Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von selbst gehosteten Jupyter Notebooks
Sie können Jupyter oder JupyterLab Notebooks auf einer Amazon EC2 EC2-Instance oder in Ihrem eigenen Amazon EKS-Cluster als selbst gehostetes Jupyter-Notebook hosten und verwalten. Anschließend können Sie interaktive Workloads mit Ihren selbstgehosteten Jupyter-Notebooks ausführen. In den folgenden Abschnitten wird der Prozess zur Einrichtung und Bereitstellung eines selbst gehosteten Jupyter Notebooks auf einem Amazon-EKS-Cluster beschrieben.
Erstellen eines selbstgehosteten Jupyter Notebooks auf einem EKS-Cluster
Eine Sicherheitsgruppe erstellen
Bevor Sie einen interaktiven Endpunkt erstellen und einen selbst gehosteten Jupyter oder ein selbst gehostetes Notebook ausführen können, müssen Sie eine Sicherheitsgruppe erstellen, um den Verkehr zwischen Ihrem JupyterLab Notebook und dem interaktiven Endpunkt zu kontrollieren. Informationen zur Verwendung der Amazon EC2-Konsole oder des Amazon EC2-SDK zum Erstellen der Sicherheitsgruppe finden Sie in den Schritten unter Sicherheitsgruppe erstellen im Amazon EC2 EC2-Benutzerhandbuch. Sie sollten die Sicherheitsgruppe in der VPC erstellen, in der Sie Ihren Notebook-Server bereitstellen möchten.
Um dem Beispiel in diesem Handbuch zu folgen, verwenden Sie dieselbe VPC wie Ihr Amazon-EKS-Cluster. Wenn Sie Ihr Notebook in einer VPC hosten möchten, die sich von der VPC für Ihren Amazon EKS-Cluster unterscheidet, müssen Sie möglicherweise eine Peering-Verbindung zwischen diesen beiden herstellen. VPCs Schritte zum Herstellen einer Peering-Verbindung zwischen zwei VPCs Personen finden Sie unter Erstellen einer VPC-Peering-Verbindung im Amazon VPC Getting Started Guide.
Sie benötigen die ID für die Sicherheitsgruppe, um im nächsten Schritt einen interaktiven Endpunkt für Amazon EMR in EKS zu erstellen.
Einen interaktiven Endpunkt für Amazon EMR in EKS erstellen
Nachdem Sie die Sicherheitsgruppe für Ihr Notebook erstellt haben, gehen Sie wie unter Einen interaktiven Endpunkt für Ihren virtuellen Cluster erstellen beschrieben vor, um einen interaktiven Endpunkt zu erstellen. Sie müssen die Sicherheitsgruppen-ID angeben, die Sie für Ihr Notebook unter Eine Sicherheitsgruppe erstellen erstellt haben.
Geben Sie die Sicherheits-ID anstelle von your-notebook-security-group-id in den folgenden Einstellungen zur Änderung der Konfiguration ein:
--configuration-overrides '{ "applicationConfiguration": [ { "classification": "endpoint-configuration", "properties": { "notebook-security-group-id": "your-notebook-security-group-id" } } ], "monitoringConfiguration": { ...'
Abrufen der Gateway-Server-URL Ihres interaktiven Endpunkts
Nachdem Sie einen interaktiven Endpunkt erstellt haben, rufen Sie die Gateway-Server-URL mit dem describe-managed-endpoint-Befehl in AWS CLI ab. Sie benötigen diese URL, um Ihr Notebook mit dem Endpunkt zu verbinden. Die Gateway-Server-URL ist ein privater Endpunkt.
aws emr-containers describe-managed-endpoint \ --regionregion\ --virtual-cluster-idvirtualClusterId\ --idendpointId
Der Endpunkt befindet sich zunächst im Status CREATING. Nach einigen Minuten wechselt er in den ACTIVE-Status. Wenn der Endpunkt ACTIVE ist, kann er verwendet werden.
Notieren Sie sich das serverUrl-Attribut, das der aws emr-containers
describe-managed-endpoint-Befehl vom aktiven Endpunkt zurückgibt. Sie benötigen diese URL, um Ihr Notebook mit dem Endpunkt zu verbinden, wenn Sie Ihren selbst gehosteten Jupyter oder Ihr selbst gehostetes Notebook bereitstellen. JupyterLab
Rufen Sie ein Authentifizierungstoken ab, um eine Verbindung zum interaktiven Endpunkt herzustellen
Um von einem Jupyter oder JupyterLab Notebook aus eine Verbindung zu einem interaktiven Endpunkt herzustellen, müssen Sie mit der API ein Sitzungstoken generieren. GetManagedEndpointSessionCredentials Das Token dient als Authentifizierungsnachweis für die Verbindung zum interaktiven Endpunktserver.
