Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verstehen, wie man Amazon EMR-Cluster erstellt und mit ihnen arbeitet
Dieses Thema bietet eine Übersicht über die Amazon-EMR-Cluster, einschließlich der Übermittlung von Aufträgen an einen Cluster, der Verarbeitung von Daten und der verschiedenen Status, die der Cluster während der Verarbeitung durchläuft.
In diesem Thema
Machen Sie sich mit Clustern und Knoten vertraut
Die zentrale Komponente des Amazon EMR ist der Cluster. Ein Cluster ist eine Sammlung von Amazon Elastic Compute Cloud (Amazon EC2)-Instances. Jede Instance in einem Cluster wird als Knoten bezeichnet. Jeder Knoten verfügt über eine Rolle im Cluster – Knotentyp genannt. Amazon EMR installiert auch verschiedene Softwarekomponenten auf den einzelnen Knotentypen und überträgt so jedem Knoten eine Rolle in einer verteilten Anwendung wie Apache Hadoop.
Amazon EMR verfügt über die folgenden Knotentypen:
-
Primärknoten: Knoten, der den Cluster durch die Ausführung von Softwarekomponenten verwaltet, die die Verteilung von Daten und Aufgaben auf andere Knoten zur Verarbeitung koordinieren. Der Primärknoten überwacht den Status der Aufgaben und überwacht den Zustand des Clusters. Jeder Cluster verfügt über einen Primärknoten und es ist möglich, einen Einzelknoten-Cluster nur mit dem Primärknoten zu erstellen.
-
Kernknoten: Ein Knoten mit Softwarekomponenten, die Aufgaben ausführen und Daten im Hadoop Distributed File System (HDFS) auf Ihrem Cluster speichern. Multi-node Cluster haben mindestens einen Kernknoten.
-
Aufgabenknoten: Knoten mit Software-Komponenten, die nur Aufgaben ausführen und keine Daten in HDFS speichern. Aufgabenknoten sind optional.
Übermitteln von Aufträgen an einen Cluster
Bei Ausführung eines Clusters in Amazon EMR haben Sie mehrere Möglichkeiten, die auszuführende Arbeit anzugeben.
-
Stellen Sie die gesamte Definition der auszuführenden Arbeit in Funktionen bereit, die Sie als Schritte angeben, wenn Sie einen Cluster erstellen. Dies wird in der Regel für Cluster durchgeführt, die eine bestimmte Datenmenge verarbeiten und nach Abschluss der Verarbeitung beendet werden.
-
Erstellen Sie einen Cluster mit langer Laufzeit und verwenden Sie die Amazon EMR-Konsole, die Amazon EMR-API oder die AWS CLI zum Senden von Schritten, die einen oder mehrere Jobs enthalten können. Weitere Informationen finden Sie unter Arbeit an einen Amazon EMR-Cluster einreichen.
-
Erstellen Sie einen Cluster, stellen Sie nach Bedarf eine Verbindung zum Primärknoten und zu anderen Knoten mit SSH her und verwenden Sie die von den installierten Anwendungen bereitgestellten Schnittstellen, um Aufgaben auszuführen und Abfragen zu senden entweder in Skripts oder interaktiv. Weitere Informationen finden Sie im Handbuch zu Amazon-EMR-Versionen.
Verarbeiten von Daten
Wenn Sie einen Cluster starten, bestimmen Sie die zu installierenden Frameworks und Anwendungen, damit Ihren Anforderungen an die Datenverarbeitung entsprochen wird. Um Daten in Ihrem Amazon-EMR-Cluster zu verarbeiten, können Sie Aufträge oder Abfragen direkt an installierte Anwendungen senden oder alternativ die Schritte im Cluster ausführen.
Übermitteln von Aufträgen direkt an die Anwendungen
Sie können Aufträge direkt an die Software übermitteln, die auf Ihrem Amazon-EMR-Cluster installiert ist, und anschließend damit interagieren. Dazu stellen Sie in der Regel eine sichere Verbindung mit dem Primärknoten her und greifen auf die Schnittstellen und Tools zu, die für die Software, die direkt auf Ihrem Cluster ausgeführt wird, verfügbar sind. Weitere Informationen finden Sie unter Eine Verbindung zu einem Amazon-EMR-Cluster herstellen.
