Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Generative KI-Upgrades für Apache Spark in AWS Glue
Mit Spark-Upgrades in AWS Glue können Dateningenieure und Entwickler ihre bestehenden AWS Glue Spark-Jobs mithilfe generativer KI auf die neuesten Spark-Versionen aktualisieren und migrieren. Dateningenieure können damit ihre AWS Glue Spark-Jobs scannen, Upgrade-Pläne erstellen, Pläne ausführen und Ergebnisse validieren. Dies reduziert den Zeit- und Kostenaufwand für Spark-Upgrades, indem die undifferenzierte Arbeit der Identifizierung und Aktualisierung von Spark-Skripten, Konfigurationen, Abhängigkeiten, Methoden und Features automatisiert wird.

Funktionsweise
Wenn Sie die Upgrade-Analyse verwenden, identifiziert AWS Glue Unterschiede zwischen Versionen und Konfigurationen im Code Ihres Jobs, um einen Upgrade-Plan zu generieren. Der Upgrade-Plan beschreibt alle Codeänderungen und die erforderlichen Migrationsschritte. Als Nächstes erstellt AWS Glue die aktualisierte Anwendung und führt sie in einer Umgebung aus, um Änderungen zu validieren, und generiert eine Liste mit Codeänderungen, damit Sie Ihren Job migrieren können. Sie können sich das aktualisierte Skript zusammen mit der Zusammenfassung ansehen, in der die vorgeschlagenen Änderungen detailliert beschrieben werden. Nachdem Sie Ihre eigenen Tests ausgeführt haben, akzeptieren Sie die Änderungen und der AWS Glue-Job wird automatisch mit dem neuen Skript auf die neueste Version aktualisiert.
Der Upgrade-Analyseprozess kann, abhängig von der Komplexität des Auftrags und dem Workload, einige Zeit in Anspruch nehmen. Die Ergebnisse der Upgrade-Analyse werden im angegebenen Amazon-S3-Pfad gespeichert und können dort eingesehen werden, um das Upgrade und mögliche Kompatibilitätsprobleme zu verstehen. Nachdem Sie die Ergebnisse der Upgrade-Analyse überprüft haben, können Sie entscheiden, ob Sie mit dem eigentlichen Upgrade fortfahren oder vor dem Upgrade noch erforderliche Änderungen am Auftrag vornehmen möchten.
Voraussetzungen
Die folgenden Voraussetzungen sind erforderlich, um generative KI zum Upgrade von Jobs in AWS Glue zu verwenden:
-
AWS Glue 2 PySpark Jobs — Nur AWS Glue 2-Jobs können auf AWS Glue 5 aktualisiert werden.
-
IAM-Berechtigungen sind erforderlich, um die Analyse zu starten, die Ergebnisse zu überprüfen und den Auftrag zu aktualisieren. Weitere Informationen finden Sie in den Beispielen im Berechtigungen-Abschnitt unten.
-
Bei Verwendung AWS KMS zur Verschlüsselung von Analyseartefakten sind zusätzliche AWS AWS KMS Berechtigungen erforderlich. Weitere Informationen finden Sie in den Beispielen im AWS KMS policy-Abschnitt unten.
Berechtigungen
-
Aktualisieren Sie die IAM-Richtlinie des Aufrufers mit der folgenden Berechtigung:
-
Aktualisieren Sie die Ausführungsrolle des Auftrags, den Sie aktualisieren, sodass sie die folgende Inline-Richtlinie enthält:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }Wenn Sie beispielsweise den Amazon-S3-Pfad
s3://amzn-s3-demo-bucket/upgraded-resultverwenden, lautet die Richtlinie wie folgt:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMS policy
Um beim Starten einer Analyse Ihren eigenen benutzerdefinierten AWS KMS Schlüssel zu übergeben, lesen Sie bitte den folgenden Abschnitt, um die entsprechenden Berechtigungen für die AWS KMS Schlüssel zu konfigurieren.
Diese Richtlinie stellt sicher, dass Sie sowohl über die Verschlüsselungs- als auch über die Entschlüsselungsberechtigungen für den AWS KMS Schlüssel verfügen.
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Ausführen einer Upgrade-Analyse und Anwenden des Upgrade-Skripts
Sie können eine Upgrade-Analyse ausführen, die einen Upgrade-Plan für einen Auftrag generiert, den Sie in der Ansicht Aufträge auswählen.
