Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrating AWS Glue für Spark-Jobs zu AWS Glue Version 5.0
In diesem Thema werden die Änderungen zwischen den AWS Glue Versionen 0.9, 1.0, 2.0, 3.0 und 4.0 beschrieben, die es Ihnen ermöglichen, Ihre Spark-Anwendungen und ETL-Jobs auf AWS Glue 5.0 zu migrieren. Außerdem werden die Funktionen in AWS Glue 5.0 und die Vorteile seiner Verwendung beschrieben.
Um diese Funktion mit Ihren AWS Glue ETL-Jobs zu verwenden, wählen Sie 5.0 Glue version bei der Erstellung Ihrer Jobs die Option.
Neue Features
In diesem Abschnitt werden die neuen Funktionen und Vorteile von AWS Glue Version 5.0 beschrieben.
-
Apache Spark-Update von 3.3.0 in AWS Glue 4.0 auf 3.5.4 in AWS Glue 5.0. Siehe Wesentliche Verbesserungen von Spark 3.3.0 zu Spark 3.5.4.
-
Spark-native feinkörnige Zugangskontrolle (FGAC) mit Lake Formation. Dazu gehört FGAC für Iceberg-, Delta- und Hudi-Tabellen. Weitere Informationen finden Sie unter Verwenden von AWS Glue with AWS Lake Formation für eine detaillierte Zugriffskontrolle.
Beachten Sie die folgenden Überlegungen oder Einschränkungen für Spark-native FGAC:
Derzeit werden Datenschreibvorgänge nicht unterstützt.
Das Schreiben in Iceberg über
GlueContextmit Lake Formation erfordert stattdessen die Verwendung der IAM-Zugriffskontrolle.
Eine vollständige Liste der Einschränkungen und Überlegungen bei der Verwendung von Spark-native FGAC finden Sie unter. Überlegungen und Einschränkungen
-
Support für Amazon S3 Access Grants als skalierbare Zugriffskontrolllösung für Ihre Amazon S3 S3-Daten von AWS Glue. Weitere Informationen finden Sie unter Verwenden von Amazon S3 Access Grants mit AWS Glue.
-
Open Table Formats (OTF) wurden auf Hudi 0.15.0, Iceberg 1.7.1 und Delta Lake 3.3.0 aktualisiert.
-
Unterstützung für Amazon SageMaker Unified Studio.
-
Amazon SageMaker Lakehouse und Integration der Datenabstraktion. Weitere Informationen finden Sie unter Abfragen von Metastore-Datenkatalogen von AWS Glue ETL.
-
Unterstützung für die Installation zusätzlicher Python-Bibliotheken mithilfe von
requirements.txt. Weitere Informationen finden Sie unter Installation zusätzlicher Python-Bibliotheken in AWS Glue 5.0 oder höher mit requirements.txt. -
AWS Glue 5.0 unterstützt Data Lineage in Amazon DataZone. Sie können so konfigurieren AWS Glue , dass während der Ausführung von Spark-Jobs automatisch Herkunftsinformationen gesammelt und die Herkunftsereignisse zur Visualisierung in Amazon gesendet werden. DataZone Weitere Informationen finden Sie unter Data Lineage in Amazon DataZone.
Um dies in der AWS Glue Konsole zu konfigurieren, aktivieren Sie Generate Lineage Events und geben Sie Ihre DataZone Amazon-Domain-ID auf der Registerkarte Jobdetails ein.
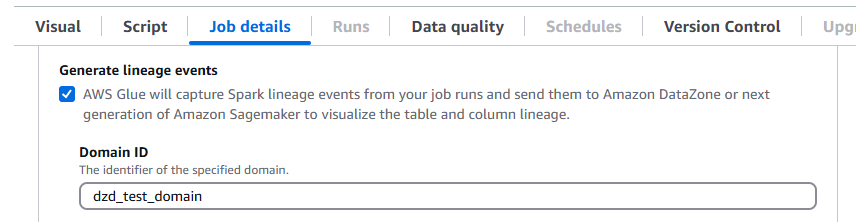
Alternativ können Sie den folgenden Job-Parameter angeben (geben Sie Ihre DataZone Domain-ID an):
Schlüssel:
--confWert:
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
Connector- und JDBC-Treiber-Updates. Weitere Informationen erhalten Sie unter Anhang B: Aktualisierungen von JDBC-Treibern und Anhang C: Konnektor-Upgrades.
