Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Glue Konzepte
AWS Glue ist ein vollständig verwalteter ETL-Service (Extrahieren, Transformieren, Laden), mit dem Sie Daten problemlos zwischen verschiedenen Datenquellen und Zielen verschieben können. Die wichtigsten Komponenten sind:
-
Datenkatalog: Ein Metadatenspeicher, der Tabellendefinitionen, Jobdefinitionen und andere Kontrollinformationen für Ihre ETL-Workflows enthält.
-
Crawler: Programme, die eine Verbindung zu Datenquellen herstellen, Datenschemas ableiten und Metadaten-Tabellendefinitionen im Datenkatalog erstellen.
-
ETL-Aufträge: Die Geschäftslogik, um Daten aus Quellen zu extrahieren, sie mithilfe von Apache-Spark-Skripts zu transformieren und in Ziele zu laden.
-
Auslöser: Mechanismen zum Initiieren von Auftragsausführungen basierend auf Zeitplänen oder Ereignissen.
Der typische Workflow umfasst:
-
Definieren von Datenquellen und Zielen im Datenkatalog.
-
Verwenden von Crawlern, um den Datenkatalog mit Tabellenmetadaten aus Datenquellen zu füllen.
-
Definieren von ETL-Aufträgen mit Transformationsskripts, um Daten zu verschieben und zu verarbeiten.
-
Ausführen von Auträgen bei Bedarf oder basierend auf Triggern.
-
Überwachen der Auftragsleistung mithilfe von Dashboards.
Das folgende Diagramm zeigt die Architektur einer AWS Glue Umgebung.
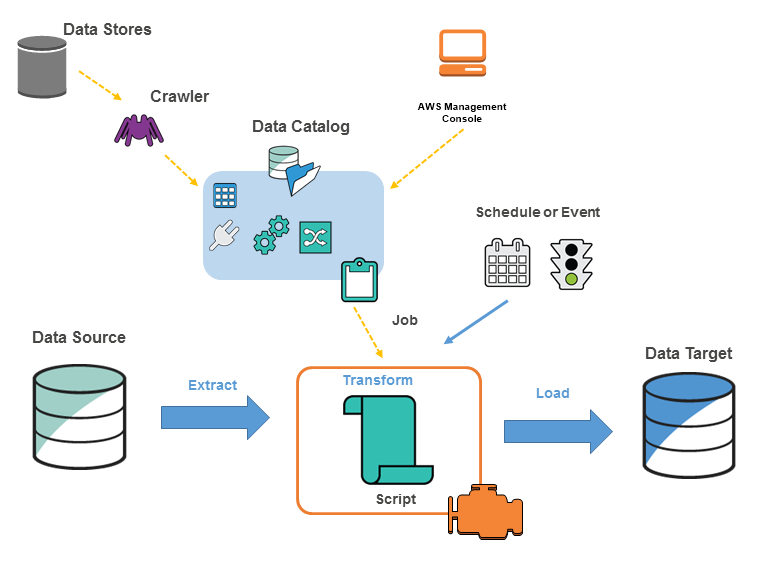
Sie definieren Jobs AWS Glue , um die Arbeit zu erledigen, die zum Extrahieren, Transformieren und Laden (ETL) von Daten aus einer Datenquelle in ein Datenziel erforderlich ist. Sie können normalerweise folgende Aktionen ausführen:
-
Für Datastore-Quellen definieren Sie einen Crawler, um den AWS Glue Data Catalog mit Metadaten-Tabellendefinitionen zu füllen. Sie verweisen Ihren Crawler auf einen Datenspeicher und der Crawler legt Tabellendefinitionen im Data Catalog an. Für Streaming-Quellen definieren Sie manuell Data-Catalog-Tabellen und legen Eigenschaften für den Datenstrom fest.
Zusätzlich zu den Tabellendefinitionen AWS Glue Data Catalog enthält der weitere Metadaten, die zur Definition von ETL-Jobs erforderlich sind. Sie verwenden diese Metadaten, wenn Sie eine Aufgabe definieren, um Ihre Daten zu transformieren.