Ausführen von Schritten zur Verarbeitung von Daten
Sie können einem Amazon-EMR-Cluster einen oder mehrere angeordnete Schritte übermitteln. Jeder Schritt ist eine Arbeitseinheit mit Anweisungen zur Verarbeitung von Daten durch auf dem Cluster installierte Software.
Es folgt ein Beispiel für einen Prozess mit vier Schritten:
-
Übermitteln Sie die Eingabedatenmenge für die Verarbeitung.
-
Verarbeiten Sie die Ausgabe des ersten Schritts mithilfe eines Pig-Programms.
-
Verarbeiten Sie eine zweites Eingabedatenmenge mithilfe eines Hive-Programms.
-
Schreiben Sie einen Ausgabedatensatz.
Wenn Sie Daten in Amazon EMR verarbeiten, wird die Eingabe als Daten in Dateien gespeichert, die sich im zugrunde liegenden Dateisystem, wie z. B. Amazon S3 oder HDFS, befinden. Diese Daten werden während des Verarbeitungsablaufs von einem Schritt zum nächsten weitergeleitet. Im letzten Schritt werden die Ausgabedaten in einen bestimmten Speicherort geschrieben, wie zum Beispiel in einen Amazon-S3-Bucket.
Die Schritte werden in der folgenden Reihenfolge ausgeführt:
-
Eine Anfrage wird übermittelt, um mit den Verarbeitungsschritten zu beginnen.
-
Der Status aller Schritte wird auf PENDING (AUSSTEHEND) festgelegt.
-
Wenn der erste Schritt der Sequenz gestartet wird, wird dessen Status in RUNNING (WIRD AUSGEFÜHRT) geändert. Die anderen Schritte bleiben im Status PENDING (AUSSTEHEND).
-
Nachdem der erste Schritt abgeschlossen ist, wird dessen Status in COMPLETED (ABGESCHLOSSEN) geändert.
-
Der nächste Schritt der Sequenz wird gestartet und dessen Status wird in RUNNING (WIRD AUSGEFÜHRT) geändert. Nachdem er abgeschlossen ist, wird dessen dessen Status in COMPLETED (ABGESCHLOSSEN) geändert.
-
Dieses Muster wiederholt sich für jeden Schritt, bis alle Schritte abgeschlossen sind und die Verarbeitung beendet wird.
Das folgende Diagramm stellt die Schrittsequenz sowie die Statusänderung für die einzelnen Schritte während der Verarbeitung dar.

Wenn ein Schritt während der Verarbeitung fehlschlägt, wechselt der Status zu FEHLGESCHLAGEN. Sie können für jeden Schritt festlegen, was als Nächstes geschieht. Standardmäßig werden alle verbleibenden Schritte in der Sequenz auf ABGEBROCHEN festgelegt und wenn ein vorangehender Schritt fehlschlägt. Außerdem können Sie das Ignorieren des Fehlers aktivieren, damit die verbleibenden Schritte ausgeführt werden oder der Cluster sofort beendet wird.
Das folgende Diagramm stellt die Schrittsequenz sowie die standardmäßige Statusänderung dar, wenn ein Schritt während der Verarbeitung fehlschlägt.

