Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden AWS Glue mit AWS Lake Formation für eine feinkörnige Zugangskontrolle
-Übersicht
Mit AWS Glue Version 5.0 und höher können Sie detaillierte Zugriffskontrollen auf Datenkatalogtabellen anwenden, die von S3 unterstützt werden. AWS Lake Formation Mit dieser Funktion können Sie Zugriffskontrollen auf Tabellen-, Zeilen-, Spalten- und Zellenebene für read-Abfragen innerhalb Ihrer AWS Glue für Apache-Spark-Aufträge konfigurieren. In den folgenden Abschnitten erfahren Sie mehr über Lake Formation und wie Sie es mit AWS Glue verwenden können.
GlueContextEine basierte Zugriffskontrolle auf Tabellenebene mit AWS Lake Formation Berechtigungen, die in Glue 4.0 oder früher unterstützt wurden, wird in Glue 5.0 nicht unterstützt. Verwenden Sie die neue native differenzierte Zugriffskontrolle (FGAC) von Spark in Glue 5.0. Beachten Sie folgende Details:
Wenn Sie eine feinkörnige Zugriffskontrolle (FGAC) für die Zugriffskontrolle von row/column /cell benötigen, müssen Sie in Glue 4.0 von
GlueContext/Glue und DynamicFrame in Glue 5.0 vor Spark-Dataframe migrieren. Beispiele finden Sie unter Migration von GlueContext/Glue DynamicFrame zu Spark DataFrameWenn Sie Full Table Access Control (FTA) benötigen, können Sie FTA DynamicFrames in AWS Glue 5.0 nutzen. Sie können auch zum nativen Spark-Ansatz migrieren, um zusätzliche Funktionen wie Resilient Distributed Datasets (RDDs), benutzerdefinierte Bibliotheken und benutzerdefinierte Funktionen (UDFs) mit Tabellen zu nutzen. AWS Lake Formation Beispiele finden Sie unter Migration von AWS Glue 4.0 zu AWS Glue 5.0.
Wenn Sie FGAC nicht benötigen, ist keine Migration zu Spark DataFrame erforderlich und
GlueContext-Features wie Auftragslesezeichen und Push-Down-Prädikate funktionieren weiterhin.Aufträge mit FGAC erfordern mindestens 4 Worker: einen Benutzertreiber, einen Systemtreiber, einen System-Executor und einen Standby-Benutzer-Executor.
Für die Verwendung von AWS AWS Lake Formation Glue mit fallen zusätzliche Gebühren an.
Wie AWS Glue funktioniert mit AWS Lake Formation
Wenn Sie AWS Glue mit Lake Formation verwenden, können Sie für jeden Spark-Job eine Berechtigungsebene erzwingen, um die Lake Formation Formation-Berechtigungssteuerung anzuwenden, wenn AWS Glue Jobs ausführt. AWS Glue verwendet Spark-Ressourcenprofile
