Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anomalieerkennung in AWS Glue Data Quality
Entwickler verwalten Hunderte von Datenpipelines gleichzeitig. Mit jeder Pipeline können Daten aus verschiedenen Quellen extrahiert und in den Data Lake oder andere Datenrepositorys geladen werden. Entwickler legen Regeln für die Datenqualität fest, um sicherzustellen, dass qualitativ hochwertige Daten für die Entscheidungsfindung bereitgestellt werden. Diese Regeln bewerten die Daten auf der Grundlage fester Kriterien, die den aktuellen Geschäftsstatus widerspiegeln. Ändert sich jedoch das Geschäftsumfeld, verändern sich die Dateneigenschaften, wodurch diese festen Kriterien überholt sind und die Datenqualität beeinträchtigt wird.
Beispielsweise hat ein Dateningenieur in einem Einzelhandelsunternehmen eine Regel festgelegt, die bestätigt, dass der Tagesumsatz einen one-million-dollar Schwellenwert überschreiten muss. Nach einigen Monaten überstieg der Tagesumsatz zwei Millionen Dollar, wodurch der Schwellenwert nicht mehr gültig war. Der Dateningenieur konnte die Regeln nicht aktualisieren, um die aktuellen Schwellenwerte widerzuspiegeln, da keine Benachrichtigung erfolgte und die Regel aufwändig manuell analysiert und aktualisiert werden musste. Im Laufe des Monats stellten die Geschäftsanwender einen Umsatzrückgang von 25 % fest. Nach stundenlangen Untersuchungen stellten die Dateningenieure fest, dass eine ETL-Pipeline, die für das Extrahieren von Daten aus einigen Filialen zuständig war, ohne Fehlermeldung ausgefallen war. Die Regel mit veralteten Schwellenwerten funktionierte weiterhin einwandfrei, ohne dass dieses Problem erkannt wurde.
Alternativ hätten proaktive Warnmeldungen, die diese Anomalien erkennen können, es den Benutzern ermöglicht, dieses Problem zu erkennen. Darüber hinaus kann die Beobachtung saisonaler Schwankungen im Geschäftsverlauf erhebliche Probleme mit der Datenqualität aufdecken. Beispielsweise können die Einzelhandelsumsätze an Wochenenden und in der Weihnachtszeit am höchsten und an Wochentagen relativ niedrig sein. Eine Abweichung von diesem Muster kann auf Probleme mit der Datenqualität oder Veränderungen der Geschäftsumstände hinweisen. Mit Datenqualitätsregeln können saisonale Muster nicht erkannt werden, da hierfür fortgeschrittene Algorithmen erforderlich sind, die aus vergangenen Mustern lernen und saisonale Schwankungen erfassen können, um Abweichungen zu erkennen.
Schließlich empfinden Benutzer die Erstellung und Pflege von Regeln aufgrund der technischen Natur des Regelerstellungsprozesses und des damit verbundenen Zeitaufwands als schwierig. Aus diesem Grund ziehen sie es vor, zuerst Dateneinblicke zu untersuchen, bevor sie Regeln definieren. Kunden müssen in der Lage sein, Anomalien mühelos zu erkennen, sodass sie Datenqualitätsprobleme proaktiv erkennen und fundierte Geschäftsentscheidungen treffen können.
Funktionsweise
Anmerkung
Die Erkennung von Anomalien wird nur in AWS Glue ETL unterstützt. Dies wird bei der datenkatalogbasierten Datenqualität nicht unterstützt.
