Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen von Tabellen
Auch wenn das Ausführen eines Crawlers die empfohlene Methode ist, um die Daten in Ihren Datenspeichern zu inventarisieren, können Sie dem AWS Glue Data Catalog manuell Metadatentabellen hinzufügen. Dieser Ansatz ermöglicht es Ihnen, mehr Kontrolle über die Metadatendefinitionen zu haben und sie an Ihre spezifischen Anforderungen anzupassen.
Sie können Tabellen auch manuell auf folgende Weise zum Datenkatalog hinzufügen:
-
Verwenden Sie die AWS Glue-Konsole, um eine Tabelle in AWS Glue Data Catalog manuell zu erstellen. Weitere Informationen finden Sie unter Erstellen von Tabellen mit der Konsole.
-
Verwenden Sie die
CreateTable-Operation in der AWS Glue API, um eine Tabelle im AWS Glue Data Catalog anzulegen. Weitere Informationen finden Sie unter CreateTable Aktion (Python: create_table). -
Verwenden Sie CloudFormation Vorlagen. Weitere Informationen finden Sie unter AWS CloudFormation für AWS Glue.
Wenn Sie eine Tabelle manuell mithilfe der Konsole oder einer API definieren, geben Sie das Tabellenschema und den Wert eines Klassifizierungsfeldes an, mit dem Typ und Format der Daten in der Datenquelle festgelegt werden. Wenn ein Crawler die Tabelle erstellt, werden das Datenformat und das Schema entweder durch einen integrierten Classifier oder einen angepassten Classifier bestimmt. Weitere Informationen zum Erstellen einer Tabelle mit der AWS Glue-Konsole finden Sie unter Erstellen von Tabellen mit der Konsole.
Themen
Tabellenpartitionen
Eine AWS Glue-Tabellendefinition eines Amazon Simple Storage Service (Amazon S3)-Ordners kann eine partitionierte Tabelle beschreiben. Um die Abfrageleistung zu verbessern, kann eine partitionierte Tabelle beispielsweise monatliche Daten in verschiedene Dateien unter Verwendung des Monatsnamens als Schlüssel aufteilen. In AWS Glue enthalten Tabellendefinitionen den Partitionierungsschlüssel einer Tabelle. Wenn AWS Glue die Daten in Amazon-S3-Ordnern auswertet, um eine Tabelle zu katalogisieren, bestimmt es, ob eine einzelne Tabelle oder eine partitionierte Tabelle hinzugefügt wird.
Sie können Partitionsindizes für eine Tabelle erstellen, um eine Teilmenge der Partitionen abzurufen, anstatt alle Partitionen in der Tabelle zu laden. Weitere Informationen zum Arbeiten mit Indizes finden Sie unter Erstellen von Partitionsindizes.
Alle folgenden Bedingungen müssen für AWS Glue zutreffen, um eine partitionierte Tabelle für einen Amazon-S3-Ordner zu erstellen:
-
Die Schemata der Dateien sind identisch, wie von AWS Glue festgelegt.
-
Das Datenformat der Dateien ist identisch.
-
Das Komprimierungsformat der Dateien ist identisch.
Sie könnten z. B. einen Amazon S3 Bucket namens my-app-bucket besitzen, in dem Sie sowohl iOS- als auch Android-App-Verkaufsdaten speichern. Die Daten werden nach Jahr, Monat und Tag partitioniert. Die Datendateien für iOS- und Android-Verkäufe haben das gleiche Schema, Datenformat und Komprimierungsformat. In der AWS Glue Data Catalog erstellt der AWS Glue Crawler eine Tabellendefinition mit Partitionierungsschlüsseln für Jahr, Monat und Tag.
Die folgende Amazon-S3-Auflistung von my-app-bucket zeigt einige der Partitionen. Das =-Symbol dient zur Zuweisung von Partitionsschlüsselwerten.
