Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Speichern von Spark-Shuffle-Daten
Shuffling ist ein wichtiger Schritt in einem Spark-Job, wenn Daten zwischen Partitionen neu angeordnet werden. Dies ist erforderlich, da umfassende Transformationen wie join,
groupByKey, reduceByKey und repartition Informationen von anderen Partitionen benötigen, um die Verarbeitung abzuschließen. Spark sammelt die erforderlichen Daten von jeder Partition und kombiniert sie zu einer neuen Partition. Beim Mischen werden Daten auf die Festplatte geschrieben und über das Netzwerk übertragen. Infolgedessen ist der Shuffle-Vorgang an die lokale Festplattenkapazität gebunden. Spark gibt den Fehler No space left on device oder den Fehler
MetadataFetchFailedException aus, wenn auf dem Executor nicht genügend Speicherplatz übrig ist und keine Wiederherstellung vorliegt.
Anmerkung
AWS Glue Das Spark-Shuffle-Plugin mit Amazon S3 wird nur für AWS Glue ETL-Jobs unterstützt.
Lösung
Mit können Sie jetzt Amazon S3 verwendenAWS Glue, um Spark-Shuffle-Daten mithilfe des Cloud Shuffle Storage Plug-ins zu speichern. Amazon S3 ist ein Objektspeicherservice, der branchenführende Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung bietet. Diese Lösung teilt Rechenleistung und Speicher für Ihre Spark-Aufträge auf und bietet vollständige Elastizität und kostengünstigen Shuffle-Speicher, sodass Sie Ihre Shuffle-intensiven Workloads zuverlässig ausführen können.
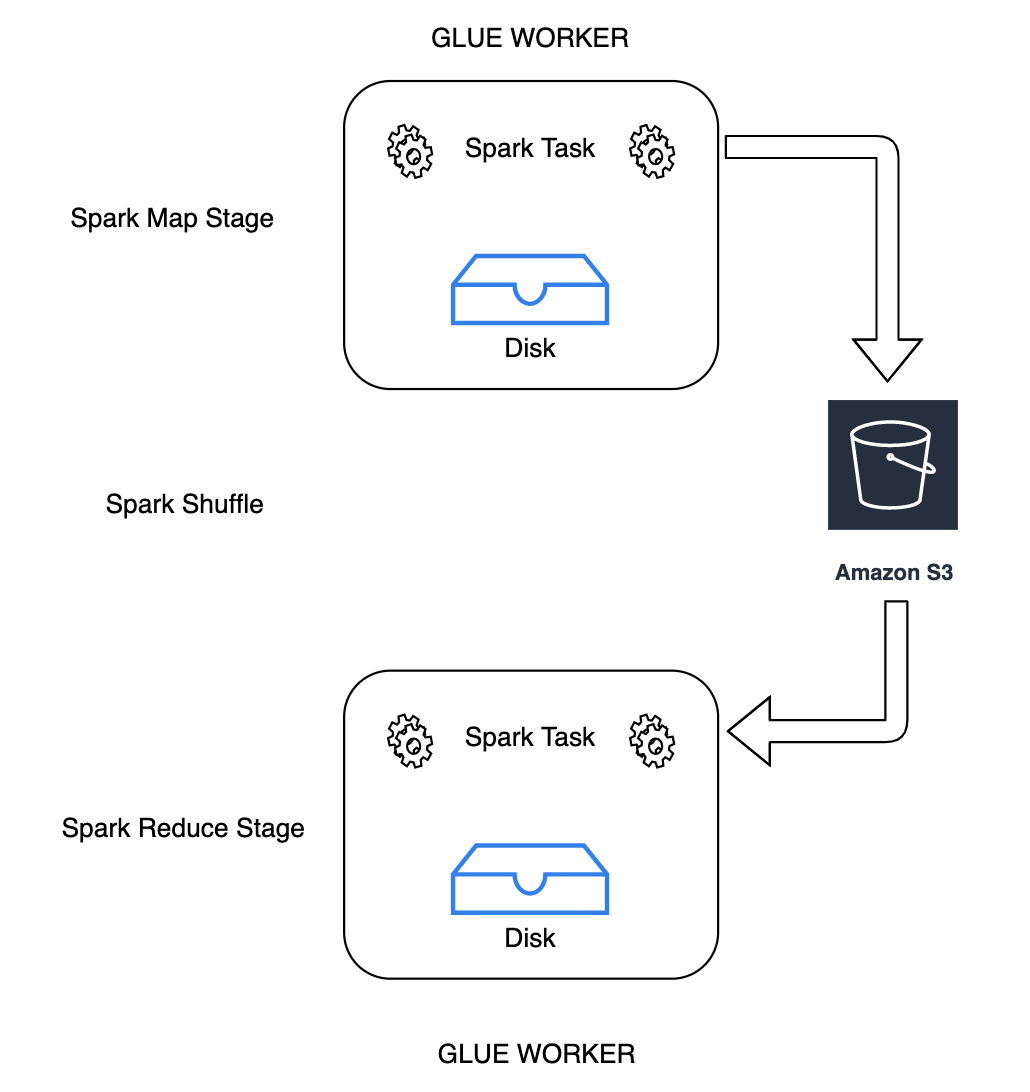
Sie können Amazon-S3-Shuffling aktivieren, um Ihre AWS Glue-Aufträge zuverlässig ohne Fehler auszuführen, wenn bekannt ist, dass sie durch die lokale Festplattenkapazität für große Shufflevorgänge gebunden sind. In einigen Fällen ist das Shuffling zu Amazon S3 geringfügig langsamer als die lokale Festplatte (oder EBS), wenn Sie eine große Anzahl kleiner Partitionen oder Shuffle-Dateien haben, die in Amazon S3 geschrieben wurden.