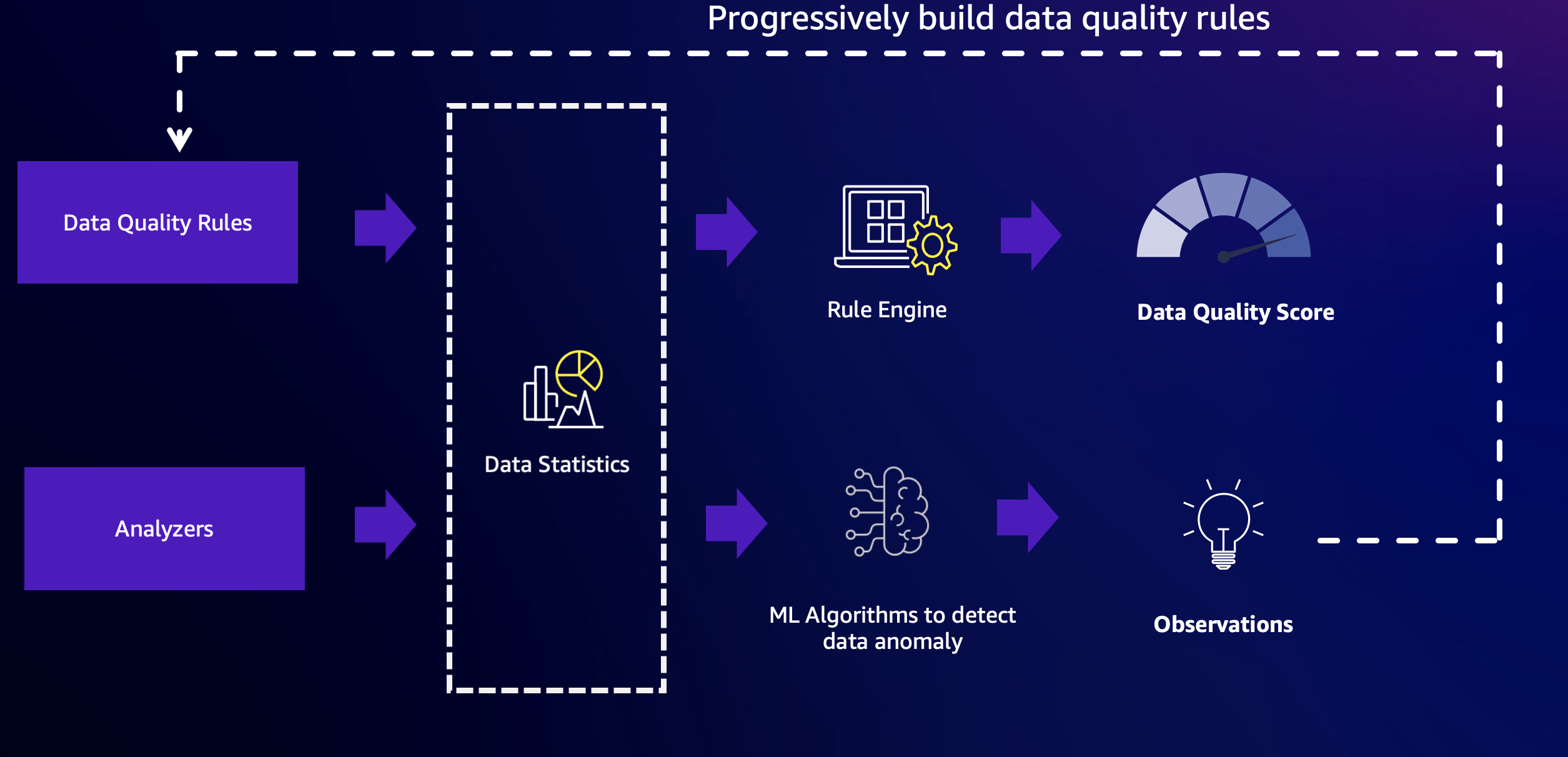
AWS Glue Data Quality kombiniert die Leistungsfähigkeit regelbasierter Datenqualitäts- und Anomalieerkennungsfunktionen, um qualitativ hochwertige Daten zu liefern. Zunächst müssen Sie Regeln und Analysatoren konfigurieren und anschließend die Anomalieerkennung aktivieren.
