zu
Ordnen Sie die obige Zielrolle der Zielressource zu. Optional können KMS für die Verschlüsselung der Daten vor dem Speichern in der Ziel-Iceberg-Tabelle und der Verbindungs-ARN für den Zugriff auf den Ziel-S3-Bucket konfiguriert werden. Wenn der Ziel-S3-Bucket so konfiguriert ist, dass er über eine bestimmte VPC zugänglich ist, kann der Verbindungs-ARN zugeordnet werden, damit die Verarbeitung innerhalb dieser VPC ausgeführt werden kann. AWS Glue Weitere Informationen zum Einrichten einer VPC finden Sie unter Erstellen einer VPC.
Verwenden der AWS Glue CLI//API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(Optional) Konfigurieren Sie die Eigenschaften der Zieltabelle
Optional können die Eigenschaften der Zieltabelle für die Zieltabellen konfiguriert werden, die mit dem Ziel synchronisiert werden sollen. Es gelten dieselben Regeln wie im Abschnitt S3-Ziel für allgemeine Zwecke beschrieben.
Verwenden von CLI oder API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
Nachdem Sie den S3-Tables Amazon-Speicher mithilfe der Lakehouse-Architektur von Amazon konfiguriert haben SageMaker, können Sie mit Konfigurieren der Integration mit Ihrem Ziel dem Abschluss der Integrationseinrichtung fortfahren.
Konfiguration eines Amazon Redshift Verwaltetes Speicherziel
In diesem Abschnitt werden die Voraussetzungen und Einrichtungsschritte für die Konfiguration eines Amazon Redshift verwalteten Speichers (RMS) als Ziel für Ihre Zero-ETL-Integration unter Verwendung der Lakehouse-Architektur von Amazon beschrieben. SageMaker
Bevor Sie eine Zero-ETL-Integration mit einer Lakehouse-Architektur von Amazon SageMaker mithilfe von Redshift Managed Storage erstellen, müssen Sie die folgenden Einrichtungsaufgaben ausführen:
Richten Sie einen Cluster oder eine serverlose Arbeitsgruppe ein Amazon Redshift
Registrieren Sie die Amazon Redshift Integration mit Lake Formation
Erstellen Sie einen verwalteten Katalog in Lake Formation.
Konfigurieren Sie die IAM-Berechtigungen.
Einrichtung Amazon Redshift verwalteter Speicher
So richten Sie Amazon Redshift verwalteten Speicher für Ihre Zero-ETL-Integration ein:
Erstellen oder verwenden Sie einen vorhandenen Amazon Redshift Cluster oder eine serverlose Arbeitsgruppe. Stellen Sie sicher, dass in der Amazon Redshift Zielarbeitsgruppe oder dem Zielcluster der
enable_case_sensitive_identifierParameter aktiviert ist, damit die Integration erfolgreich ist. Weitere Informationen zur Aktivierung der Groß- und Kleinschreibung finden Sie unter Aktivieren der Groß- und Kleinschreibung für Ihr Data Warehouse im Amazon Redshift Verwaltungsleitfaden.Registrieren Sie eine Integration von Redshift in den Katalog in AWS Lake Formation. Siehe Registrieren von Amazon Redshift Clustern und Namespaces im Datenkatalog.
Erstellen Sie einen föderierten oder verwalteten Katalog in. AWS Lake Formation Weitere Informationen finden Sie unter:
Konfigurieren Sie IAM-Berechtigungen für die Zielrolle. Die Rolle benötigt Berechtigungen für den Zugriff auf Redshift- und Lake-Formation-Ressourcen. Die Rolle sollte mindestens Folgendes aufweisen:
Berechtigungen für den Zugriff auf den Redshift-Cluster oder die Arbeitsgruppe
Berechtigungen für den Zugriff auf den Lake-Formation-Katalog
Berechtigungen zum Erstellen von Tabellen und Verwalten von Tabellen im Katalog
CloudWatch und CloudWatch protokolliert Berechtigungen für die Überwachung
Nachdem Sie den Amazon SageMaker Lakehouse-Katalog mit Amazon Redshift verwaltetem Speicher konfiguriert haben, können Sie mit Konfigurieren der Integration mit Ihrem Ziel dem Abschluss der Integrationseinrichtung fortfahren.
Konfiguration eines Amazon Redshift Data Warehouse-Ziel
In diesem Abschnitt werden die Voraussetzungen und Einrichtungsschritte für die Konfiguration eines Amazon Redshift Data Warehouse als Ziel für Ihre Zero-ETL-Integration beschrieben.
Bevor Sie eine Zero-ETL-Integration mit einem Amazon Redshift Data Warehouse-Ziel erstellen, müssen Sie die folgenden Einrichtungsaufgaben ausführen:
Richten Sie einen Amazon Redshift Cluster oder eine serverlose Arbeitsgruppe ein
Richten Sie die Unterscheidung zwischen Groß- und Kleinschreibung ein.
Konfigurieren Sie die IAM-Berechtigungen.