Der folgende Befehl wird anhand eines Ausgabebeispiels weiter unten ausführlicher erklärt.
aws emr-containers get-managed-endpoint-session-credentials \ --endpoint-identifierendpointArn\ --virtual-cluster-identifiervirtualClusterArn\ --execution-role-arnexecutionRoleArn\ --credential-type "TOKEN" \ --duration-in-secondsdurationInSeconds\ --regionregion
endpointArn-
Der ARN Ihres Endpunkts. Sie finden den ARN im Ergebnis eines
describe-managed-endpoint-Aufrufs. virtualClusterArn-
Die ARN des virtuellen Clusters.
executionRoleArn-
Die ARN der Ausführungsrolle.
durationInSeconds-
Die Dauer in Sekunden, für die das Token gültig ist. Die Standarddauer beträgt 15 Minuten (
900) und die Höchstdauer 12 Stunden (43200). region-
Dieselbe Region wie Ihr Endpunkt.
Die Ausgabe sollte etwa wie das folgende Beispiel aussehen. Notieren Sie sich den session-token
{
"id": "credentialsId",
"credentials": {
"token": "session-token"
},
"expiresAt": "2022-07-05T17:49:38Z"
}Beispiel: Stellen Sie ein Notebook bereit JupyterLab
Nachdem Sie die obigen Schritte abgeschlossen haben, können Sie dieses Beispielverfahren ausprobieren, um ein JupyterLab Notebook mit Ihrem interaktiven Endpunkt im Amazon EKS-Cluster bereitzustellen.
-
Erstellen Sie einen Namespace, um den Notebook-Server auszuführen.
-
Erstellen Sie lokal eine Datei
notebook.yamlund den folgenden Inhalten. Der Inhalt der Datei wird im Folgenden beschrieben.apiVersion: v1 kind: Pod metadata: name: jupyter-notebook namespace:namespacespec: containers: - name: minimal-notebook image: jupyter/all-spark-notebook:lab-3.1.4 # open source image ports: - containerPort: 8888 command: ["start-notebook.sh"] args: ["--LabApp.token=''"] env: - name: JUPYTER_ENABLE_LAB value: "yes" - name: KERNEL_LAUNCH_TIMEOUT value: "400" - name: JUPYTER_GATEWAY_URL value: "serverUrl" - name: JUPYTER_GATEWAY_VALIDATE_CERT value: "false" - name: JUPYTER_GATEWAY_AUTH_TOKEN value: "session-token"Wenn Sie das Jupyter-Notebook in einem reinen Fargate-Cluster bereitstellen, kennzeichnen Sie den Jupyter-Pod mit einer
role-Kennzeichnung, wie im folgenden Beispiel gezeigt:... metadata: name: jupyter-notebook namespace: default labels: role:example-role-name-labelspec: ...namespace-
Der Kubernetes-Namespace, in dem das Notebook bereitgestellt wird.
serverUrl-
Das
serverUrl-Attribut, in dem derdescribe-managed-endpoint-Befehl in Abrufen der Gateway-Server-URL Ihres interaktiven Endpunkts zurückgegeben wurde. session-token-
Das
session-token-Attribut, in dem derget-managed-endpoint-session-credentials-Befehl in Rufen Sie ein Authentifizierungstoken ab, um eine Verbindung zum interaktiven Endpunkt herzustellen zurückgegeben wurde. KERNEL_LAUNCH_TIMEOUT-
Die Zeit in Sekunden, die der interaktive Endpunkt darauf wartet, dass der Kernel den RUNNING-Status erreicht. Stellen Sie sicher, dass genügend Zeit bis zum Abschluss des Kernelstarts vergangen ist, indem Sie das Timeout für den Kernelstart auf einen geeigneten Wert setzen (maximal 400 Sekunden).
