Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überwachen Sie den Kubernetes-Workload-Traffic mit Container Network Observability
Amazon EKS bietet erweiterte Funktionen zur Netzwerkbeobachtbarkeit, die tiefere Einblicke in Ihre Container-Netzwerkumgebung bieten. Diese Funktionen helfen Ihnen dabei, Ihre Kubernetes-Netzwerklandschaft in besser zu verstehen, zu überwachen und Fehler zu beheben. AWS Dank der verbesserten Beobachtbarkeit von Container-Netzwerken können Sie detaillierte, netzwerkbezogene Metriken für eine bessere proaktive Erkennung von Anomalien im Cluster-Traffic, AZ-übergreifenden Flows und Diensten nutzen. AWS Mithilfe dieser Metriken können Sie die Systemleistung messen und die zugrunde liegenden Metriken mithilfe Ihres bevorzugten Observability-Stacks visualisieren.
Darüber hinaus bietet Amazon EKS jetzt Netzwerküberwachungsvisualisierungen in der AWS Konsole, die die präzise Fehlerbehebung beschleunigen und verbessern und so eine schnellere Ursachenanalyse ermöglichen. Sie können diese visuellen Funktionen auch nutzen, um Top-Talker und Netzwerkflüsse zu identifizieren, die zu erneuten Übertragungen und Timeouts bei der erneuten Übertragung führen, wodurch blinde Flecken bei Vorfällen beseitigt werden.
Diese Funktionen werden von Amazon CloudWatch Network Flow Monitor aktiviert.
Anwendungsfälle
Messen Sie die Netzwerkleistung, um Anomalien zu erkennen
Mehrere Teams verwenden standardmäßig einen Observability-Stack, der es ihnen ermöglicht, die Leistung ihres Systems zu messen, Systemmetriken zu visualisieren und bei Überschreitung eines bestimmten Schwellenwerts alarmiert zu werden. Die Beobachtbarkeit von Containernetzwerken in EKS passt genau darauf an, indem wichtige Systemmetriken offengelegt werden, die Sie auswerten können, um die Beobachtbarkeit der Netzwerkleistung Ihres Systems auf Pod- und Worker-Node-Ebene zu erweitern.
Nutzen Sie Konsolenvisualisierungen für eine genauere Fehlerbehebung
Falls Ihr Überwachungssystem einen Alarm ausgibt, sollten Sie sich auf den Cluster und die Arbeitslast konzentrieren, von denen das Problem herrührt. Um dies zu unterstützen, können Sie Visualisierungen in der EKS-Konsole nutzen, um den Untersuchungsumfang auf Clusterebene einzugrenzen und die Offenlegung der Netzwerkflüsse zu beschleunigen, die für die meisten Neuübertragungen, Zeitüberschreitungen bei der erneuten Übertragung und das übertragene Datenvolumen verantwortlich sind.
Verfolgen Sie Top-Talker in Ihrer Amazon EKS-Umgebung
Viele Teams verwenden EKS als Grundlage für ihre Plattformen und machen es somit zum Mittelpunkt der Netzwerkaktivitäten einer Anwendungsumgebung. Mithilfe der Netzwerküberwachungsfunktionen in dieser Funktion können Sie verfolgen, welche Workloads für den meisten Datenverkehr (gemessen am Datenvolumen) innerhalb des Clusters, über AZs hinweg sowie für den Datenverkehr zu externen Zielen innerhalb AWS (DynamoDB und S3) und außerhalb der AWS Cloud (Internet oder lokal) verantwortlich sind. Darüber hinaus können Sie die Leistung jedes dieser Datenflüsse anhand von Neuübertragungen, Zeitüberschreitungen bei der erneuten Übertragung und übertragenen Daten überwachen.
Features
-
Leistungsmetriken — Mit dieser Funktion können Sie netzwerkbezogene Systemmetriken für Pods und Worker-Knoten direkt aus dem Network Flow Monitor (NFM) -Agenten abrufen, der in Ihrem EKS-Cluster ausgeführt wird.
