Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Generative KI-Fehlerbehebung für Apache Spark in AWS Glue
Generative KI-Fehlerbehebung für Apache Spark-Jobs in AWS Glue ist eine neue Funktion, mit der Dateningenieure und Wissenschaftler Probleme in ihren Spark-Anwendungen mühelos diagnostizieren und beheben können. Mithilfe von Machine Learning und Technologien für generative KI analysiert dieses Feature Probleme in Spark-Aufträgen und bietet eine detaillierte Ursachenanalyse sowie umsetzbare Empfehlungen zur Lösung dieser Probleme. Die generative KI-Fehlerbehebung für Apache Spark ist für Jobs verfügbar, die auf AWS Glue Version 4.0 und höher ausgeführt werden.
|
Transformieren Sie Ihre Apache Spark-Fehlerbehebung mit unserem KI-gestützten Troubleshooting-Agenten, der jetzt alle wichtigen Bereitstellungsmodi unterstützt, darunter AWS Glue, Amazon EMR-EC2, Amazon EMR-Serverless und Amazon AI Notebooks. SageMaker Dieser leistungsstarke Agent macht komplexe Debugging-Prozesse überflüssig, indem er Interaktionen in natürlicher Sprache, Workload-Analysen in Echtzeit und intelligente Codeempfehlungen zu einem nahtlosen Erlebnis kombiniert. Einzelheiten zur Implementierung finden Sie unter Was ist der Apache Spark Troubleshooting Agent for Amazon EMR. Sehen Sie sich die zweite Demonstration unter Beispiele zur Fehlerbehebung mit dem Troubleshooting-Agenten für AWS Glue an. |
Wie funktioniert die Fehlerbehebung mit generativer KI für Apache Spark?
Für Ihre fehlgeschlagenen Spark-Jobs analysiert Generative AI Troubleshooting die Job-Metadaten und die genauen Metriken und Protokolle, die mit der Fehlersignatur Ihres Jobs verknüpft sind, um eine Ursachenanalyse zu erstellen, und empfiehlt spezifische Lösungen und bewährte Methoden zur Behebung von Jobfehlern.
Einrichten der Fehlerbehebung mit generativer KI für Apache Spark für Ihre Aufträge
Konfigurieren von IAM-Berechtigungen
Um Benutzern, die von Spark Troubleshooting für Ihre Jobs in AWS Glue APIs verwendet werden, Berechtigungen zu gewähren, sind entsprechende IAM-Berechtigungen erforderlich. Sie können Berechtigungen erhalten, indem Sie Ihrer IAM-Identität (z. B. einem Benutzer, einer Rolle oder einer Gruppe) die folgende benutzerdefinierte AWS Richtlinie zuordnen.
Anmerkung
Die folgenden beiden APIs werden in der IAM-Richtlinie verwendet, um diese Erfahrung über die AWS Glue Studio-Konsole zu aktivieren: StartCompletion undGetCompletion.
Zuweisen von Berechtigungen
Um Zugriff zu gewähren, fügen Sie Ihren Benutzern, Gruppen oder Rollen Berechtigungen hinzu:
-
Für Benutzer und Gruppen in IAM Identity Center: Erstellen Sie einen Berechtigungssatz. Befolgen Sie die Anweisungen unter Erstellen eines Berechtigungssatzes im IAM-Identity-Center-Benutzerhandbuch.
-
Für Benutzer, die in IAM über einen Identitätsanbieter verwaltet werden: Erstellen Sie eine Rolle für den Identitätsverbund. Befolgen Sie die Anweisungen unter Erstellen einer Rolle für einen externen Identitätsanbieter (Verbund) im IAM-Benutzerhandbuch.
-
Für IAM-Benutzer: Erstellen Sie eine Rolle, die Ihr Benutzer annehmen kann. Folgen Sie den Anweisungen unter Erstellen einer Rolle für einen IAM-Benutzer im IAM-Benutzerhandbuch.