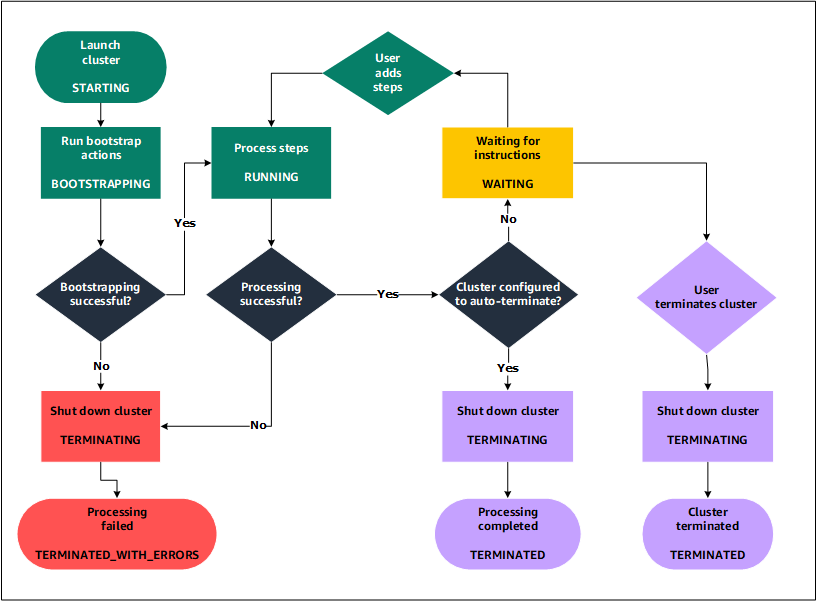
Verstehen des Cluster-Lebenszyklus
Ein erfolgreicher Amazon-EMR-Cluster befolgt diesen Prozess:
-
Amazon EMR stellt zunächst EC2-Instances im Cluster für jede Instance nach Maßgabe Ihrer Spezifikationen bereit. Weitere Informationen finden Sie unter Amazon EMR-Cluster-Hardware und -Netzwerke konfigurieren. Amazon EMR verwendet für alle Instances das Standard-AMI für Amazon EMR oder ein von Ihnen angegebenes benutzerdefiniertes Amazon-Linux-AMI. Weitere Informationen finden Sie unter Verwendung eines benutzerdefinierten AMI für mehr Flexibilität bei der Amazon EMR-Clusterkonfiguration. Während dieser Phase ist der Cluster-Status auf
STARTINGgesetzt. -
Amazon EMR; führt Bootstrap-Aktionen aus, die Sie für jede Instance angeben. Sie können Bootstrap-Aktionen verwenden, um benutzerdefinierte Anwendungen zu installieren und erforderliche Anpassungen vorzunehmen. Weitere Informationen finden Sie unter Erstellen Sie Bootstrap-Aktionen, um zusätzliche Software mit einem Amazon EMR-Cluster zu installieren. Während dieser Phase ist der Cluster-Status auf
BOOTSTRAPPINGgesetzt. -
Amazon EMR installiert die nativen Anwendungen, die Sie angeben, wenn Sie den Cluster erstellen, z. B. Hive, Hadoop, Spark usw.
-
Nachdem Bootstrap-Aktionen erfolgreich abgeschlossen und native Anwendungen installiert wurden, lautet der Cluster-Status
RUNNING. An diesem Punkt können Sie die Verbindung zu Cluster-Instances herstellen. Der Cluster führt sequenziell die Schritte aus, die Sie beim Erstellen des Clusters angegeben haben. Sie können zusätzliche Schritte senden, die dann nach Abschluss der vorherigen Schritte ausgeführt werden. Weitere Informationen finden Sie unter Arbeit an einen Amazon EMR-Cluster einreichen. -
Nachdem die Schritte erfolgreich ausgeführt wurden, erhält der Cluster den Status
WAITING. Wenn ein Cluster für die automatische Beendigung nach Abschluss des letzten Schritts konfiguriert ist, wechselt der Cluster den StatusTERMINATING-Zustand und dann in denTERMINATED-Zustand. Wenn der Cluster so konfiguriert ist, dass er wartet, müssen Sie ihn manuell herunterfahren, wenn Sie ihn nicht mehr benötigen. Nachdem Sie den Cluster manuell beenden haben, wird dieser in den StatusTERMINATINGversetzt und danach in den StatusTERMINATED.
Ein Fehler im Cluster-Lebenszyklus veranlasst, Amazon EMR den Cluster und dessen Instances zu beenden, sofern Sie nicht den Beendigungsschutz aktivieren. Wenn ein Cluster wegen eines Fehlers beendet wird, werden alle auf dem Cluster befindlichen Daten gelöscht und dem Cluster-Status wird der Status TERMINATED_WITH_ERRORS zugewiesen. Wenn Sie den Beendigungsschutz aktiviert haben, können Sie Daten vom Cluster abrufen und anschließend den Beendigungsschutz entfernen und den Cluster beenden. Weitere Informationen finden Sie unter Verwenden Sie den Kündigungsschutz, um Ihre Amazon EMR-Cluster vor einem versehentlichen Herunterfahren zu schützen.
Das folgende Diagramm stellt den Lebenszyklus eines Clusters dar und wie die einzelnen Lebenszyklusphasen einem bestimmten Cluster-Status zugeordnet sind.