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv ... my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
Tabellenressourcen-Verknüpfungen
| Die AWS Glue-Konsole wurde kürzlich aktualisiert. Die aktuelle Version der Konsole bietet keine Unterstützung für Tabellenressourcenlinks. |
Außerdem kann der Data Catalog auch Ressourcenlinks zu Tabellen enthalten. Ein Link zu einer Tabellenressource ist eine Verknüpfung zu einer lokalen oder freigegebenen Datenbank. Derzeit können Sie Ressourcenlinks nur in AWS Lake Formation erstellen. Nachdem Sie einen Ressourcenlink zu einer Tabelle erstellt haben, können Sie den Namen des Ressourcenlinks überall verwenden, wo Sie den Tabellennamen verwenden möchten. Zusammen mit Datenbanken, die Sie besitzen oder die für Sie freigegeben sind, werden Tabellenressourcenlinks von glue:GetTables() zurückgegeben und als Einträge auf der Tabellenseite der AWS Glue-Konsole angezeigt.
Außerdem kann der Data Catalog auch Ressourcen-Links zu Datenbanken enthalten.
Weitere Informationen zu Ressourcenlinks finden Sie unter Creating Resource Links (Erstellen von Ressourcenlinks) im AWS Lake Formation -Entwicklerhandbuch.
Erstellen von Tabellen mit der Konsole
Eine Tabelle in der AWS Glue Data Catalog ist die Metadatendefinition, die die Daten in einem Datenspeicher darstellt. Sie erstellen Tabellen, wenn Sie einen Crawler ausführen, oder Sie können eine Tabelle manuell in der AWS Glue -Konsole erstellen. Die Tables (Tabellen)-Liste in der AWS Glue-Konsole zeigt die Werte Ihrer Tabellenmetadaten an. Sie verwenden Tabellendefinitionen zum Angeben von Quellen und Zielen, wenn Sie ETL (Extrahieren, Transformieren und Laden)-Aufträge erstellen.
Anmerkung
Aufgrund der jüngsten Änderungen an der AWS Managementkonsole müssen Sie möglicherweise Ihre vorhandenen IAM-Rollen ändern, um die SearchTablesentsprechende Berechtigung zu erhalten. Für die Erstellung neuer Rollen wurde die SearchTables-API-Berechtigung bereits standardmäßig hinzugefügt.
Melden Sie sich zunächst bei der an AWS-Managementkonsole und öffnen Sie die AWS Glue Konsole unter https://console.aws.amazon.com/glue/
Hinzufügen von Tabellen in der Konsole
Um einen Crawler zum Hinzufügen von Tabellen zu verwenden, wählen Sie Add tables (Tabellen hinzufügen), Add tables using a crawler (Tabellen mit einem Crawler hinzufügen) aus. Dann folgen Sie den Anweisungen im Add crawler (Crawler hinzufügen)-Assistenten. Wenn der Crawler ausgeführt wird, werden Tabellen dem AWS Glue Data Catalog hinzugefügt. Weitere Informationen finden Sie unter Verwenden von Crawlern zum Auffüllen des Datenkatalogs.
Wenn Sie die Attribute kennen, die zum Erstellen einer Amazon Simple Storage Service (Amazon S3)-Tabellendefinition in Ihrem Data Catalog erforderlich sind, können Sie sie mit dem Tabellenassistenten erstellen. Wählen Sie Add tables (Tabellen hinzufügen), Add table manually (Tabelle manuell hinzufügen) aus und befolgen Sie die Anweisungen im Add table (Tabelle hinzufügen)-Assistenten.
Wenn eine Tabelle über die Konsole manuell hinzufügt wird, sollten Sie Folgendes beachten:
-
Wenn Sie über Amazon Athena auf die Tabelle zugreifen möchten, müssen Sie einen Namen angeben, der nur aus alphanumerischen Zeichen und Unterstrichen besteht. Weitere Informationen finden Sie unter Athena-Namen.
-
Der Speicherort der Quelldaten muss ein Amazon-S3-Pfad sein.
-
Das Datenformat der Daten muss einem der im Assistenten aufgelisteten Formate entsprechen. Die entsprechende Klassifizierung und andere Tabelleneigenschaften werden automatisch auf der Grundlage des ausgewählten Formats aufgefüllt. SerDe Sie können Tabellen mit den folgenden Formaten definieren:
- Avro
-
Apache Avro-JSON-Binärformat.
- CSV
-
Werte mit Zeichentrennung. Sie geben auch das Trennzeichen Komma, Pipe, Semikolon, Tab oder Strg-A an.
- JSON
-
JavaScript Objektnotation.
