Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aktivieren des Verdichtungsoptimierers
Sie können die AWS Glue Konsole oder AWS API verwenden AWS CLI, um die Komprimierung für Ihre Apache Iceberg-Tabellen im AWS Glue Datenkatalog zu aktivieren. Für neue Tabellen können Sie Apache Iceberg als Tabellenformat auswählen und die Verdichtung beim Erstellen der Tabellen aktivieren. Für neue Tabellen ist die Verdichtung standardmäßig deaktiviert.
- Console
-
Aktivieren der Verdichtung
-
Öffnen Sie die AWS Glue Konsole unter https://console.aws.amazon.com/glue/und melden Sie sich als Data Lake-Administrator, als Tabellenersteller oder als Benutzer an, dem die lakeformation:GetDataAccess Berechtigungen glue:UpdateTable und für die Tabelle erteilt wurden.
-
Wählen Sie im Navigationsbereich unter Datenkatalog die Option Tabellen aus.
Wählen Sie auf der Seite Tabellen eine Tabelle im offenen Tabellenformat aus, für die Sie die Verdichtung aktivieren möchten, und wählen Sie dann im Menü Aktionen die Option Optimierung und dann Aktivieren aus.
Sie können die Verdichtung auch aktivieren, indem Sie die Registerkarte Tabellenoptimierung auf der Seite mit den Tabellendetails auswählen. Wählen Sie im unteren Bereich der Seite die Registerkarte Tabellenoptimierung und dann Verdichtung aktivieren aus.
Die Option Optimierung aktivieren ist auch verfügbar, wenn Sie eine neue Iceberg-Tabelle im Datenkatalog erstellen.
-
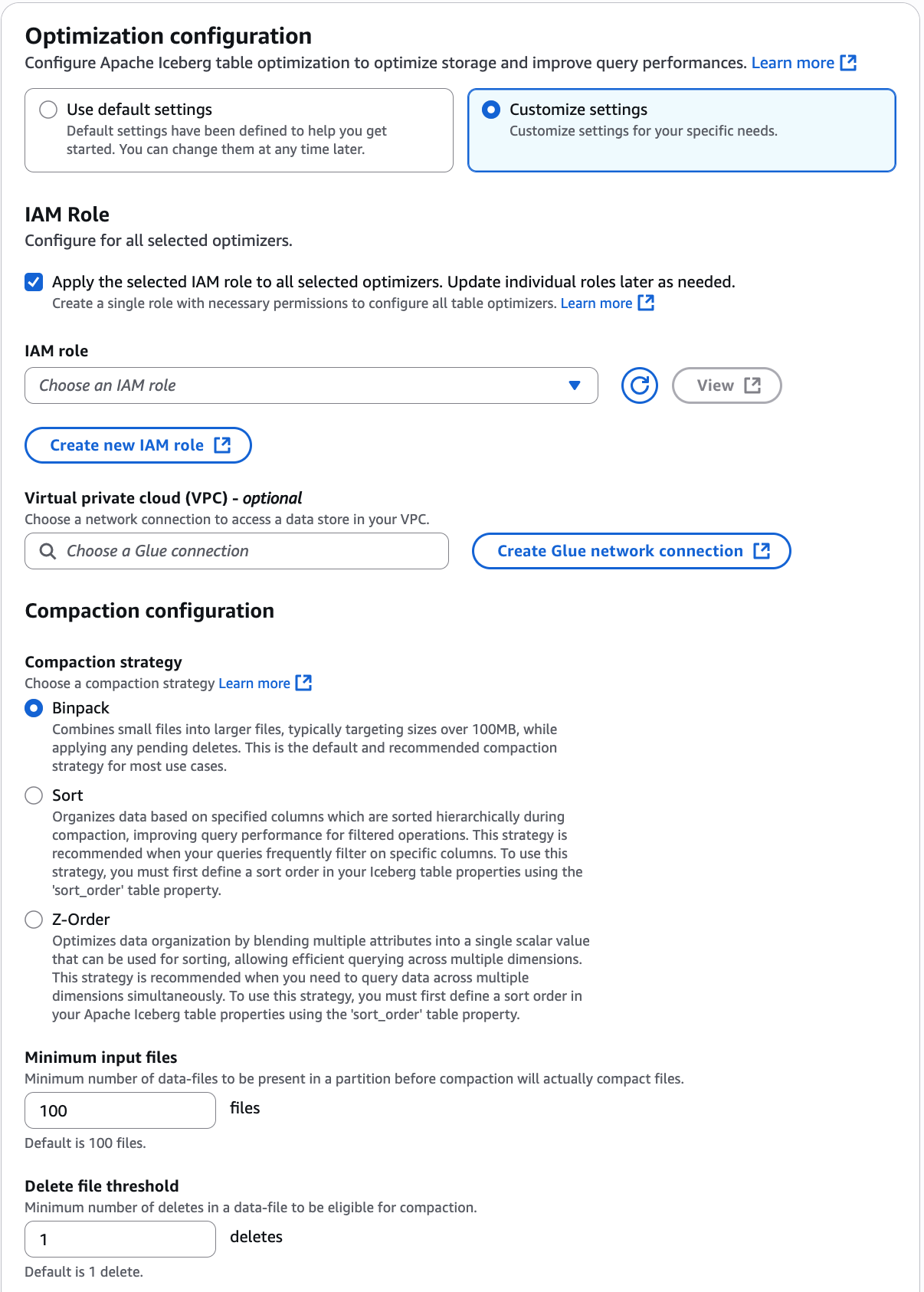
Wählen Sie auf der Seite Optimierung aktivieren unter Optimierungsoptionen die Option Verdichtung aus.