-
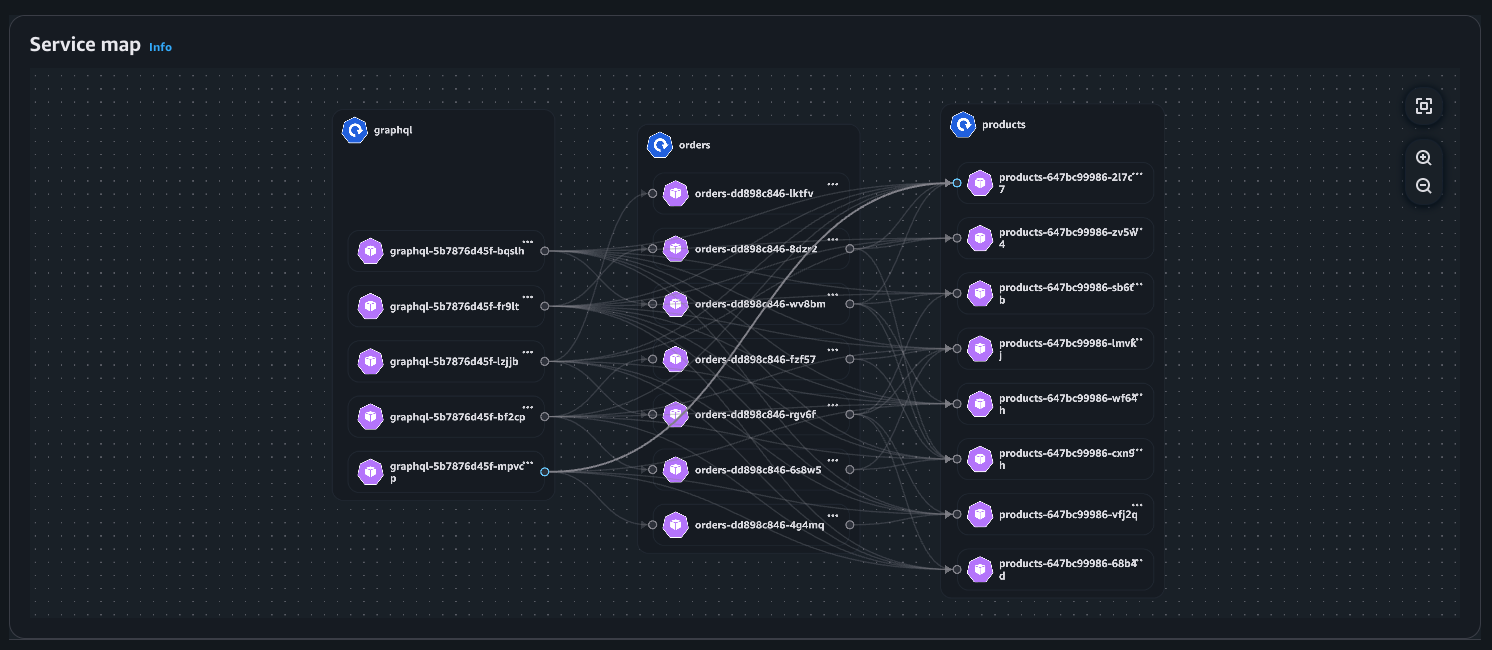
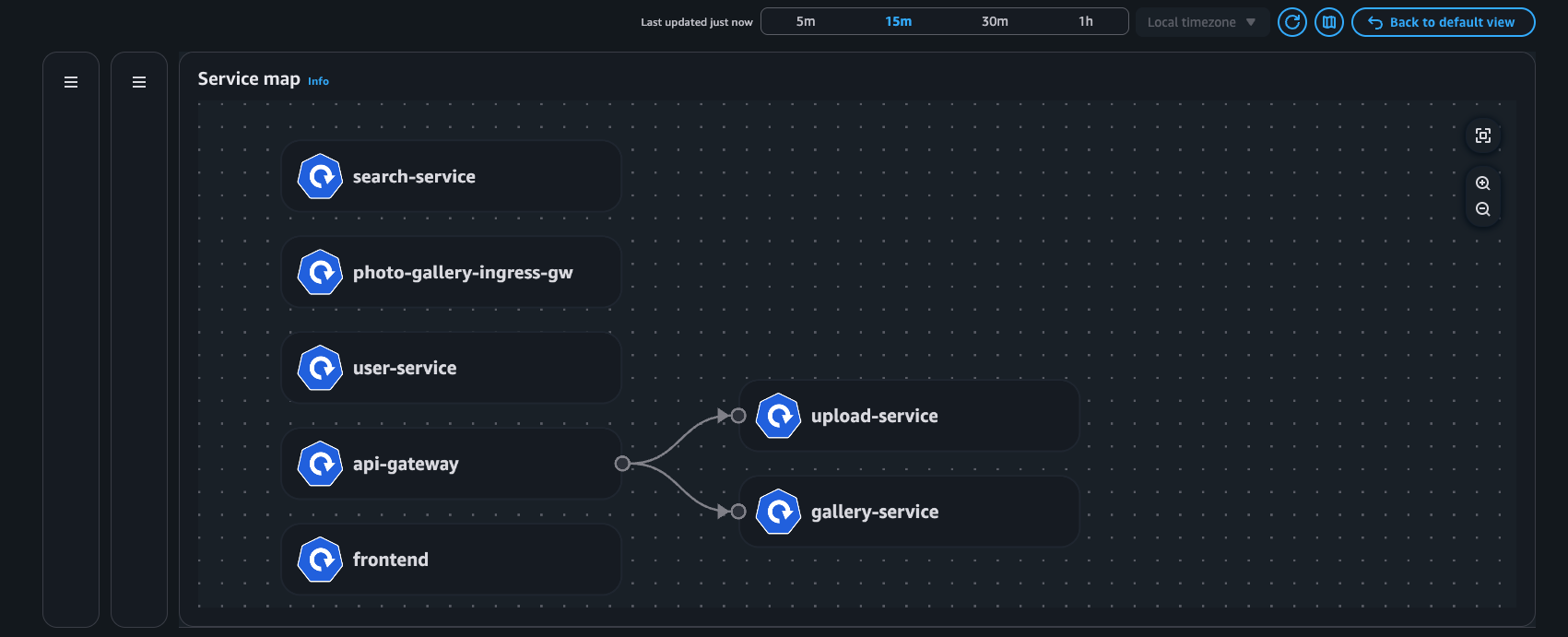
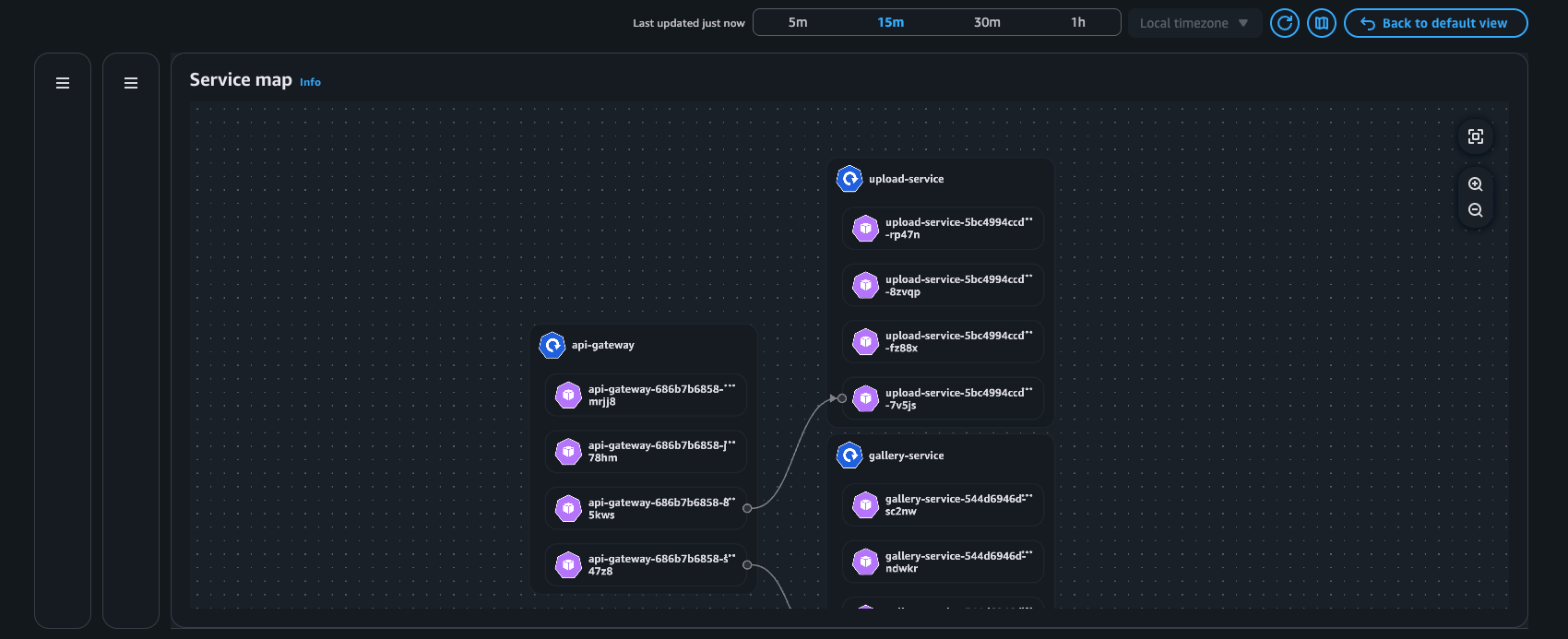
Service Map — Diese Funktion visualisiert dynamisch die Interkommunikation zwischen Workloads im