- XML
-
Extensible Markup Language-Format. Geben Sie das XML-Tag an, das eine Zeile in den Daten definiert. Spalten werden innerhalb von Zeilen-Tags definiert.
- Parquet
-
Spaltenweise Speicherung von Apache Parquet.
- ORC
-
Optimiertes ORC-Dateiformat (Row Columnar). Ein Format zur effizienten Speicherung von Hive-Daten.
-
Sie können einen Partitionsschlüssel für die Tabelle definieren.
-
Derzeit können partitionierte Tabellen, die Sie mit der Konsole erstellen, nicht in ETL-Jobs verwendet werden.
Tabellenattribute
Es folgen einige wichtige Attribute Ihrer Tabelle:
- Name
-
Der Name wird festgelegt, wenn die Tabelle erstellt wird, und kann nicht geändert werden. Sie beziehen sich in vielen AWS Glue-Operationen auf einen Tabellennamen.
- Datenbank
-
Das Container-Objekt, in dem die Tabelle gespeichert ist. Dieses Objekt enthält eine Organisation Ihrer Tabellen, die innerhalb des Datenspeichers existiert AWS Glue Data Catalog und sich von dieser unterscheiden kann. Wenn Sie eine Datenbank löschen, werden alle Tabellen in der Datenbank ebenfalls von dem Data Catalog gelöscht.
- Description
-
Die Beschreibung der Tabelle. Sie können eine Beschreibung zum besseren Verständnis der Inhalte der Tabelle schreiben.
- Tabellenformat
-
Geben Sie an, eine AWS Glue Standardtabelle oder eine Tabelle im Apache Iceberg-Format zu erstellen.
Der Datenkatalog bietet die folgenden Tabellenoptimierungsoptionen, um den Tabellenspeicher zu verwalten und die Abfrageleistung für Iceberg-Tabellen zu verbessern.
-
Compaction – Datendateien werden zusammengeführt und neu geschrieben, um veraltete Daten zu entfernen und fragmentierte Daten in größeren, effizienteren Dateien zu konsolidieren.
Aufbewahrung von Snapshots: Snapshots sind Versionen einer Iceberg-Tabelle mit Zeitstempel. Mit Konfigurationen zur Beibehaltung von Snapshots können Kunden festlegen, wie lange und wie viele Snapshots beibehalten werden sollen. Die Konfiguration eines Optimierer zur Aufbewahrung von Snapshots kann helfen, den Speicheraufwand zu minimieren, indem ältere, unnötige Snapshots und die zugehörigen zugrunde liegenden Dateien entfernt werden.
Löschen verwaister Dateien: Verwaiste Dateien sind Dateien, auf die in den Metadaten der Iceberg-Tabelle nicht mehr verwiesen wird. Diese Dateien können sich im Laufe der Zeit ansammeln, insbesondere nach Vorgängen wie dem Löschen von Tabellen oder fehlgeschlagenen ETL-Aufträgen. Wenn Sie das Löschen verwaister Dateien aktivieren AWS Glue , können Sie diese überflüssigen Dateien regelmäßig identifizieren und entfernen, wodurch Speicherplatz frei wird.
Weitere Informationen finden Sie unter Optimieren von Iceberg-Tabellen.
-
- Optimierungskonfiguration
Sie können entweder die Standardeinstellungen verwenden oder die Einstellungen für die Aktivierung der Tabellenoptimierer anpassen.
- IAM role (IAM-Rolle)
Um die Tabellenoptimierer auszuführen, nimmt der Service eine IAM-Rolle in Ihrem Namen an. Sie können über das Dropdown-Menü eine IAM-Rolle auswählen. Die Rolle sollte die erforderlichen Berechtigungen für die Verdichtung haben.
Weitere Informationen zu den erforderlichen Berechtigungen für die IAM-Rolle finden Sie unter Voraussetzungen für die Tabellenoptimierung.
- Speicherort
-
Der Zeiger auf den Speicherort der Daten in einem Datenspeicher, den diese Tabellendefinition repräsentiert.
- Klassifizierung
-
Ein Kategorisierungswert, der bei der Erstellung der Tabelle bereitgestellt wurde. In der Regel wird dieser geschrieben, wenn ein Crawler ausgeführt wird, und gibt das Format der Quelldaten an.