-
Java-Update von 8 auf 17.
-
Erhöhung des Speicherplatzes für
G.2XMitarbeiter AWS GlueG.1Xund Erhöhung des Festplattenspeichers auf 94 GB bzw. 138 GB Darüber hinaus sind neue Worker-Typen und speicheroptimierteG.12XG.16X,R.1X,R.2XR.4X, in AWS Glue Version 4.0 undR.8Xspäteren Versionen verfügbar. Weitere Informationen finden Sie unter Jobs. Jobs, die AWS SDK for Java, Version AWS Glue 2-5.0 Support, können die Java-Versionen 1.12.569
oder 2.28.8 verwenden, wenn der Job v2 unterstützt. Das AWS SDK for Java 2.x ist eine umfassende Neufassung der Codebasis von Version 1.x. Sie basiert auf Java 8+ und fügt mehrere häufig angeforderte Funktionen hinzu. Dazu gehören die Unterstützung von Non-Blocking und die Möglichkeit I/O, zur Laufzeit eine andere HTTP-Implementierung einzubinden. Weitere Informationen, einschließlich eines Migrationshandbuchs von SDK für Java v1 zu v2, finden Sie im Handbuch AWS SDK für Java, Version 2.
Abwärtskompatible Änderungen
Beachten Sie die folgenden grundlegenden Änderungen:
-
Wenn in AWS Glue 5.0 das S3A-Dateisystem verwendet wird und sowohl `fs.s3a.endpoint` als auch `fs.s3a.endpoint.region` nicht gesetzt sind, ist die von S3A verwendete Standardregion `us-east-2`. Dies kann zu Problemen wie Timeout-Fehlern beim S3-Upload führen, insbesondere bei VPC-Aufträgen. Um die durch diese Änderung verursachten Probleme zu beheben, legen Sie die Spark-Konfiguration `fs.s3a.endpoint.region` fest, wenn Sie das AWS Glue S3A-Dateisystem in 5.0 verwenden.
-
Fine-grained Zugangskontrolle für Lake Formation (FGAC)
-
AWS Glue 5.0 unterstützt nur das neue Spark-native FGAC mit Spark. DataFrames Die Verwendung von FGAC wird nicht unterstützt. AWS Glue DynamicFrames
-
Die Verwendung von FGAC in 5.0 erfordert eine Migration von zu Spark AWS Glue DynamicFrames DataFrames
-
Wenn Sie FGAC nicht benötigen, ist es nicht notwendig, zu Spark zu migrieren, DataFrame und GlueContext Funktionen wie Job-Lesezeichen und Push-Down-Prädikate funktionieren weiterhin.
-
-
Jobs mit Spark-native FGAC erfordern mindestens 4 Mitarbeiter: einen Benutzertreiber, einen Systemtreiber, einen System-Executor und einen Standby-User-Executor.
-
Weitere Informationen finden Sie unter Verwenden AWS Glue von with für eine detaillierte Zugriffskontrolle. AWS Lake Formation
-
-
Lake Formation – vollständiger Tabellenzugriff (FTA)
-
AWS Glue 5.0 unterstützt FTA mit Spark-native DataFrames (neu) und GlueContext DynamicFrames (veraltet, mit Einschränkungen)
-
Spark-native FTA
-
Wenn das 4.0-Skript verwendet wird GlueContext, wechseln Sie zur Verwendung von nativem Spark.
-
Dieses Feature ist auf Hive- und Iceberg-Tabellen beschränkt.
-
Weitere Informationen zur Konfiguration eines 5.0-Jobs für die Verwendung von Spark Native FTA finden Sie unterNatives Spark-FTA in 5.0 AWS Glue.
-
-
GlueContext DynamicFrame FTA
-
Keine Codeänderung erforderlich
-
Dieses Feature ist auf Nicht-OTF-Tabellen beschränkt – es funktioniert nicht mit Iceberg, Delta Lake und Hudi.
-
-
Der vektorisierte SIMD-CSV-Reader wird nicht unterstützt.
Die kontinuierliche Protokollierung in der Ausgabeprotokollgruppe wird nicht unterstützt. Verwenden Sie stattdessen die Protokollgruppe
error.Der AWS Glue Job Run Insights
job-insights-rule-driverist veraltet. Der Protokollstreamjob-insights-rca-driverbefindet sich jetzt in der Fehlerprotokollgruppe.Athena-based custom/marketplace Konnektoren werden nicht unterstützt.
