Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Weitere Informationen zur Zonenverschiebung von Amazon Application Recovery Controller (ARC) in Amazon EKS
Kubernetes verfügt über native Features, mit denen Sie Ihre Anwendungen stabiler gegenüber Ereignissen wie einer verschlechterten Verfügbarkeit oder Beeinträchtigung einer Availability Zone (AZ) machen können. Wenn Sie Ihre Workloads in einem Amazon-EKS-Cluster ausführen, können Sie die Fehlertoleranz und Anwendungswiederherstellung Ihrer Anwendungsumgebung weiter verbessern, indem Sie Amazon Application Recovery Controller (ARC)-Zonenverschiebung oder automatische Zonenverschiebung einsetzen. ARC-Zonenverschiebung ist als vorübergehende Maßnahme konzipiert, mit der Sie den Datenverkehr für eine Ressource aus einer beeinträchtigten AZ verlagern können, bis die Zonenverschiebung abläuft oder Sie sie abbrechen. Bei Bedarf können Sie die Zonenverschiebung verlängern.
Sie können eine Zonenverschiebung für einen EKS-Cluster starten oder Sie können zulassen, dass der Verkehr für Sie AWS verlagert wird, indem Sie Zonal Autoshift aktivieren. Diese Verschiebung aktualisiert den Ost-West-Netzwerkdatenverkehr in Ihrem Cluster, sodass nur Netzwerkendpunkte für Pods berücksichtigt werden, die auf Worker-Knoten in fehlerfreien AZs ausgeführt werden. Darüber hinaus leitet jeder ALB oder NLB, der den eingehenden Datenverkehr für Anwendungen in Ihrem EKS-Cluster verarbeitet, den Datenverkehr automatisch an Ziele in den funktionsfähigen AZs weiter. Für Kunden, die höchste Verfügbarkeit anstreben, kann es im Falle einer Beeinträchtigung einer AZ wichtig sein, den gesamten Datenverkehr von der beeinträchtigten AZ wegleiten zu können, bis diese wiederhergestellt ist. Hierzu können Sie auch einen ALB oder NLB mit ARC-Zonenverschiebung aktivieren.
Verständnis des Ost-West-Netzwerkdatenverkehrs zwischen Pods
Das folgende Diagramm veranschaulicht zwei Beispiel-Workloads: Bestellungen und Produkte. Dieses Beispiel soll verdeutlichen, wie Workloads und Pods in verschiedenen AZs miteinander kommunizieren.
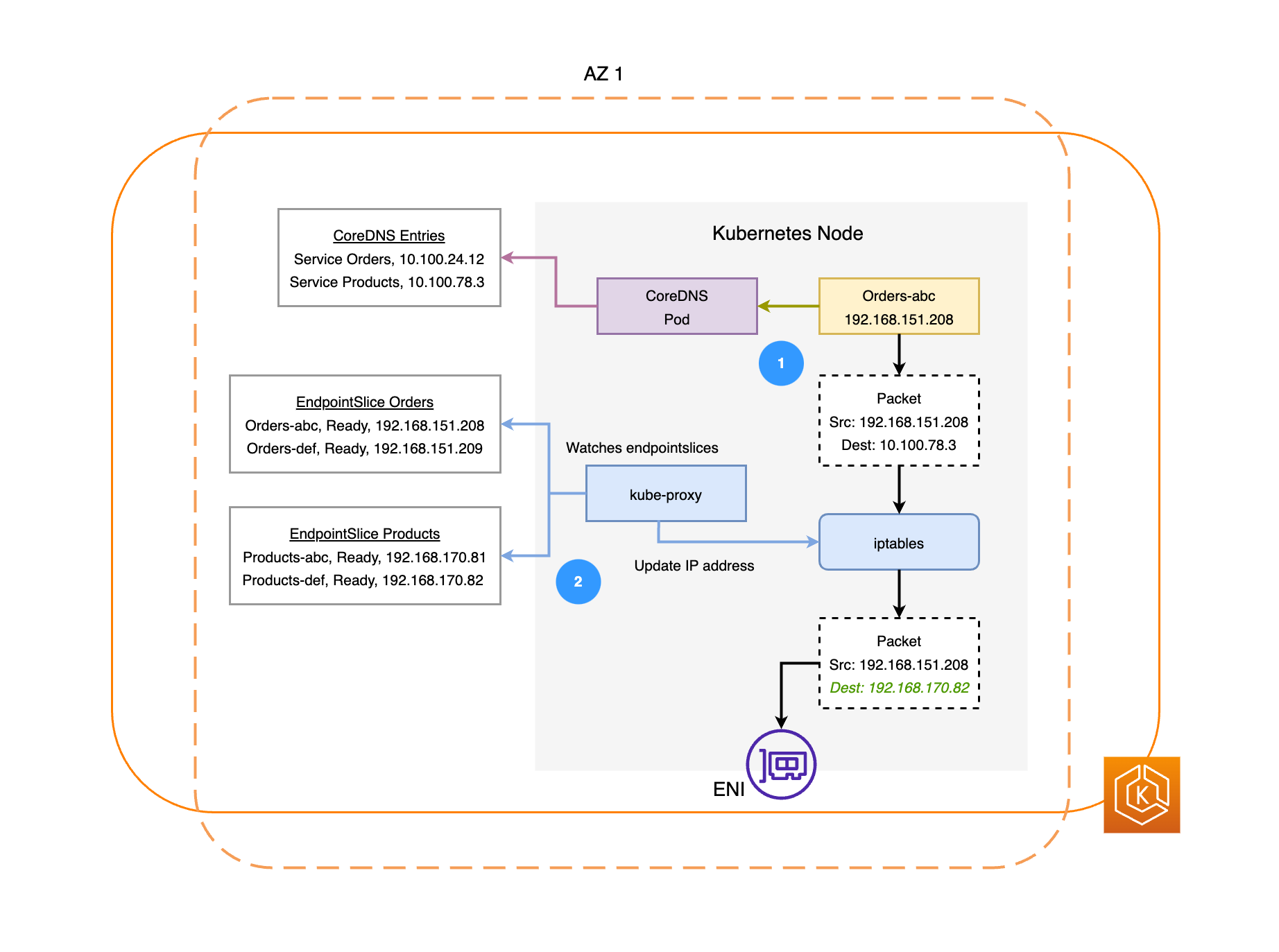
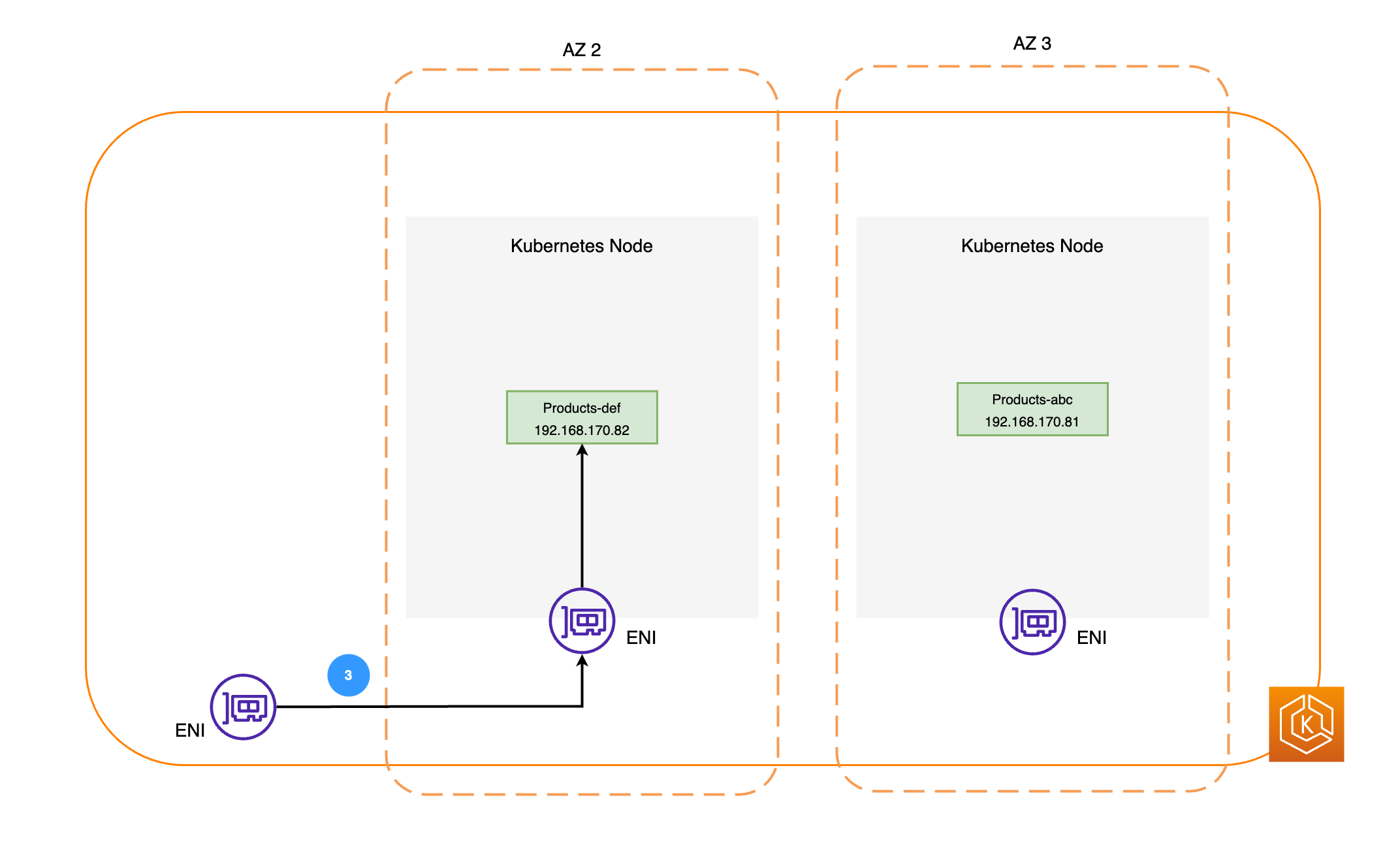
-
Damit Aufträge mit Produkten kommunizieren können, müssen sie zunächst den DNS-Namen des Ziel-Services auflösen. Aufträge kommunizieren mit CoreDNS, um die virtuelle IP-Adresse (Cluster-IP) für diesen Service abzurufen. Nachdem Aufträge den Produktnamen aufgelöst hat, sendet es Datenverkehr an diese Ziel-IP-Adresse.
-
Der Kube-Proxy läuft auf jedem Knoten im Cluster und sucht kontinuierlich nach Diensten. EndpointSlices