Einrichtung des Amazon Redshift Data Warehouse
So richten Sie ein Amazon Redshift Data Warehouse für Ihre Zero-ETL-Integration ein:
Navigieren Sie zur Amazon Redshift -Konsole
und klicken Sie auf Cluster erstellen oder verwenden Sie einen vorhandenen Cluster. Informationen zum Erstellen eines Amazon Redshift Clusters finden Sie unter Cluster erstellen. Für eine Amazon-Redshift-Serverless-Arbeitsgruppe klicken Sie auf Arbeitsgruppe erstellen. Informationen zum Erstellen einer Amazon-Redshift-Serverless-Arbeitsgruppe unter Erstellen einer Arbeitsgruppe mit einem Namespace. Wenn Sie einen neuen Cluster erstellen, wählen Sie eine geeignete Clustergröße und stellen Sie sicher, dass Ihr Cluster verschlüsselt ist. Konfigurieren Sie für Serverless die Arbeitsgruppeneinstellungen entsprechend Ihren Anforderungen.
Stellen Sie sicher, dass in der Amazon Redshift Zielarbeitsgruppe oder dem Zielcluster der
enable_case_sensitive_identifierParameter aktiviert ist, damit die Integration erfolgreich ist. Weitere Informationen zum Aktivieren der Unterscheidung zwischen Groß- und Kleinschreibung finden Sie unter Aktivieren der Unterscheidung zwischen Groß- und Kleinschreibung für Ihr Data Warehouse im Amazon-Redshift-Managementleitfaden.Konfigurieren Sie IAM-Berechtigungen, damit die Zero-ETL-Integration auf Ihr Data Warehouse zugreifen kann. Amazon Redshift Sie müssen eine IAM-Rolle mit den folgenden Berechtigungen erstellen:
Berechtigungen für den Zugriff auf den Cluster oder die Arbeitsgruppe Amazon Redshift
Berechtigungen zum Erstellen und Verwalten von Datenbanken und Tabellen in Amazon Redshift
CloudWatch und CloudWatch protokolliert Berechtigungen für die Überwachung
Nachdem die Amazon Redshift Arbeitsgruppen- oder Clustereinrichtung abgeschlossen ist, müssen Sie Ihr Data Warehouse für Zero-ETL-Integrationen konfigurieren. Weitere Informationen finden Sie im Amazon–Redshift-Managementleitfaden unter Erste Schritte mit Null-ETL-Integrationen.
Anmerkung
Wenn Sie ein Amazon Redshift Data Warehouse als Ziel verwenden, erstellt die Integration ein Schema in der angegebenen Datenbank, um die replizierten Daten zu speichern. Der Schemaname wird vom Integrationsnamen abgeleitet.
Anmerkung
Für die Amazon Redshift Zielarbeitsgruppe oder den Zielcluster muss der enable_case_sensitive_identifier Parameter aktiviert sein, damit die Integration erfolgreich ist.
Nach der Konfiguration des Amazon Redshift Data Warehouse können Sie mit Konfigurieren der Integration mit Ihrem Ziel dem Abschluss der Integrationseinrichtung fortfahren.
Konfigurieren der Integration mit Ihrem Ziel
Gehen Sie nach der Konfiguration der Quell- und Zielressourcen wie folgt vor, um das Integrations-Setup abzuschließen:
Navigieren Sie zur Seite „Zero-ETL Integrationen“ und starten Sie den Workflow zur Integrationserstellung.
Wählen Sie die in den vorherigen Schritten konfigurierte Quellressource aus.
Wählen Sie die in den vorherigen Schritten konfigurierte Zielressource (gleiches Konto oder kontoübergreifende Ressource) aus, oder geben Sie sie an.
Wählen Sie die zuvor konfigurierte IAM-Zielrolle aus.
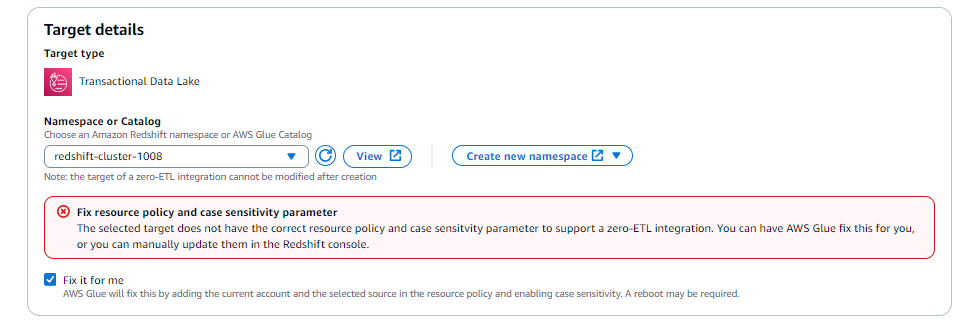
Wählen Sie die Option Fix it for me (nur verfügbar, wenn sich das Ziel im selben Konto befindet).
Für das reguläre Amazon S3 S3-Ziel S3-Table (AWS Glue Datenbank) und (Katalog) bedeutet dies:
Wenden Sie einen autorisierten Service Principal auf die Ressourcenrichtlinie des Zielkatalogs an.
Wenden Sie einen autorisierten AWS Glue Quellprinzipal-ARN auf die Zielkatalog-Ressourcenrichtlinie an.
Für das Amazon Redshift Ziel bedeutet dies:
Wenden Sie einen autorisierten Dienstprinzipal auf den Amazon Redshift Cluster oder die serverlose Arbeitsgruppe an.
Wenden Sie einen autorisierten AWS Glue Quell-ARN auf den Amazon Redshift Cluster oder die serverlose Arbeitsgruppe an.
Verknüpfen Sie eine neue Parametergruppe mit
enable_case_sensitive_identifier = true.
Verwenden Sie Folgendes, um die Integration über API oder CLI zu erstellen: CreateIntegration API.