Voraussetzungen für die Verwendung des Cloud-Shuffle-Speicher-Plugins
Um das Cloud Shuffle Storage Plugin mit AWS Glue ETL-Jobs verwenden zu können, benötigen Sie Folgendes:
-
Ein Amazon-S3-Bucket, der sich in der gleichen Region befindet, in der Ihr Auftrag ausgeführt wird, um die Shuffle- und Ausgabedaten zwischenzuspeichern. Das Amazon-S3-Präfix des Shuffle-Speichers kann wie im folgenden Beispiel mit
--conf spark.shuffle.glue.s3ShuffleBucket=s3://angegeben werden:shuffle-bucket/prefix/--conf spark.shuffle.glue.s3ShuffleBucket=s3://glue-shuffle-123456789-us-east-1/glue-shuffle-data/ -
Legen Sie die Lebenszyklusrichtlinien für den Amazon-S3-Speicher auf das Präfix fest (z. B.
glue-shuffle-data), da der Shuffle-Manager die Dateien nach Abschluss der Aufgabe nicht bereinigt. Die dazwischen liegenden Shuffle- und Ausgabedaten sollten nach Beendigung eines Auftrags gelöscht werden. Benutzer können Richtlinien für einen kurzen Lebenszyklus für das Präfix festlegen. Anweisungen zum Einrichten einer Amazon-S3-Lebenszyklusrichtlinie finden Sie unter Lebenszykluskonfiguration für einen Bucket festlegen im Benutzerhandbuch für Amazon Simple Storage Service.
Verwenden AWS Glue Spark Shuffle Manager von AWS Konsole
So richten Sie AWS Glue-Spark-Shuffle-Manager mit der AWS Glue-Konsole oder AWS Glue Studio bei der Konfiguration eines Auftrags ein: Wählen Sie den Auftragsparameter --write-shuffle-files-to-s3, um Amazon-S3-Shuffling für den Auftrag zu aktivieren.
Verwenden AWS Glue Spark-Shuffle-Plugin
Die folgenden Auftragsparameter aktivieren und optimieren die AWS Glue-Shuffle-Manager. Da es sich bei diesen Parametern um Flags handelt, werden die angegebenen Werte nicht berücksichtigt.
