Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Glue Jobs lokal mit einem Docker-Image entwickeln und testen
Für eine produktionsreife Datenplattform sind der Entwicklungsprozess und die CI/CD Pipeline für AWS Glue Jobs ein zentrales Thema. Sie können AWS Glue Jobs in einem Docker-Container flexibel entwickeln und testen. AWS Glue hostet Docker-Images auf Docker Hub, um Ihre Entwicklungsumgebung mit zusätzlichen Dienstprogrammen einzurichten. Sie können Ihre bevorzugte IDE, Ihr bevorzugtes Notebook oder REPL mithilfe der ETL-Bibliothek verwenden AWS Glue . In diesem Thema wird beschrieben, wie Sie Jobs der AWS Glue Version 5.0 in einem Docker-Container mithilfe eines Docker-Images entwickeln und testen.
Verfügbare Docker-Images
Die folgenden Docker-Images sind für AWS Glue Amazon ECR
-
Für AWS Glue Version 5.0:
public.ecr.aws/glue/aws-glue-libs:5 -
Für AWS Glue Version 4.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 -
Für AWS Glue Version 3.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 -
Für AWS Glue Version 2.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
Anmerkung
AWS Glue Docker-Images sind sowohl mit x86_64 als auch mit arm64 kompatibel.
In diesem Beispiel verwenden wir public.ecr.aws/glue/aws-glue-libs:5 und führen den Container auf einem lokalen Rechner (Mac, Windows oder Linux) aus. Dieses Container-Image wurde für Spark-Jobs der Version 5.0 getestet AWS Glue . Dieses Image enthält Folgendes:
-
Amazon Linux 2023
-
AWS Glue ETL-Bibliothek
-
Apache Spark 3.5.4
-
Bibliotheken im offenen Tabellenformat; Apache Iceberg 1.7.1, Apache Hudi 0.15.0 und Delta Lake 3.3.0
-
AWS Glue Datenkatalog-Client
-
Amazon Redshift Konnektor für Apache Spark
-
Amazon DynamoDB Anschluss für Apache Hadoop
Laden Sie zum Einrichten Ihres Containers das Image aus der ECR Public Gallery herunter und führen Sie dann den Container aus. In diesem Thema wird gezeigt, wie Sie Ihren Container je nach Ihren Anforderungen mit den folgenden Methoden ausführen:
-
spark-submit -
REPL-Shell
(pyspark) -
pytest -
Visual Studio Code
Voraussetzungen
Stellen Sie vor dem Starten sicher, dass Docker installiert ist und der Docker-Daemon ausgeführt wird. Installationsanweisungen finden Sie in der Docker-Dokumentation für Mac
Weitere Informationen zu Einschränkungen bei der lokalen Entwicklung von AWS Glue Code finden Sie unter Einschränkungen für die lokale Entwicklung.
Konfiguration AWS
Um AWS API-Aufrufe aus dem Container zu aktivieren, richten Sie die AWS Anmeldeinformationen wie folgt ein. In den folgenden Abschnitten werden wir dieses AWS benannte Profil verwenden.
-
Öffnen Sie es
cmdunter Windows oder einem Terminal Mac/Linux und führen Sie den folgenden Befehl in einem Terminal aus:PROFILE_NAME="<your_profile_name>"
In den folgenden Abschnitten verwenden wir dieses AWS benannte Profil.
Wenn Sie Docker in Windows ausführen, wählen Sie das Docker-Symbol aus (mit Rechtsklick) und wählen Sie dann Zu Linux-Containern wechseln aus, bevor Sie das Image abrufen.
Mit dem folgenden Befehl können Sie das Image aus ECR Public abrufen:
docker pull public.ecr.aws/glue/aws-glue-libs:5
Ausführen des Containers
Sie können jetzt mit diesem Image einen Container ausführen. Sie können eine der folgenden Optionen entsprechend Ihren Anforderungen auswählen.
spark-submit
Sie können ein AWS Glue Jobskript ausführen, indem Sie den spark-submit Befehl auf dem Container ausführen.
-
Schreiben Sie Ihr Skript und speichern Sie es als
sample.pywie im Beispiel unten. Speichern Sie es mit den folgenden Befehlen unter dem/local_path_to_workspace/src/-Verzeichnis:$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME} -
Diese Variablen werden im folgenden Docker-Ausführungsbefehl verwendet. Der im folgenden Befehl „spark-submit“ verwendete Beispielcode (sample.py) ist im Anhang am Ende dieses Themas enthalten.
Führen Sie den folgenden Befehl aus, um den
spark-submit-Befehl für den Container zum Übermitteln einer neuen Spark-Anwendung auszuführen:$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_spark_submit \ public.ecr.aws/glue/aws-glue-libs:5 \ spark-submit /home/hadoop/workspace/src/$SCRIPT_FILE_NAME -
(Optional) Passen Sie die Konfiguration von
spark-submitan Ihre Umgebung an. Sie können beispielsweise Ihre Abhängigkeiten mit der--jars-Konfiguration übergeben. Weitere Informationen finden Sie unter Dynamically Loading Spark Propertiesin der Spark-Dokumentation.