Wenn ein Dienst erstellt wird, EndpointSlice wird ein Dienst im Hintergrund vom Controller erstellt und verwaltet. EndpointSlice Jeder EndpointSlice hat eine Liste oder Tabelle mit Endpunkten, die eine Teilmenge von Pod-Adressen sowie die Knoten enthält, auf denen sie ausgeführt werden. Der Kube-Proxy richtet mithilfe von iptablesauf den Knoten Routing-Regeln für jeden dieser Pod-Endpunkte ein. Der Kube-Proxy ist auch für eine grundlegende Form des Lastausgleichs zuständig, indem er den für die Cluster-IP-Adresse eines Services bestimmten Datenverkehr umleitet, sodass dieser stattdessen direkt an die IP-Adresse eines Pods gesendet wird. Der kube-proxy erreicht dies, indem er die Ziel-IP-Adresse der ausgehenden Verbindung umschreibt. -
Die Netzwerkpakete werden dann mithilfe der ENIs auf den jeweiligen Knoten an den Produkt-Pod in AZ 2 gesendet, wie im vorherigen Diagramm dargestellt.
Verständnis der ARC-Zonenverschiebung in Amazon EKS
Sollte in Ihrer Umgebung eine AZ-Beeinträchtigung vorliegen, können Sie eine Zonenverschiebung für Ihre EKS-Cluster-Umgebung initiieren. Alternativ können AWS Sie den wechselnden Verkehr mit zonaler Autoshift für Sie verwalten lassen. Mit Zonal Autoshift wird der gesamte Zustand der AZ AWS überwacht und auf eine mögliche Beeinträchtigung der AZ reagiert, indem der Verkehr in Ihrer Cluster-Umgebung automatisch von der beeinträchtigten AZ weggeleitet wird.
Nachdem Ihr Amazon EKS-Cluster Zonal Shift mit ARC aktiviert hat, können Sie eine Zonal Shift starten oder Zonal Autoshift aktivieren, indem Sie die ARC-Konsole, die AWS CLI oder die Zonal Shift- und Zonal Autoshift-APIs verwenden. Während einer EKS-Zonenverschiebung wird Folgendes automatisch durchgeführt:
-
Alle Knoten in der betroffenen AZ werden gesperrt. Dadurch wird verhindert, dass der Kubernetes-Scheduler neue Pods auf Knoten in der fehlerhaften AZ plant.
-
Wenn Sie verwaltete Knotengruppen verwenden, wird die Neugewichtung der Availability Zone ausgesetzt und Ihre Auto-Scaling-Gruppe aktualisiert, um sicherzustellen, dass neue EKS-Datenebenen-Knoten nur in fehlerfreien AZs gestartet werden.
-
Die Knoten in der fehlerhaften AZ werden nicht beendet und Pods werden nicht aus den Knoten entfernt. Dadurch wird sichergestellt, dass Ihr Datenverkehr nach Ablauf oder Aufhebung einer Zonenverschiebung sicher in die AZ zurückgeführt werden kann, um die volle Kapazität wiederherzustellen.
-
Der EndpointSlice Controller findet alle Pod-Endpunkte in der beeinträchtigten AZ und entfernt sie aus den entsprechenden. EndpointSlices Dadurch wird sichergestellt, dass nur Pod-Endpunkte in intakten AZs für den Empfang von Netzwerkverkehr vorgesehen sind. Wenn eine Zonenverschiebung storniert wird oder abläuft, aktualisiert der EndpointSlice Controller sie so, EndpointSlices dass die Endpunkte in der wiederhergestellten AZ enthalten sind.
Die folgenden Diagramme bieten einen allgemeinen Überblick darüber, wie die EKS-Zonenverschiebung sicherstellt, dass nur fehlerfreie Pod-Endpunkte in Ihrer Cluster-Umgebung angesteuert werden.