-
Wählen Sie unter Jobs einen AWS Glue 2.0-Job aus und wählen Sie dann im Menü Aktionen die Option Upgrade-Analyse ausführen aus.
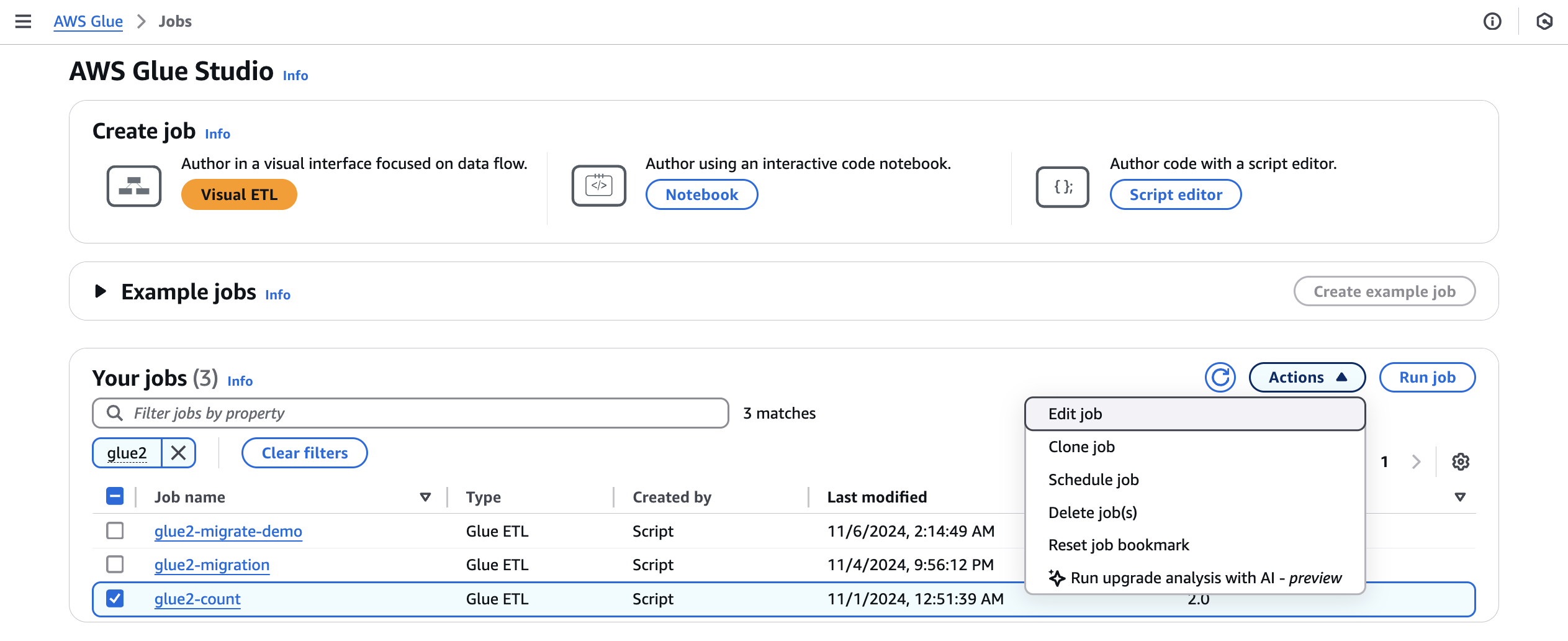
-
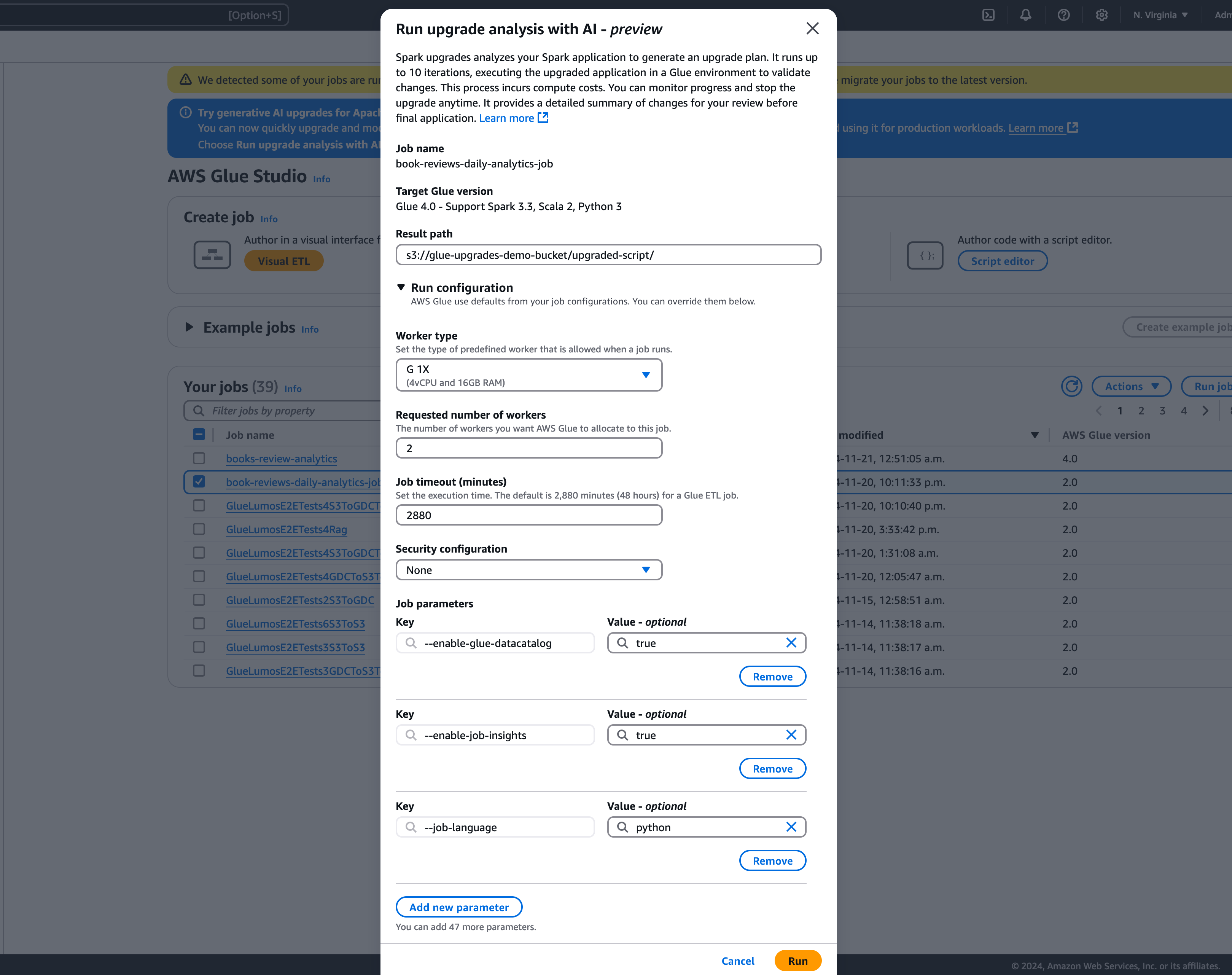
Wählen Sie im Modal einen Pfad zum Speichern Ihres generierten Upgrade-Plans im Ergebnispfad aus. Es muss sich um einen Amazon-S3-Bucket handeln, auf den Sie zugreifen und in den Sie schreiben können.
-
Konfigurieren Sie bei Bedarf die folgenden zusätzlichen Optionen:
-
Run-Konfiguration – optional: Die Run-Konfiguration ist eine optionale Einstellung, mit der Sie verschiedene Aspekte der während der Upgrade-Analyse durchgeführten Validierungsläufe anpassen können. Diese Konfiguration wird zur Ausführung des aktualisierten Skripts verwendet und ermöglicht Ihnen die Auswahl der Eigenschaften der Rechenumgebung (Workertyp, Anzahl der Worker usw.). Beachten Sie, dass Sie Ihre Entwicklerkonten, die nicht für die Produktion bestimmt sind, verwenden sollten, um die Validierungen an Beispieldatensätzen durchzuführen, bevor Sie die Änderungen überprüfen, akzeptieren und auf Produktionsumgebungen anwenden. Die Run-Konfiguration umfasst die folgenden anpassbaren Parameter:
-
Workertyp: Sie können den Workertyp angeben, der für die Validierungsläufe verwendet werden soll, sodass Sie je nach Ihren Anforderungen die geeigneten Rechenressourcen auswählen können.