REPL-Shell (Pyspark)
Sie können die REPL (read-eval-print loops)-Shell für die interaktive Entwicklung ausführen. Führen Sie den folgenden Befehl aus, um den PySpark Befehl auf dem Container auszuführen und die REPL-Shell zu starten:
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Dann erhalten Sie die folgende Ausgabe:
Python 3.11.6 (main, Jan 9 2025, 00:00:00) [GCC 11.4.1 20230605 (Red Hat 11.4.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.5.4-amzn-0 /_/ Using Python version 3.11.6 (main, Jan 9 2025 00:00:00) Spark context Web UI available at None Spark context available as 'sc' (master = local[*], app id = local-1740643079929). SparkSession available as 'spark'. >>>
Mit dieser REPL-Shell können Sie interaktiv programmieren und testen.
Pytest
Für Komponententests können Sie Jobskripte pytest für AWS Glue Spark verwenden. Führen Sie zur Vorbereitung die folgenden Befehle aus.
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
Führen Sie folgenden Befehl zur Ausführung von pytest mit docker run aus:
$ docker run -i --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pytest \ public.ecr.aws/glue/aws-glue-libs:5 \ -c "python3 -m pytest --disable-warnings"
Sobald pytest die Ausführung der Modultests abgeschlossen hat, sieht Ihre Ausgabe in etwa so aus:
============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-8.3.4, pluggy-1.5.0 rootdir: /home/hadoop/workspace plugins: integration-mark-0.2.0 collected 1 item tests/test_sample.py . [100%] ======================== 1 passed, 1 warning in 34.28s =========================
Einrichten des Containers für die Verwendung von Visual Studio Code
Gehen Sie wie folgt vor, um den Container mit Visual Studio Code einzurichten.
Installieren Sie Visual Studio Code.
Installieren Sie Python
. Installieren Sie Visual Studio Code Remote - Containers
Öffnen Sie den Workspace-Ordner in Visual Studio Code.
Drücken Sie
Ctrl+Shift+P(Windows/Linux) oderCmd+Shift+P(Mac).Geben Sie
Preferences: Open Workspace Settings (JSON)ein.Drücken Sie die Eingabetaste.
Fügen Sie das folgende JSON ein und speichern Sie die Einstellung.
{ "python.defaultInterpreterPath": "/usr/bin/python3.11", "python.analysis.extraPaths": [ "/usr/lib/spark/python/lib/py4j-0.10.9.7-src.zip:/usr/lib/spark/python/:/usr/lib/spark/python/lib/", ] }
So richten Sie den Container ein:
-
Führen Sie den Docker-Container aus.
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark -
Starten Sie Visual Studio Code.
-
Wählen Sie im linken Menü Remote Explorer und dann
amazon/aws-glue-libs:glue_libs_4.0.0_image_01aus. -
Right-click und wählen Sie „Im aktuellen Fenster anhängen“.
-
Wenn das folgende Dialogfeld angezeigt wird, wählen Sie Verstanden.
-
Öffnen Sie
/home/handoop/workspace/.
-
