Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Hinzufügen einer JDBC-Verbindung mit Ihren eigenen JDBC-Treibern
Sie können Ihren eigenen JDBC-Treiber verwenden, wenn Sie eine JDBC-Verbindung verwenden. Wenn der vom AWS Glue Crawler verwendete Standardtreiber keine Verbindung zu einer Datenbank herstellen kann, können Sie Ihren eigenen JDBC-Treiber verwenden. Wenn Sie beispielsweise SHA-256 mit Ihrer Postgres-Datenbank verwenden möchten und ältere Postgres-Treiber dies nicht unterstützen, können Sie Ihren eigenen JDBC-Treiber verwenden.
Unterstützte Datenquellen
| Unterstützte Datenquellen | Nicht unterstützte Datenquellen |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
*Wird unterstützt, wenn der native JDBC-Treiber verwendet wird. Nicht alle Treiber-Features können genutzt werden.
Hinzufügen eines JDBC-Treibers zu einer JDBC-Verbindung
Anmerkung
Wenn Sie sich dafür entscheiden, Ihre eigenen JDBC-Treiberversionen zu verwenden, verbrauchen AWS Glue Crawler Ressourcen in AWS Glue Jobs und Amazon S3 S3-Buckets, um sicherzustellen, dass Ihr bereitgestellter Treiber in Ihrer Umgebung ausgeführt wird. Der zusätzliche Ressourcenverbrauch wird in Ihrem Konto angezeigt. Die Kosten für AWS Glue Crawler und Jobs werden unter der Kategorie „Abrechnung“ aufgeführt. AWS Glue Darüber hinaus bedeutet das Bereitstellen eines eigenen JDBC-Treibers nicht, dass der Crawler in der Lage ist, alle Features des Treibers zu nutzen.
So fügen Sie Ihren eigenen JDBC-Treiber zu einer JDBC-Verbindung hinzu:
-
Fügen Sie die JDBC-Treiberdatei einem Amazon-S3-Speicherort hinzu. Sie können einen and/or Bucket-Ordner erstellen oder einen vorhandenen and/or Bucket-Ordner verwenden.
-
Wählen Sie in der AWS Glue Konsole im Menü auf der linken Seite unter Datenkatalog die Option Verbindungen aus und erstellen Sie dann eine neue Verbindung.
-
Füllen Sie die Felder für Verbindungseigenschaften aus und wählen Sie JDBC als Verbindungstyp aus.
-
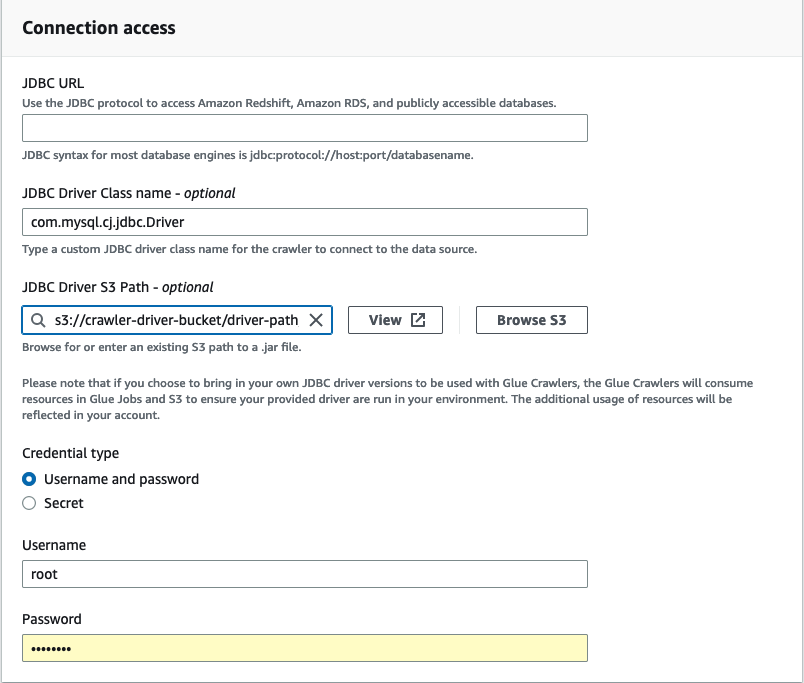
Geben Sie unter Verbindungszugriff die JDBC-URL und den Namen der JDBC-Treiberklasse ein – optional. Der Name der Treiberklasse muss für eine Datenquelle stehen, die von Crawlern unterstützt wird. AWS Glue
-
Wählen Sie den Amazon-S3-Pfad, unter dem sich der JDBC-Treiber befindet, im Feld Amazon-S3-Pfad des JDBC-Treibers aus – optional.
