Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Planen inkrementeller Crawls zum Hinzufügen neuer Partitionen
Sie können die AWS-Glue-Crawler Ausführung inkrementeller Crawls so konfigurieren, dass dem Tabellenschema nur neue Partitionen hinzugefügt werden. Wenn der Crawler zum ersten Mal ausgeführt wird, führt er einen vollständigen Crawl durch, um die gesamte Datenquelle zu verarbeiten und das vollständige Schema sowie alle vorhandenen Partitionen in AWS Glue Data Catalog aufzuzeichnen.
Nach dem ersten vollständigen Crawl werden nur noch inkrementelle Crawls durchgeführt, bei denen der Crawler nur die neuen Partitionen identifiziert und hinzufügt, die seit dem letzten Crawl hinzugefügt wurden. Dieser Ansatz führt zu niedrigeren Crawl-Zeiten, da der Crawler nicht mehr bei jeder Ausführung die gesamte Datenquelle verarbeiten muss, sondern sich nur noch auf die neuen Partitionen konzentriert.
Anmerkung
Änderungen oder Löschungen vorhandener Partitionen werden von inkrementellen Crawls nicht erkannt. Diese Konfiguration eignet sich am besten für Datenquellen mit einem stabilen Schema. Wenn eine einmalige größere Schemaänderung auftritt, empfiehlt es sich, den Crawler vorübergehend so einzustellen, dass er einen vollständigen Crawl durchführt, um das neue Schema genau zu erfassen, und dann wieder in den inkrementellen Crawling-Modus zurückzukehren.
Das folgende Diagramm zeigt, dass der Crawler bei aktivierter Einstellung für inkrementelles Crawling nur den neu hinzugefügten Ordner „month=March“ erkennt und dem Katalog hinzufügt.
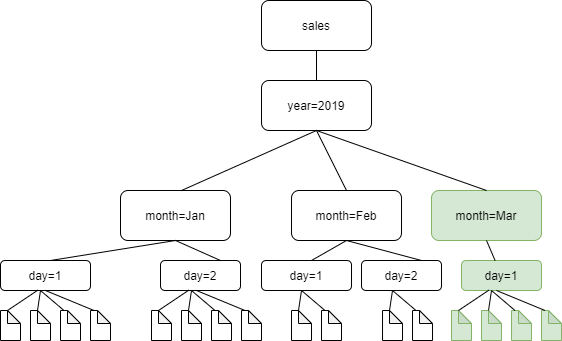
Gehen Sie wie folgt vor, um Ihren Crawler so zu aktualisieren, dass er inkrementelle Crawls durchführt:
Hinweise und Einschränkungen
Wenn diese Option aktiviert ist, können Sie die Amazon-S3-Zieldatenspeicher beim Bearbeiten des Crawlers nicht ändern. Diese Option wirkt sich auf bestimmte Crawler-Konfigurationseinstellungen aus. Wenn diese Option aktiviert ist, erzwingt sie das Aktualisierungs- und Löschverhalten des Crawlers für LOG. Dies bedeutet, dass:
-
Wenn Objekte entdeckt werden, bei denen Schemas nicht kompatibel sind, fügt der Crawler die Objekte nicht dem Datenkatalog hinzu und fügt dieses Detail als Protokoll in Logs hinzu. CloudWatch
-
Gelöschte Objekte werden im Datenkatalog nicht aktualisiert.