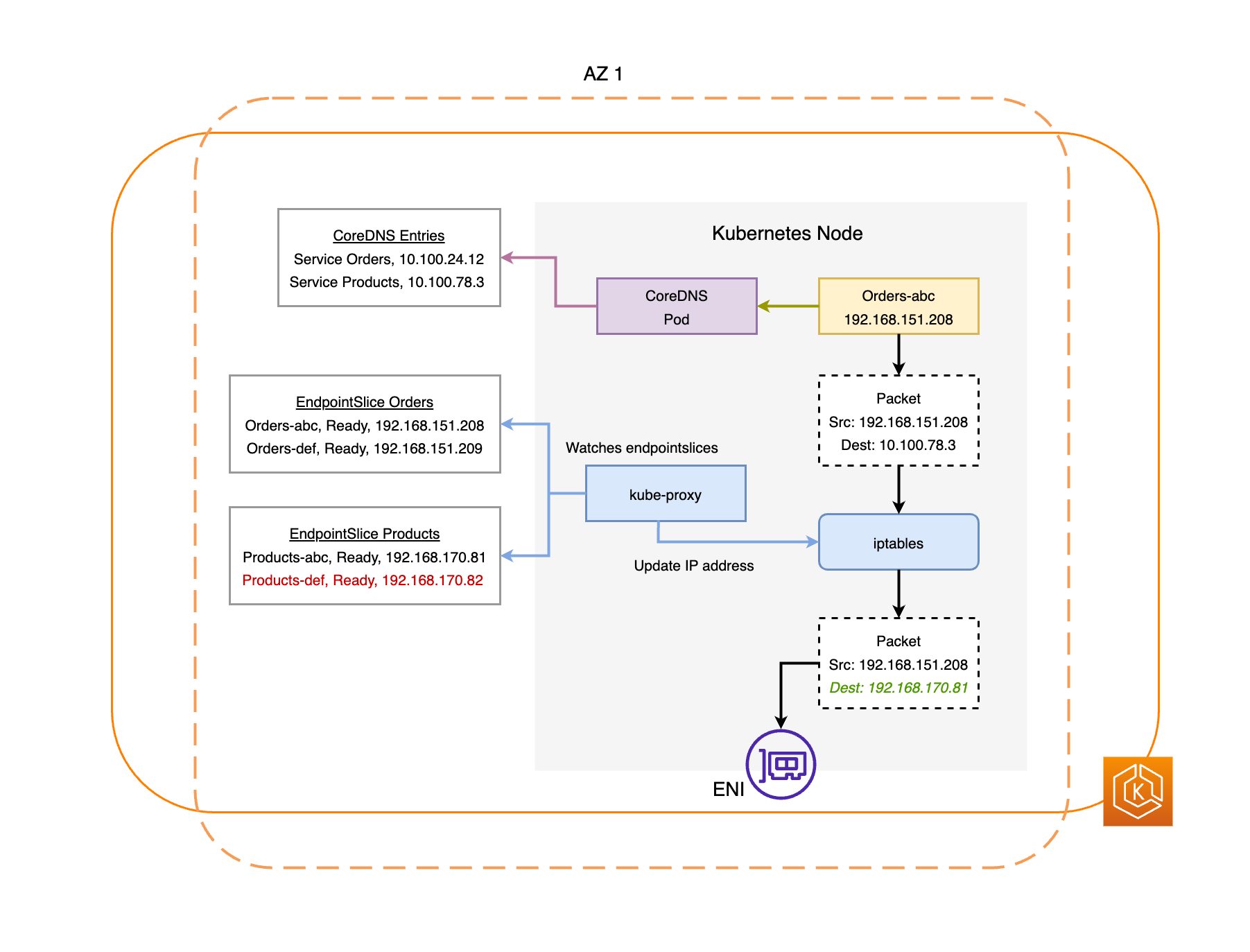
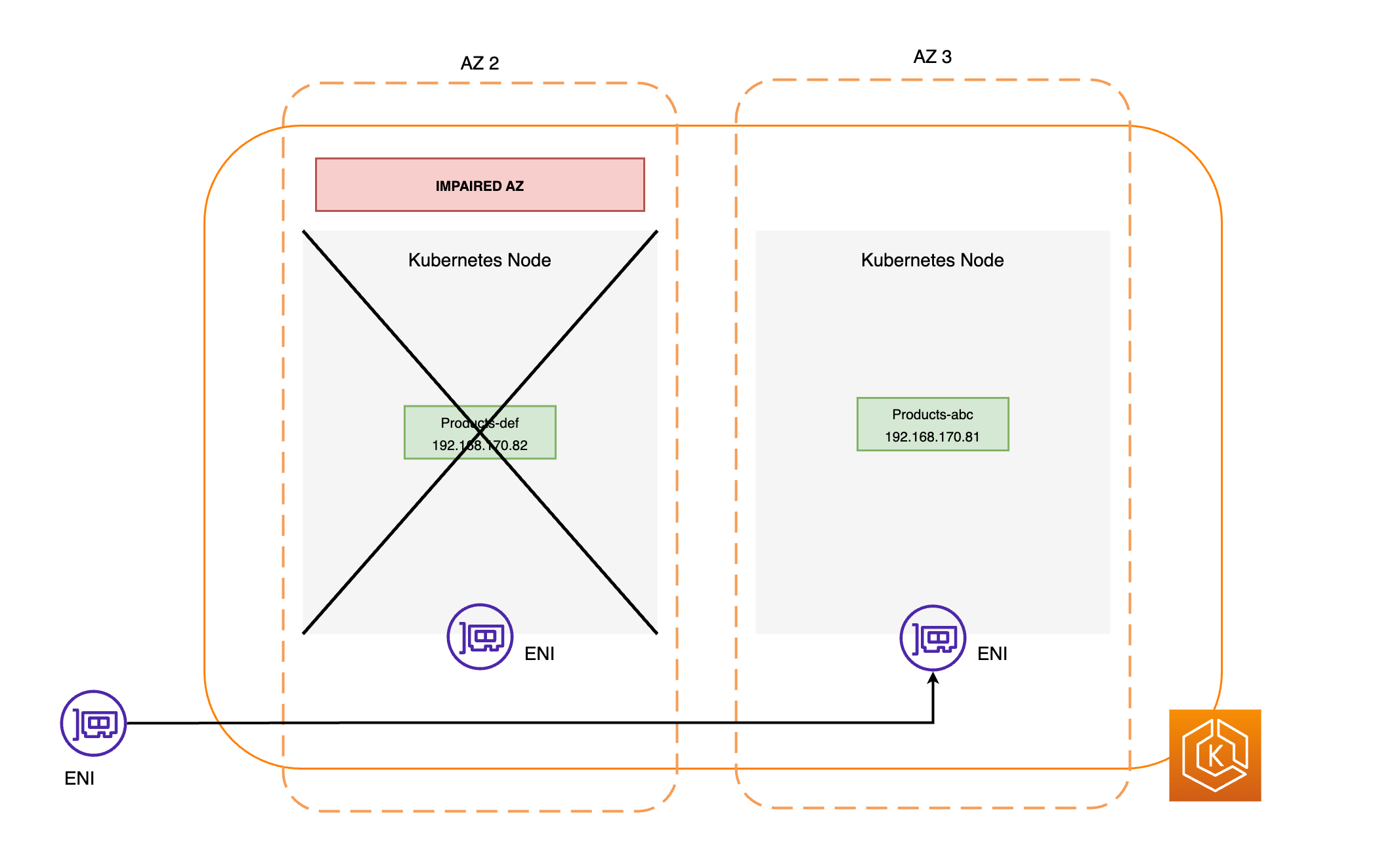
Anforderungen der EKS-Zonenverschiebung
Damit die Zonenverschiebung mit EKS erfolgreich funktioniert, müssen Sie Ihre Cluster-Umgebung im Voraus so einrichten, dass sie gegenüber einer AZ-Beeinträchtigung widerstandsfähig ist. Nachfolgend finden Sie eine Liste mit Konfigurationsoptionen, die zur Gewährleistung der Ausfallsicherheit beitragen.
-
Bereitstellung der Worker-Knoten Ihres Clusters über mehrere AZs hinweg
-
Bereitstellung von ausreichend Rechenkapazität, um den Ausfall einer einzelnen AZ zu kompensieren
-
Pre-scale deine Pods, einschließlich CoreDNS, in jeder AZ
-
Verteilung mehrerer Pod-Replikate auf alle AZs, um sicherzustellen, dass Sie auch bei einer Verlagerung aus einer einzelnen AZ weiterhin über ausreichende Kapazitäten verfügen
-
Co-Location von voneinander abhängigen oder verwandten Pods in derselben AZ
-
Testen Sie, ob Ihre Cluster-Umgebung ohne eine AZ wie erwartet funktioniert, indem Sie manuell eine Zonenverschiebung weg von einer AZ starten. Alternativ können Sie die automatische Zonenverschiebung aktivieren und sich auf Testläufe der automatischen Verschiebung verlassen. Tests mit manuellen oder praktischen Zonenverschiebungen sind für die Funktion der Zonenverschiebung in EKS nicht erforderlich, werden aber dringend empfohlen.
