Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von EMR Serverless mitAWS Lake Formationfür eine differenzierte Zugriffskontrolle
-Übersicht
Mit den Amazon EMR-Versionen 7.2.0 und höher können AWS Lake Formation Sie detaillierte Zugriffskontrollen auf Datenkatalogtabellen anwenden, die von S3 unterstützt werden. Mit dieser Funktion können Sie Zugriffskontrollen auf Tabellen-, Zeilen-, Spalten- und Zellenebene für read Abfragen innerhalb Ihrer Amazon EMR Serverless Spark-Jobs konfigurieren. Verwenden Sie EMR Studio, um eine detaillierte Zugriffskontrolle für Apache Spark-Batchjobs und interaktive Sitzungen zu konfigurieren. In den folgenden Abschnitten erfahren Sie mehr über Lake Formation und dessen Verwendung mit EMR Serverless.
Für die Nutzung von Amazon EMR Serverless mit AWS Lake Formation fallen zusätzliche Gebühren an. Weitere Informationen finden Sie unter Amazon EMR-Preise
So funktioniert EMR Serverless mitAWS Lake Formation
Wenn Sie EMR Serverless mit Lake Formation verwenden, können Sie für jeden Spark-Job eine Berechtigungsebene erzwingen, um die Lake Formation Formation-Berechtigungssteuerung anzuwenden, wenn EMR Serverless Jobs ausführt. EMR Serverless verwendet Spark-Ressourcenprofile, um zwei Profile
Wenn Sie vorinitialisierte Kapazität mit Lake Formation verwenden, empfehlen wir, mindestens zwei Spark-Treiber zu verwenden. Jeder Formation-enabled Lake-Job verwendet zwei Spark-Treiber, einen für das Benutzerprofil und einen für das Systemprofil. Die beste Leistung erzielen Sie, wenn Sie für Formation-enabled Lake-Jobs die doppelte Anzahl von Treibern verwenden, als wenn Sie Lake Formation nicht verwenden.
Wenn Sie Spark-Jobs auf EMR Serverless ausführen, sollten Sie auch die Auswirkungen der dynamischen Zuweisung auf das Ressourcenmanagement und die Clusterleistung berücksichtigen. Die Konfiguration spark.dynamicAllocation.maxExecutors der maximalen Anzahl von Executors pro Ressourcenprofil gilt für Benutzer- und System-Executoren. Wenn Sie diese Anzahl so konfigurieren, dass sie der maximal zulässigen Anzahl von Executoren entspricht, kann es sein, dass Ihre Jobausführung aufgrund eines Executortyps, der alle verfügbaren Ressourcen verwendet, blockiert wird, wodurch der andere Executor verhindert wird, wenn Sie Job-Jobs ausführen.
Damit Ihnen nicht die Ressourcen ausgehen, legt EMR Serverless die standardmäßige maximale Anzahl von Executoren pro Ressourcenprofil auf 90% des Werts fest. spark.dynamicAllocation.maxExecutors Sie können diese Konfiguration überschreiben, wenn Sie einen Wert zwischen spark.dynamicAllocation.maxExecutorsRatio 0 und 1 angeben. Konfigurieren Sie außerdem die folgenden Eigenschaften, um die Ressourcenzuweisung und die Gesamtleistung zu optimieren:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
Im Folgenden finden Sie einen allgemeinen Überblick darüber, wie EMR Serverless Zugriff auf Daten erhält, die durch Sicherheitsrichtlinien von Lake Formation geschützt sind.
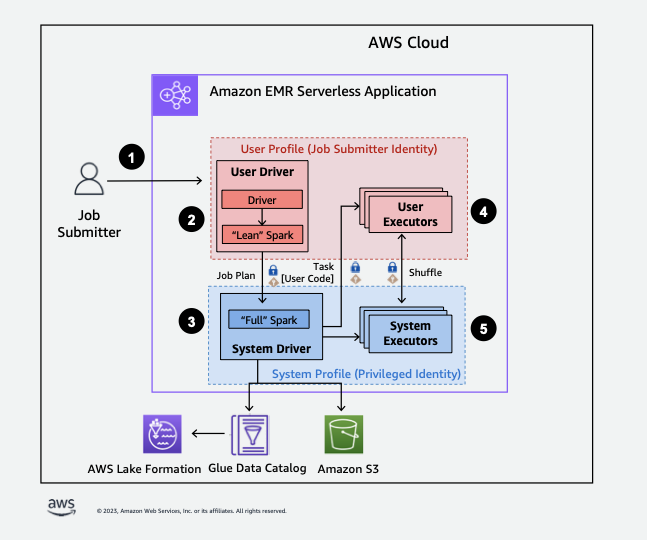
-
Ein Benutzer sendet einen Spark-Job an eine AWS Lake Formation -fähige EMR Serverless-Anwendung.