-
Füllen Sie die Felder für den Anmeldeinformationstyp aus, wenn Sie einen Benutzernamen, ein Passwort oder ein Secret eingeben. Wenn der Vorgang abgeschlossen ist, wählen Sie Verbindung erstellen aus.
Anmerkung
Das Testen der Verbindung wird derzeit nicht unterstützt. Beim Crawling der Datenquelle mit einem von Ihnen bereitgestellten JDBC-Treiber überspringt der Crawler diesen Schritt.
-
Fügen Sie die neu erstellte Verbindung einem Crawler hinzu. Wählen Sie in der AWS Glue Konsole im linken Menü unter Datenkatalog die Option Crawler aus und erstellen Sie dann einen neuen Crawler.
-
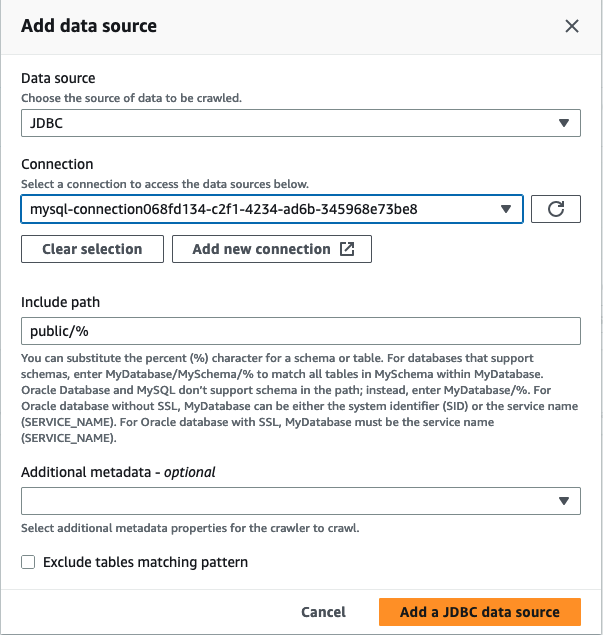
Wählen Sie im Assistenten zum Hinzufügen von Crawlern in Schritt 2 die Option Datenquelle hinzufügen aus.
-
Wählen Sie JDBC als Datenquelle und wählen Sie die Verbindung aus, die in den vorherigen Schritten erstellt wurde. Complete
-
Um Ihren eigenen JDBC-Treiber mit einem AWS Glue Crawler zu verwenden, fügen Sie der vom Crawler verwendeten Rolle die folgenden Berechtigungen hinzu:
-
Gewähren Sie Berechtigungen für die folgenden Auftragsaktionen:
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Gewähren Sie Berechtigungen für IAM-Aktionen:
iam:PassRole -
Gewähren Sie Berechtigungen für alle Amazon-S3-Aktionen:
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Gewähren Sie dem Dienstprinzipal Zugriff auf bucket/folder in der IAM-Richtlinie.
Beispiel für eine IAM-Richtlinie:
Der AWS Glue Crawler erstellt zwei Ordner: _glue_job_crawler und _crawler.
Wenn sich die Treiber-JAR-Datei im Ordner
s3://amzn-s3-demo-bucket/driver.jar"befindet, fügen Sie die folgenden Ressourcen hinzu:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]Wenn sich die Treiber-JAR-Datei im Ordner
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"befindet, fügen Sie die folgenden Ressourcen hinzu:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
Wenn Sie eine VPC verwenden, müssen Sie den Zugriff auf den AWS Glue Endpunkt zulassen, indem Sie den Schnittstellenendpunkt erstellen und ihn Ihrer Routentabelle hinzufügen. Weitere Informationen finden Sie unter Erstellen eines Schnittstellen-VPC-Endpunkts für AWS Glue
-
Wenn Sie Verschlüsselung in Ihrem Datenkatalog verwenden, erstellen Sie den AWS KMS Schnittstellenendpunkt und fügen Sie ihn Ihrer Routentabelle hinzu. Weitere Informationen finden Sie unter Erstellen eines VPC-Endpunkts für AWS KMS.