-
Anzahl der Worker: Sie können die Anzahl der Worker definieren, die für die Validierungsläufe bereitgestellt werden sollen, sodass Sie die Ressourcen entsprechend Ihren Workload-Anforderungen skalieren können.
-
Auftrags-Timeout (in Minuten): Mit diesem Parameter können Sie ein Zeitlimit für die Validierungsläufe festlegen und so sicherstellen, dass die Aufträge nach einer bestimmten Dauer beendet werden, um einen übermäßigen Ressourcenverbrauch zu vermeiden.
-
Sicherheitskonfiguration: Sie können Sicherheitseinstellungen wie Verschlüsselung und Zugriffskontrolle konfigurieren, um den Schutz Ihrer Daten und Ressourcen während der Validierungsläufe zu gewährleisten.
-
Zusätzliche Auftragsparameter: Bei Bedarf können Sie neue Auftragsparameter hinzufügen, um die Ausführungsumgebung für die Validierungsläufe weiter anzupassen.
Durch die Nutzung der Run-Konfiguration können Sie die Validierungsläufe an Ihre spezifischen Anforderungen anpassen. Sie können die Validierungsläufe beispielsweise so konfigurieren, dass ein kleinerer Datensatz verwendet wird, wodurch die Analyse schneller abgeschlossen wird und die Kosten optimiert werden. Dieser Ansatz stellt sicher, dass die Upgrade-Analyse effizient durchgeführt wird und gleichzeitig die Ressourcenauslastung und die damit verbundenen Kosten während der Validierungsphase minimiert werden.
-
-
Verschlüsselungskonfiguration – optional:
-
Verschlüsselung von Upgrade-Artefakten aktivieren: Aktiviert die Verschlüsselung im Ruhezustand, wenn Daten in den Ergebnispfad geschrieben werden. Wenn Sie keine Verschlüsselung Ihrer Upgrade-Artefakte wünschen, aktivieren Sie diese Option nicht.
-
-
-
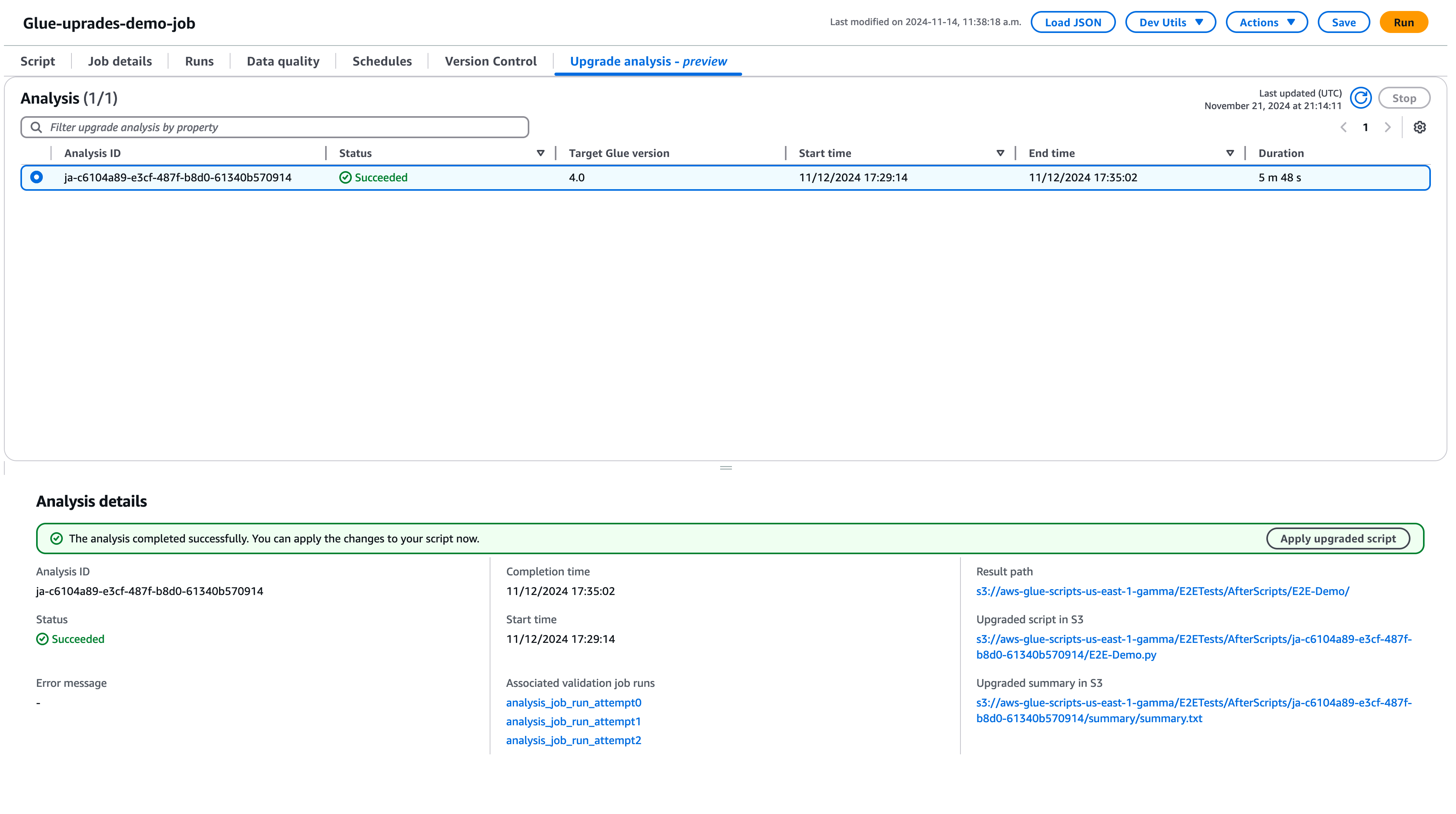
Wählen Sie Ausführen, um die Upgrade-Analyse zu starten. Während die Analyse ausgeführt wird, können Sie die Ergebnisse auf der Registerkarte Upgrade-Analyse anzeigen. Im Fenster mit den Analysedetails werden Informationen zur Analyse sowie Links zu den Upgrade-Artefakten angezeigt.