-
EMR Serverless sendet den Job an einen Benutzertreiber und führt den Job im Benutzerprofil aus. Der Benutzertreiber führt eine schlanke Version von Spark aus, die nicht in der Lage ist, Aufgaben zu starten, Executors anzufordern, auf S3 oder den Glue-Katalog zuzugreifen. Er erstellt einen Auftragsplan.
-
EMR Serverless richtet einen zweiten Treiber ein, den Systemtreiber, und führt ihn im Systemprofil aus (mit einer privilegierten Identität). EMR Serverless richtet einen verschlüsselten TLS-Kanal zwischen den beiden Treibern für die Kommunikation ein. Der Benutzertreiber verwendet den Kanal, um die Auftragspläne an den Systemtreiber zu senden. Der Systemtreiber führt keinen vom Benutzer übermittelten Code aus. Er führt Spark vollständig aus und kommuniziert mit S3 und dem Datenkatalog für den Datenzugriff. Er fordert Executors an und stellt den Auftragsplan in eine Abfolge von Ausführungsphasen zusammen.
-
EMR Serverless führt dann die Stufen auf Executoren mit dem Benutzertreiber oder Systemtreiber aus. Benutzercode wird in jeder Phase ausschließlich auf Benutzerprofil-Executors ausgeführt.
-
Stufen, die Daten aus Datenkatalogtabellen lesen, die durch Sicherheitsfilter geschützt sind AWS Lake Formation oder solche, die Sicherheitsfilter anwenden, werden an System-Executoren delegiert.
Aktivierung der Lake Formation in Amazon EMR
Um Lake Formation zu aktivieren, legen Sie spark.emr-serverless.lakeformation.enabled beim Erstellen einer serverlosen EMR-Anwendung den Wert für den Laufzeitkonfigurationsparameter auf true spark-defaults Unterklassifizierung fest.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
Sie können Lake Formation auch aktivieren, wenn Sie eine neue Anwendung in EMR Studio erstellen. Wählen Sie Lake Formation verwenden für eine detaillierte Zugriffskontrolle aus, die unter Zusätzliche Konfigurationen verfügbar ist.
Inter-worker Die Verschlüsselung ist standardmäßig aktiviert, wenn Sie Lake Formation mit EMR Serverless verwenden, sodass Sie die Interworker-Verschlüsselung nicht erneut explizit aktivieren müssen.
Aktivierung von Lake Formation für Spark-Jobs
Um Lake Formation für einzelne Spark-Jobs spark.emr-serverless.lakeformation.enabled zu aktivieren, setzen Sie ihn bei der Verwendung auf truespark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
IAM-Berechtigungen für die Auftrag-Laufzeitrolle
Lake Formation Formation-Berechtigungen kontrollieren den Zugriff auf AWS Glue Data Catalog-Ressourcen, Amazon S3 S3-Standorte und die zugrunde liegenden Daten an diesen Standorten. IAM-Berechtigungen steuern den Zugriff auf die APIs und AWS-Ressourcen von Lake Formation und Glue. Obwohl Sie möglicherweise über die Lake-Formation-Berechtigung verfügen, auf eine Tabelle im Datenkatalog (SELECT) zuzugreifen, schlägt Ihr Vorgang fehl, wenn Sie nicht über die IAM-Berechtigung für den glue:Get*-API-Vorgang verfügen.
Die folgende Beispielrichtlinie beschreibt, wie Sie IAM-Berechtigungen für den Zugriff auf ein Skript in S3, das Hochladen von Protokollen in S3, API-Berechtigungen für AWS Glue und die Berechtigung für den Zugriff auf Lake Formation erteilen.
Lake-Formation-Berechtigungen für die Auftrag-Laufzeitrolle einrichten
Registrieren Sie zunächst den Speicherort Ihrer Hive-Tabelle bei Lake Formation. Erstellen Sie anschließend Berechtigungen für Ihre Auftrag-Laufzeitrolle für die gewünschte Tabelle. Weitere Informationen zu Lake Formation finden Sie unter Was istAWS Lake Formation? im AWS Lake FormationEntwicklerhandbuch.