KERNEL_EXTRA_SPARK_OPTS-
Optional können Sie zusätzliche Spark-Konfigurationen für die Spark-Kernel übergeben. Legen Sie diese Umgebungsvariable mit den Werten als Spark-Konfigurationseigenschaft fest, wie im folgenden Beispiel gezeigt:
- name: KERNEL_EXTRA_SPARK_OPTS value: "--conf spark.driver.cores=2 --conf spark.driver.memory=2G --conf spark.executor.instances=2 --conf spark.executor.cores=2 --conf spark.executor.memory=2G --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.shuffleTracking.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=5 --conf spark.dynamicAllocation.initialExecutors=1 "
-
Stellen Sie die Pod-Spezifikation in Ihrem Amazon-EKS-Cluster bereit:
kubectl apply -f notebook.yaml -nnamespaceDadurch wird ein minimales JupyterLab Notizbuch gestartet, das mit Ihrem interaktiven Endpunkt Amazon EMR auf EKS verbunden ist. Warten Sie, bis der Pod RUNNING ist. Sie können den Status mit dem folgenden Befehl überprüfen:
kubectl get pod jupyter-notebook -nnamespaceWenn der Pod bereit ist, gibt der
get pod-Befehl eine Ausgabe zurück, die der folgenden ähnelt:NAME READY STATUS RESTARTS AGE jupyter-notebook 1/1 Running 0 46s -
Ordnen Sie die Notebook-Sicherheitsgruppe dem Knoten zu, für den das Notebook geplant ist.
-
Identifizieren Sie zunächst mit dem
describe pod-Befehl den Knoten, für den derjupyter-notebook-Pod geplant ist.kubectl describe pod jupyter-notebook -nnamespace Öffnen Sie die Amazon EKS-Konsole unter https://console.aws.amazon.com/eks/home#/clusters
. -
Navigieren Sie zur Registerkarte Datenverarbeitung für Ihren Amazon-EKS-Cluster und wählen Sie den durch den
describe pod-Befehl identifizierten Knoten aus. Wählen Sie die Instance-ID für den Knoten aus. -
Wählen Sie im Menü Aktionen die Option Sicherheit > Sicherheitsgruppen ändern aus, um die Sicherheitsgruppe anzuhängen, die Sie in Eine Sicherheitsgruppe erstellen erstellt haben.
-
Wenn Sie den Jupyter-Notebook-Pod bereitstellen AWS Fargate, erstellen Sie einen