-
Ergebnispfad – hier werden die Zusammenfassung der Ergebnisse und das Upgrade-Skript gespeichert.
-
Aktualisiertes Skript in Amazon S3 – der Speicherort des Upgrade-Skripts in Amazon S3. Sie können sich das Skript anzeigen lassen, bevor Sie das Upgrade anwenden.
-
Upgrade-Zusammenfassung in Amazon S3 – der Speicherort der Upgrade-Zusammenfassung in Amazon S3. Sie können sich die Upgrade-Zusammenfassung anzeigen lassen, bevor Sie das Upgrade anwenden.
-
-
Wenn die Upgrade-Analyse erfolgreich abgeschlossen wurde, können Sie das Upgrade-Skript anwenden, um Ihren Auftrag automatisch zu aktualisieren, indem Sie Aktualisiertes Skript anwenden wählen.
Nach der Anwendung wird die AWS Glue-Version auf 4.0 aktualisiert. Sie finden das neue Skript auf der Registerkarte Skript.
Grundlegendes zu Ihrer Upgrade-Zusammenfassung
Dieses Beispiel zeigt, wie ein AWS Glue-Job von Version 2.0 auf Version 4.0 aktualisiert wird. Der Beispielauftrag liest Produktdaten aus einem Amazon-S3-Bucket, wendet mithilfe von Spark SQL mehrere Transformationen auf die Daten an und speichert dann die transformierten Ergebnisse wieder in einem Amazon-S3-Bucket.
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

Basierend auf der Zusammenfassung werden von AWS Glue vier Änderungen vorgeschlagen, um das Skript erfolgreich von AWS Glue 2.0 auf Glue 4.0 zu AWS aktualisieren:
-
Spark-SQL-Konfiguration (spark.sql.adaptive.enabled): Diese Änderung dient dazu, das Anwendungsverhalten wiederherzustellen, da mit Spark 3.2 ein neues Feature für die adaptive Abfrageausführung von Spark SQL eingeführt wurde. Sie können diese Konfigurationsänderung überprüfen und sie je nach Wunsch weiter aktivieren oder deaktivieren.