-
Wählen Sie als Nächstes eine IAM-Rolle aus der Drop-down-Liste mit den Berechtigungen im Abschnitt Voraussetzungen für die Tabellenoptimierung aus.
Sie können auch die Option Neue IAM-Rolle erstellen auswählen, um eine benutzerdefinierte Rolle mit den erforderlichen Berechtigungen zum Ausführen der Verdichtung zu erstellen.
Gehen Sie wie folgt vor, um eine vorhandene IAM-Rolle zu aktualisieren:
-
Um die Berechtigungsrichtlinie für die IAM-Rolle zu aktualisieren, wechseln Sie in der IAM-Konsole zu der IAM-Rolle, die zum Ausführen der Verdichtung verwendet wird.
-
Wählen Sie im Abschnitt Berechtigungen hinzufügen die Option „Richtlinie erstellen“ aus. Erstellen Sie im neu geöffneten Browserfenster eine neue Richtlinie, die Sie mit Ihrer Rolle verwenden möchten.
-
Wählen Sie auf der Seite „Richtlinie erstellen“ die Registerkarte JSON aus. Kopieren Sie den JSON-Code aus den Voraussetzungen in das Feld im Richtlinieneditor.
-
Wenn Sie Sicherheitsrichtlinien-Konfigurationen haben, bei denen der Iceberg-Tabellenoptimierer von einer bestimmten Virtual Private Cloud (VPC) aus auf Amazon S3 S3-Buckets zugreifen muss, stellen Sie eine AWS Glue Netzwerkverbindung her oder verwenden Sie eine bestehende.
Wenn Sie noch keine AWS Glue VPC-Verbindung eingerichtet haben, erstellen Sie eine neue, indem Sie mit der AWS Glue Konsole oder dem /SDK die Schritte im Abschnitt Verbindungen für Konnektoren erstellen ausführen. AWS CLI
-
Wählen Sie eine Verdichtungsstrategie. Die verfügbaren Optionen sind:
Binpack: Binpack ist die Standard-Verdichtungsstrategie in Apache Iceberg. Sie kombiniert kleinere Datendateien zu größeren, um eine optimale Leistung zu erzielen.
-
Sortieren: Bei der Sortierung in Apache Iceberg handelt es sich um eine Datenorganisationstechnik, bei der Informationen innerhalb von Dateien auf der Grundlage bestimmter Spalten gruppiert werden. Dadurch wird die Abfrageleistung erheblich verbessert, da die Anzahl der zu verarbeitenden Dateien reduziert wird. Sie legen die Sortierreihenfolge in den Metadaten von Iceberg mithilfe des Felds „Sortierreihenfolge“ fest. Wenn mehrere Spalten angegeben sind, werden die Daten in der Reihenfolge sortiert, in der die Spalten in der Sortierreihenfolge erscheinen, sodass Datensätze mit ähnlichen Werten innerhalb der Dateien zusammen gespeichert werden. Die Sortier- und Verdichtungsstrategie optimiert den Prozess weiter, indem sie Daten über alle Dateien innerhalb einer Partition hinweg sortiert.