Wichtig
Um Amazon S3 S3-Shuffling zu deaktivieren, müssen Sie den --write-shuffle-files-to-s3 Parameter vollständig aus Ihrer Jobkonfiguration entfernen. Wenn Sie den Wert auf setzen, wird Amazon S3 S3-Shuffling false nicht deaktiviert — der Parameter fungiert als präsenzbasiertes Flag, was bedeutet, dass jeder Wert (einschließlichfalse) Amazon S3 S3-Shuffling aktiviert, wenn der Parameter vorhanden ist.
-
--write-shuffle-files-to-s3– Der wichtigste Flag, der den AWS Glue-Spark-Shuffle-Manager aktiviert, um Amazon-S3-Buckets zum Schreiben und Lesen von Shuffle-Daten zu verwenden. Wenn das Flag nicht angegeben ist, wird der Shuffle-Manager nicht verwendet. -
--write-shuffle-spills-to-s3– (Nur von AWS Glue-Version 2.0 unterstützt). Ein optionales Flag, mit dem Sie Ausgabeateien in Amazon-S3-Buckets auslagern können, was zusätzliche Ausfallsicherheit für Ihren Spark-Auftrag bereitstellt. Das ist nur bei großen Workloads erforderlich, bei denen viele Daten unabsichtlich auf der Festplatte landen. Wenn das Flag nicht angegeben ist, werden keine Ausgabe-Zwischendateien geschrieben. -
--conf spark.shuffle.glue.s3ShuffleBucket=s3://<shuffle-bucket>– Ein weiterer optionaler Parameter, der den Amazon S3 Bucket angibt, in den Sie die Shuffle-Dateien schreiben. Standardmäßig /shuffle-data.--TempDirAWS Glue 3.0+ unterstützt das Schreiben von Shuffle-Dateien in mehrere Buckets, indem Buckets mit einem Kommatrennzeichen angegeben werden, wie in.--conf spark.shuffle.glue.s3ShuffleBucket=s3://Die Verwendung mehrerer Buckets verbessert die Leistung.shuffle-bucket-1/prefix,s3://shuffle-bucket-2/prefix/
Sie müssen Sicherheitskonfigurationseinstellungen vornehmen, um die Verschlüsselung im Ruhezustand für die Shuffle-Daten zu aktivieren. Weitere Informationen zu Sicherheitskonfigurationen finden Sie unterEinrichten der Verschlüsselung in AWS Glue. AWS Glue unterstützt alle anderen Shuffle-bezogenen Konfigurationen, die von Spark bereitgestellt werden.
Software-Binärdateien für das Cloud-Shuffle-Speicher-Plugin
Sie können auch die Software-Binärdateien des Cloud-Shuffle-Speicher-Plugins für Apache Spark unter der Apache-2.0-Lizenz herunterladen und in jeder Spark-Umgebung ausführen. Das neue Plugin wird mit sofort einsatzbereiter Unterstützung für Amazon S3 geliefert und kann problemlos für die Verwendung anderer Cloud-Speicherformen wie Google Cloud Storage und Microsoft Azure Blob Storage
Hinweise und Einschränkungen
Im Folgenden finden Sie Hinweise oder Einschränkungen für den AWS Glue-Shuffle-Manager:
-
AWS Glue Shuffle Manager löscht die (temporären) Shuffle-Datendateien, die in Ihrem Amazon S3 S3-Bucket gespeichert sind, nicht automatisch, nachdem ein Job abgeschlossen ist. Befolgen Sie zur Gewährleistung des Datenschutzes die Anweisungen in Voraussetzungen für die Verwendung des Cloud-Shuffle-Speicher-Plugins, bevor Sie das Cloud-Shuffle-Speicher-Plugin aktivieren.
-
Sie können dieses Feature verwenden, wenn Ihre Daten verzerrt sind.