Im Folgenden finden Sie einen allgemeinen Überblick darüber, wie AWS Glue Zugriff auf Daten erhält, die durch die Sicherheitsrichtlinien von Lake Formation geschützt sind.
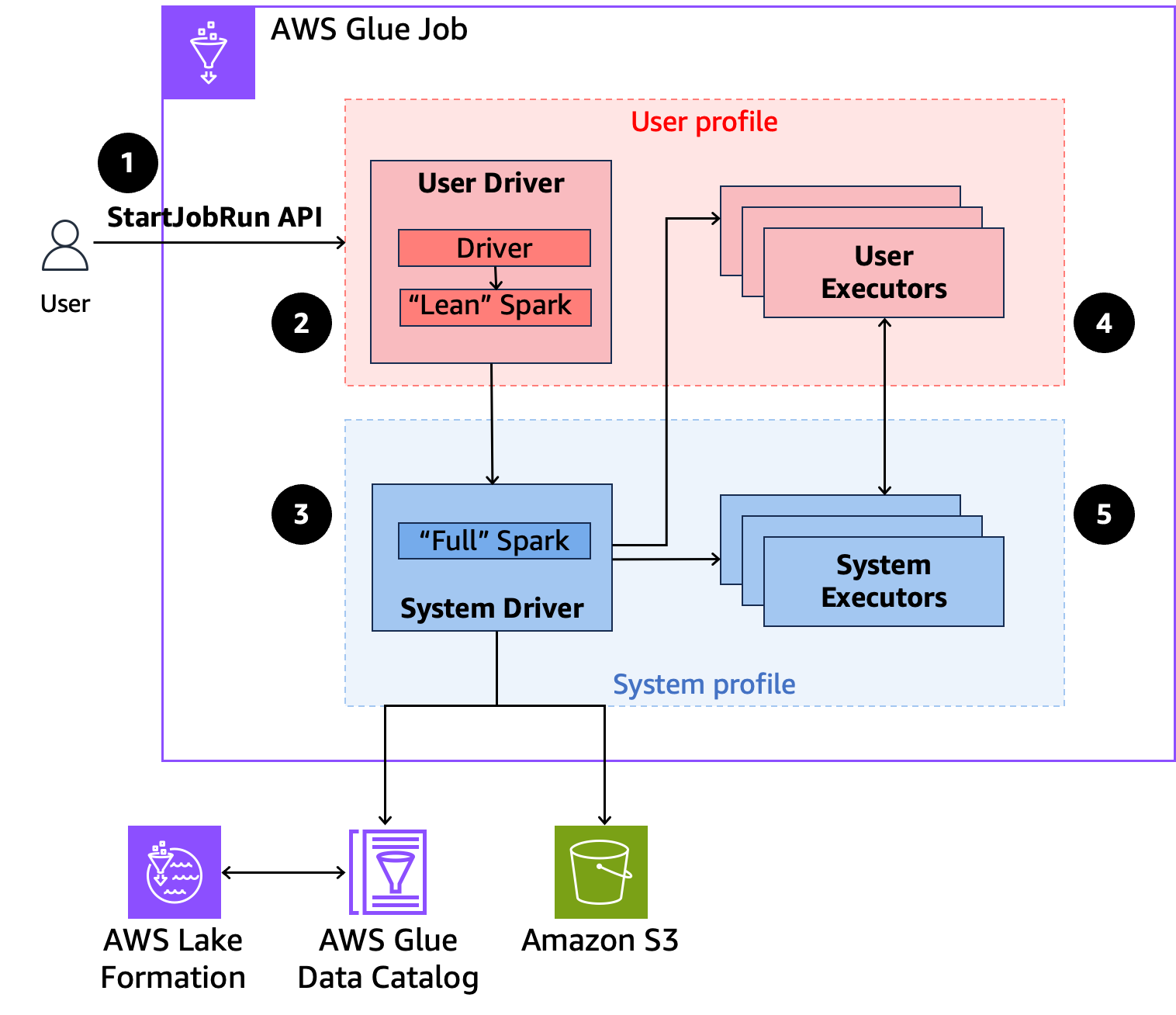
-
Ein Benutzer ruft die
StartJobRunAPI für einen AWS Lake Formation-enabled AWS Glue-Job auf. -
AWS Glue sendet den Job an einen Benutzertreiber und führt den Job im Benutzerprofil aus. Der Benutzertreiber führt eine schlanke Version von Spark aus, die nicht in der Lage ist, Aufgaben zu starten, Executors anzufordern, auf S3 oder den Glue-Katalog zuzugreifen. Er erstellt einen Auftragsplan.
-
AWS Glue richtet einen zweiten Treiber ein, den Systemtreiber, und führt ihn im Systemprofil aus (mit einer privilegierten Identität). AWS Glue richtet einen verschlüsselten TLS-Kanal zwischen den beiden Treibern für die Kommunikation ein. Der Benutzertreiber verwendet den Kanal, um die Auftragspläne an den Systemtreiber zu senden. Der Systemtreiber führt keinen vom Benutzer übermittelten Code aus. Er führt Spark vollständig aus und kommuniziert mit S3 und dem Datenkatalog für den Datenzugriff. Er fordert Executors an und stellt den Auftragsplan in eine Abfolge von Ausführungsphasen zusammen.
-
AWS Glue führt dann die Stufen auf Executoren mit dem Benutzertreiber oder Systemtreiber aus. Benutzercode wird in jeder Phase ausschließlich auf Benutzerprofil-Executors ausgeführt.
-
Stufen, die Daten aus Datenkatalogtabellen lesen, die durch Sicherheitsfilter geschützt sind AWS Lake Formation oder solche, die Sicherheitsfilter anwenden, werden an System-Executoren delegiert.
Mindestanforderung an Worker
Ein Formation-enabled Lake-Job in AWS Glue erfordert mindestens 4 Worker: einen Benutzertreiber, einen Systemtreiber, einen System-Executor und einen Standby-User Executor. Dies ist ein Anstieg der Mindestanzahl von 2 Arbeitern, die für AWS Standardklebearbeiten erforderlich sind.
Ein Formation-enabled Lake-Job in AWS Glue verwendet zwei Spark-Treiber — einen für das Systemprofil und einen weiteren für das Benutzerprofil. Ebenso sind die Executors in zwei Profile unterteilt:
System-Executors: Bearbeiten Aufgaben, bei denen Lake-Formation-Datenfilter angewendet werden.
Benutzer-Executoren: Werden bei Bedarf vom Systemtreiber angefordert.
Da Spark-Jobs von Natur aus faul sind, reserviert AWS Glue 10% der gesamten Arbeiter (mindestens 1), nach Abzug der beiden Treiber, für Benutzerausführungen.
