Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
DynamoDB-Konnektor mit Spark-Unterstützung DataFrame
Der DynamoDB-Konnektor mit DataFrame Spark-Unterstützung ermöglicht es Ihnen, mithilfe von Spark-APIs aus Tabellen in DynamoDB zu lesen und in Tabellen zu schreiben. DataFrame Die Schritte zur Einrichtung des Connectors sind dieselben wie für den DynamicFrame-based Connector und finden Sie hier.
Um die DataFrame-based Connector-Bibliothek zu laden, stellen Sie sicher, dass Sie eine DynamoDB-Verbindung an den Glue-Job anhängen.
Anmerkung
Die Benutzeroberfläche der Glue-Konsole unterstützt derzeit nicht das Erstellen einer DynamoDB-Verbindung. Sie können Glue CLI (CreateConnection) verwenden, um eine DynamoDB-Verbindung herzustellen:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Nachdem Sie die DynamoDB-Verbindung erstellt haben, können Sie sie über CLI (CreateJob, UpdateJob) oder direkt auf der Seite „Jobdetails“ an Ihren Glue-Job anhängen:
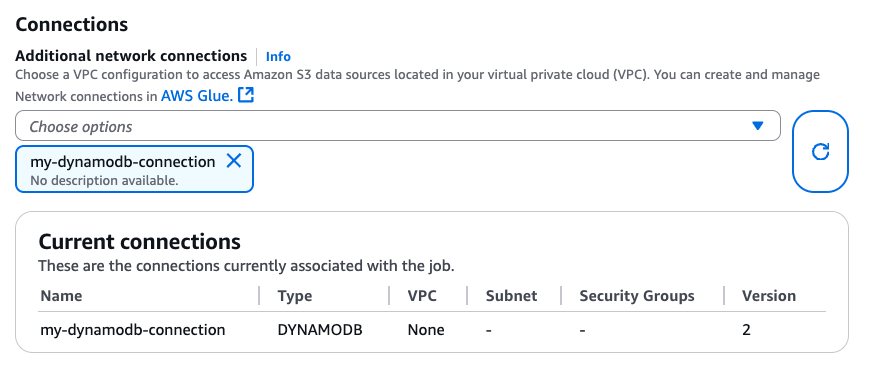
Nachdem Sie sichergestellt haben, dass eine Verbindung mit DYNAMODB Type an Ihren Glue-Job angeschlossen ist, können Sie die folgenden Lese-, Schreib- und Exportvorgänge vom DataFrame-based Konnektor aus verwenden.
Mit dem Konnektor aus DynamoDB lesen und in DynamoDB schreiben DataFrame-based
Die folgenden Codebeispiele zeigen, wie Sie über den Konnektor aus DynamoDB-Tabellen lesen und in sie schreiben. DataFrame-based Sie demonstrieren das Lesen von einer Tabelle und das Schreiben in eine andere Tabelle.
DynamoDB-Export über den Konnektor verwenden DataFrame-based
Der Exportvorgang wird dem Lesevorgang für DynamoDB-Tabellen mit einer Größe von mehr als 80 GB vorgezogen. Die folgenden Codebeispiele zeigen, wie aus einer Tabelle gelesen, nach S3 exportiert und die Anzahl der Partitionen über den DataFrame-based Konnektor gedruckt wird.