Z-Reihenfolge: Die Z-Reihenfolge ist eine Methode zum Organisieren von Daten, wenn Sie diese nach mehreren Spalten mit gleicher Wichtigkeit sortieren müssen. Im Gegensatz zur herkömmlichen Sortierung, bei der eine Spalte gegenüber anderen priorisiert wird, gewichtet die Z-Sortierung jede Spalte gleichmäßig, sodass Ihre Suchmaschine bei der Datensuche weniger Dateien lesen muss.
Bei dieser Technik werden die Binärziffern der Werte aus verschiedenen Spalten miteinander verwoben. Wenn Sie beispielsweise die Zahlen 3 und 4 aus zwei Spalten haben, werden diese bei der Z-Reihenfolge zunächst in Binärzahlen umgewandelt (3 wird zu 011 und 4 zu 100) und dann miteinander verschachtelt, um einen neuen Wert zu bilden: 011010. Durch diese Verschachtelung entsteht ein Muster, bei dem verwandte Daten physisch nahe beieinander bleiben.
Die Z-Reihenfolge ist besonders effektiv für mehrdimensionale Abfragen. Beispielsweise kann die Z-Reihenfolge bei einer Kundentabelle, die nach Einkommen, Bundesstaat und Postleitzahl sortiert ist, bei Abfragen über mehrere Dimensionen hinweg eine überlegene Leistung im Vergleich zur hierarchischen Sortierung bieten. Diese Organisation ermöglicht Abfragen, die auf bestimmte Kombinationen aus Einkommen und geografischem Standort abzielen, um relevante Daten schnell zu finden und gleichzeitig unnötige Dateiscans zu minimieren.
-
Mindestanzahl an Eingabedateien: Die Anzahl der Datendateien, die in einer Partition vorhanden sein müssen, bevor die Verdichtung ausgelöst wird.
-
Schwellenwert für das Löschen von Dateien: Mindestanzahl an Löschvorgängen, die in einer Datendatei erforderlich sind, bevor sie für die Verdichtung infrage kommt.
-
Wählen Sie Optimierung aktivieren aus.
- AWS CLI
-
Im folgenden Beispiel wird gezeigt, wie Sie die Verdichtung aktivieren. Ersetzen Sie die Konto-ID durch eine gültige AWS Konto-ID. Ersetzen Sie den Datenbanknamen und den Tabellennamen durch die tatsächlichen Tabellen- und Datenbanknamen in Iceberg. Ersetzen Sie den roleArn durch den AWS -Ressourcennamen (ARN) der IAM-Rolle und den Namen der IAM-Rolle, die über die erforderlichen Berechtigungen zum Ausführen der Verdichtung verfügt. Sie können die Verdichtungsstrategie sort durch andere unterstützte Strategien wie z-order oder binpack ersetzen.
Reihenfolge“ je nach Ihren Anforderungen.
aws glue create-table-optimizer \
--catalog-id 123456789012 \
--database-name iceberg_db \
--table-name iceberg_table \
--table-optimizer-configuration '{
"roleArn": "arn:aws:iam::123456789012:role/optimizer_role",
"enabled": true,
"vpcConfiguration": {"glueConnectionName": "glue_connection_name"},
"compactionConfiguration": {
"icebergConfiguration": {"strategy": "sort"}
}
}'\
--type compaction
- AWS API
-
Rufen Sie die Operation CreateTableOptimizer auf, um die Verdichtung für eine Tabelle zu aktivieren.
Nachdem Sie die Verdichtung aktiviert haben, werden auf der Registerkarte Tabellenoptimierung die folgenden Verdichtungsdetails angezeigt, sobald der Verdichtungsprozess abgeschlossen wurde:
- Startzeit
-
Die Zeit, zu der der Verdichtungsprozess innerhalb von Data Catalog gestartet wurde. Der Wert ist ein Zeitstempel in UTC-Zeit.
- Endzeit
-
Die Zeit, zu der der Verdichtungsprozess innerhalb von Data Catalog beendet wurde. Der Wert ist ein Zeitstempel in UTC-Zeit.
- Status
-
Der Status der Verdichtungsausführung. Die Werte sind „Erfolgreich“ oder „Fehlgeschlagen“.
- Verdichtete Dateien
Anzahl der verdichteten Dateien.
- Verdichtete Bytes
-
Anzahl der verdichteten Bytes.