Durchführen einer Fehlerbehebungsanalyse von einer fehlgeschlagenen Auftragsausführung
Sie können über mehrere Pfade in der AWS Glue-Konsole auf die Fehlerbehebungsfunktion zugreifen. So machen Sie die ersten Schritte:
Option 1: Von der Seite mit der Auftragsliste
-
Öffnen Sie die AWS Glue-Konsole unter https://console.aws.amazon.com/glue/
. -
Wählen Sie im Navigationsbereich die Option ETL-Aufträge aus.
-
Suchen Sie Ihren fehlgeschlagenen Auftrag in der Auftragsliste.
-
Wählen Sie die Registerkarte Ausführungen im Abschnitt mit den Auftragsdetails.
-
Klicken Sie auf die fehlgeschlagene Auftragsausführung, die Sie analysieren möchten.
-
Wählen Sie Fehlerbehebung mit KI aus, um die Analyse zu starten.
-
Wenn die Analyse zur Fehlerbehebung abgeschlossen ist, können Sie die Ursachenanalyse und die Empfehlungen auf der Registerkarte Fehlerbehebungsanalyse am unteren Bildschirmrand anzeigen.
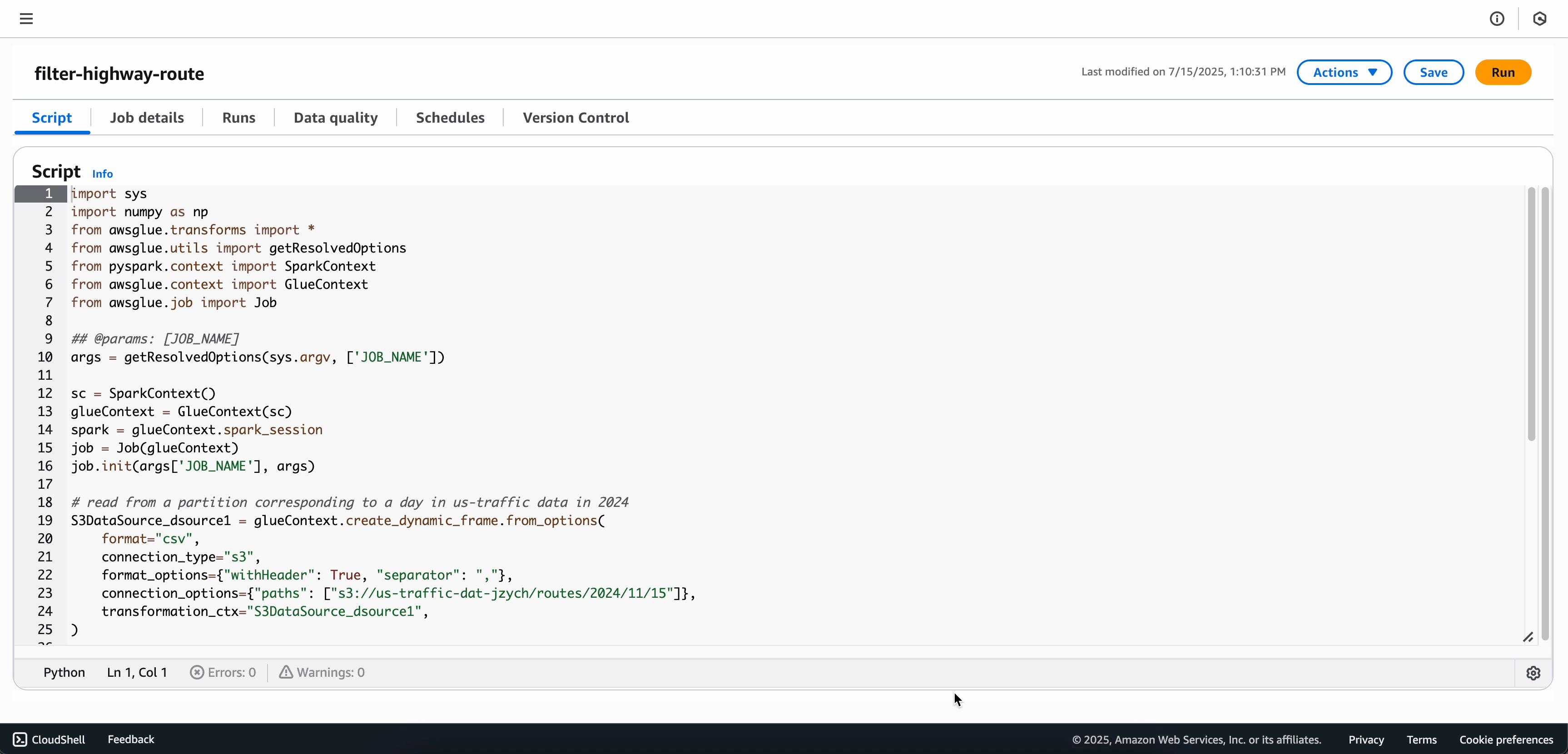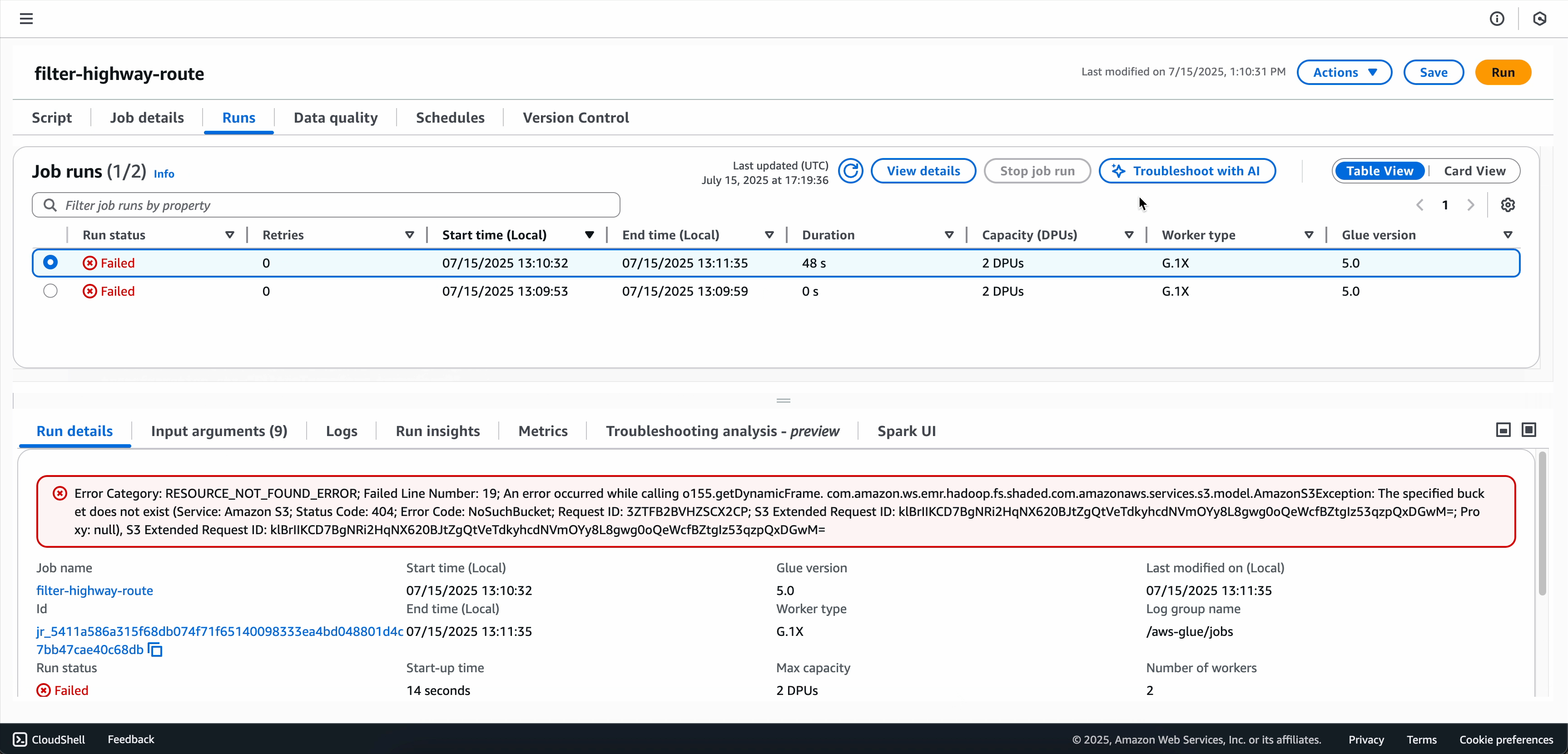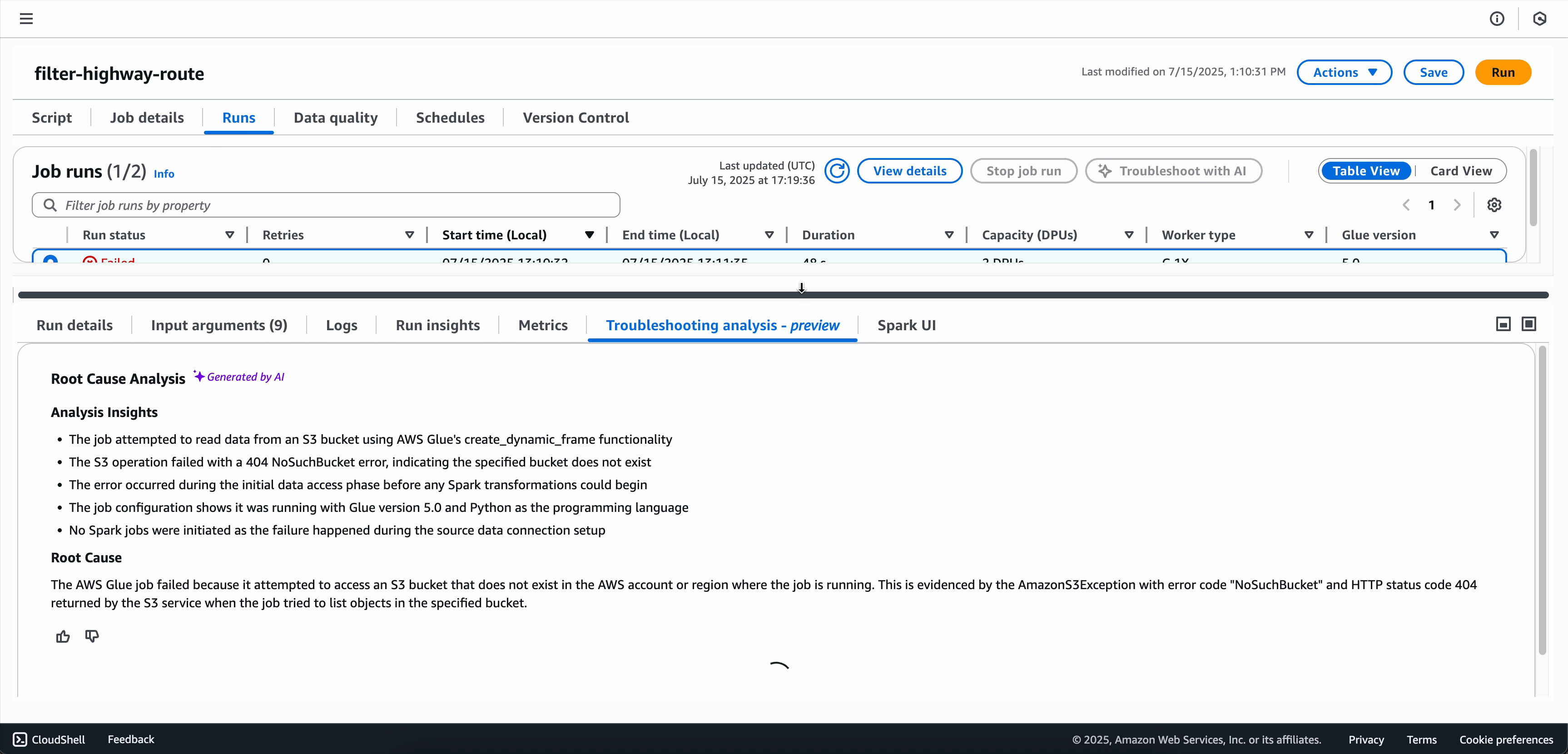