Die Konnektoren für Adobe Marketo Engage, Facebook Ads, Google Analytics 4, Google Sheets, Hubspot, Instagram Ads, Intercom, Jira Cloud, Oracle, Salesforce, Salesforce Marketing Cloud NetSuite, Salesforce Marketing Cloud Account Engagement, SAP OData,, Slack, Snapchat Ads ServiceNow, Stripe, Zendesk und Zoho CRM werden nicht unterstützt.
Benutzerdefinierte log4j-Eigenschaften werden in 5.0 nicht unterstützt. AWS Glue
Wesentliche Verbesserungen von Spark 3.3.0 zu Spark 3.5.4
Berücksichtigen Sie die folgenden Verbesserungen:
-
Python-Client für Spark Connect (SPARK-39375
). -
Implementieren Sie die Unterstützung für DEFAULT-Werte für Spalten in Tabellen (SPARK-38334
). -
Support „Lateral Column Alias References“ (SPARK-27561
). -
Versichern Sie die Verwendung von SQLSTATE für Fehlerklassen () SPARK-41994
. -
Aktiviert standardmäßig den Bloom-Filter Joins () SPARK-38841
. -
Bessere Skalierbarkeit und Treiberstabilität der Spark-Benutzeroberfläche für große Anwendungen (SPARK-41053
). -
Asynchrone Fortschrittsverfolgung im strukturierten Streaming (SPARK-39591
). -
Beliebige zustandsbehaftete Python-Verarbeitung in strukturiertem Streaming (SPARK-40434
). -
Verbesserungen der Pandas-API-Abdeckung (SPARK-42882
) und NumPy Eingabeunterstützung in PySpark (SPARK-39405 ). -
Stellen Sie einen Speicherprofiler für PySpark benutzerdefinierte Funktionen bereit (). SPARK-40281
-
Implementieren Sie den PyTorch Verteiler () SPARK-41589
. -
Veröffentlichen Sie SBOM-Artefakte () SPARK-41893
. -
IPv6-only Unterstützungsumgebung (SPARK-39457
). -
Kundenspezifischer K8s-Scheduler (Apache YuniKorn und Volcano) GA (). SPARK-42802
-
Unterstützung für Scala- und Go-Clients in Spark Connect (SPARK-42554
) und (SPARK-43351 ). -
PyTorch-based verteilte ML-Unterstützung für Spark Connect (SPARK-42471
). -
Strukturierte Streaming-Unterstützung für Spark Connect in Python und Scala (SPARK-42938
). -
Pandas-API-Unterstützung für den Python Spark Connect Client (SPARK-42497
). -
Führen Sie Arrow Python UDFs (SPARK-40307
) ein. -
Support benutzerdefinierte Python-Tabellenfunktionen (SPARK-43798
). -
Migrieren Sie PySpark Fehler auf Fehlerklassen (SPARK-42986
). -
PySpark Testframework (SPARK-44042
). -
Unterstützung für Datasketches HllSketch () hinzugefügt. SPARK-16484
-
Built-in Verbesserung der SQL-Funktion (). SPARK-41231
-
IDENTIFIER-Klausel (SPARK-43205
). -
Fügen Sie SQL-Funktionen zu Scala, Python und R API hinzu (SPARK-43907
). -
Fügen Sie Unterstützung für benannte Argumente für SQL-Funktionen hinzu (SPARK-43922
). -
Vermeiden Sie unnötige Wiederholungen von Aufgaben auf einem außer Betrieb genommenen Executor, der verloren geht, wenn Shuffle-Daten migriert werden (). SPARK-41469
-
Verteiltes ML <> Spark Connect (). SPARK-42471
-
DeepSpeed Verteiler (SPARK-44264
). -
Implementieren Sie das Changelog-Checkpointing für RocksDB State Store (). SPARK-43421
-
Führen Sie die Ausbreitung von Wasserzeichen zwischen Operatoren ein (). SPARK-42376
-
Führen Sie drop DuplicatesWithinWatermark (SPARK-42931
) ein. -
Verbesserungen bei der Speicherverwaltung des RocksDB State Store Providers () SPARK-43311
.