Cluster, sodass Sie wichtige Kennzahlen (Retransmissions — RT, Retransmission Timeouts — RTO und übertragene Daten — DT) im Zusammenhang mit Netzwerkflüssen zwischen kommunizierenden Pods schnell offenlegen können.
-
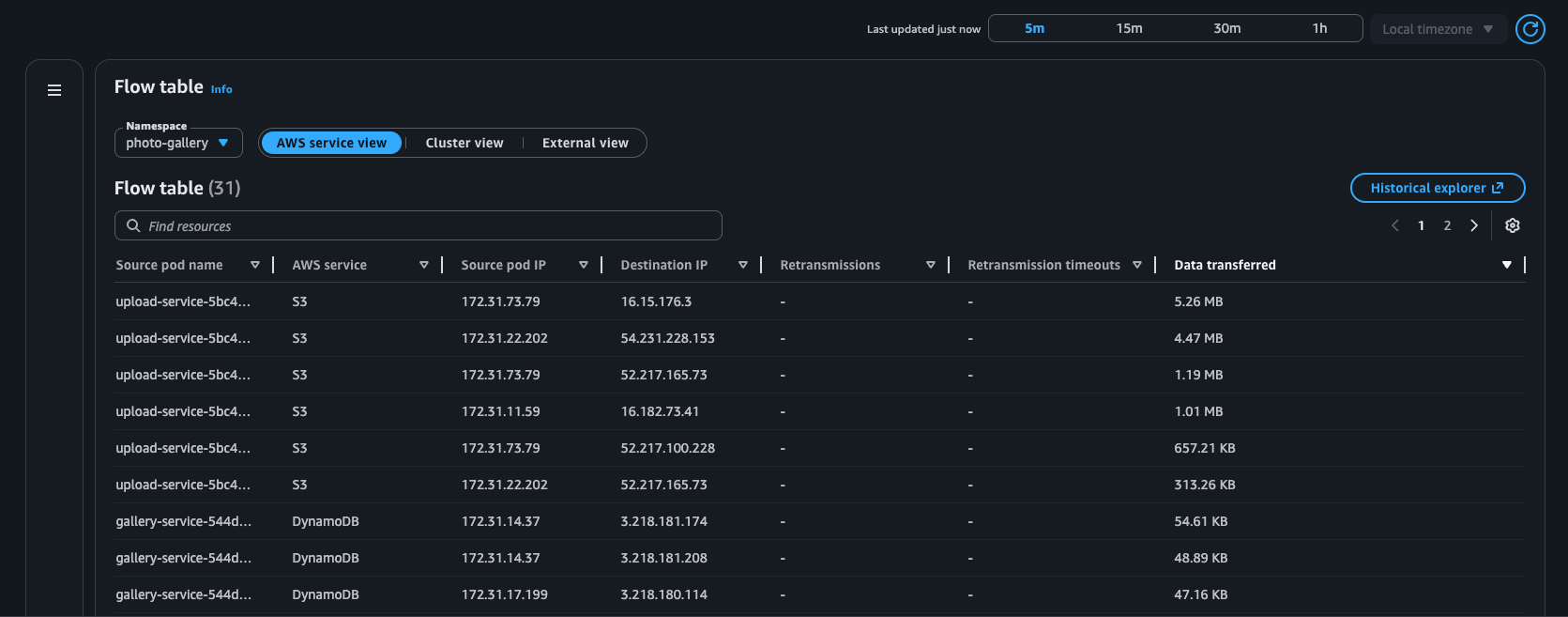
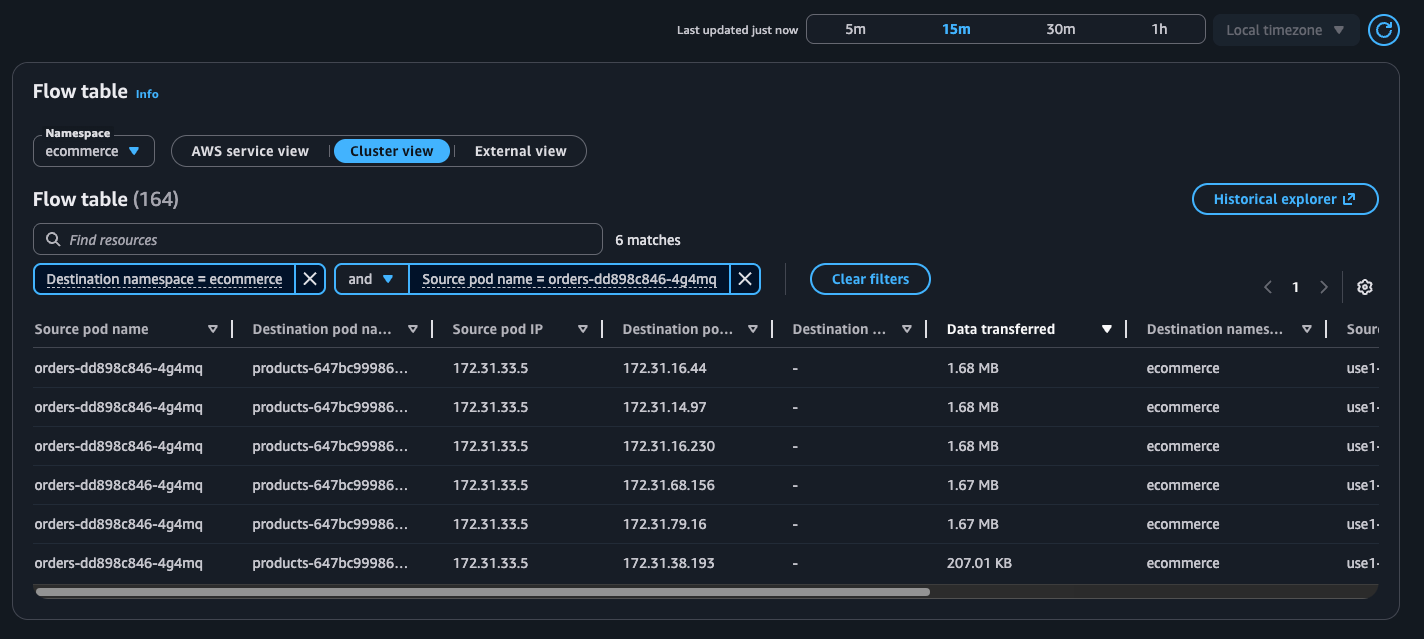
Flow-Tabelle — Mit dieser Tabelle können Sie die Top-Talker der Kubernetes-Workloads in Ihrem Cluster aus drei verschiedenen Blickwinkeln überwachen: Serviceansicht, Clusteransicht und externe Ansicht. AWS Für jede Ansicht können Sie die erneuten Übertragungen, die Timeouts für die erneute Übertragung und die zwischen dem Quell-Pod und seinem Ziel übertragenen Daten sehen.