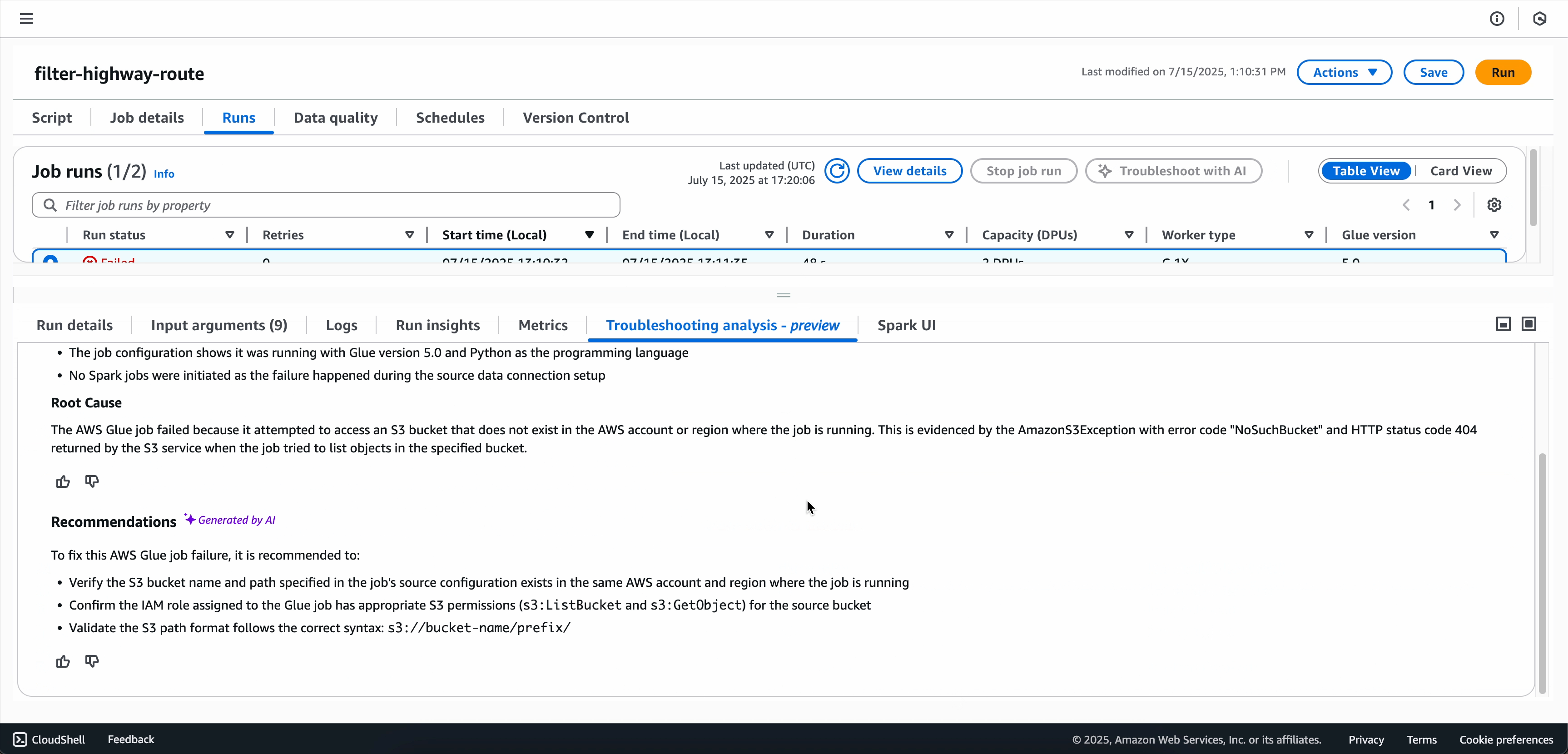
Option 2: Verwenden der Seite „Überwachung der Auftragsausführung“
-
Navigieren Sie zur Seite zur Überwachung der Auftragsausführung.
-
Suchen Sie nach der fehlgeschlagenen Auftragsausführung.
-
Wählen Sie die Dropdown-Liste Aktionen aus.
-
Wählen Sie Problembehandlung mit KI aus.

