Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwendung von Kontexterkennung mit Amazon Q Data Integration in AWS Glue
Mit abfragebasierter, kontextsensitiver und PySpark DataFrame Codegenerierung in Amazon Q Data Integration können Sie Datenverarbeitungsaufträge jetzt effizienter erstellen. Sie können diese Aufforderung beispielsweise verwenden, um PySpark Code zu generieren: „Erstellen Sie einen Job zum Laden von Verkaufsdaten aus der Redshift-Tabelle 'analytics.salesorder' mithilfe der Verbindung 'erp_conn', filtern Sie order_amount unter 50 Dollar und speichern Sie sie in Amazon S3 im Parquet-Format.“
Amazon Q generiert das Skript auf der Grundlage Ihrer Eingabeaufforderung und der Einrichtung des Workflows zur Datenintegration mit den in Ihrer Frage angegebenen Details, wie Verbindungskonfigurationen, Schemadetails, database/table Namen und Spaltenspezifikationen für Transformationen. Vertrauliche Informationen, wie Passwörter für Verbindungsoptionen, werden weiterhin unkenntlich gemacht.
Wenn Sie die erforderlichen Informationen in Ihrem Prompt nicht angeben, fügt Amazon Q Platzhalter ein. Sie müssen den generierten Code mit den entsprechenden Werten aktualisieren, bevor Sie ihn ausführen.
Im Folgenden finden Sie Beispiele für die Verwendung der Kontexterkennung.
Beispiel: Interaktionen
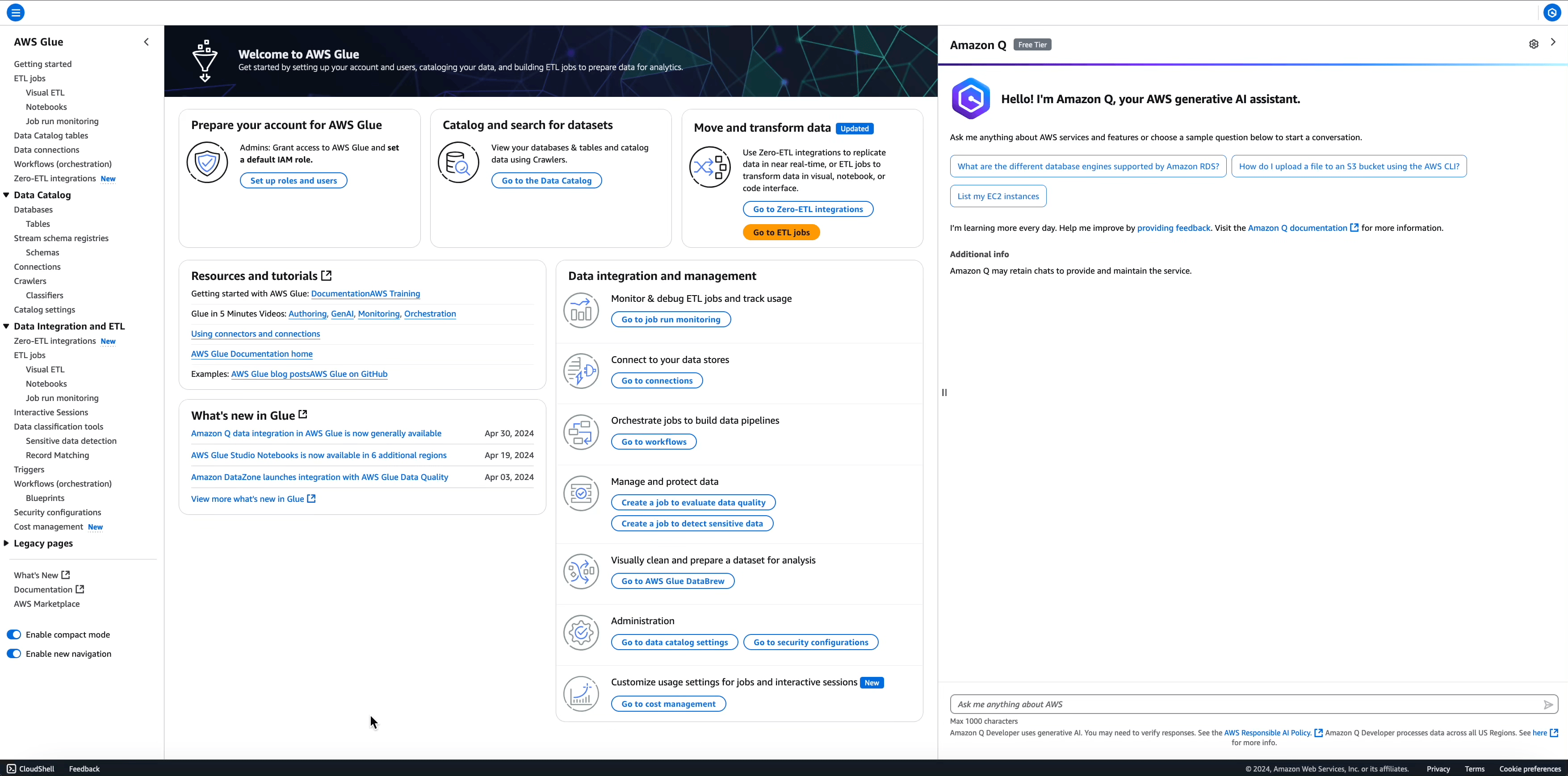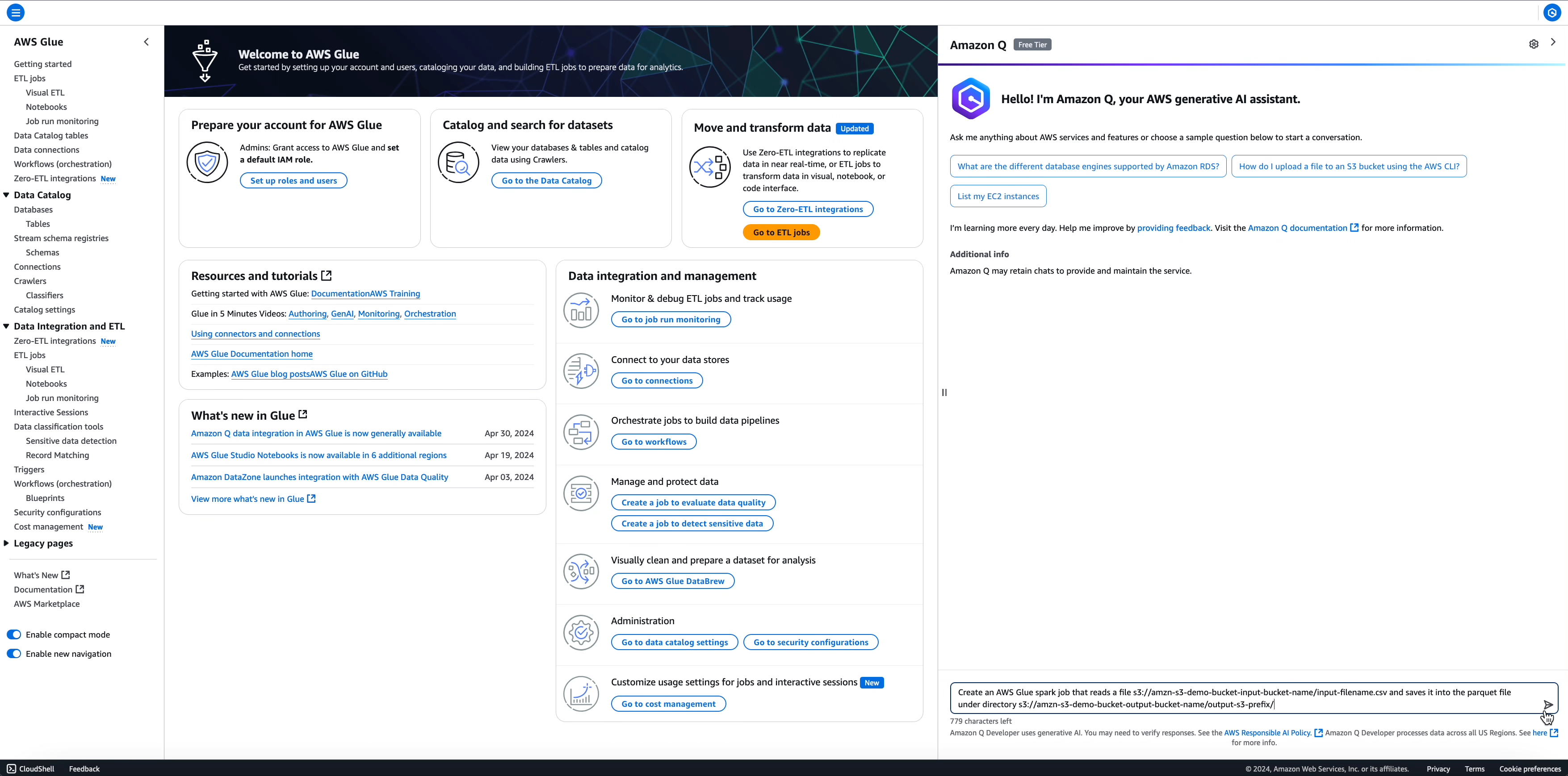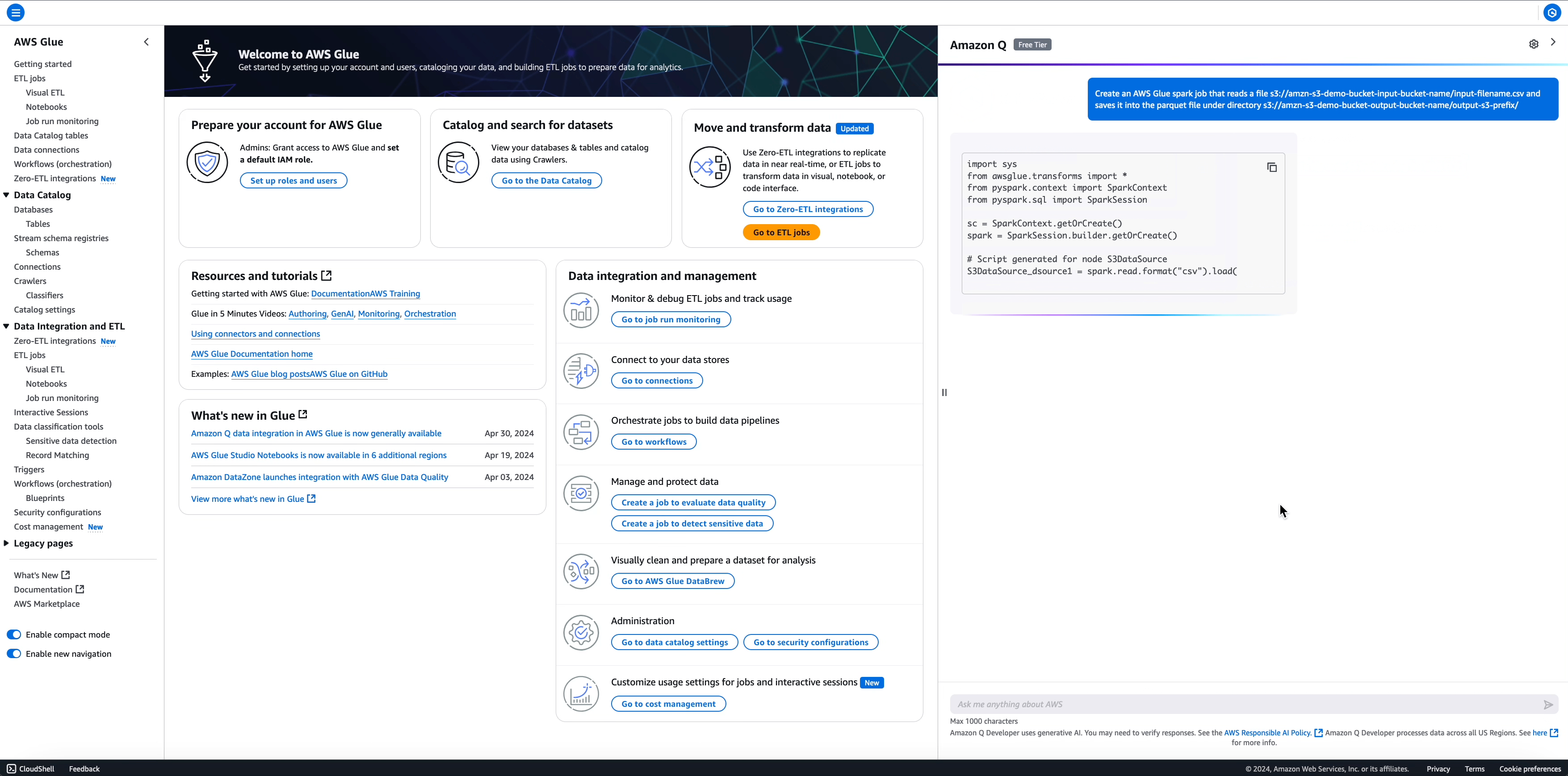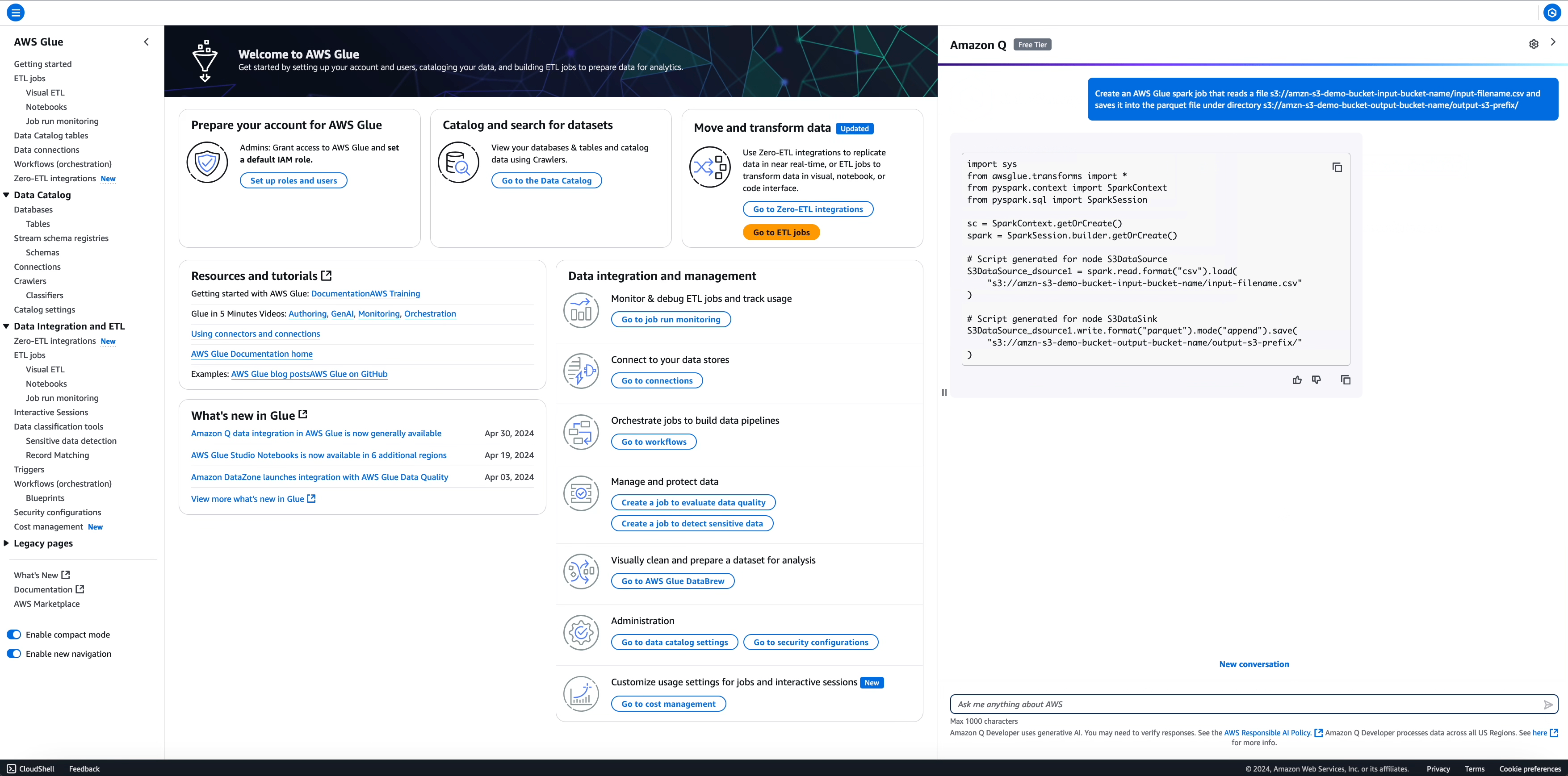
Prompt: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and
saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("csv").load( "s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv" ) # Script generated for node S3DataSink S3DataSource_dsource1.write.format("parquet").mode("append").save( "s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/" )

Prompt: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table
my-target-table
Für Felder, für die Sie keine Informationen angegeben haben (z. B. der erforderliche connectionName für die MySQL-Datensenke und der Platzhalter <connection-name> im generierten Code), wird ein Platzhalter beibehalten, damit Sie die erforderlichen Informationen vor dem Ausführen des Skripts eingeben können.