-
DataFrame API-Änderung: Die Pfadoption kann nicht zusammen mit anderen DataFrameReader Vorgängen wie
load()existieren. Um das vorherige Verhalten beizubehalten, hat AWS Glue das Skript aktualisiert und eine neue SQL-Konfiguration hinzugefügt (OptionBehavior.enabledspark.sql.legacy.path). -
Änderung der Spark-SQL-API: Das Verhalten von
strfmtinformat_string(strfmt, obj, ...)wurde aktualisiert, sodass0$nicht mehr als erstes Argument zulässig ist. Um die Kompatibilität zu gewährleisten, hat AWS Glue das Skript so geändert, dass es stattdessen1$als erstes Argument verwendet wird. -
Änderung der Spark-SQL-API: Die
unbase64-Funktion erlaubt keine fehlerhaften Zeichenketteneingaben. Um das vorherige Verhalten beizubehalten, hat AWS Glue das Skript aktualisiert, um dietry_to_binaryFunktion zu verwenden.
Beenden einer laufenden Upgrade-Analyse
Sie können eine laufende Upgrade-Analyse abbrechen oder die Analyse einfach beenden.
-
Wählen Sie die Registerkarte Upgrade-Analyse aus.
-
Wählen Sie den Auftrag aus, der gerade ausgeführt wird, und klicken Sie dann auf Beenden. Dadurch wird die Analyse beendet. Anschließend können Sie eine weitere Upgrade-Analyse für denselben Auftrag ausführen.

Überlegungen
Wenn Sie mit der Nutzung von Spark Upgrades beginnen, müssen Sie mehrere wichtige Aspekte berücksichtigen, um den Service optimal nutzen zu können.
-
Serviceumfang und Einschränkungen: Die aktuelle Version konzentriert sich auf PySpark Code-Upgrades von AWS Glue-Versionen 2.0 auf Version 5.0. Derzeit verarbeitet der Service PySpark Code, der nicht auf zusätzlichen Bibliotheksabhängigkeiten angewiesen ist. Sie können automatisierte Upgrades für bis zu 10 Jobs gleichzeitig in einem AWS Konto ausführen, sodass Sie mehrere Jobs effizient aktualisieren und gleichzeitig die Systemstabilität aufrechterhalten können.
-
Es werden nur PySpark Jobs unterstützt.
-
Für die Upgrade-Analyse tritt nach 24 Stunden ein Timeout auf.
-
Für einen Auftrag kann jeweils nur eine aktive Upgrade-Analyse ausgeführt werden. Auf Kontoebene können bis zu 10 aktive Upgrade-Analysen gleichzeitig ausgeführt werden.
-
-
Optimierung der Kosten während des Upgrade-Prozesses: Da Spark-Upgrades generative KI verwenden, um den Upgrade-Plan über mehrere Iterationen hinweg zu validieren, wobei jede Iteration als AWS Glue-Job in Ihrem Konto ausgeführt wird, ist es wichtig, die Konfigurationen der Validierungsjob-Ausführung aus Kostengründen zu optimieren. Um dies zu erreichen, empfehlen wir, beim Start einer Upgrade-Analyse eine Run-Konfiguration wie folgt anzugeben:
-
Verwenden Sie Entwicklerkonten, die nicht zur Produktion bestimmt sind, und wählen Sie für die Validierung mit Spark-Upgrades Beispieldatensätze aus, die Ihre Produktionsdaten repräsentieren, aber kleiner sind.
-
Verwenden Sie Rechenressourcen mit der richtigen Größe, wie z. B. G.1X Arbeitskräften, und wählen Sie eine angemessene Anzahl von Mitarbeitern für die Verarbeitung Ihrer Beispieldaten aus.
-
Aktivieren AWS Sie gegebenenfalls die auto-scaling von Glue-Jobs, um Ressourcen automatisch an die Arbeitslast anzupassen.
Wenn Ihr Produktionsjob beispielsweise Terabyte an Daten mit 20 G.2X Mitarbeitern verarbeitet, können Sie den Upgrade-Job so konfigurieren, dass er einige Gigabyte repräsentativer Daten mit 2 G.2X Workern verarbeitet und die auto-scaling für die Validierung aktiviert ist.