Nachdem Sie die Lake Formation Formation-Berechtigungen eingerichtet haben, reichen Sie Spark-Jobs auf Amazon EMR Serverless ein. Weitere Informationen zu Spark-Jobs finden Sie in den Spark-Beispielen.
Senden einer Auftragsausführung
Nachdem Sie die Lake Formation Grants eingerichtet haben, können Sie Spark-Jobs auf EMR Serverless einreichen. Der folgende Abschnitt enthält Beispiele für die Konfiguration und Übermittlung der Eigenschaften für die Ausführung von Jobs.
Benötigte Berechtigungen
Tabellen, die nicht registriert sind inAWS Lake Formation
Bei TabellenAWS Lake Formation, bei denen nicht registriert ist, greift die Job-Runtime-Rolle sowohl auf den AWS Glue-Datenkatalog als auch auf die zugrunde liegenden Tabellendaten in Amazon S3 zu. Dazu muss die Job-Runtime-Rolle über die entsprechenden IAM-Berechtigungen sowohl für AWS Glue- als auch für Amazon S3 S3-Operationen verfügen.
Tabellen sind registriert inAWS Lake Formation
Bei TabellenAWS Lake Formation, bei denen registriert ist, greift die Job-Runtime-Rolle auf die Metadaten des AWS Glue-Datenkatalogs zu, während temporäre Anmeldeinformationen, die von Lake Formation bereitgestellt wurden, auf die zugrunde liegenden Tabellendaten in Amazon S3 zugreifen. Die Lake Formation Formation-Berechtigungen, die zur Ausführung eines Vorgangs erforderlich sind, hängen vom AWS Glue Data Catalog und den Amazon S3 S3-API-Aufrufen ab, die der Spark-Job initiiert, und lassen sich wie folgt zusammenfassen:
-
Die DESCRIBE-Berechtigung ermöglicht es der Runtime-Rolle, Tabellen- oder Datenbankmetadaten im Datenkatalog zu lesen
-
Die ALTER-Berechtigung ermöglicht der Runtime-Rolle, Tabellen- oder Datenbankmetadaten im Datenkatalog zu ändern
-
Die DROP-Berechtigung ermöglicht der Runtime-Rolle, Tabellen- oder Datenbankmetadaten aus dem Datenkatalog zu löschen
-
Die SELECT-Berechtigung ermöglicht es der Runtime-Rolle, Tabellendaten aus Amazon S3 zu lesen
-
Die INSERT-Berechtigung ermöglicht es der Runtime-Rolle, Tabellendaten in Amazon S3 zu schreiben
-
Die DELETE-Berechtigung ermöglicht es der Runtime-Rolle, Tabellendaten aus Amazon S3 zu löschen
Anmerkung
Lake Formation wertet Berechtigungen träge aus, wenn ein Spark-Job AWS Glue zum Abrufen von Tabellenmetadaten und Amazon S3 zum Abrufen von Tabellendaten aufruft. Jobs, die eine Runtime-Rolle mit unzureichenden Berechtigungen verwenden, schlagen erst fehl, wenn Spark einen AWS Glue- oder Amazon S3-Aufruf tätigt, für den die fehlende Berechtigung erforderlich ist.
Anmerkung
In der folgenden unterstützten Tabellenmatrix:
-
Als Unterstützt markierte Operationen verwenden ausschließlich Lake Formation-Anmeldeinformationen, um auf Tabellendaten für Tabellen zuzugreifen, die bei Lake Formation registriert sind. Wenn die Lake Formation Formation-Berechtigungen nicht ausreichen, greift der Vorgang nicht auf Anmeldeinformationen für Runtime-Rollen zurück. Bei Tabellen, die nicht bei Lake Formation registriert sind, greifen die Anmeldeinformationen der Job-Runtime-Rolle auf die Tabellendaten zu.
-
Operationen, die als Unterstützt mit IAM-Berechtigungen am Amazon S3-Standort markiert sind, verwenden keine Lake Formation Formation-Anmeldeinformationen für den Zugriff auf die zugrunde liegenden Tabellendaten in Amazon S3. Um diese Operationen auszuführen, muss die Job-Runtime-Rolle über die erforderlichen Amazon S3 S3-IAM-Berechtigungen für den Zugriff auf die Tabellendaten verfügen, unabhängig davon, ob die Tabelle bei Lake Formation registriert ist.