- Letzte Aktualisierung
-
Die Uhrzeit und das Datum (UTC), zu denen diese Tabelle im Data Catalog aktualisiert wurde.
- Datum hinzugefügt
-
Die Uhrzeit und das Datum (UTC), zu denen diese Tabelle dem Data Catalog hinzugefügt wurde.
- Als veraltet gekennzeichnet
-
Wenn AWS Glue erkennt, dass eine Tabelle im Data Catalog im ursprünglichen Datenspeicher nicht mehr existiert, markiert es die Tabelle im Data Catalog als veraltet. Wenn Sie einen Auftrag ausführen, der auf eine veraltete Tabelle verweist, kann der Auftrag fehlschlagen. Bearbeiten Sie Aufträge, die auf veraltete Tabellen verweisen, um sie als Quellen und Ziele zu entfernen. Wir empfehlen, dass Sie veraltete Tabellen löschen, wenn sie nicht mehr benötigt werden.
- Connection (Verbindung)
-
Wenn AWS Glue eine Verbindung mit dem Datenspeicher benötigt, wird der Name der Verbindung mit der Tabelle verknüpft.
Anzeigen und Verwalten von Tabellendetails
Um die Details einer vorhandenen Tabelle anzuzeigen, wählen Sie den Tabellennamen in der Liste und dann Action, View details (Aktion, Details anzeigen) aus.
Die Tabellendetails umfassen Eigenschaften der Tabelle und deren Schema. Diese Ansicht zeigt das Schema der Tabelle an, einschließlich Spaltennamen in der Reihenfolge, die für die Tabelle, Datentypen und Schlüsselspalten für Partitionen definiert wurde. Wenn eine Spalte ein komplexer Typ ist, können Sie View properties (Eigenschaften anzeigen) auswählen, um Details der Struktur dieses Felds anzuzeigen, wie im folgenden Beispiel dargestellt:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Weitere Informationen zu den Eigenschaften einer Tabelle, wie z. B. StorageDescriptor, finden Sie unter StorageDescriptor Struktur.
Wenn Sie das Schema einer Tabelle ändern möchten, wählen Sie Edit schema (Schema bearbeiten) aus, um Spalten hinzuzufügen oder zu löschen und Spaltennamen und Datentypen zu ändern.
Um verschiedene Versionen einer Tabelle, einschließlich ihres Schemas, zu vergleichen, wählen Sie Versionen vergleichen, um einen side-by-side Vergleich zweier Versionen des Schemas für eine Tabelle anzuzeigen. Weitere Informationen finden Sie unter Vergleichen von Tabellenschemaversionen.
Zum Anzeigen der Dateien, aus denen eine Amazon-S3-Partition besteht, wählen Sie View Partition (Partition anzeigen) aus. Bei Amazon-S3-Tabellen zeigt die Schlüssel-Spalte die Partitionsschlüssel an, die verwendet werden, um die Tabelle im Quelldatenspeicher zu partitionieren. Die Partitionierung ist eine Möglichkeit, eine Tabelle auf der Grundlage der Werte einer Schlüsselspalte, wie Datum, Ort oder Abteilung, in verwandte Teile zu unterteilen. Für weitere Informationen zu Partitionen, suchen Sie im Internet nach Informationen über "Hive-Partitionierung".
Anmerkung
step-by-stepAnleitungen zum Anzeigen der Details einer Tabelle finden Sie in der Konsole im Tutorial „Tabelle erkunden“.