Regeln
Regeln: Regeln beschreiben die Erwartungen an Ihre Daten in einer offenen Sprache, der Data Quality Definition Language (DQDL). Es folgt ein Beispiel für eine Regel. Diese Regel ist erfolgreich, wenn die Spalte „passenger_count“ keine leeren oder NULL-Werte enthält:
Rules = [ IsComplete "passenger_count" ]
Analysatoren
Wenn Sie die kritischen Spalten kennen, aber nicht genügend Informationen über die Daten haben, um spezifische Regeln zu erstellen, können Sie diese Spalten mithilfe von Analysatoren überwachen. Analysatoren ermöglichen das Erfassen von Datenstatistiken, ohne explizite Regeln zu definieren. Es folgt ein Beispiel für die Konfiguration von Analysatoren:
Analyzers = [ AllStatistics "fare_amount", DistinctValuesCount "pulocationid", RowCount ]
In diesem Beispiel sind drei Analysatoren konfiguriert:
-
Der erste Analyzer, `AllStatistics „fare_amount"`, erfasst alle verfügbaren Statistiken für das Feld `fare_amount`.
-
Der zweite Analyzer, `DistinctValuesCount „pulocationid"`, erfasst die Anzahl der unterschiedlichen Werte in der Spalte `pulocationid`.
-
Der dritte Analyzer, `RowCount`, erfasst die Gesamtzahl der Datensätze im Datensatz.
Analysatoren bieten eine einfache Möglichkeit, relevante Datenstatistiken zu erfassen, ohne komplexe Regeln festlegen zu müssen. Durch die Überwachung dieser Statistiken erhalten Sie Einblicke in die Datenqualität und können potenzielle Probleme oder Anomalien identifizieren, die möglicherweise weitere Untersuchungen oder die Erstellung spezifischer Regeln erfordern.
Datenstatistik
Sowohl Analyzer als auch Rules in AWS Glue Data Quality erfassen Datenstatistiken, auch bekannt als Datenprofile. Diese Statistiken geben Aufschluss über die Eigenschaften und die Qualität Ihrer Daten. Die gesammelten Statistiken werden im Laufe der Zeit innerhalb des AWS Glue-Dienstes gespeichert, sodass Sie Änderungen in Ihren Datenprofilen verfolgen und analysieren können.
Sie können diese Statistiken einfach abrufen und zur weiteren Analyse oder Langzeitspeicherung in Amazon S3 schreiben, indem Sie die entsprechende APIs Option aufrufen. Diese Funktion ermöglicht es Ihnen, die Erstellung von Datenprofilen in Ihre Datenverarbeitungs-Workflows zu integrieren und die erfassten Statistiken für verschiedene Zwecke zu nutzen, z. B. für die Überwachung der Datenqualität und die Anomalieerkennung.
Durch die Speicherung der Datenprofile in Amazon S3 profitieren Sie von der Skalierbarkeit, der Ausfallsicherheit und der Kosteneffizienz des Objektspeicher-Services von Amazon. Darüber hinaus können Sie andere AWS Dienste oder Tools von Drittanbietern nutzen, um die Datenprofile zu analysieren und zu visualisieren, sodass Sie tiefere Einblicke in Ihre Datenqualität gewinnen und fundierte Entscheidungen über Datenmanagement und Datenverwaltung treffen können.
Hier ist ein Beispiel für Datenstatistiken, die im Laufe der Zeit gespeichert wurden.