AWS Glue kann ein Skript zur Transformation Ihrer Daten generieren. Oder Sie können das Skript in der AWS Glue Konsole oder API bereitstellen.
-
Sie können Ihre Aufgabe bei Bedarf ausführen oder sie so einrichten, dass sie bei Auftreten eines bestimmten Auslösers gestartet wird. Der Auslöser kann zeitbasiert oder ein Ereignis sein.
Wenn Ihr Auftrag ausgeführt wird, extrahiert ein Skript die Daten aus Ihrer Datenquelle, transformiert die Daten und lädt sie in Ihr Datenziel. Das Skript wird in einer Apache-Spark-Umgebung in ausgeführt AWS Glue.
Wichtig
Tabellen und Datenbanken in AWS Glue sind Objekte in der AWS Glue Data Catalog. Sie enthalten Metadaten – keine Daten aus einem Datenspeicher.
|
Textbasierte Daten, wie z. B. CSVs, müssen codiert werden, AWS Glue damit sie |
AWS Glue Terminologie
AWS Glue stützt sich bei der Erstellung und Verwaltung Ihres ETL-Workflows (Extrahieren, Transformieren und Laden) auf das Zusammenspiel mehrerer Komponenten.
AWS Glue Data Catalog
Die persistenten Metadaten werden in gespeichert AWS Glue. Es enthält Tabellendefinitionen, Jobdefinitionen und andere Kontrollinformationen zur Verwaltung Ihrer AWS Glue Umgebung. Jedes AWS Konto hat ein Konto AWS Glue Data Catalog pro Region.
Classifier
Bestimmt das Schema Ihrer Daten. AWS Glue bietet Klassifikatoren für gängige Dateitypen wie CSV, JSON, AVRO, XML und andere. Es stellt auch Classifier für gängige relationale Datenbankmanagementsysteme mit einer JDBC-Verbindung zur Verfügung. Sie können einen eigenen Classifier schreiben, indem Sie ein Grok-Muster verwenden oder indem Sie einen Row-Tag in einem XML-Dokument festlegen.
Connection (Verbindung)
Ein Data-Catalog-Objekt mit den Eigenschaften, die für die Verbindung mit einem bestimmten Datenspeicher erforderlich sind.
Crawler
Ein Programm, das sich mit einem Datenspeicher (Quelle oder Ziel) verbindet, eine priorisierte Liste von Classifiern verarbeitet, um das Schema für Ihre Daten zu bestimmen, und dann Metadatentabellen im AWS Glue Data Catalog erstellt.
Datenbank
Eine Gruppe zugeordneter Data-Catalog-Tabellendefinitionen, die in einer logischen Gruppe organisiert sind.
Datenspeicher, Datenquelle, Datenziel
Ein Datenspeicher ist ein Repository für die dauerhafte Speicherung Ihrer Daten. Beispiele hierfür sind Amazon-S3-Buckets und relationale Datenbanken. Eine Datenquelle ist ein Datenspeicher, der als Eingabe für einen Prozess oder eine Transformation verwendet wird. Ein Datenziel ist ein Datenspeicher, in den ein Prozess oder eine Transformation schreibt.
Entwicklungsendpunkt
Eine Umgebung, mit der Sie Ihre AWS Glue ETL-Skripts entwickeln und testen können.
Dynamischer Frame
Eine verteilte Tabelle, die verschachtelte Daten wie Strukturen und Arrays unterstützt. Jeder Datensatz ist selbstbeschreibend und wurde auf Schema-Flexibilität mit halbstrukturierten Daten ausgelegt. Jeder Datensatz enthält sowohl Daten als auch das Schema, das diese Daten beschreibt. Sie können sowohl dynamische Frames als auch Apache Spark DataFrames in Ihren ETL-Skripten verwenden und zwischen diesen konvertieren. Dynamische Frames bieten eine Reihe von erweiterten Transformationen für die Datenbereinigung und für ETL.
Aufgabe
Die Geschäftslogik, die für die Ausführung von ETL-Arbeiten erforderlich ist. Sie besteht aus einem Transformationsskript, Datenquellen und Datenzielen. Auftragsausführungen werden durch Auslöser ausgelöst. Diese können geplant sein oder durch Ereignisse ausgelöst werden.