Bereitstellung Ihrer EKS-Worker-Knoten über mehrere Availability Zones hinweg
AWS Regionen haben mehrere, separate Standorte mit physischen Rechenzentren, die als Availability Zones (AZs) bezeichnet werden. AZs sind physisch voneinander isoliert, um gleichzeitige Auswirkungen zu vermeiden, die eine gesamte Region beeinträchtigen könnten. Bei der Bereitstellung eines EKS-Clusters empfehlen wir, Ihre Worker-Knoten über mehrere AZs in einer Region zu verteilen. Dies trägt dazu bei, Ihre Cluster-Umgebung ausfallsicherer gegenüber Störungen einer einzelnen AZ zu machen. Außerdem können Sie so eine hohe Verfügbarkeit für Ihre Anwendungen gewährleisten, die in den anderen AZs ausgeführt werden. Wenn Sie mit einer Zonenverlagerung weg von der betroffenen AZ beginnen, wird das Cluster-Netzwerk Ihrer EKS-Umgebung automatisch aktualisiert, sodass nur funktionsfähige AZs verwendet werden, um die hohe Verfügbarkeit Ihres Clusters aufrechtzuerhalten.
Die Sicherstellung einer Multi-AZ-Konfiguration für Ihre EKS-Umgebung erhöht die allgemeine Zuverlässigkeit Ihres Systems. Multi-AZ-Umgebungen beeinflussen jedoch die Art und Weise, wie Anwendungsdaten übertragen und verarbeitet werden, was sich wiederum auf die Netzwerkgebühren Ihrer Umgebung auswirkt. Insbesondere häufiger ausgehender zonenübergreifender Datenverkehr (zwischen AZs verteilter Datenverkehr) kann erhebliche Auswirkungen auf Ihre netzwerkbezogenen Kosten haben. Sie können verschiedene Strategien anwenden, um die Menge des zonenübergreifenden Datenverkehrs zwischen Pods in Ihrem EKS-Cluster zu steuern und die damit verbundenen Kosten zu senken. Weitere Informationen zur Optimierung der Netzwerkkosten beim Betrieb hochverfügbarer EKS-Umgebungen finden Sie in diesen Bewährten Methoden
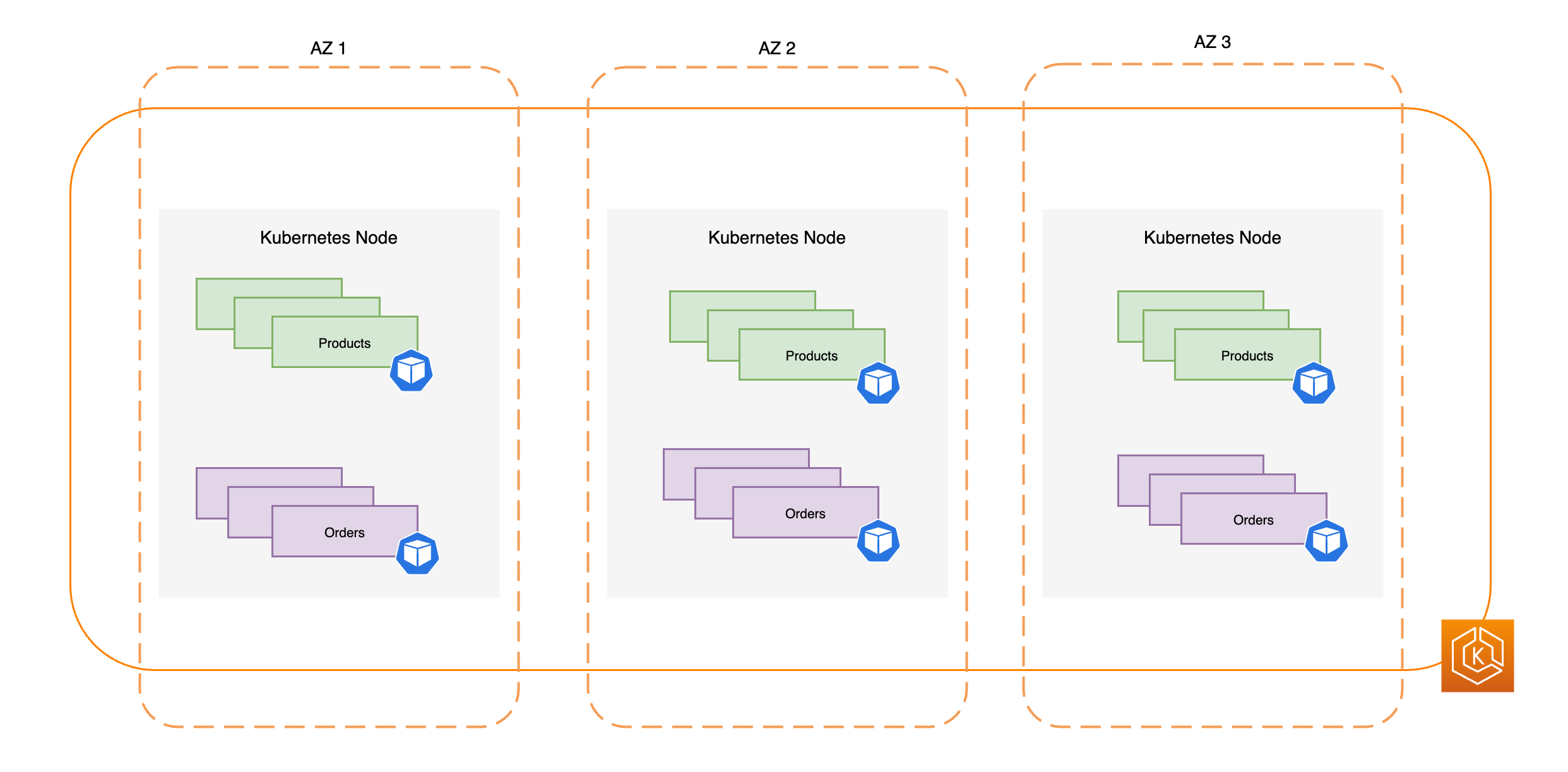
Das folgende Diagramm veranschaulicht eine hochverfügbare EKS-Umgebung mit drei funktionsfähigen AZs.