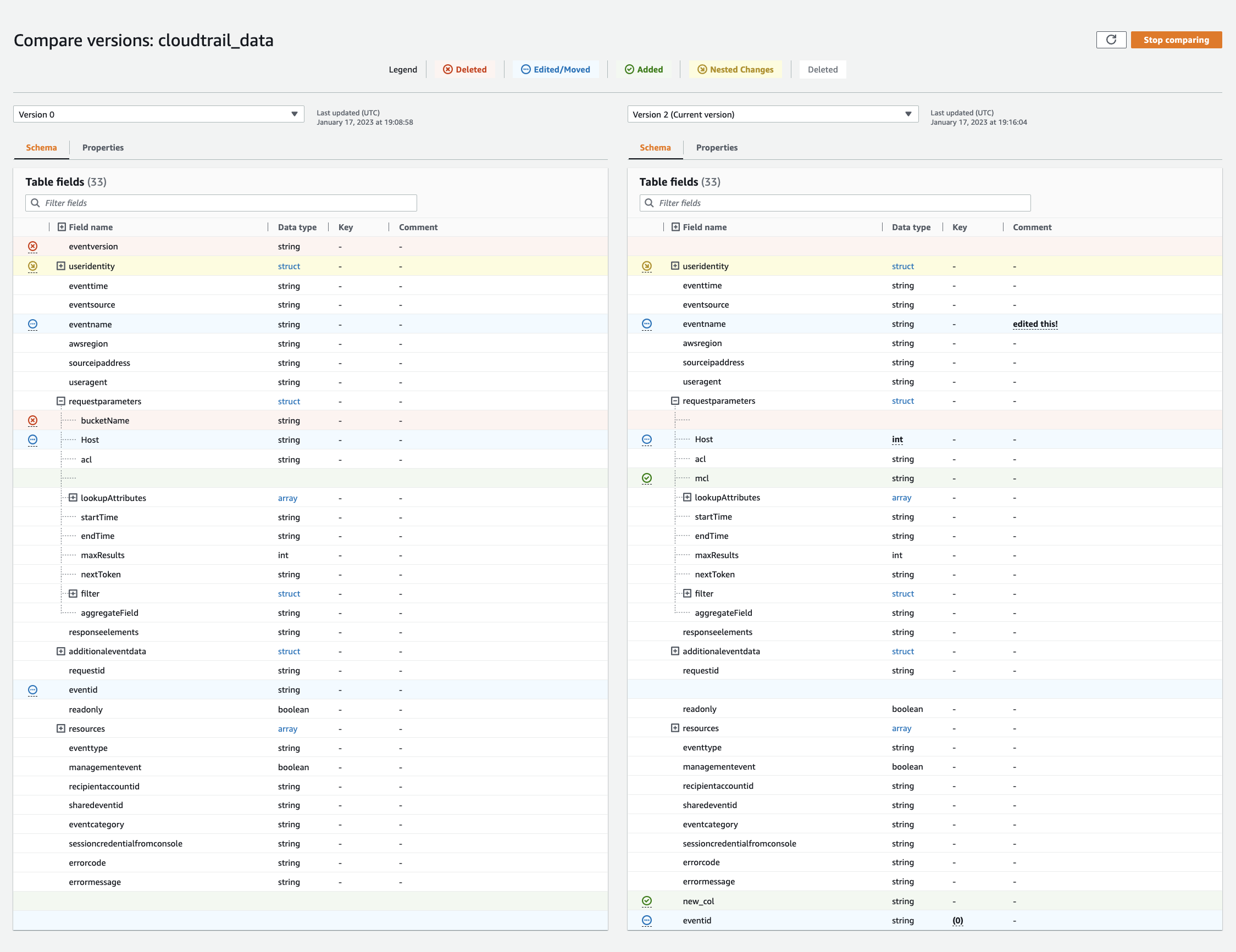
Vergleichen von Tabellenschemaversionen
Wenn Sie zwei Versionen von Tabellenschemas vergleichen, können Sie Änderungen an verschachtelten Zeilen vergleichen, indem Sie verschachtelte Zeilen erweitern und reduzieren, Schemas zweier Versionen side-by-side vergleichen und Tabelleneigenschaften anzeigen. side-by-side
Wie Sie Versionen vergleichen
-
Wählen Sie in der AWS Glue-Konsole Tabellen, dann Aktionen und dann Versionen vergleichen aus.
-
Wählen Sie eine Version, die Sie vergleichen möchten, indem Sie das Dropdown-Menü wählen. Beim Vergleich von Schemas ist die Registerkarte Schema orange hervorgehoben.
-
Wenn Sie Tabellen zwischen zwei Versionen vergleichen, werden Ihnen die Tabellenschemas auf der linken und rechten Seite des Bildschirms angezeigt. Auf diese Weise können Sie Änderungen visuell ermitteln, indem Sie die Felder Spaltenname, Datentyp, Schlüssel und Kommentar vergleichen. side-by-side Wenn es eine Änderung gibt, zeigt ein farbiges Symbol die Art der vorgenommenen Änderung an.