Aktionen, zu denen migriert werden soll AWS Glue 5.0
Ändern Sie bei vorhandenen Aufträgen die Glue version von der vorherigen Version auf Glue 5.0 in der Auftragskonfiguration.
-
Wählen Sie in AWS Glue Studio
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3inGlue version. -
Wählen Sie in der API
5.0imGlueVersion-Parameter in derUpdateJob-API-Operation aus.
Wählen Sie für neue Aufträge Glue 5.0 aus, wenn Sie Aufträge erstellen.
-
Wählen Sie in der Konsole
Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)in derGlue versionaus. -
Wählen Sie in AWS Glue Studio die Option
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3InGlue version. -
Wählen Sie in der API
5.0imGlueVersion-Parameter in derCreateJob-API-Operation aus.
Um Spark-Ereignisprotokolle von AWS Glue 5.0 aus Version AWS Glue 2.0 oder früher anzuzeigen, starten Sie einen aktualisierten Spark-Verlaufsserver für AWS Glue 5.0 mit CloudFormation oder Docker.
Checkliste für die Migration
Überprüfen Sie diese Checkliste für die Migration:
-
Java-17-Aktualisierungen
-
[Scala] Führen Sie ein Upgrade von AWS SDK-Aufrufen von Version 1 auf Version 2 durch
-
Migration von Python 3.10 auf 3.11
-
[Python] Aktualisierung der Boto-Referenzen von 1.26 auf 1.34
AWS Glue 5.0-Funktionen
In diesem Abschnitt werden die AWS Glue Funktionen ausführlicher beschrieben.
Abfragen von Metastore-Datenkatalogen von AWS Glue ETL
Sie können Ihren AWS Glue Job registrieren, um auf die zuzugreifen AWS Glue Data Catalog, wodurch Tabellen und andere Metastore-Ressourcen unterschiedlichen Benutzern zur Verfügung stehen. Der Datenkatalog unterstützt eine Hierarchie mit mehreren Katalogen, die alle Ihre Daten in Data Lakes von Amazon S3 vereinheitlicht. Er bietet außerdem eine Hive-Metastore-API und eine Open-Source-API von Apache Iceberg für den Datenzugriff. Diese Funktionen sind für AWS Glue und andere datenorientierte Dienste wie Amazon EMR, Amazon Athena und Amazon Redshift verfügbar.
Wenn Sie Ressourcen im Datenkatalog erstellen, können Sie von jeder SQL-Engine aus darauf zugreifen, die die Apache Iceberg REST-API unterstützt. AWS Lake Formation verwaltet Berechtigungen. Nach der Konfiguration können Sie die Funktionen nutzen AWS Glue, um unterschiedliche Daten abzufragen, indem Sie diese Metastore-Ressourcen mit vertrauten Anwendungen abfragen. Dazu gehören Apache Spark und Trino.
So werden Metadatenressourcen organisiert
Die Daten werden in einer logischen Hierarchie von Katalogen, Datenbanken und Tabellen organisiert, wobei Folgendes verwendet wird: AWS Glue Data Catalog
Katalog: Ein logischer Container, der Objekte aus einem Datenspeicher wie Schemata oder Tabellen enthält.
Datenbank: Organisiert Datenobjekte wie Tabellen und Ansichten in einem Katalog.
Tabellen und Ansichten: Datenobjekte in einer Datenbank, die eine Abstraktionsschicht mit einem verständlichen Schema bereitstellen. Sie erleichtern den Zugriff auf zugrunde liegende Daten, die in verschiedenen Formaten und an verschiedenen Orten vorliegen können.
Migration von AWS Glue 4.0 bis AWS Glue 5.0
Alle bestehenden Jobparameter und wichtigen Funktionen, die in AWS Glue 4.0 vorhanden sind, werden in AWS Glue 5.0 verfügbar sein, mit Ausnahme von Transformationen für maschinelles Lernen.
Folgende neue Parameter wurden hinzugefügt:
-
--enable-lakeformation-fine-grained-access: Aktiviert die FGAC-Funktion (Fine-Grained Access Control) in AWS Lake Formation-Tabellen.
Weitere Informationen finden Sie in der Dokumentation zur Spark-Migration:
Migration von AWS Glue 3.0 bis AWS Glue 5.0
Anmerkung
Informationen zu Migrationsschritten im Zusammenhang mit AWS Glue 4.0 finden Sie unterMigration von AWS Glue 3.0 auf 4.0 AWS Glue.