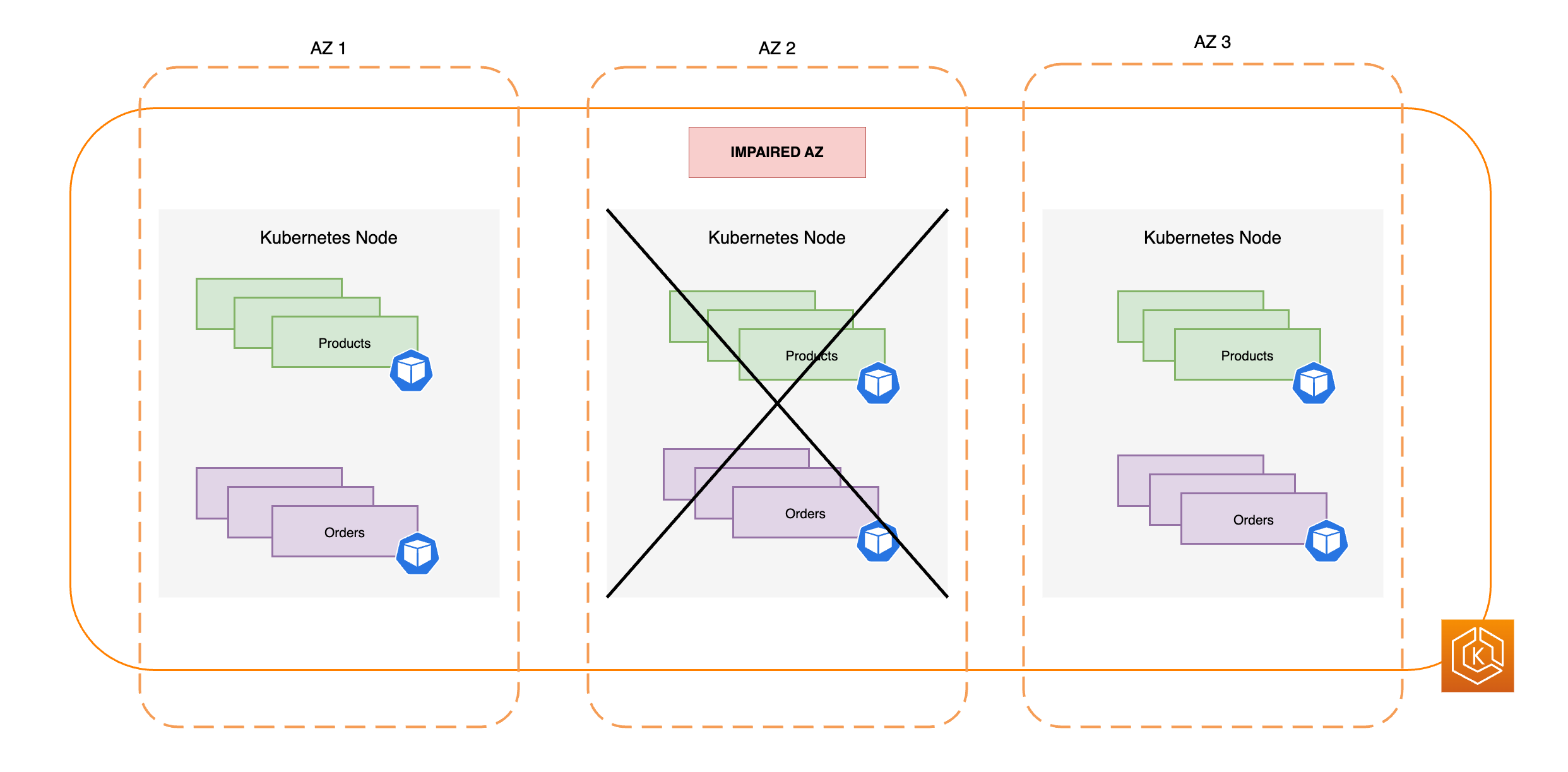
Das folgende Diagramm veranschaulicht, wie eine EKS-Umgebung mit drei AZs gegenüber einer AZ-Beeinträchtigung ausfallsicher ist und hochverfügbar bleibt, da noch zwei fehlerfreie AZs vorhanden sind.
Stellen Sie ausreichend Rechenkapazität bereit, um den Ausfall einer einzelnen Availability Zone zu kompensieren.
Um die Ressourcennutzung und die Kosten für Ihre Recheninfrastruktur in der EKS-Datenebene zu optimieren, empfiehlt es sich, die Rechenkapazität an Ihren Workload-Anforderungen auszurichten. Wenn jedoch alle Ihre Worker-Knoten voll ausgelastet sind, sind Sie darauf angewiesen, dass neue Worker-Knoten zur EKS-Datenebene hinzugefügt werden, bevor neue Pods geplant werden können. Wenn Sie wichtige Workloads ausführen, empfiehlt es sich im Allgemeinen, redundante Kapazitäten online zu betreiben, um Szenarien wie plötzliche Lastanstiege und Probleme mit der Knotenintegrität zu bewältigen. Wenn Sie eine Zonenverschiebung planen, beabsichtigen Sie, bei einer Wertminderung die gesamte Kapazität einer AZ zu entfernen. Dies bedeutet, dass Sie Ihre redundante Rechenkapazität so anpassen müssen, dass sie auch dann noch ausreicht, um die Last zu bewältigen, wenn eine der AZs offline ist.
Wenn Sie Ihre Rechenressourcen skalieren, dauert der Vorgang des Hinzufügens neuer Knoten zur EKS-Datenebene einige Zeit. Dies kann Auswirkungen auf die Echtzeitleistung und Verfügbarkeit Ihrer Anwendungen haben, insbesondere im Falle einer Beeinträchtigung der Zone. Ihre EKS-Umgebung sollte in der Lage sein, den Ausfall einer AZ zu kompensieren, ohne dass dies zu einer Beeinträchtigung der Benutzererfahrung für Ihre Endbenutzer oder Clients führt. Das heißt, die Verzögerung zwischen dem Zeitpunkt, zu dem ein neuer Pod benötigt wird, und dem Zeitpunkt, zu dem er tatsächlich auf einem Worker-Knoten geplant wird, sollte minimiert oder ganz vermieden werden.
Darüber hinaus sollten Sie bei einer Beeinträchtigung der Zone darauf abzielen, das Risiko einer Einschränkung der Rechenkapazität zu minimieren, die verhindern würde, dass neu benötigte Knoten zu Ihrer EKS-Datenebene in den funktionsfähigen AZs hinzugefügt werden können.
Um das Risiko dieser potenziellen negativen Auswirkungen zu verringern, empfehlen wir, in einigen Worker-Knoten in den einzelnen AZs Rechenkapazität zu hoch bereitzustellen. Dadurch steht dem Kubernetes Scheduler bereits vorhandene Kapazität für neue Pod-Platzierungen zur Verfügung. Dies ist besonders wichtig, wenn eine der AZs in Ihrer Umgebung verloren geht.