-
AWS Serviceansicht: Zeigt die Top-Talker zu AWS Diensten an (DynamoDB und S3)
-
Cluster-Ansicht: Zeigt die Top-Talker innerhalb des Clusters an (von Ost ← nach → West)
-
Externe Ansicht: Zeigt die Top-Talker zu clusterexternen Zielen außerhalb AWS
-
Erste Schritte
Aktivieren Sie zunächst Container Network Observability in der EKS-Konsole für einen neuen oder vorhandenen Cluster. Dadurch wird die Erstellung von Network Flow Monitor (NFM) -Abhängigkeiten (Scope - und Monitor-Ressourcen) automatisiert. Darüber hinaus müssen Sie das Network Flow Monitor Agent-Add-on installieren. Alternativ können Sie diese Abhängigkeiten mithilfe der AWS CLI EKS-APIs (für das Add-on), NFM-APIs oder Infrastructure as Code (wie Terraform
Wenn Sie Network Flow Monitor in EKS verwenden, können Sie Ihren bestehenden Observability-Workflow und Ihren Technologie-Stack beibehalten und gleichzeitig eine Reihe zusätzlicher Funktionen nutzen, die es Ihnen ermöglichen, die Netzwerkschicht Ihrer EKS-Umgebung besser zu verstehen und zu optimieren. Weitere Informationen zu den Preisen von Network Flow Monitor finden Sie hier.
Voraussetzungen und wichtige Hinweise
-
Wie oben erwähnt, werden die zugrunde liegenden NFM-Ressourcenabhängigkeiten (Scope und Monitor) automatisch in Ihrem Namen erstellt, wenn Sie Container Network Observability von der EKS-Konsole aus aktivieren, und Sie werden durch den Installationsprozess des EKS-Add-ons für NFM geführt.
-
Wenn Sie diese Funktion mithilfe von Infrastructure as Code (IaC) wie Terraform aktivieren möchten, müssen Sie die folgenden Abhängigkeiten in Ihrem IaC definieren: NFM Scope, NFM Monitor, EKS-Add-on für NFM. Darüber hinaus müssen Sie dem EKS-Add-On mithilfe von Pod Identity - oder IAM-Rollen für Dienstkonten (IRSA) die entsprechenden Berechtigungen gewähren.
-
Sie müssen eine Mindestversion von 1.1.0 für das EKS-Add-on des NFM-Agenten ausführen.
-
Sie müssen Version 6.21.0 oder höher des Terraform AWS Providers verwenden, um die Network Flow Monitor-Ressourcen
zu unterstützen.