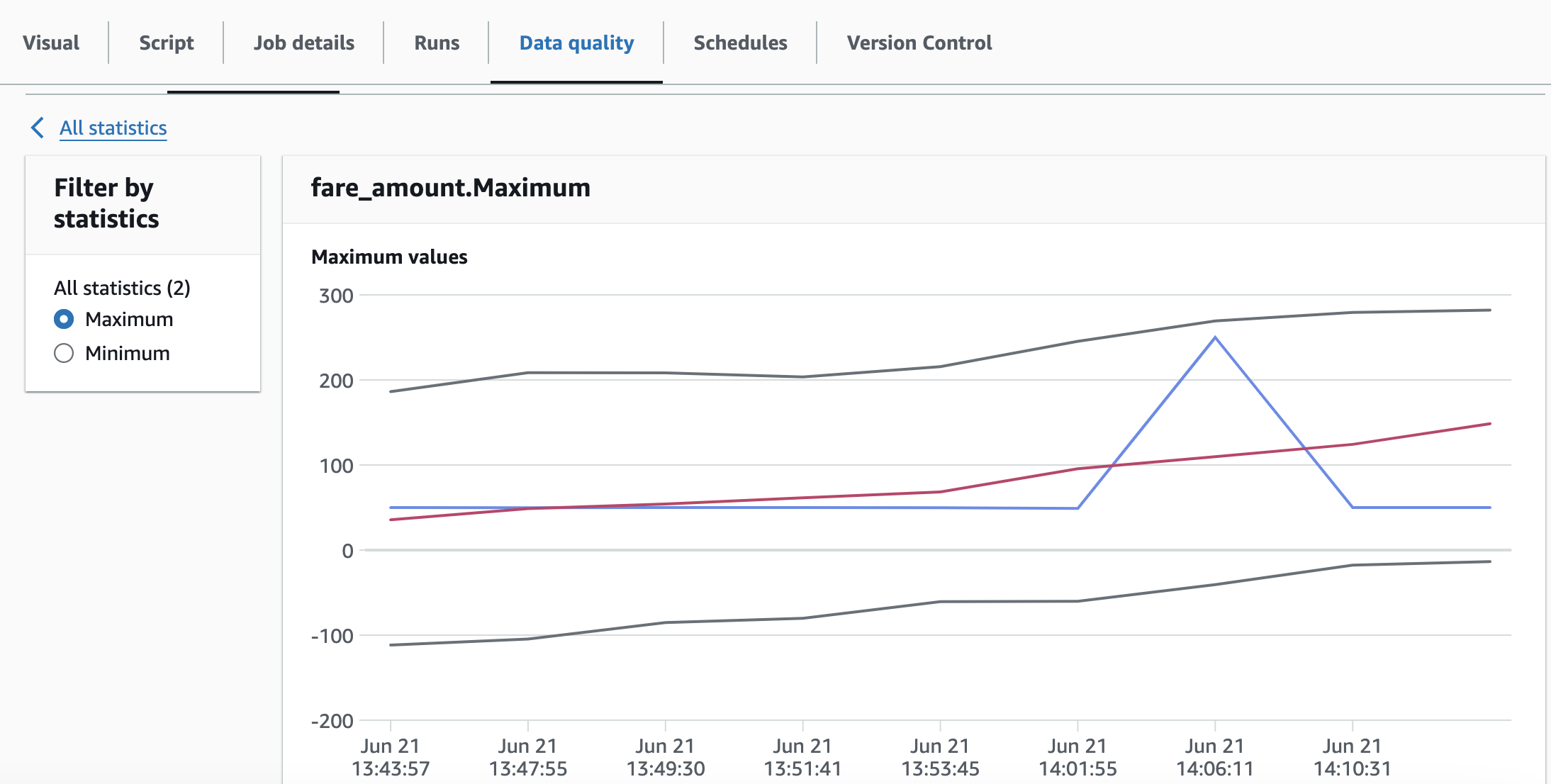
Anmerkung
AWS Glue Data Quality erfasst Statistiken nur einmal, auch wenn Sie sowohl Rule als auch Analyzer für dieselben Spalten haben, wodurch der Prozess der Statistikgenerierung effizient wird.