Generiertes Skript:
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession from connectivity.adapter import CatalogConnectionHelper sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("parquet").load( "s3://amzn-lakehouse-demo-bucket/my-database/my-table" ) # Script generated for node ConnectionV2DataSink ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"} CatalogConnectionHelper(spark).write( S3DataSource_dsource1, "mysql", "<connection-name>", ConnectionV2DataSink_dsink1_additional_options, )
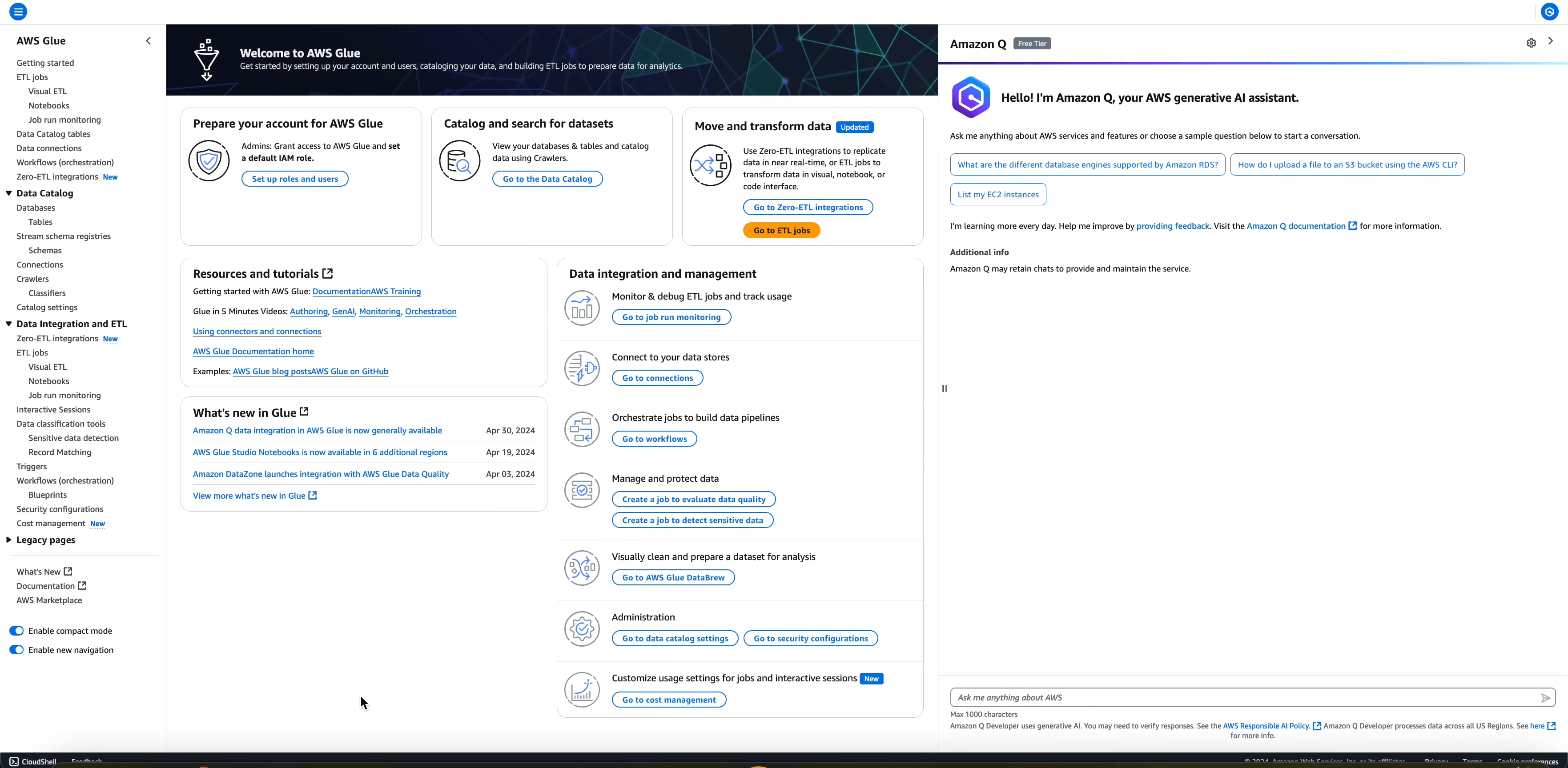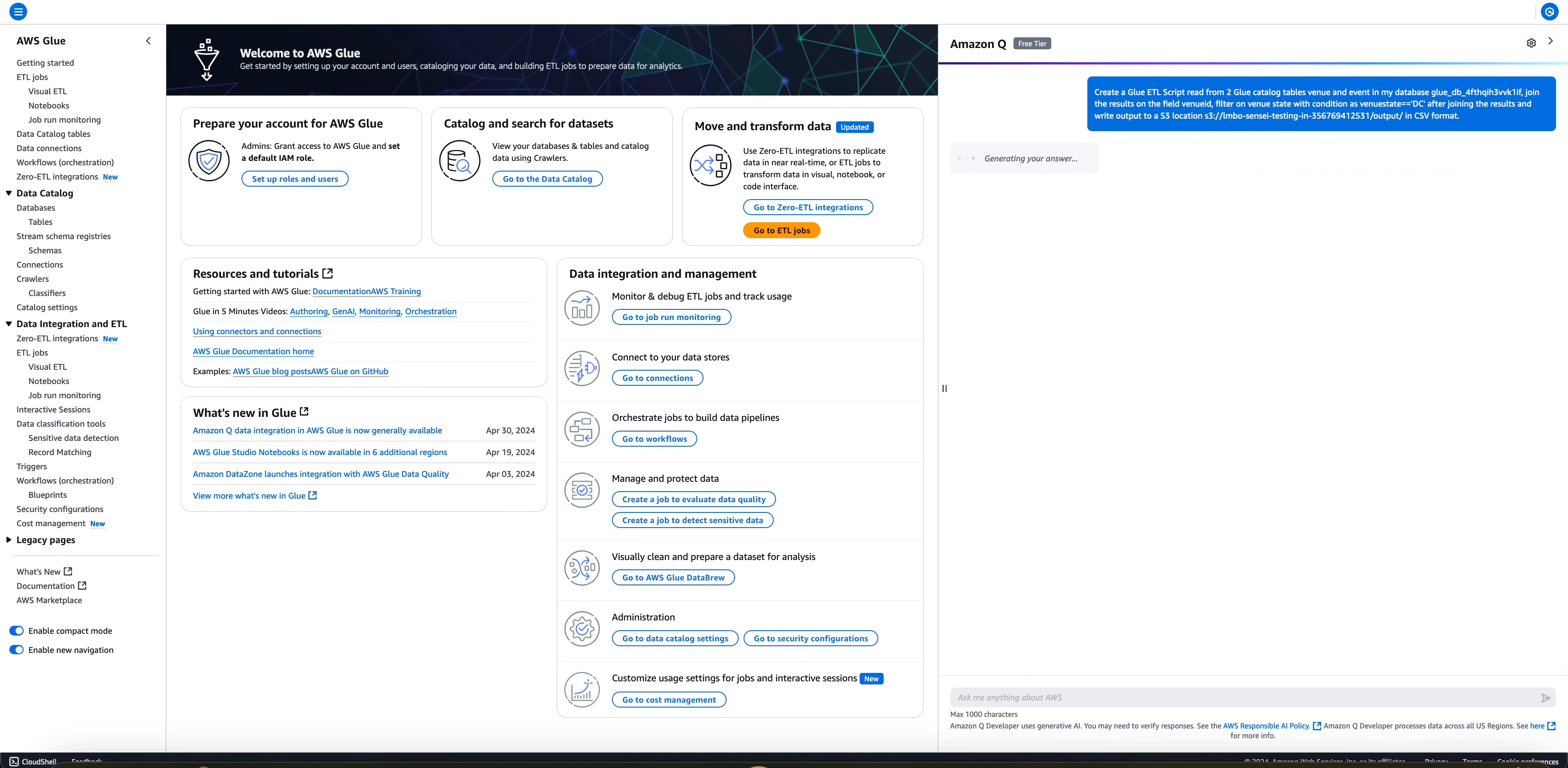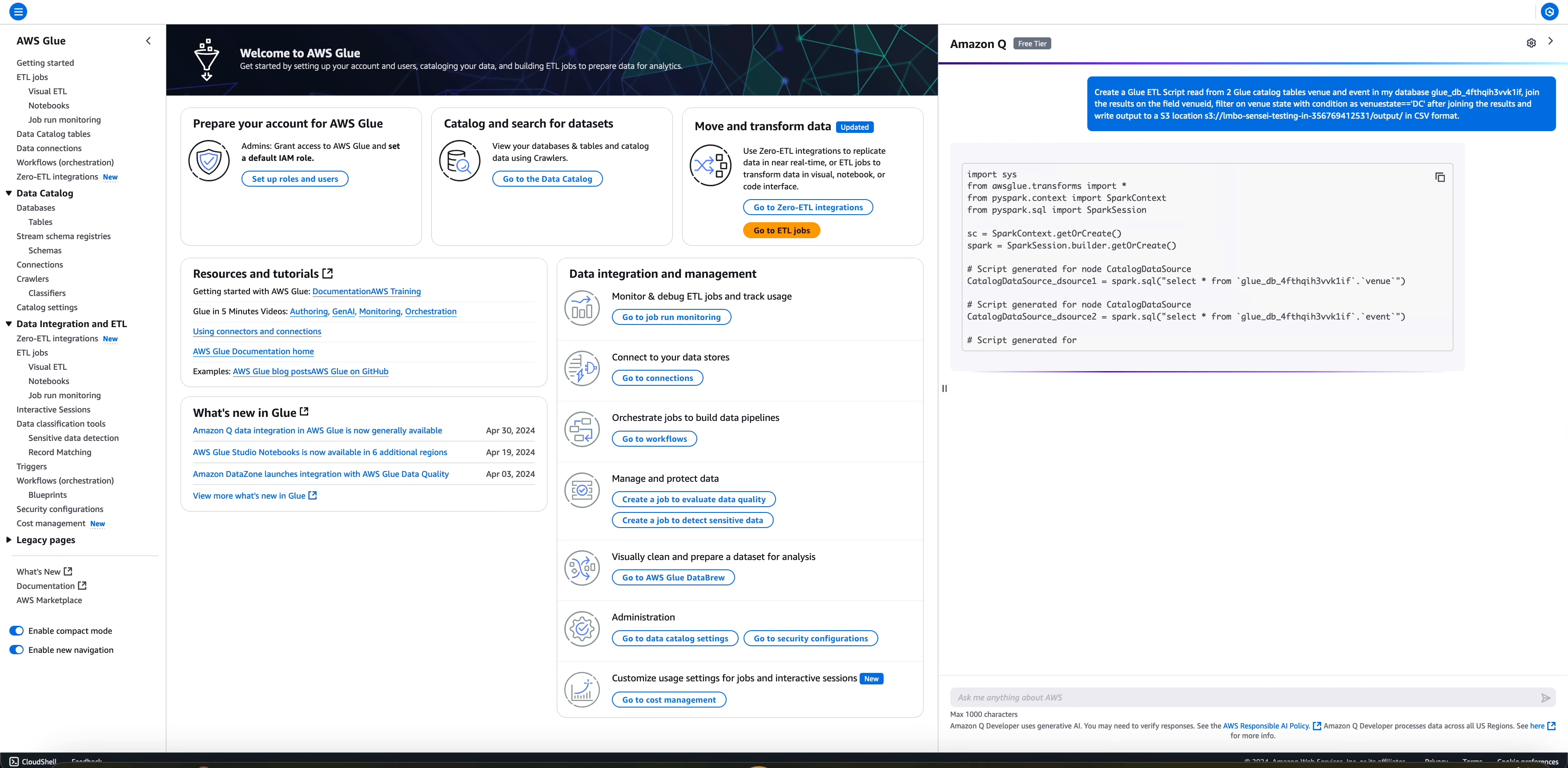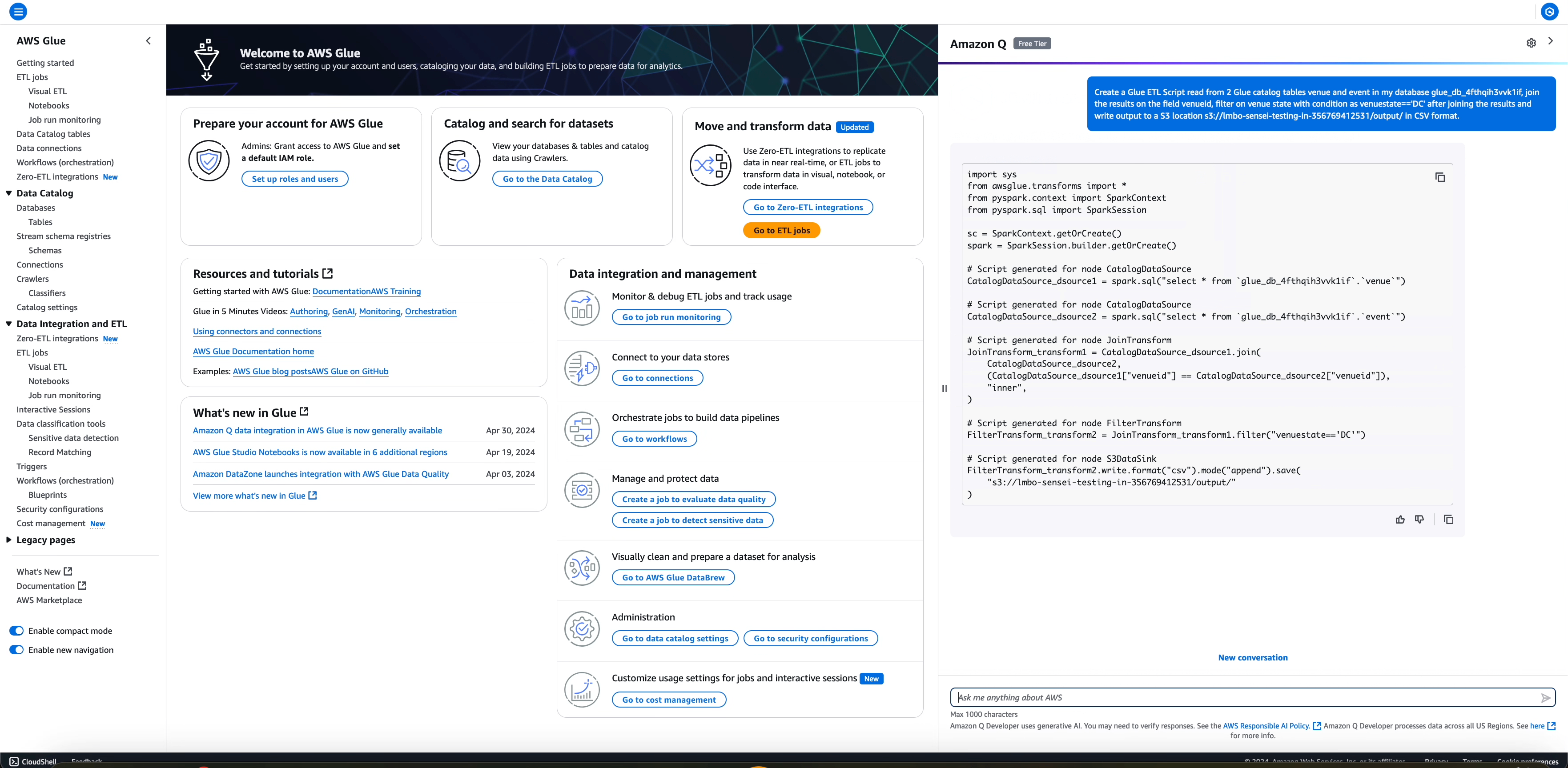