Ausführung und Verteilung mehrerer Pod-Replikate über Availability Zones hinweg
Mit Kubernetes können Sie Ihre Workloads vorab skalieren, indem Sie mehrere Instances (Pod-Replikate) einer einzelnen Anwendung ausführen. Durch die Ausführung mehrerer Pod-Replikate für eine Anwendung werden einzelne Fehlerquellen beseitigt und die Gesamtleistung gesteigert, da die Ressourcenbelastung eines einzelnen Replikats reduziert wird. Um jedoch sowohl eine hohe Verfügbarkeit als auch eine bessere Fehlertoleranz für Ihre Anwendungen zu erreichen, empfehlen wir Ihnen, mehrere Replikate Ihrer Anwendung auszuführen und die Replikate auf verschiedene Ausfall-Domains (auch Topologie-Domains genannt) zu verteilen. Die Ausfall-Domains in diesem Szenario sind die Availability Zones. Durch die Verwendung von Topologie-Verteilungsbeschränkungen
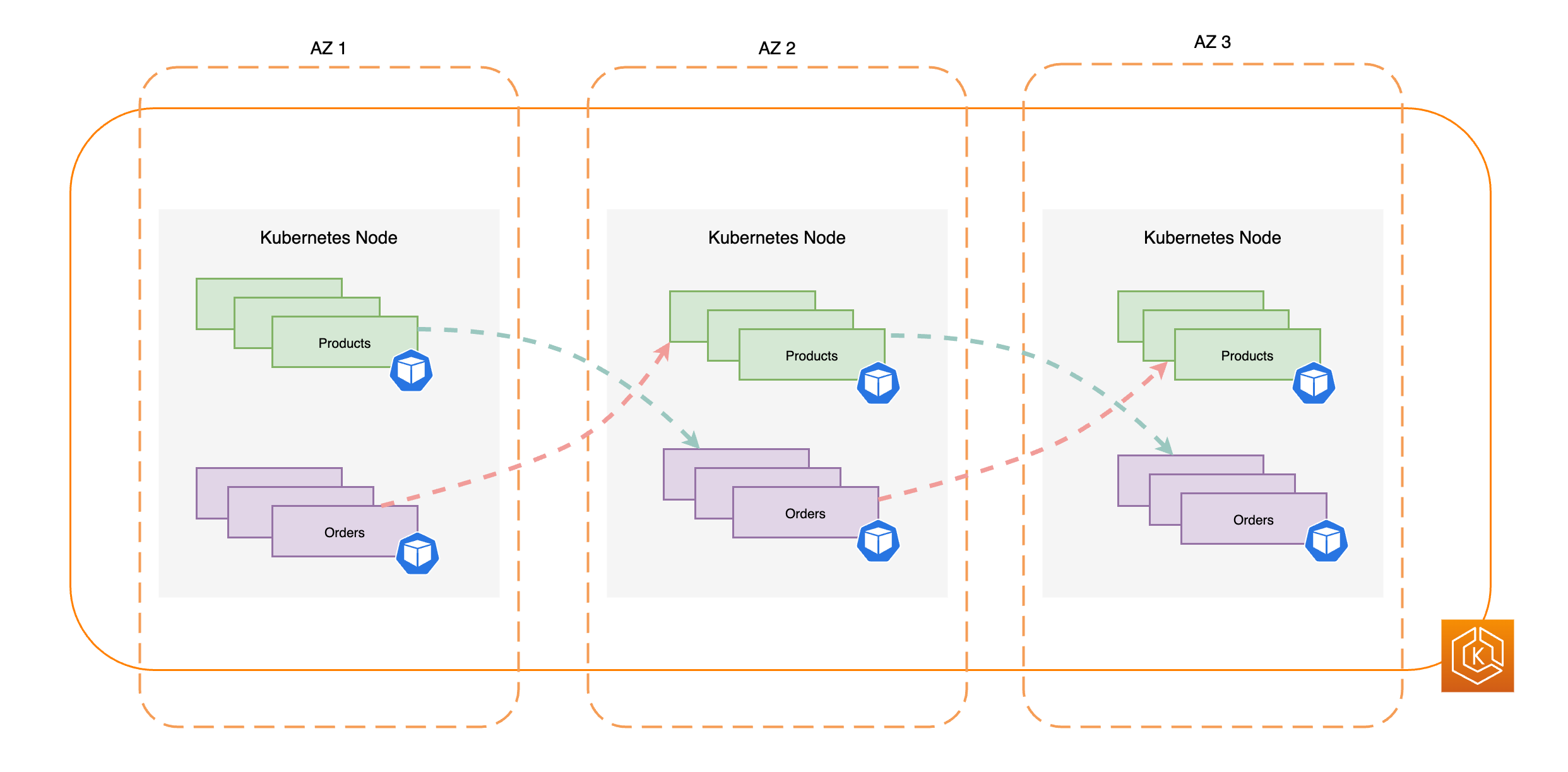
Das folgende Diagramm veranschaulicht eine EKS-Umgebung mit Ost-West-Datenverkehr, wenn alle AZs fehlerfrei funktionieren.
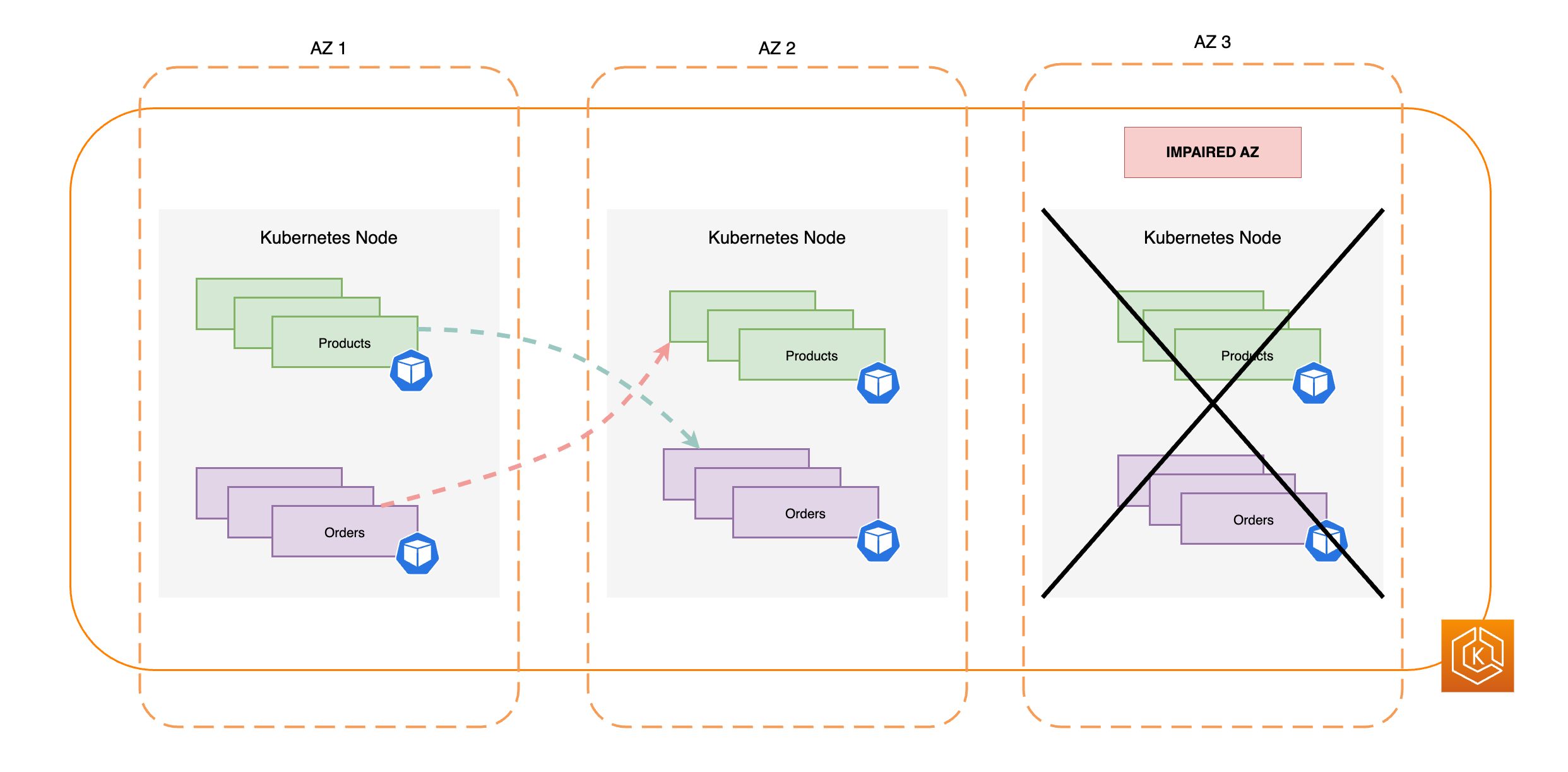
Das folgende Diagramm veranschaulicht eine EKS-Umgebung mit Ost-West-Datenverkehr, in der eine einzelne AZ ausgefallen ist und Sie eine Zonenverschiebung gestartet haben.
Der folgende Code-Ausschnitt ist ein Beispiel dafür, wie Sie Ihre Workload mit mehreren Replikaten in Kubernetes einrichten können.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Am wichtigsten ist, dass Sie mehrere Replikate Ihrer DNS-Serversoftware (CoreDNS/kube-dns) ausführen und ähnliche Beschränkungen für die Topologieverteilung anwenden sollten, sofern diese nicht standardmäßig konfiguriert sind. Dadurch wird sichergestellt, dass Sie bei einer einzelnen AZ-Beeinträchtigung über genügend DNS-Pods in funktionsfähigen AZs verfügen, um weiterhin Anfragen zur Serviceerkennung für andere kommunizierende Pods im Cluster zu bearbeiten. Das CoreDNS-EKS-Add-On verfügt über Standardeinstellungen für die CoreDNS-Pods, die sicherstellen, dass verfügbare Knoten in mehreren AZs über die Availability Zones Ihres Clusters verteilt werden. Falls gewünscht, können Sie diese Standardeinstellungen durch Ihre eigenen benutzerdefinierten Konfigurationen ersetzen.