Anomalieerkennung
AWS Glue Data Quality erfordert mindestens drei Datenpunkte, um Anomalien zu erkennen. Es nutzt einen Machine-Learning-Algorithmus, um aus vergangenen Trends zu lernen und dann zukünftige Werte vorherzusagen. Wenn der tatsächliche Wert nicht innerhalb des vorhergesagten Bereichs liegt, erstellt AWS Glue Data Quality eine Anomaliebeobachtung. Diese bietet eine visuelle Darstellung des tatsächlichen Werts und der Trends. In der folgenden Grafik werden vier Werte angezeigt.
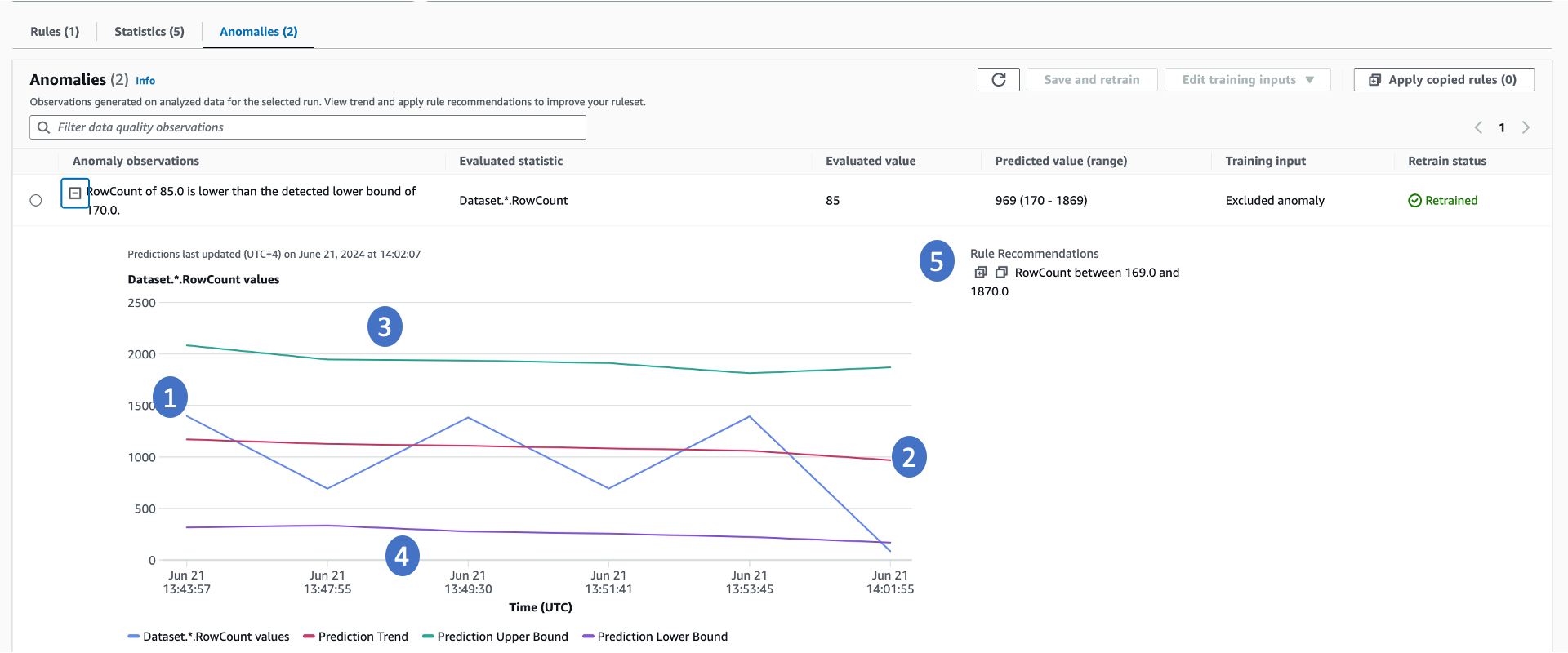
-
Die tatsächliche Statistik und ihr Trend im Zeitverlauf.