Dashboard zur Auftragsperformance
AWS Glue bietet ein umfassendes Run-Dashboard für Ihre ETL-Jobs. Das Dashboard zeigt Informationen zu Auftragsausführungen in einem bestimmten Zeitraum an.
Notebook-Schnittstelle
Ein verbessertes Notebook-Erlebnis mit Ein-Klick-Einrichtung für einfache Auftragserstellung und Datenexploration. Das Notebook und die Connectors werden automatisch für Sie konfiguriert. Sie können die auf Jupyter Notebook basierende Notebook-Oberfläche verwenden, um Skripts und Workflows mithilfe der AWS Glue serverlosen Apache Spark ETL-Infrastruktur interaktiv zu entwickeln, zu debuggen und bereitzustellen. Sie können auch Ad-hoc-Abfragen, Datenanalysen und Visualisierung (z. B. Tabellen und Diagramme) in der Notebook-Umgebung durchführen.
Script
Code, der Daten aus Quellen extrahiert, transformiert und in Ziele lädt. AWS Glue generiert PySpark oder Scala-Skripte.
Tabelle
Die Metadaten-Definition, die Ihre Daten repräsentiert. Unabhängig davon, ob sich Ihre Daten in einer Amazon Simple Storage Service (Amazon S3)-, einer Amazon Relational Database Service (Amazon RDS)-Tabelle oder anderen Datenelementen befinden, definiert eine Tabelle das Schema Ihrer Daten. Eine Tabelle in der AWS Glue Data Catalog besteht aus den Namen von Spalten, Datentypdefinitionen, Partitionsinformationen und anderen Metadaten zu einem Basisdatensatz. Das Schema Ihrer Daten ist in Ihrer AWS Glue Tabellendefinition dargestellt. Die eigentlichen Daten verbleiben in ihrem ursprünglichen Datenspeicher, unabhängig davon, ob sie sich in einer Datei oder einer relationalen Datenbanktabelle befinden. AWS Glue katalogisiert Ihre Dateien und relationalen Datenbanktabellen in der. AWS Glue Data Catalog Sie werden als Quellen und Ziele verwendet, wenn Sie einen ETL-Auftrag anlegen.
Transformieren
Die Codelogik, die verwendet wird, um Ihre Daten in ein anderes Format zu bringen.
Auslöser
Initiiert einen ETL-Auftrag. Auslöser können auf der Grundlage einer geplanten Uhrzeit oder eines Ereignisses definiert werden.
Visueller Auftragseditor
Der visuelle Auftrags-Editor ist eine grafische Oberfläche, mit der Sie ETL-Aufträge (Extract, Transform, Load) in AWS Glue ganz einfach erstellen, ausführen und überwachen können. Sie können Workflows zur Datentransformation visuell zusammenstellen, sie nahtlos auf der AWS Glue Apache Spark-basierten serverlosen ETL-Engine ausführen und das Schema und die Datenergebnisse in jedem Schritt des Jobs überprüfen.
Worker
Mit zahlen Sie nur für die Zeit AWS Glue, die Ihr ETL-Job für die Ausführung benötigt. Sie müssen keine Ressourcen verwalten, es gibt keine Vorabkosten und Ihnen werden keine Start- oder Shutdown-Zeit in Rechnung gestellt. Ihnen wird ein Stundensatz berechnet, der auf der Anzahl der Datenverarbeitungseinheiten (oder DPUs) basiert, die für die Ausführung Ihres ETL-Jobs verwendet werden. Eine einzelne Datenverarbeitungseinheit (DPU) wird auch als Worker bezeichnet. AWS Glue verfügt über mehrere Workertypen, sodass Sie die Konfiguration auswählen können, die Ihren Anforderungen an die Auftragslatenz und die Kosten entspricht. Worker sind in den Standardkonfigurationen und in den Konfigurationen G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X erhältlich sowie in arbeitsspeicheroptimierten Konfigurationen R.1X, R.2X, R.4X, R.8X.