Wenn Sie CoreDNS mit HelmreplicaCount in der Datei values.yamltopologySpreadConstraints-Eigenschaft in derselben values.yaml-Datei aktualisieren. Der folgende Code-Ausschnitt veranschaulicht, wie Sie CoreDNS entsprechend konfigurieren können.
CoreDNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
Bei einer AZ-Beeinträchtigung können Sie die erhöhte Belastung der CoreDNS-Pods durch den Einsatz eines Systems zur automatischen Skalierung für CoreDNS abfedern. Die Anzahl der erforderlichen DNS- Instances hängt von der Anzahl der in Ihrem Cluster ausgeführten Workloads ab. CoreDNS ist CPU-gebunden, wodurch es mithilfe des Horizontal Pod Autoscaler (HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
Alternativ kann EKS die automatische Skalierung der CoreDNS-Bereitstellung in der EKS-Add-On-Version von CoreDNS verwalten. Dieser CoreDNS-Autoscaler überwacht kontinuierlich den Status des Clusters, einschließlich der Anzahl der Knoten und CPU-Kerne. Basierend auf diesen Informationen passt der Controller die Anzahl der Replikate der CoreDNS-Bereitstellung in einem EKS-Cluster dynamisch an.
Um die Konfiguration für die automatische Skalierung im CoreDNS-EKS-Add-On zu aktivieren, verwenden Sie die folgende Konfigurationseinstellung:
{ "autoScaling": { "enabled": true } }
Sie können auch NodeLocal DNS
Co-Location voneinander abhängiger Pods in derselben Availability Zone
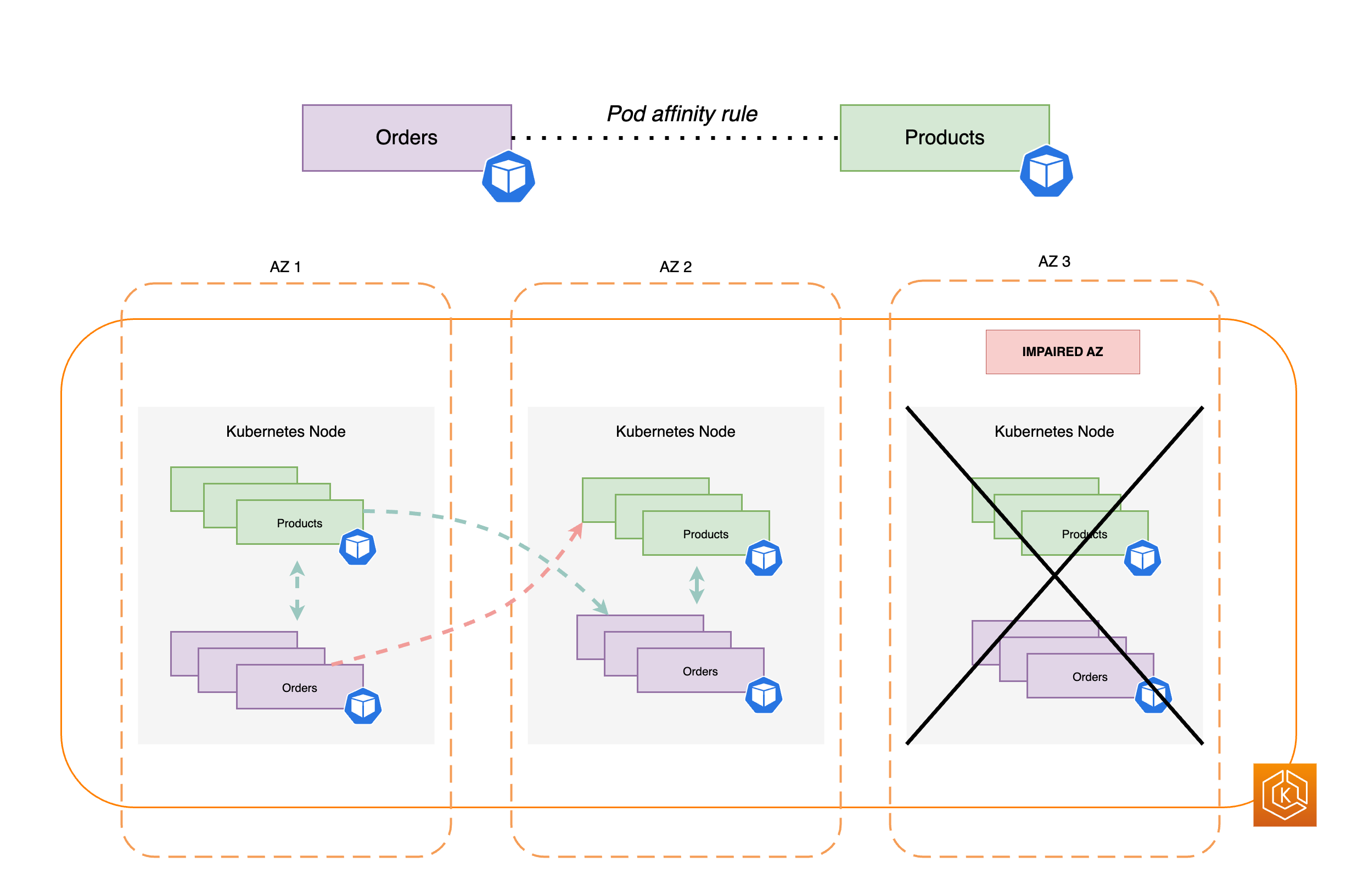
Normalerweise verfügen Anwendungen über unterschiedliche Workloads, die miteinander kommunizieren müssen, um einen durchgängigen Prozess erfolgreich abzuschließen. Wenn diese unterschiedlichen Anwendungen über verschiedene AZs verteilt sind und sich nicht in derselben AZ befinden, kann eine einzelne AZ-Beeinträchtigung den End-to-End-Prozess beeinträchtigen. Wenn beispielsweise Anwendung A mehrere Replikate in AZ 1 und AZ 2 hat, Anwendung B jedoch alle Replikate in AZ 3, wirkt sich der Verlust von AZ 3 auf die durchgängigen Prozesse zwischen den beiden Workloads, Anwendung A und Anwendung B, aus. Wenn Sie Einschränkungen der Topologieverteilung mit Pod-Affinität kombinieren, können Sie die Ausfallsicherheit Ihrer Anwendung verbessern, indem Sie Pods über alle AZs verteilen. Darüber hinaus wird dadurch eine Beziehung zwischen bestimmten Pods konfiguriert, um sicherzustellen, dass sie zusammen platziert sind.
Mit Pod-Affinitätsregeln
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Das folgende Diagramm zeigt mehrere Pods, die mithilfe von Pod-Affinitätsregeln auf demselben Knoten zusammen platziert wurden.
Testen Ihrer Cluster-Umgebung für die Bewältigung eines Ausfalls einer AZ
Nachdem Sie die in den vorherigen Abschnitten beschriebenen Anforderungen erfüllt haben, müssen Sie im nächsten Schritt überprüfen, ob Sie über ausreichende Rechen- und Workload-Kapazitäten verfügen, um den Ausfall einer AZ zu bewältigen. Dazu können Sie manuell eine Zonenverschiebung in EKS starten. Alternativ können Sie die automatische Zonenverschiebung aktivieren und Testläufe konfigurieren, mit denen ebenfalls überprüft wird, ob Ihre Anwendungen mit einer AZ weniger in Ihrer Cluster-Umgebung wie erwartet funktionieren.