Erstellen Sie ein AWS Glue PySpark Skript und wählen Sie Ausführen.
Sie werden die erfolgreiche Ausführung des Skripts sehen.
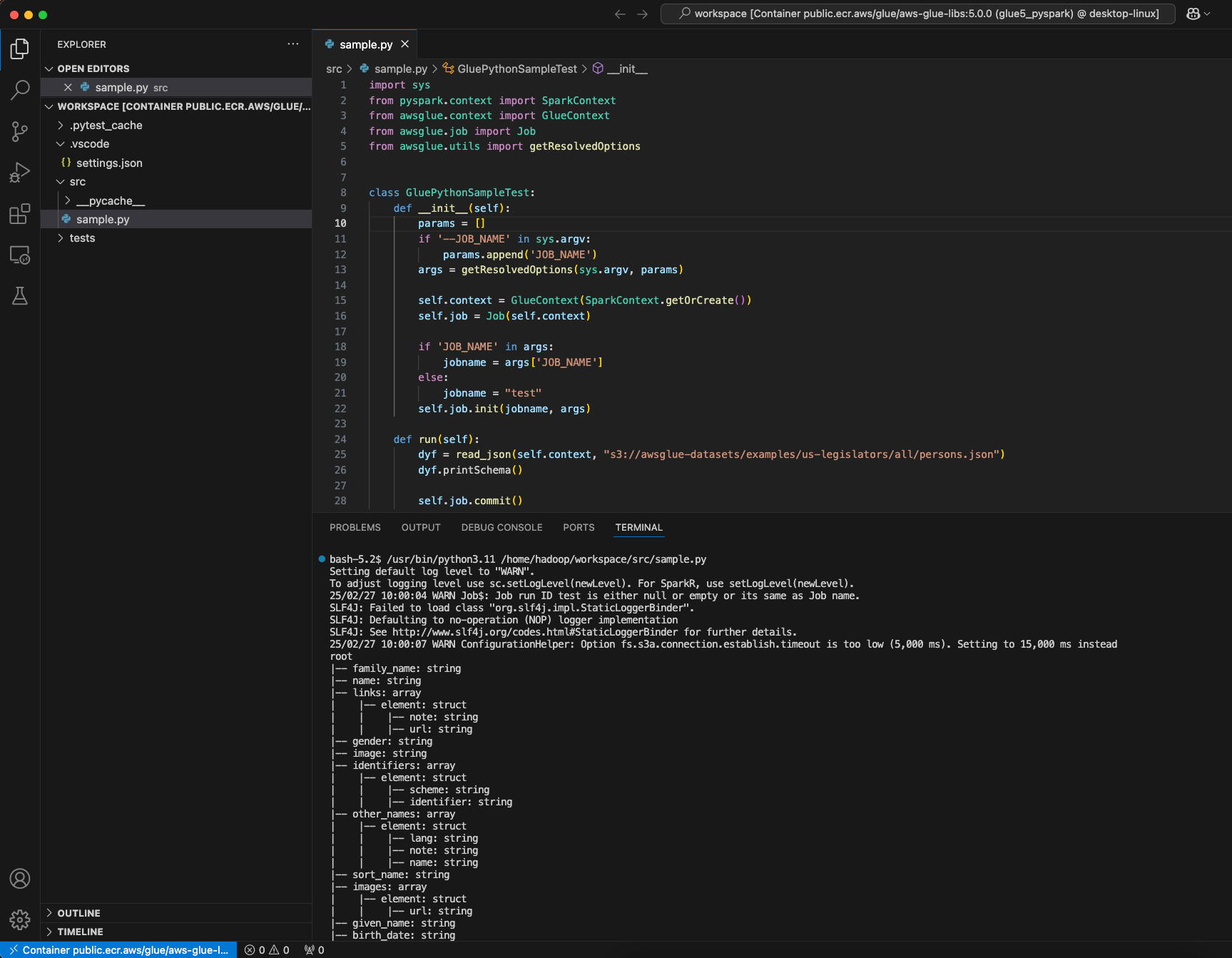
Änderungen zwischen dem Docker-Image AWS Glue 4.0 und AWS Glue 5.0
Die wichtigsten Änderungen zwischen dem Docker-Image AWS Glue 4.0 und AWS Glue 5.0:
-
In AWS Glue 5.0 gibt es ein einzelnes Container-Image für Batch- und Streaming-Jobs. Dies unterscheidet sich von Glue 4.0, wo es ein Image für Batch und ein weiteres für Streaming gab.
-
In AWS Glue 5.0 lautet der Standardbenutzername des Containers
hadoop. In AWS Glue 4.0 lautete der Standardbenutzernameglue_user. -
In AWS Glue 5.0 wurden mehrere zusätzliche Bibliotheken, darunter Livy JupyterLab und Livy, aus dem Bild entfernt. Sie können diese manuell installieren.
-
In AWS Glue 5.0 sind alle Iceberg-, Hudi- und Delta-Bibliotheken standardmäßig vorinstalliert, und die Umgebungsvariable
DATALAKE_FORMATSwird nicht mehr benötigt. Vor AWS Glue 4.0 wurde die UmgebungsvariableDATALAKE_FORMATSUmgebungsvariable verwendet, um anzugeben, welche spezifischen Tabellenformate geladen werden sollten.
Die obige Liste ist spezifisch für das Docker-Image. Weitere Informationen zu AWS Glue 5.0-Updates finden Sie unter Einführung in AWS Glue 5.0 für Apache Spark
Überlegungen
Beachten Sie, dass die folgenden Funktionen nicht unterstützt werden, wenn Sie das AWS Glue Container-Image zur lokalen Entwicklung von Jobskripten verwenden.
-
AWS Glue Parquet Writer (unter Verwendung des Parquet-Formats in AWS Glue)
-
Die benutzerdefinierte Eigenschaft JdbcDriverS3Path zum Laden des JDBC-Treibers aus dem Amazon S3 S3-Pfad
-
AWS Lake Formation Verkauf von Zugangsdaten auf der Grundlage von Genehmigungen
Anhang: Hinzufügen von JDBC-Treibern und Java-Bibliotheken
Um einen JDBC-Treiber hinzuzufügen, der derzeit nicht im Container verfügbar ist, können Sie in Ihrem Arbeitsbereich ein neues Verzeichnis mit den benötigten JAR-Dateien erstellen und das Verzeichnis im Docker-Ausführungsbefehl unter /opt/spark/jars/ einbinden. JAR-Dateien, die sich im Container unter /opt/spark/jars/ befinden, werden automatisch zu Spark Classpath hinzugefügt und können während der Auftragsausführung verwendet werden.
Verwenden Sie beispielsweise den folgenden Befehl docker run, um JDBC-Treiber-Jars zur REPL-Shell hinzuzufügen. PySpark
docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -v $WORKSPACE_LOCATION/jars/:/opt/spark/jars/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_jdbc \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Wie unter Überlegungen hervorgehoben, kann die customJdbcDriverS3Path Verbindungsoption nicht verwendet werden, um einen benutzerdefinierten JDBC-Treiber aus Amazon S3 in AWS Glue Container-Images zu importieren.