Anmerkung
Die DynamoDB-Exportfunktion ist über das DynamoDBExport Scala-Objekt verfügbar. Python-Benutzer können über das JVM-Interop von Spark darauf zugreifen oder das AWS-SDK für Python (boto3) mit der DynamoDB-API verwenden. ExportTableToPointInTime
Konfigurationsoptionen
Lesen Sie die Optionen
| Option | Description | Standard |
|---|---|---|
dynamodb.input.tableName |
DynamoDB-Tabellenname (erforderlich) | - |
dynamodb.throughput.read |
Die zu verwendenden Lesekapazitätseinheiten (RCU). Falls nicht spezifiziert, dynamodb.throughput.read.ratio wird sie für die Berechnung verwendet. |
- |
dynamodb.throughput.read.ratio |
Das Verhältnis von Lesekapazitätseinheiten (RCU) zur Nutzung | 0.5 |
dynamodb.table.read.capacity |
Die Lesekapazität der On-Demand-Tabelle, die zur Berechnung des Durchsatzes verwendet wird. Dieser Parameter ist nur in On-Demand-Kapazitätstabellen wirksam. Die Standardeinstellung ist auf Leseeinheiten mit warmem Durchsatz eingestellt. | - |
dynamodb.splits |
Definiert, wie viele Segmente bei parallel Scanvorgängen verwendet werden. Falls nicht angegeben, berechnet der Connector einen angemessenen Standardwert. | - |
dynamodb.consistentRead |
Ob stark konsistente Lesevorgänge verwendet werden sollen | FALSE |
dynamodb.input.retry |
Definiert, wie viele Wiederholungen wir durchführen, wenn es eine Ausnahme gibt, die erneut versucht werden kann. | 10 |
Optionen schreiben
| Option | Description | Standard |
|---|---|---|
dynamodb.output.tableName |
DynamoDB-Tabellenname (erforderlich) | - |
dynamodb.throughput.write |
Die zu verwendenden Schreibkapazitätseinheiten (WCU). Falls nicht angegeben, dynamodb.throughput.write.ratio wird sie für die Berechnung verwendet. |
- |
dynamodb.throughput.write.ratio |
Das Verhältnis von Schreibkapazitätseinheiten (WCU) zur Nutzung | 0.5 |
dynamodb.table.write.capacity |
Die Schreibkapazität der On-Demand-Tabelle, die für die Berechnung des Durchsatzes verwendet wird. Dieser Parameter ist nur in On-Demand-Kapazitätstabellen wirksam. Standardmäßig werden Schreibeinheiten mit warmem Durchsatz verwendet. | - |
dynamodb.item.size.check.enabled |
Falls wahr, berechnet der Konnektor die Elementgröße und bricht ab, wenn die Größe die maximale Größe überschreitet, bevor er in die DynamoDB-Tabelle schreibt. | TRUE |
dynamodb.output.retry |
Definiert, wie viele Wiederholungen wir durchführen, wenn es eine Ausnahme gibt, die erneut versucht werden kann. | 10 |
Optionen für den Export
| Option | Description | Standard |
|---|---|---|
dynamodb.export |
Wenn auf gesetzt, wird der AWS Glue DynamoDB-Exportconnector ddb aktiviert, über den während des Glue-Jobs ein neuer aufgerufen ExportTableToPointInTimeRequet wird. AWS Ein neuer Export wird mit dem Speicherort generiert, der von dynamodb.s3.bucket an dynamodb.s3.prefix übergeben wurde. Wenn auf gesetzt, wird der AWS Glue DynamoDB-Exportconnector s3 aktiviert, aber die Erstellung eines neuen DynamoDB-Exports übersprungen und stattdessen dynamodb.s3.bucket and dynamodb.s3.prefix als Amazon S3 S3-Speicherort für den letzten Export dieser Tabelle verwendet. |
ddb |
dynamodb.tableArn |
Die DynamoDB-Tabelle, aus der gelesen werden soll. Erforderlich, wenn dynamodb.export auf ddb festgelegt wird. |
|
dynamodb.simplifyDDBJson |
Wenn auf gesetzttrue, wird eine Transformation durchgeführt, um das Schema der DynamoDB-JSON-Struktur zu vereinfachen, die in Exporten vorhanden ist. |
FALSE |
dynamodb.s3.bucket |
Der S3-Bucket zum Speichern temporärer Daten während des DynamoDB-Exports (erforderlich) | |
dynamodb.s3.prefix |
Das S3-Präfix zum Speichern temporärer Daten während des DynamoDB-Exports | |
dynamodb.s3.bucketOwner |
Geben Sie den Bucket-Besitzer an, der für den kontoübergreifenden Amazon S3 S3-Zugriff benötigt wird | |
dynamodb.s3.sse.algorithm |
Art der Verschlüsselung, die für den Bucket verwendet wird, in dem temporäre Daten gespeichert werden. Gültige Werte sind AES256 und KMS. |
|
dynamodb.s3.sse.kmsKeyId |
Die ID des AWS KMS verwalteten Schlüssels, der zur Verschlüsselung des S3-Buckets verwendet wird, in dem temporäre Daten gespeichert werden (falls zutreffend). | |
dynamodb.exportTime |
Ein Zeitpunkt, zu dem der Export erfolgen soll. Gültige Werte: Zeichenketten, die Zeitpunkte darstellen ISO-8601 . |
Allgemeine Optionen
| Option | Description | Standard |
|---|---|---|
dynamodb.sts.roleArn |
Der ARN der IAM-Rolle, der für den kontoübergreifenden Zugriff übernommen werden soll | - |
dynamodb.sts.roleSessionName |
Name der STS-Sitzung | glue-dynamodb-sts-session |
dynamodb.sts.region |
Region für den STS-Client (für regionsübergreifende Rollenübernahme) | Entspricht der Option region |