-
Gelöscht – ein rotes Symbol zeigt an, wo die Spalte aus einer früheren Version des Tabellenschemas entfernt wurde.
-
Bearbeitet oder Verschoben – Ein blaues Symbol zeigt an, wo die Spalte in einer neueren Version des Tabellenschemas geändert oder verschoben wurde.
-
Gelöscht – ein rotes Symbol zeigt an, wo die Spalte aus einer früheren Version des Tabellenschemas entfernt wurde.
-
Verschachtelte Änderungen – Ein gelbes Symbol zeigt an, wo die verschachtelte Spalte Änderungen enthält. Wählen Sie die Spalte aus, die erweitert werden soll, und sehen Sie sich die Spalten an, die entweder gelöscht, bearbeitet, verschoben oder hinzugefügt wurden.
-
-
Verwenden Sie die Suchleiste für Filterfelder, um Felder anzuzeigen, die auf den Zeichen basieren, die Sie hier eingeben. Wenn Sie in einer der Tabellenversionen einen Spaltennamen eingeben, werden die gefilterten Felder in beiden Tabellenversionen angezeigt, um Ihnen zu zeigen, wo die Änderungen vorgenommen wurden.
-
Um Eigenschaften zu vergleichen, wählen Sie die Registerkarte der Eigenschaften.
-
Um den Versionsvergleich zu beenden, wählen Sie Vergleich beenden, um zur Liste der Tabellen zurückzukehren.
Aktualisieren von manuell erstellten Data-Catalog-Tabellen mit Crawlern
Möglicherweise möchten Sie AWS Glue Data Catalog Tabellen manuell erstellen und sie dann mit AWS Glue Crawlern auf dem neuesten Stand halten. Crawler, die nach einem Zeitplan ausgeführt werden, können neue Partitionen hinzufügen und die Tabellen mit allen Schemaänderungen aktualisieren. Dies gilt auch für Tabellen, die aus aus einem Apache Hive-Metastore migriert wurden.
Hierzu geben Sie beim Definieren eines Crawlers statt eines oder mehrerer Datenspeicher als Quelle eines Crawls eine oder mehrere vorhandene Data-Catalog-Tabellen an. Der Crawler durchsucht dann die durch die Katalogtabellen angegebenen Datenspeicher. In diesem Fall werden keine neuen Tabellen erstellt. Stattdessen werden Ihre manuell erstellten Tabellen aktualisiert.
Es folgen weitere mögliche Gründe dafür, Katalogtabellen manuell zu erstellen und Katalogtabellen als Crawler-Quelle anzugeben.
-
Sie möchten den Katalog-Tabellennamen wählen und dies nicht dem Benennungsalgorithmus der Katalogtabelle überlassen.
-
Sie möchten verhindern, dass neue Tabellen erstellt werden, falls Dateien mit einem die Paritionserkennung störenden Format versehentlich im Pfad der Datenquelle gespeichert werden.
Weitere Informationen finden Sie unter Schritt 2: Auswahl von Datenquellen und Classifier.
Eigenschaften der Data-Catalog-Tabelle
Tabelleneigenschaften oder Parameter, wie sie in der AWS CLI genannt werden, sind nicht validierte Schlüssel- und Wertezeichenfolgen. Sie können Ihre eigenen Eigenschaften für die Tabelle festlegen, um die Verwendung des Data Catalog außerhalb von AWS Glue zu unterstützen. Andere Dienste, die den Datenkatalog verwenden, können dies ebenfalls tun. AWS Glue legt einige Tabelleneigenschaften fest, wenn Jobs oder Crawler ausgeführt werden. Sofern nicht anders beschrieben, sind diese Eigenschaften für den internen Gebrauch bestimmt. Wir unterstützen nicht, dass sie in ihrer aktuellen Form fortbestehen, und wir unterstützen auch nicht das Produktverhalten, wenn diese Eigenschaften manuell geändert werden.
Weitere Hinweise zu Tabelleneigenschaften, die von AWS Glue Crawlern festgelegt wurden, finden Sie unter. Parameter, die vom Crawler in Data-Catalog-Tabellen festgelegt wurden