-
Ein abgeleiteter Trend, der aus dem tatsächlichen Trend gelernt wurde. Dies ist hilfreich, um die Trendrichtung zu verstehen.
-
Die mögliche Obergrenze für die Statistik.
-
Die mögliche Untergrenze für die Statistik.
-
Empfohlene Datenqualitätsregeln, mit denen diese Probleme in Zukunft erkannt werden können.
In Bezug auf Anomalien sind einige wichtige Punkte zu beachten:
-
Die Datenqualitätswerte werden durch das Auftreten von Anomalien nicht beeinträchtigt.
-
Wird eine Anomalie erkannt, gilt sie für nachfolgende Durchläufe als normal. Der Machine-Learning-Algorithmus berücksichtigt diesen anomalen Wert als Eingabe, sofern er nicht explizit ausgeschlossen wird.
Erneutes Training
Das erneute Training des Anomalieerkennungsmodells ist entscheidend, um die richtigen Anomalien zu erkennen. Wenn Anomalien erkannt werden, nimmt AWS Glue Data Quality die Anomalie als Normalwert in das Modell auf. Um sicherzustellen, dass die Anomalieerkennung korrekt funktioniert, ist es wichtig, Feedback zu geben, indem die Anomalie bestätigt oder abgelehnt wird. AWS Glue Data Quality bietet Mechanismen sowohl in AWS Glue Studio als auch APIs zur Bereitstellung von Feedback zum Modell. Weitere Informationen finden Sie in der Dokumentation zur Einrichtung der Anomalieerkennung in AWS Glue-ETL-Pipelines.
Einzelheiten zum Algorithmus zur Anomalieerkennung
-
Der Algorithmus zur Anomalieerkennung untersucht Datenstatistiken im Zeitverlauf. Der Algorithmus berücksichtigt alle verfügbaren Datenpunkte und ignoriert alle Statistiken, die explizit ausgeschlossen wurden.
-