Alle bestehenden Jobparameter und Hauptfunktionen, die in AWS Glue 3.0 vorhanden sind, werden auch in AWS Glue 5.0 verfügbar sein, mit Ausnahme von Transformationen für maschinelles Lernen.
Migration von AWS Glue 2,0 bis AWS Glue 5.0
Anmerkung
Migrationsschritte im Zusammenhang mit AWS Glue 4.0 und eine Liste der Migrationsunterschiede zwischen AWS Glue Version 3.0 und 4.0 finden Sie unterMigration von AWS Glue 3.0 auf 4.0 AWS Glue.
Beachten Sie auch die folgenden Migrationsunterschiede zwischen den AWS Glue Versionen 3.0 und 2.0:
Alle bestehenden Jobparameter und Hauptfunktionen, die es in AWS Glue 2.0 gibt, werden auch in AWS Glue 5.0 verfügbar sein, mit Ausnahme von Transformationen für maschinelles Lernen.
Einige Spark-Änderungen allein erfordern möglicherweise eine Überarbeitung Ihrer Skripte, um sicherzustellen, dass entfernte Features nicht referenziert werden. Zum Beispiel aktiviert Spark 3.1.1 und höher keine Scala-untyped UDFs, aber Spark 2.4 erlaubt sie.
Python 2.7 wird nicht unterstützt.
Alle zusätzlichen Jar-Dateien, die in bestehenden AWS Glue 2.0-Jobs bereitgestellt wurden, können zu widersprüchlichen Abhängigkeiten führen, da es in mehreren Abhängigkeiten Upgrades gab. Sie können Klassenpfadkonflikte mit dem
--user-jars-first-Auftragsparameter vermeiden.Änderungen am Verhalten loading/saving von Parquet-Dateien mit Zeitstempel from/to . Weitere Informationen finden Sie unter Upgrade von Spark SQL 3.0 auf 3.1.
Unterschiedliche Parallelität der Spark-Tasks für die Konfiguration. driver/executor Sie können die Parallelität von Aufgaben anpassen, indem Sie das Auftragsargument
--executor-coresübergeben.
Verhaltensänderungen protokollieren in AWS Glue 5.0
Im Folgenden sind die Änderungen des Protokollierungsverhaltens in AWS Glue 5.0 aufgeführt. Weitere Informationen finden Sie unter Protokollierung von AWS Glue Aufträgen.
-
Alle Protokolle (Systemprotokolle, Spark-Daemon-Protokolle, Benutzerprotokolle und Glue-Logger-Protokolle) werden nun standardmäßig in die
/aws-glue/jobs/error-Protokollgruppe geschrieben. -
Die in früheren Versionen für die kontinuierliche Protokollierung verwendete
/aws-glue/jobs/logs-v2-Protokollgruppe wird nicht mehr verwendet. -
Sie können die Namen der Protokollgruppen oder Protokollstreams nicht mehr mit den entfernten Argumenten für die kontinuierliche Protokollierung umbenennen oder anpassen. Sehen Sie sich stattdessen die neuen Job-Argumente in AWS Glue 5.0 an.
Zwei neue Job-Argumente werden in eingeführt AWS Glue 5.0
-
––custom-logGroup-prefix: Ermöglicht es Ihnen, ein benutzerdefiniertes Präfix für die Protokollgruppen/aws-glue/jobs/errorund/aws-glue/jobs/outputanzugeben. -
––custom-logStream-prefix: Ermöglicht es Ihnen, ein benutzerdefiniertes Präfix für die Namen der Protokollstreams innerhalb der Protokollgruppen anzugeben.Zu den Validierungsregeln und Einschränkungen für benutzerdefinierte Präfixe gehört Folgendes:
-
Der Name des Protokollstreams muss insgesamt zwischen 1 und 512 Zeichen lang sein.
-
Das benutzerdefinierte Präfix für Namen für Protokollstreams ist auf 400 Zeichen begrenzt.
-
Zu den zulässigen Zeichen in Präfixen gehören alphanumerische Zeichen, Unterstriche (_), Bindestriche (-) und Schrägstriche (/).