SecurityGroupPolicy, der auf den Jupyter-Notebook-Pod angewendet werden soll, mit der Rollenbezeichnung:cat >my-security-group-policy.yaml <<EOF apiVersion: vpcresources.k8s.aws/v1beta1 kind: SecurityGroupPolicy metadata: name:example-security-group-policy-namenamespace: default spec: podSelector: matchLabels: role:example-role-name-labelsecurityGroups: groupIds: -your-notebook-security-group-idEOF
-
-
Führen Sie nun einen Port-Forward durch, sodass Sie lokal auf die Schnittstelle zugreifen können: JupyterLab
kubectl port-forward jupyter-notebook 8888:8888 -nnamespaceSobald das läuft, navigieren Sie zu Ihrem lokalen Browser und besuchen
localhost:8888Sie die JupyterLab Benutzeroberfläche:
-
Erstellen Sie von aus JupyterLab ein neues Scala-Notizbuch. Hier ist ein Beispielcodeausschnitt, den Sie ausführen können, um den Wert von Pi zu approximieren:
import scala.math.random import org.apache.spark.sql.SparkSession /** Computes an approximation to pi */ val session = SparkSession .builder .appName("Spark Pi") .getOrCreate() val slices = 2 // avoid overflow val n = math.min(100000L * slices, Int.MaxValue).toInt val count = session.sparkContext .parallelize(1 until n, slices) .map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (n - 1)}") session.stop()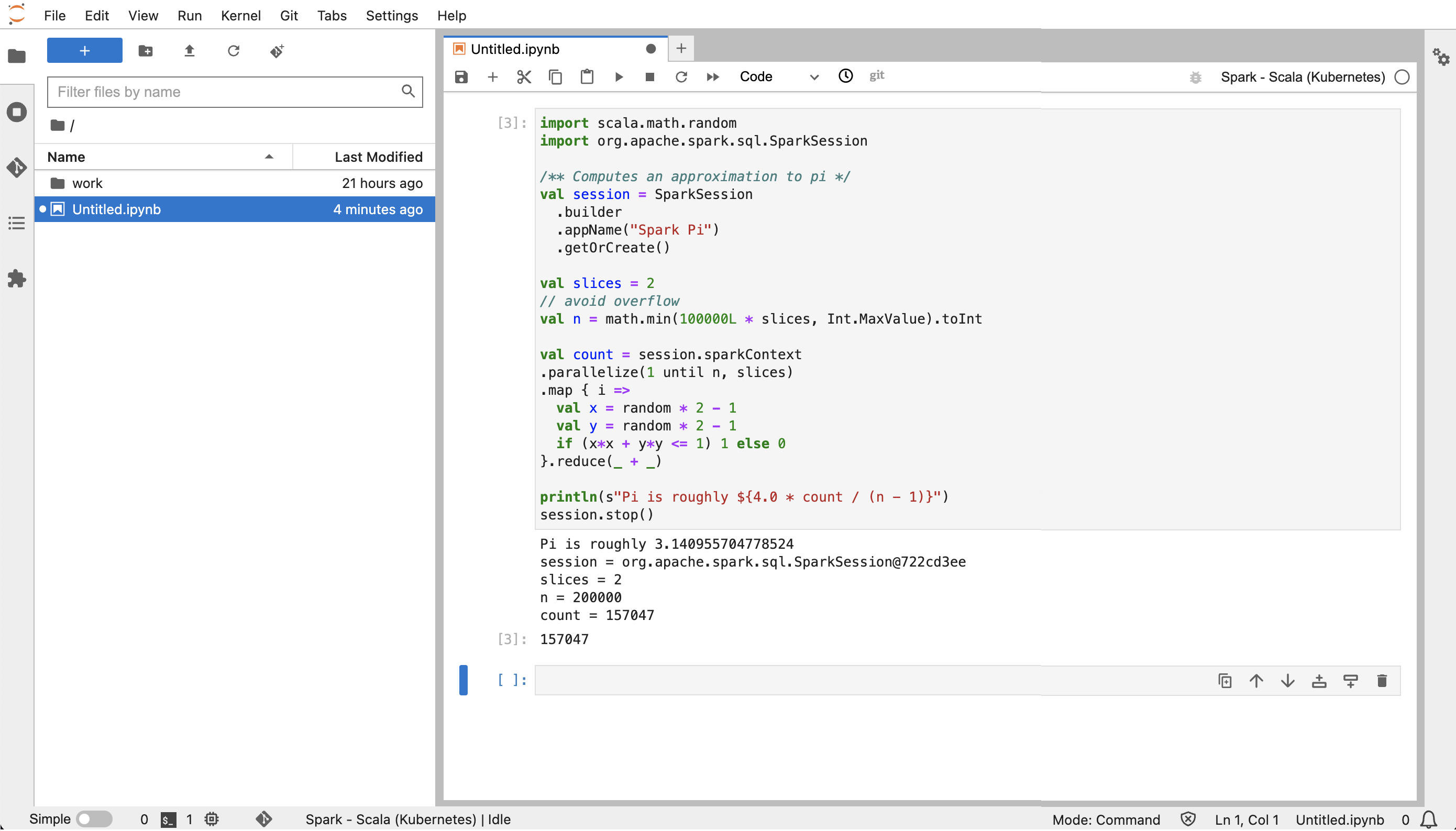
Löschen Sie ein selbst gehostetes Jupyter Notebook
Wenn Sie bereit sind, Ihr selbst gehostetes Notebook zu löschen, können Sie auch den interaktiven Endpunkt und die Sicherheitsgruppe löschen. Führen Sie die Aktionen in der folgenden Reihenfolge aus:
-
Verwenden Sie den folgenden -Befehl, um den
jupyter-notebookPod zu löschen:kubectl delete pod jupyter-notebook -nnamespace -
Löschen Sie dann Ihren interaktiven Endpunkt mit dem
delete-managed-endpoint-Befehl. Schritte zum Löschen eines interaktiven Endpunkts finden Sie unter Löschen eines interaktiven Endpunkts. Zu Beginn befindet sich Ihr Endpunkt im TERMINATING-Status. Sobald alle Ressourcen bereinigt wurden, wechselt er in den TERMINATED-Status. -
Wenn Sie nicht vorhaben, die Notebook-Sicherheitsgruppe, in der Sie Eine Sicherheitsgruppe erstellen erstellt haben, für andere Jupyter-Notebook-Bereitstellungen zu verwenden, können Sie sie löschen. Weitere Informationen finden Sie unter Löschen einer Sicherheitsgruppe im Amazon-EC2-Benutzerhandbuch.