Häufig gestellte Fragen
Warum sollte ich dieses Feature nutzen?
Durch die Verwendung von ARC-Zonenverschiebung oder automatischer Zonenverschiebung in Ihrem EKS-Cluster können Sie die Verfügbarkeit von Kubernetes-Anwendungen besser aufrechterhalten. Dazu wird der schnelle Wiederherstellungsprozess automatisiert, bei dem der Netzwerk-Datenverkehr innerhalb des Clusters von einer beeinträchtigten AZ weg verlagert wird. Mit ARC können Sie langwierige, komplizierte Schritte vermeiden, die bei Störungen in AZs zu einer verlängerten Wiederherstellungszeit führen können
Wie funktioniert diese Funktion mit anderen Diensten? AWS
EKS ist in ARC integriert, das die primäre Schnittstelle für die Durchführung von Wiederherstellungsvorgängen darstellt AWS. Um sicherzustellen, dass der Datenverkehr innerhalb des Clusters ordnungsgemäß von einer beeinträchtigten AZ weggeleitet wird, nimmt EKS Änderungen an der Liste der Netzwerkendpunkte für Pods vor, die in der Kubernetes-Datenebene ausgeführt werden. Wenn Sie Elastic Load Balancing verwenden, um externen Datenverkehr in den Cluster zu leiten, können Sie Ihre Load Balancer bei ARC registrieren und eine Zonenverschiebung auf ihnen starten, um zu verhindern, dass Datenverkehr in die beeinträchtigte AZ gelangt. Die Zonenverschiebung ist auch mit Amazon-EC2-Auto-Scaling-Gruppen kompatibel, die von EKS-verwalteten Knotengruppen erstellt werden. Um zu verhindern, dass eine beeinträchtigte AZ für neue Kubernetes-Pods oder Knoten-Starts verwendet wird, entfernt EKS die beeinträchtigte AZ aus den Auto-Scaling-Gruppen.
Inwiefern unterscheidet sich dieses Feature von den standardmäßigen Kubernetes-Schutzmaßnahmen?
Dieses Feature arbeitet mit mehreren in Kubernetes integrierten Schutzmaßnahmen zusammen, welche die Ausfallsicherheit von Kundenanwendungen verbessern Sie können Pod-Bereitschafts- und Aktivitätsprüfung konfigurieren, die entscheiden, wann ein Pod Datenverkehr aufnehmen soll. Wenn diese Prüfungen fehlschlagen, entfernt Kubernetes diese Pods als Ziele für einen Service, und es wird kein Datenverkehr mehr an den Pod gesendet. Dies ist zwar nützlich, für Kunden ist es jedoch nicht einfach, diese Integritätsprüfungen so zu konfigurieren, dass sie garantiert fehlschlagen, wenn eine AZ beeinträchtigt wird. Feature für die ARC-Zonenverschiebung bietet ein zusätzliches Sicherheitsnetz, mit dem Sie eine beeinträchtigte AZ vollständig isolieren können, wenn der native Schutz von Kubernetes nicht ausreicht. Durch Zonenverschiebung können Sie außerdem auf einfache Weise die Betriebsbereitschaft und Ausfallsicherheit Ihrer Architektur überprüfen.
Kann ich in meinem Namen eine Zonenverschiebung AWS starten?
Ja, wenn Sie eine vollständig automatisierte Nutzung der ARC-Zonenverschiebung wünschen, können Sie die automatische ARC-Zonenverschiebung aktivieren. Mit Zonal Autoshift können Sie sich darauf verlassen, AWS dass Sie den Zustand der AZs für Ihren EKS-Cluster überwachen und automatisch eine Zonenverschiebung starten, wenn eine Beeinträchtigung der AZs festgestellt wird.
Was geschieht, wenn ich dieses Feature verwende und meine Worker-Knoten und Workloads nicht vorab skaliert sind?
Wenn Sie nicht vorab skaliert haben und während einer Zonenverschiebung auf die Bereitstellung zusätzlicher Knoten oder Pods angewiesen sind, riskieren Sie eine verzögerte Wiederherstellung. Das Hinzufügen neuer Knoten zur Kubernetes-Datenebene nimmt einige Zeit in Anspruch, was sich auf die Echtzeitleistung und Verfügbarkeit Ihrer Anwendungen auswirken kann, insbesondere bei einer Beeinträchtigung der Zone. Darüber hinaus kann es im Falle einer Beeinträchtigung der Zone zu einer potenziellen Einschränkung der Rechenkapazität kommen, die das Hinzufügen neu benötigter Knoten zu den funktionsfähigen AZs verhindern könnte.
Wenn Ihre Workloads nicht vorab skaliert und auf alle AZs in Ihrem Cluster verteilt sind, kann eine Beeinträchtigung der Zone die Verfügbarkeit einer Anwendung beeinträchtigen, die nur auf Worker-Knoten in einer betroffenen AZ ausgeführt wird. Um das Risiko eines vollständigen Ausfalls der Verfügbarkeit Ihrer Anwendung zu mindern, verfügt EKS über eine Ausfallsicherung für den Datenverkehr, der an Pod-Endpunkte in einer beeinträchtigten Zone gesendet wird, wenn alle Endpunkte dieser Workload in der nicht funktionsfähigen AZ liegen. Wir empfehlen Ihnen jedoch dringend, Ihre Anwendungen vorab zu skalieren und auf alle AZs zu verteilen, um die Verfügbarkeit im Falle eines Problems mit einer Zone aufrechtzuerhalten.
Wie funktioniert dies, wenn ich eine zustandsbehaftete Anwendung ausführe?
Wenn Sie eine zustandsbehaftete Anwendung ausführen, müssen Sie deren Fehlertoleranz auf der Grundlage Ihres Anwendungsfalls und Ihrer Architektur bewerten. Wenn Sie über eine active/standby Architektur oder ein Muster verfügen, kann es vorkommen, dass sich die aktive Komponente in einer beeinträchtigten AZ befindet. Auf Anwendungsebene kann es zu Problemen mit Ihrer Anwendung kommen, wenn der Standby-Modus nicht aktiviert ist. Es können auch Probleme auftreten, wenn neue Kubernetes-Pods in funktionsfähigen AZs gestartet werden, da diese nicht an die persistenten Volumes gebunden werden können, die der beeinträchtigten AZ zugeordnet sind.
Ist dieses Feature mit Karpenter kompatibel?
Karpenter unterstützt ARC Zonal Shift und Zonal Autoshift in EKS mit Karpenter
Ist dieses Feature mit EKS Fargate kompatibel?
Dieses Feature ist mit EKS Fargate nicht kompatibel. Standardmäßig werden Pods bei Erkennung eines zonenbezogenen Zustandsereignisses durch EKS Fargate vorzugsweise in den anderen AZs ausgeführt.
Wird die von EKS verwaltete Kubernetes- Steuerebene davon betroffen sein?
Nein, standardmäßig führt Amazon EKS die Kubernetes-Steuerebene über mehrere AZs hinweg aus und skaliert sie, um eine hohe Verfügbarkeit zu gewährleisten. Die ARC-Zonenverschiebung und die automatische Zonenverschiebung wirken sich ausschließlich auf die Kubernetes-Datenebene aus.
Sind mit diesem neuen Feature Kosten verbunden?
Sie können ARC-Zonenverschiebung und automatische Zonenverschiebung in Ihrem EKS-Cluster ohne zusätzliche Kosten nutzen. Sie müssen jedoch weiterhin für bereitgestellte Instances bezahlen. Wir empfehlen Ihnen dringend, Ihre Kubernetes-Datenebene vor der Nutzung dieses Features vorab zu skalieren. Sie sollten ein Gleichgewicht zwischen Kosten und Anwendungsverfügbarkeit anstreben.
Weitere Ressourcen