-
Veraltete Argumente für die kontinuierliche Protokollierung in AWS Glue 5.0
Die folgenden Job-Argumente für die kontinuierliche Protokollierung sind in 5.0 veraltet AWS Glue
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Migration von Konnektoren und JDBC-Treibern für AWS Glue 5.0
Die aktualisierten Versionen von JDBC- und Data-Lake-Konnektoren finden Sie unter:
Die folgenden Änderungen gelten für die Connector- oder Treiberversionen, die in den Anhängen für Glue 5.0 aufgeführt sind.
Amazon Redshift
Beachten Sie folgende Änderungen:
Integriert die Unterstützung für dreiteilige Tabellennamen, damit der Connector Redshift-Datenfreigabetabellen abfragen kann.
Korrigiert die Zuordnung von Spark
ShortType, um RedshiftSMALLINTanstelle vonINTEGERzu verwenden, um die erwartete Datengröße besser anzupassen.Unterstützung für benutzerdefinierte Clusternamen (CNAME) für Amazon Redshift Serverless hinzugefügt.
Apache Hudi
Beachten Sie folgende Änderungen:
Unterstützung für Indexierung auf Datensatzebene.
Unterstützung für die automatische Generierung von Datensatzschlüsseln. Sie müssen das Datensatzschlüsselfeld jetzt nicht mehr angeben.
Apache Iceberg
Beachten Sie folgende Änderungen:
Support Sie eine feinkörnige Zugriffskontrolle mit. AWS Lake Formation
Unterstützt Verzweigen und Markieren, d. h. benannte Verweise auf Snapshots mit eigenen, unabhängigen Lebenszyklen.
Ein neues Verfahren zur Änderungsprotokollansicht generiert eine Ansicht, die die Änderungen an einer Tabelle über einen bestimmten Zeitraum oder zwischen bestimmten Snapshots enthält.
Delta Lake
Beachten Sie folgende Änderungen:
Support Delta Universal Format (UniForm), das einen nahtlosen Zugriff über Apache Iceberg und Apache Hudi ermöglicht.
Support Löschvektoren, die ein Merge-on-Read Paradigma implementieren.
AzureCosmos
Beachten Sie folgende Änderungen:
Unterstützung für hierarchische Partitionsschlüssel hinzugefügt.
Option hinzugefügt, um ein benutzerdefiniertes Schema mit StringType (rohes JSON) für eine verschachtelte Eigenschaft zu verwenden.
Es wurde eine Konfigurationsoption hinzugefügt
spark.cosmos.auth.aad.clientCertPemBase64, um die Verwendung der SPN-Authentifizierung (ServicePrincipal Name) mit Zertifikat anstelle des geheimen Client-Schlüssels zu ermöglichen.
Weitere Informationen finden Sie im Änderungsprotokoll des Spark-Connectors von Azure Cosmos DB.
Microsoft SQL Server
Beachten Sie folgende Änderungen:
Die TLS-Verschlüsselung ist standardmäßig aktiviert.
Wenn encrypt = false ist, der Server aber Verschlüsselung erfordert, wird das Zertifikat basierend auf der
trustServerCertificate-Verbindungseinstellung validiert.aadSecurePrincipalIdundaadSecurePrincipalSecretsind veraltet.Die
getAADSecretPrincipalId-API wurde entfernt.CNAME-Auflösung hinzugefügt, wenn Realm angegeben ist.
MongoDB
Beachten Sie folgende Änderungen:
Unterstützung für Micro-Batch-Modus mit strukturiertem Spark-Streaming.
Unterstützung für BSON-Datentypen.
Unterstützung für das Lesen mehrerer Sammlungen im Micro-Batch- oder kontinuierlichen Streaming-Modus hinzugefügt.
Wenn der Name einer in Ihrer
collection-Konfigurationsoption verwendeten Sammlung ein Komma enthält, behandelt der Spark-Connector diese als zwei verschiedene Sammlungen. Um dies zu vermeiden, müssen Sie dem Komma einen Backslash (\) voranstellen.Wenn der Name einer in Ihrer
collection-Konfigurationsoption verwendeten Sammlung „*“ ist, interpretiert der Spark-Connector dies als Anweisung zum Scannen aller Sammlungen. Um dies zu vermeiden, müssen Sie dem Sternchen einen Backslash (\) voranstellen.Wenn der Name einer in Ihrer
collection-Konfigurationsoption verwendeten Sammlung einen Backslash (\) enthält, behandelt der Spark-Connector diesen als Escape-Zeichen. Dies kann die Interpretation des Werts ändern. Um dies zu vermeiden, müssen Sie dem Backslash einen weiteren Backslash voranstellen.