Option 3: Von der Seite mit den Details der Auftragsausführung
-
Navigieren Sie zur Detailseite der fehlgeschlagenen Auftragsausführung, indem Sie entweder auf der Registerkarte Ausführungen auf Details anzeigen zu einer fehlgeschlagenen Ausführung klicken oder die Auftragsausführung auf der Seite Überwachung der Auftragsausführung auswählen.
-
Suchen Sie auf der Seite mit den Details der Auftragsausführung die Registerkarte Fehlerbehebungsanalyse.
Unterstützte Kategorien zur Fehlerbehebung
Dieser Service konzentriert sich auf drei Hauptkategorien von Problemen, auf die Dateningenieure und Entwickler in ihren Spark-Anwendungen häufig stoßen:
-
Fehler bei der Einrichtung und beim Zugriff auf Ressourcen: Beim Ausführen von Spark-Anwendungen in AWS Glue gehören Fehler bei der Einrichtung und beim Zugriff auf Ressourcen zu den häufigsten, aber schwierig zu diagnostizierenden Problemen. Diese Fehler treten häufig auf, wenn Ihre Spark-Anwendung versucht, mit AWS Ressourcen zu interagieren, aber auf Berechtigungsprobleme, fehlende Ressourcen oder Konfigurationsprobleme stößt.
-
Speicherprobleme mit Spark-Treibern und -Executors: Speicherbezogene Fehler in Apache-Spark-Aufträgen können komplex zu diagnostizieren und zu beheben sein. Diese Fehler treten häufig auf, wenn Ihre Datenverarbeitungsanforderungen die verfügbaren Speicherressourcen überschreiten, entweder im Treiberknoten oder in den Executor-Knoten.
-
Probleme mit der Spark-Festplattenkapazität: Speicherbedingte Fehler in AWS Glue Spark-Jobs treten häufig bei Shuffle-Vorgängen, beim Verschütten von Daten oder bei umfangreichen Datentransformationen auf. Diese Fehler können besonders problematisch sein, weil sie möglicherweise erst auftreten, wenn Ihr Auftrag eine Weile ausgeführt wurde, wodurch möglicherweise wertvolle Rechenzeit und Ressourcen verschwendet werden.
-
Fehler bei der Ausführung von Abfragen: Abfragefehler in Spark SQL und DataFrame Vorgängen können schwierig zu beheben sein, da Fehlermeldungen möglicherweise nicht eindeutig auf die Ursache hinweisen und Abfragen, die mit kleinen Datensätzen einwandfrei funktionieren, plötzlich in großem Umfang fehlschlagen können. Diese Fehler werden noch schwieriger, wenn sie tief in komplexen Transformationspipelines auftreten, wo das eigentliche Problem eher auf Datenqualitätsprobleme in früheren Phasen als auf die Abfragelogik selbst zurückzuführen sein kann.
Anmerkung
Bevor Sie vorgeschlagene Änderungen in Ihrer Produktionsumgebung implementieren, sollten Sie die vorgeschlagenen Änderungen sorgfältig prüfen. Der Service bietet Empfehlungen, die auf Mustern und bewährten Methoden basieren. Ihr spezieller Anwendungsfall erfordert jedoch möglicherweise zusätzliche Überlegungen.
Unterstützte -Regionen
Generative KI-Fehlerbehebung für Apache Spark ist in den folgenden Regionen verfügbar:
-
Afrika: Kapstadt (af-south-1)
-
Asien-Pazifik: Hongkong (ap-east-1), Tokio (ap-northeast-1), Seoul (ap-northeast-2), Osaka (ap-northeast-3), Mumbai (ap-south-1), Singapur (ap-southeast-1), Sydney (ap-southeast-2) und Jakarta (ap-southeast-3)
-
Europa: Frankfurt (eu-central-1), Stockholm (eu-nord-1), Mailand (eu-south-1), Irland (eu-west-1), London (eu-west-2) und Paris (eu-west-3)
-
Naher Osten: Bahrain (me-south-1) und VAE (me-central-1)
-
Nordamerika: Kanada (ca-central-1)
-
Südamerika: São Paulo (sa-east-1)
-
Vereinigte Staaten: Nord-Virginia (us-east-1), Ohio (us-east-2), Nordkalifornien (US-West-1) und Oregon (US-West-2)