-
-
Bewährte Methoden: Wir empfehlen dringend, Ihr Upgrade mit Aufträgen zu beginnen, die nichts mit der Produktion zu tun haben. Dieser Ansatz ermöglicht es Ihnen, sich mit dem Upgrade-Workflow vertraut zu machen und zu verstehen, wie der Dienst mit verschiedenen Arten von Spark-Codemustern umgeht.
-
Alarme und Benachrichtigungen: Wenn Sie die Generative AI-Upgrade-Funktion alarms/notifications für einen Job verwenden, stellen Sie sicher, dass die Ausführung bei fehlgeschlagenen Jobs ausgeschaltet ist. Während des Upgrade-Vorgangs können in Ihrem Konto bis zu 10 fehlgeschlagene Auftragsausführungen auftreten, bevor die aktualisierten Artefakte bereitgestellt werden.
-
Regeln zur Erkennung von Anomalien: Deaktivieren Sie alle Regeln zur Erkennung von Anomalien für den Auftrag, der ebenfalls aktualisiert wird, da die während der Zwischenausführung des Auftrags in die Ausgabeordner geschriebenen Daten möglicherweise nicht das erwartete Format haben, während die Aktualisierungsvalidierung durchgeführt wird.
-
Verwenden Sie die Upgrade-Analyse für idempotente Aufträge: Verwenden Sie die Upgrade-Analyse für idempotente Aufträge, um sicherzustellen, dass jeder nachfolgende Ausführungsversuch eines Validierungsauftrags dem vorherigen ähnelt und keine Probleme auftreten. Bei idempotenten Aufträgen handelt es sich um Aufträge, die mehrfach mit denselben Eingabedaten ausgeführt werden können und jedes Mal dieselbe Ausgabe erzeugen. Wenn Sie die Generative AI-Upgrades für Apache Spark in AWS Glue verwenden, führt der Service im Rahmen des Validierungsprozesses mehrere Iterationen Ihres Jobs aus. Bei jeder Iteration werden Änderungen an Ihrem Spark-Code und Ihren Konfigurationen vorgenommen, um den Upgrade-Plan zu validieren. Wenn Ihr Spark-Auftrag nicht idempotent ist, können Probleme auftreten, wenn Sie ihn mehrmals mit denselben Eingabedaten ausführen.
Unterstützte -Regionen
Generative KI-Upgrades für Apache Spark sind in den folgenden Regionen verfügbar:
-
Asien-Pazifik: Tokio (ap-northeast-1), Seoul (ap-northeast-2), Mumbai (ap-south-1), Singapur (ap-southeast-1) und Sydney (ap-southeast-2)
-
Nordamerika: Kanada (ca-central-1)
-
Europa: Frankfurt (eu-central-1), Stockholm (eu-nord-1), Irland (eu-west-1), London (eu-west-2) und Paris (eu-west-3)
-
Südamerika: São Paulo (sa-east-1)
-
Vereinigte Staaten: Nord-Virginia (us-east-1), Ohio (us-east-2) und Oregon (US-West-2)
Cross-region Inferenz bei Spark-Upgrades
Spark Upgrades basiert auf regionsübergreifender Inferenz (CRIS) Amazon Bedrock und nutzt diese. Mit CRIS werden von Spark-Upgrades automatisch die optimale Region innerhalb Ihrer geografischen Umgebung ausgewählt (wie hier näher beschrieben), um Ihre Inferenzanforderung zu verarbeiten, die verfügbaren Rechenressourcen und die Modellverfügbarkeit zu maximieren und das beste Kundenerlebnis zu bieten. Für die Nutzung von regionsübergreifender Inferenz fallen keine zusätzlichen Kosten an.
Cross-region Inferenzanfragen werden in den AWS Regionen gespeichert, die Teil der Region sind, in der sich die Daten ursprünglich befinden. Beispielsweise wird eine in den USA gestellte Anfrage in den AWS Regionen der USA aufbewahrt. Obwohl die Daten nur in der Hauptregion gespeichert bleiben, können sich Ihre Prompts und Ausgabeergebnisse bei Verwendung der regionsübergreifenden Inferenz möglicherweise außerhalb Ihrer Hauptregion bewegen. Alle Daten werden bei der Übertragung über das sichere Netzwerk von Amazon verschlüsselt.