Weitere Informationen finden Sie in den Versionshinweisen zum MongoDB-Connector für Spark
Snowflake
Beachten Sie folgende Änderungen:
Ein neuer
trim_space-Parameter wurde eingeführt, mit dem Sie Werte vonStringType-Spalten beim Speichern in einer Snowflake-Tabelle automatisch kürzen können. Standard:false.Der
abort_detached_query-Parameter wurde standardmäßig auf Sitzungsebene deaktiviert.Die Anforderung des
SFUSER-Parameters bei Verwendung von OAUTH wurde entfernt.Das Feature „Erweiterter Abfrage-Pushdown“ wurde entfernt. Es sind Alternativen zu diesem Feature verfügbar. Anstatt Daten aus Snowflake-Tabellen zu laden, können Benutzer beispielsweise Daten direkt aus Snowflake-SQL-Abfragen laden.
Weitere Informationen finden Sie in den Versionshinweisen zum Snowflake-Connector für Spark
Anhang A: Nennenswerte Aktualisierungen von Abhängigkeiten
Im Folgenden sind Abhängigkeits-Upgrades aufgeführt:
| -Abhängigkeit | Version in 5.0 AWS Glue | Version in AWS Glue 4.0 | Version in AWS Glue 3.0 | Version in AWS Glue 2.0 | Version in AWS Glue 1.0 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Scala | 2.12,18 | 2.12 | 2.12 | 2.11 | 2.11 |
| Jackson | 2.15,2 | 2.12 | 2.12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4 | 2.3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2,69,0 | 2,54,0 | 2,46,0 | 2.38.0 | 2.30.0 |
| JSON4s | 3.7.0-M11 | 3.7.0-M11 | 3.6.6 | 3.5.x | 3.5.x |
| Arrow | 12.0.1 | 7.0.0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS Glue Datenkatalog-Client | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/A |
| AWS SDK for Java | 2.29.52 | 1.12 | 1.12 | ||
| Python | 3,11 | 3,10 | 3.7 | 2.7 und 3.6 | 2.7 und 3.6 |
| Boto | 1,34,131 | 1,26 | 1,18 | 1.12 | N/A |
| EMR-DynamoDB-Connector | 5.6.0 | 4,16.0 |
Anhang B: Aktualisierungen von JDBC-Treibern
Die folgenden JDBC-Treiber-Upgrades sind:
| Treiber | JDBC-Treiberversion in 5.0 AWS Glue | JDBC-Treiberversion in 4.0 AWS Glue | JDBC-Treiberversion in 3.0 AWS Glue | JDBC-Treiberversion in früheren Versionen AWS Glue |
|---|---|---|---|---|
| MySQL | 8.0.33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10.2,0 | 9.4,0 | 7.0.0 | 6.1.0 |
| Oracle-Datenbanken | 23.3.0.23,09 | 21,7 | 21,1 | 11.2 |
| PostgreSQL | 42,7,3 | 42,3,6 | 42,2,18 | 42,10 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP HANA | 2,20,17 | 2.17,12 | ||
| Teradata | 20,00,00,33 | 20.00.00.06 |
Anhang C: Konnektor-Upgrades
Im Folgenden sind Konnektor-Upgrades aufgeführt:
| Treiber | Connector-Version in 5.0 AWS Glue | Connector-Version in AWS Glue 4.0 | Connector-Version in AWS Glue 3.0 |
|---|---|---|---|
| EMR-DynamoDB-Connector | 5.6.0 | 4.16.0 | |
| Amazon Redshift | 6.4.0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3.0 | 10.0.4 | 3.0.0 |
| Snowflake | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0,32,2 | 0,32,2 | |
| AzureCosmos | 4,33,0 | 4,22,0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 3.3.5 | 3.3.5 |
Anhang D: Verbesserungen des Open-Table-Formats
Im Folgenden finden Sie die Verbesserungen des Open-Table-Formats:
| OTF | Connector-Version in 5.0 AWS Glue | Connector-Version in AWS Glue 4.0 | Connector-Version in AWS Glue 3.0 |
|---|---|---|---|
| Hudi | 0.15.0 | 0.12.1 | 0.10.1 |
| Delta Lake | 3.3.0 | 2.1.0 | 1.0.0 |
| Iceberg | 1.7.1 | 1.0.0 | 0.13.1 |