Bei allen Formation-enabled Lake-Jobs ist die auto-scaling aktiviert, was bedeutet, dass die Benutzerausführungen nur bei Bedarf gestartet werden.
Eine Beispielkonfiguration finden Sie unter Überlegungen und Einschränkungen.
IAM-Berechtigungen für die Auftrag-Laufzeitrolle
Lake Formation Formation-Berechtigungen kontrollieren den Zugriff auf AWS Glue Data Catalog-Ressourcen, Amazon S3 S3-Standorte und die zugrunde liegenden Daten an diesen Standorten. IAM-Berechtigungen steuern den Zugriff auf die APIs und AWS -Ressourcen von Lake Formation und Glue. Obwohl Sie möglicherweise über die Lake-Formation-Berechtigung verfügen, auf eine Tabelle im Datenkatalog (SELECT) zuzugreifen, schlägt Ihr Vorgang fehl, wenn Sie nicht über die IAM-Berechtigung für den glue:Get*-API-Vorgang verfügen.
Die folgende Beispielrichtlinie beschreibt, wie Sie IAM-Berechtigungen für den Zugriff auf ein Skript in S3, das Hochladen von Protokollen in S3, API-Berechtigungen für AWS Glue und die Berechtigung für den Zugriff auf Lake Formation erteilen.
Lake-Formation-Berechtigungen für die Auftrag-Laufzeitrolle einrichten
Registrieren Sie zunächst den Speicherort Ihrer Hive-Tabelle bei Lake Formation. Erstellen Sie anschließend Berechtigungen für Ihre Auftrag-Laufzeitrolle für die gewünschte Tabelle. Weitere Informationen zu Lake Formation finden Sie unter Was ist AWS Lake Formation? im AWS Lake Formation Entwicklerhandbuch.
Nachdem Sie die Lake-Formation-Berechtigungen eingerichtet haben, können Sie Spark-Aufträge auf AWS Glue senden.
Senden einer Auftragsausführung
Nachdem Sie die Lake Formation Grants eingerichtet haben, können Sie Spark-Jobs auf AWS Glue einreichen. Um Iceberg-Aufträge auszuführen, müssen Sie die folgenden Spark-Konfigurationen angeben. Geben Sie den folgenden Parameter ein, um die Konfiguration über Glue-Auftragsparameter vorzunehmen:
Schlüssel:
--confWert:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
Verwenden einer interaktiven Sitzung
Nachdem Sie die AWS Lake Formation Grants eingerichtet haben, können Sie interaktive Sessions auf AWS Glue verwenden. Sie müssen die folgenden Spark-Konfigurationen über die %%configure-Magic angeben, bevor Sie Code ausführen.
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
FGAC für AWS Glue 5.0 Notizbuch oder interaktive Sitzungen
Um Fine-Grained Access Control (FGAC) in AWS Glue zu aktivieren, müssen Sie die für Lake Formation erforderlichen Spark-Konfigurationen als Teil von %%configure Magic angeben, bevor Sie die erste Zelle erstellen.
Eine spätere Angabe über die Aufrufe SparkSession.builder().conf("").get() oder SparkSession.builder().conf("").create() reicht nicht aus. Dies ist eine Änderung gegenüber dem Verhalten von AWS Glue 4.0.
Open-table Unterstützung für Formate
AWS Glue Version 5.0 oder höher bietet Unterstützung für eine feinkörnige Zugriffskontrolle auf Basis von Lake Formation. AWS Glue unterstützt die Tabellentypen Hive und Iceberg. In der folgenden Tabelle werden alle unterstützten Vorgänge beschrieben.
| Operationen | Hive | Iceberg |
|---|---|---|
| DDL-Befehle | Nur mit IAM-Rollenberechtigungen | Nur mit IAM-Rollenberechtigungen |
| Inkrementelle Abfragen | Nicht zutreffend | Vollständig unterstützt |
| Zeitreiseabfragen | Gilt nicht für dieses Tabellenformat | Vollständig unterstützt |
| Metadaten-Tabellen | Gilt nicht für dieses Tabellenformat | Wird unterstützt, aber bestimmte Tabellen sind ausgeblendet. Weitere Informationen finden Sie unter Überlegungen und Einschränkungen. |
DML INSERT |
Nur mit IAM-Berechtigungen | Nur mit IAM-Berechtigungen |
| DML-UPDATE | Gilt nicht für dieses Tabellenformat | Nur mit IAM-Berechtigungen |
DML DELETE |
Gilt nicht für dieses Tabellenformat | Nur mit IAM-Berechtigungen |
| Lesevorgänge | Vollständig unterstützt | Vollständig unterstützt |
| Gespeicherte Prozeduren | Nicht zutreffend | Unterstützt mit den Ausnahmen von register_table und migrate. Weitere Informationen finden Sie unter Überlegungen und Einschränkungen. |