Diese Datenstatistiken werden im AWS Glue-Dienst gespeichert, und Sie können AWS KMS Schlüssel zur Verschlüsselung bereitstellen. Informationen zur Bereitstellung von AWS KMS Schlüsseln zur Verschlüsselung der AWS Glue-Datenqualitätsstatistiken finden Sie im Sicherheitsleitfaden.
-
Die Zeitkomponente ist entscheidend für den Algorithmus zur Anomalieerkennung. Basierend auf vergangenen Werten bestimmt AWS Glue Data Quality die Ober- und Untergrenzen. Dabei wird die Zeitkomponente berücksichtigt. Die Grenzwerte unterscheiden sich für dieselben Werte in einem einminütigen, stündlichen oder täglichen Intervall.
Erfassung der Saisonalität
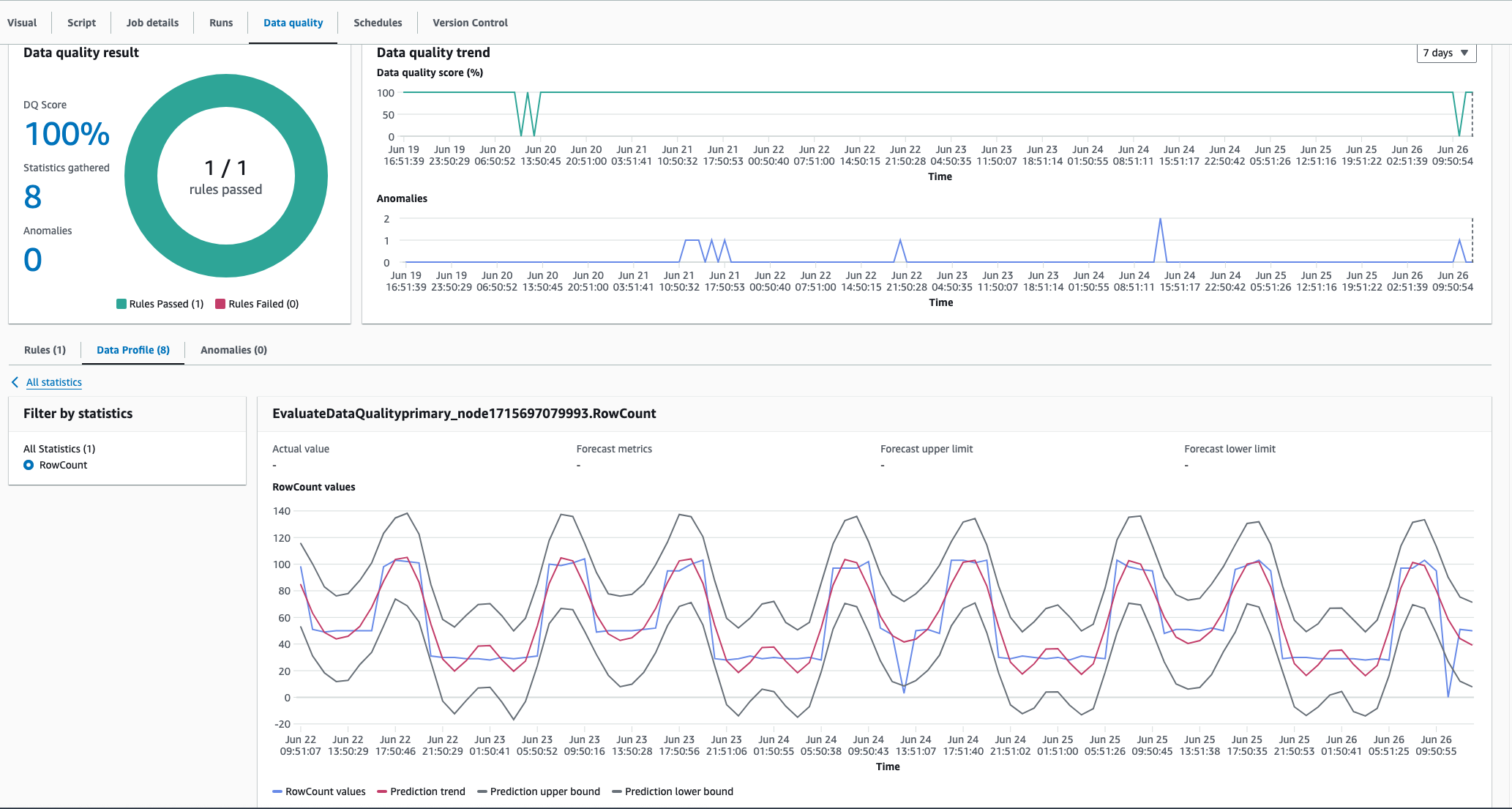
AWS Der Algorithmus zur Erkennung von Anomalien von Glue Data Quality kann saisonale Muster erfassen. Beispielsweise erkennt er, dass sich die Muster an Wochentagen von denen am Wochenende unterscheiden. Dies ist im folgenden Beispiel zu sehen, in dem AWS Glue Data Quality einen saisonalen Trend in den Datenwerten erkennt. Für die Aktivierung dieser Funktion sind keine besonderen Maßnahmen erforderlich. Im Laufe der Zeit lernt AWS Glue Data Quality saisonale Trends kennen und erkennt Anomalien, wenn diese Muster durchbrechen.
Cost (Kosten)
Die Abrechnung erfolgt auf Basis der Zeit, die für die Erkennung von Anomalien benötigt wird. Für jede Statistik wird 1 DPU für die Zeit der Anomalieerkennung berechnet. Detaillierte Beispiele finden Sie unter AWS Glue – Preise
Wesentliche Überlegungen
Für die Speicherung der Statistiken fallen keine Kosten an. Es gibt jedoch ein Limit von 100.000 Statistiken pro Konto. Diese Statistiken werden maximal zwei Jahre lang gespeichert.
