Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einrichten eines Crawlers für Amazon-S3-Ereignisbenachrichtigungen für eine Datenkatalogtabelle
Wenn Sie ein Datenkatalogziel haben, richten Sie einen Crawler für Amazon-S3-Ereignisbenachrichtigungen mit der AWS Glue-Konsole ein:
-
Legen Sie Ihre Crawler-Eigenschaften fest. Weitere Informationen finden Sie unter Festlegen von Crawler-Konfigurationsoptionen auf der AWS Glue-Konsole.
-
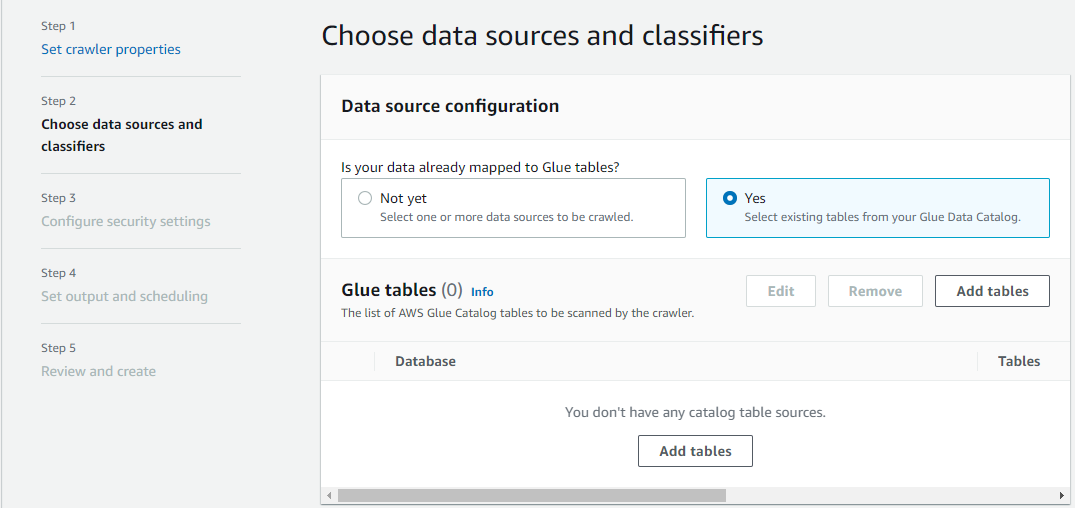
Im Abschnitt Data source configuration (Datenquellenkonfiguration) werden Sie Folgendes gefragt: Sind Ihre Daten bereits AWS Glue-Tabellen zugeordnet?
Wählen Sie Ja, um vorhandene Tabellen aus Ihrem Data Catalog als Datenquelle auszuwählen.
-
Wählen Sie im Abschnitt Glue-Tabellen die Option Tabellen hinzufügen.
