Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Glue Automatische Streaming-Skalierung
AWS Glue Streaming-ETL-Jobs verbrauchen kontinuierlich Daten aus Streaming-Quellen, bereinigen und transformieren die Daten während der Übertragung und stellen sie für Analysen zur Verfügung. Durch die Überwachung jeder Phase der Auftragsausführung kann AWS Glue Autoscaling Worker ausschalten, wenn sie inaktiv sind, oder Worker hinzufügen, wenn zusätzliche Parallelverarbeitung möglich ist.
Die folgenden Abschnitte enthalten Informationen zur automatischen AWS Glue Streaming-Skalierung
Auto Scaling aktivieren in AWS Glue Studio
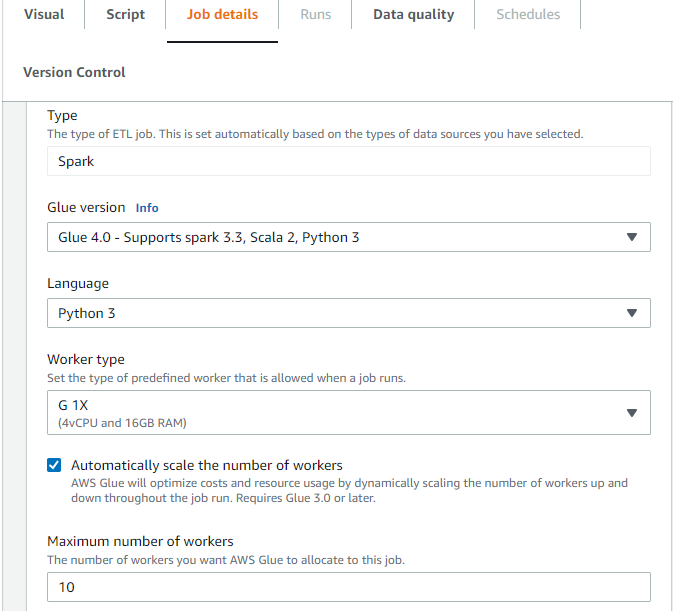
Wählen Sie in AWS Glue Studio auf der Registerkarte Jobdetails den Typ als Spark oder Spark Streaming und die Glue-Version als Glue 3.0 oder ausGlue 4.0. Dann erscheint unter Worker-Typ ein Kontrollfeld.
-
Wählen Sie die Option Automatisches Skalieren der Worker-Anzahl aus.
-
Legen Sie die Maximale Worker-Anzahl fest, um die maximale Anzahl von Workern zu definieren, die für die Auftragsausführung ausgegeben werden können.
Aktivieren von Auto Scaling mit dem AWS CLI oder SDK
Um Auto Scaling über die AWS CLI für Ihren Joblauf zu aktivieren, führen Sie start-job-run ihn mit der folgenden Konfiguration aus:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
Sobald die Ausführung des ETL-Jobs abgeschlossen ist, können Sie auch anrufen, get-job-run um die tatsächliche Ressourcennutzung des ausgeführten Jobs zu überprüfen DPU-seconds. Hinweis: Das neue Feld dpuSeconds wird nur für Ihre Batch-Jobs auf AWS Glue Version 3.0 oder höher angezeigt, die mit Auto Scaling aktiviert sind. Dieses Feld wird für Streaming-Aufträge nicht unterstützt.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
Sie können Auftragsausführungen mit Auto Scaling auch über das AWS Glue -SDK konfigurieren. Die Konfiguration ist dieselbe.
Funktionsweise
Skalieren über Micro-Batches hinweg
Anhand des folgenden Beispiels wird beschrieben, wie Auto Scaling funktioniert.
-
Sie haben einen AWS Glue Job, der mit 50 DPUs beginnt.
-
Auto Scaling ist aktiviert.
In diesem Beispiel wird AWS Glue anhand der Metrik ProcessingTimeInMs „Batch“ für einige Mikrobatches ermittelt, ob Ihre Aufträge innerhalb der von Ihnen festgelegten Fenstergröße abgeschlossen werden. Wenn Ihre Aufträge schneller abgeschlossen werden, und je nachdem, wie schnell sie abgeschlossen werden, kann es sein, dass AWS Glue herunterskaliert wird. Diese Metrik, dargestellt mit“ Zahl AllExecutors „, kann überwacht werden, Amazon CloudWatch um zu sehen, wie Autoscaling funktioniert.
Die Anzahl der Executors skaliert exponentiell nach oben oder unten, nachdem jeder Micro-Batch abgeschlossen ist. Wie Sie dem Amazon CloudWatch Monitoring-Protokoll entnehmen können, AWS Glue wird die Anzahl der benötigten Executoren (orange Linie) überprüft und die Executoren (blaue Linie) automatisch entsprechend skaliert.

Sobald die Anzahl der Executoren AWS Glue herunterskaliert wird und festgestellt wird, dass das Datenvolumen zunimmt, wodurch sich die Verarbeitungszeit für Mikro-Batches erhöht, AWS Glue wird die Skalierung auf bis zu 50 DPUs durchgeführt, was der angegebenen Obergrenze entspricht.
Skalieren innerhalb von Micro-Batches
Im obigen Beispiel überwacht das System einige abgeschlossene Micro-Batches, um zu entscheiden, ob hoch- oder herunterzuskalieren ist. Längere Zeitfenster erfordern eine Autoskalierung, um innerhalb des Mikrobatches schneller reagieren zu können, anstatt auf mehrere Mikrobatches zu warten. Für diese Fälle können Sie eine zusätzliche Konfiguration --auto-scale-within-microbatch zu true verwenden. Sie können dies wie unten gezeigt zu den AWS Glue Auftragseigenschaften hinzufügen. AWS Glue Studio