Das folgende Beispiel zeigt, wie Sie AWS Glue bitten können, ein AWS Glue-Skript zu erstellen, um einen vollständigen ETL-Workflow mit der folgenden Aufforderung abzuschließen:Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database
glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC'
after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format.
Der Workflow umfasst das Lesen aus verschiedenen Datenquellen (zwei AWS Glue Data Catalog-Tabellen) und einige Transformationen nach dem Lesen, indem das Ergebnis aus zwei Lesungen zusammengeführt, nach bestimmten Bedingungen gefiltert und die transformierte Ausgabe im CSV-Format an ein Amazon S3 S3-Ziel geschrieben wird.
Der generierte Auftrag füllt die detaillierten Informationen in die Datenquelle ein, transformiert sie und leitet sie an die Senke weiter, wobei die entsprechenden Informationen aus der Benutzerfrage wie unten angegeben extrahiert werden.
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node CatalogDataSource CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`") # Script generated for node CatalogDataSource CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`") # Script generated for node JoinTransform JoinTransform_transform1 = CatalogDataSource_dsource1.join( CatalogDataSource_dsource2, (CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]), "inner", ) # Script generated for node FilterTransform FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'") # Script generated for node S3DataSink FilterTransform_transform2.write.format("csv").mode("append").save( "s3://amz-s3-demo-bucket/output//output/" )
Einschränkungen
-
Kontextübertragung:
-
Das Feature zur Kontexterkennung überträgt nur den Kontext aus der vorherigen Benutzerfrage innerhalb derselben Konversation. Der Kontext über die unmittelbar vorhergehende Frage hinaus wird nicht beibehalten.
-
-
Support für Knotenkonfigurationen:
-
Derzeit unterstützt die Kontexterkennung nur eine Teilmenge der erforderlichen Konfigurationen für verschiedene Knoten.
-
Die Unterstützung für optionale Felder ist in zukünftigen Versionen geplant.
-
-
Verfügbarkeit:
-
Kontextsensitivität und DataFrame Support sind in Q Chat- und SageMaker Unified Studio-Notebooks verfügbar. Diese Funktionen sind jedoch in AWS Glue Studio-Notebooks noch nicht verfügbar.
-