-
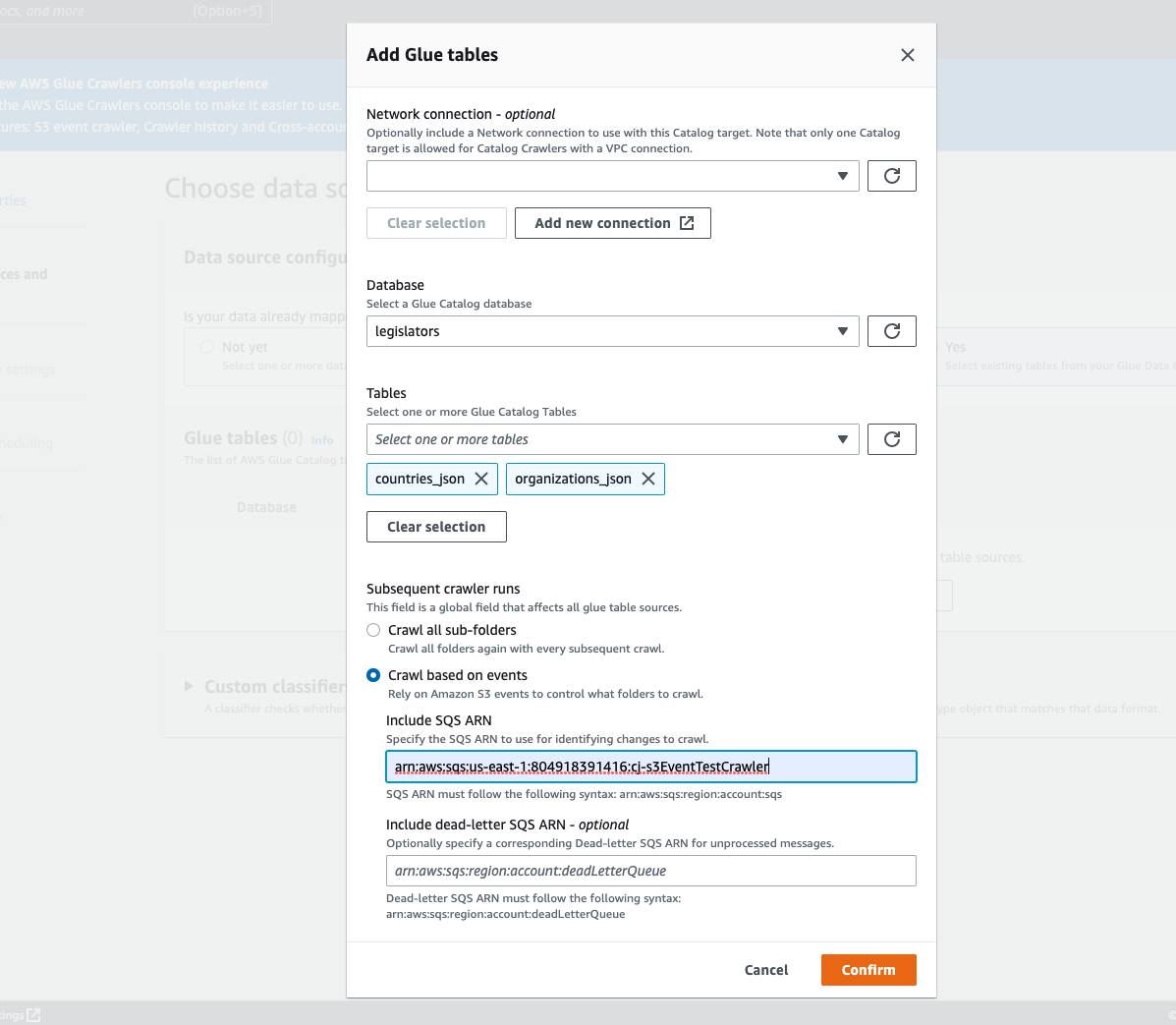
Konfigurieren Sie im Modal Tabelle hinzufügen die Datenbank und die Tabellen:
-
Network connection (Netzwerkverbindung) (Optional): Wählen Sie Add new connection (Neue Verbindung hinzufügen).
-
Datenbank: Wählen Sie eine Datenbank im Data Catalog.
-
Tabellen: Wählen Sie eine oder mehrere Tabellen aus dieser Datenbank im Data Catalog aus.
-
Subsequent crawler runs (Nachfolgende Crawler-Ausführungen): Wählen Sie Crawl based on events (Crawling basierend auf Ereignissen) aus, um Amazon-S3-Ereignisbenachrichtigungen für Ihren Crawler zu verwenden.
-
SQS ARN hinzufügen: Geben Sie die Datenspeicherparameter einschließlich eines gültigen SQS ARN an. (Beispiel:
arn:aws:sqs:region:account:sqs). -
Dead-Letter SQS ARN hinzufügen (Optional): Geben Sie einen gültigen Amazon Dead-Letter SQS ARN an. (Beispiel:
arn:aws:sqs:region:account:deadLetterQueue). -
Wählen Sie Bestätigen aus.
-