Erforderliche IAM-Berechtigungen
EKS-Add-on für den NFM-Agenten
Sie können die CloudWatchNetworkFlowMonitorAgentPublishPolicy AWS verwaltete Richtlinie mit Pod Identity verwenden. Diese Richtlinie enthält Berechtigungen für den NFM-Agenten, Telemetrieberichte (Metriken) an einen Network Flow Monitor-Endpunkt zu senden.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Action" : [ "networkflowmonitor:Publish" ], "Resource" : "*" } ] }
Container-Netzwerk-Observability in der EKS-Konsole
Die folgenden Berechtigungen sind erforderlich, um die Funktion zu aktivieren und die Service-Map und die Flow-Tabelle in der Konsole zu visualisieren.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect": "Allow", "Action": [ "networkflowmonitor:ListScopes", "networkflowmonitor:ListMonitors", "networkflowmonitor:GetScope", "networkflowmonitor:GetMonitor", "networkflowmonitor:CreateScope", "networkflowmonitor:CreateMonitor", "networkflowmonitor:TagResource", "networkflowmonitor:StartQueryMonitorTopContributors", "networkflowmonitor:StopQueryMonitorTopContributors", "networkflowmonitor:GetQueryStatusMonitorTopContributors", "networkflowmonitor:GetQueryResultsMonitorTopContributors" ], "Resource": "*" } ] }
Verwenden von AWS CLI, EKS-API und NFM-API
#!/bin/bash # Script to create required Network Flow Monitor resources set -e CLUSTER_NAME="my-eks-cluster" CLUSTER_ARN="arn:aws:eks:{Region}:{Account}:cluster/{ClusterName}" REGION="us-west-2" AGENT_NAMESPACE="amazon-network-flow-monitor" echo "Creating Network Flow Monitor resources..." # Check if Network Flow Monitor agent is running in the cluster echo "Checking for Network Flow Monitor agent in cluster..." if kubectl get pods -n "$AGENT_NAMESPACE" --no-headers 2>/dev/null | grep -q "Running"; then echo "Network Flow Monitor agent exists and is running in the cluster" else echo "Network Flow Monitor agent not found. Installing as EKS addon..." aws eks create-addon \ --cluster-name "$CLUSTER_NAME" \ --addon-name "$AGENT_NAMESPACE" \ --region "$REGION" echo "Network Flow Monitor addon installation initiated" fi # Get Account ID ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) echo "Cluster ARN: $CLUSTER_ARN" echo "Account ID: $ACCOUNT_ID" # Check for existing scope echo "Checking for existing Network Flow Monitor Scope..." EXISTING_SCOPE=$(aws networkflowmonitor list-scopes --region $REGION --query 'scopes[0].scopeArn' --output text 2>/dev/null || echo "None") if [ "$EXISTING_SCOPE" != "None" ] && [ "$EXISTING_SCOPE" != "null" ]; then echo "Using existing scope: $EXISTING_SCOPE" SCOPE_ARN=$EXISTING_SCOPE else echo "Creating new Network Flow Monitor Scope..." SCOPE_RESPONSE=$(aws networkflowmonitor create-scope \ --targets "[{\"targetIdentifier\":{\"targetId\":{\"accountId\":\"${ACCOUNT_ID}\"},\"targetType\":\"ACCOUNT\"},\"region\":\"${REGION}\"}]" \ --region $REGION \ --output json) SCOPE_ARN=$(echo $SCOPE_RESPONSE | jq -r '.scopeArn') echo "Scope created: $SCOPE_ARN" fi # Create Network Flow Monitor with EKS Cluster as local resource echo "Creating Network Flow Monitor..." MONITOR_RESPONSE=$(aws networkflowmonitor create-monitor \ --monitor-name "${CLUSTER_NAME}-monitor" \ --local-resources "type=AWS::EKS::Cluster,identifier=${CLUSTER_ARN}" \ --scope-arn "$SCOPE_ARN" \ --region $REGION \ --output json) MONITOR_ARN=$(echo $MONITOR_RESPONSE | jq -r '.monitorArn') echo "Monitor created: $MONITOR_ARN" echo "Network Flow Monitor setup complete!" echo "Monitor ARN: $MONITOR_ARN" echo "Scope ARN: $SCOPE_ARN" echo "Local Resource: AWS::EKS::Cluster (${CLUSTER_ARN})"
Verwendung von Infrastruktur als Code (IaC)
Terraform
Wenn Sie Terraform zur Verwaltung Ihrer AWS Cloud-Infrastruktur verwenden, können Sie die folgenden Ressourcenkonfigurationen einbeziehen, um Container Network Observability für Ihren Cluster zu aktivieren.
NFM-Geltungsbereich
data "aws_caller_identity" "current" {} resource "aws_networkflowmonitor_scope" "example" { target { region = "us-east-1" target_identifier { target_type = "ACCOUNT" target_id { account_id = data.aws_caller_identity.current.account_id } } } tags = { Name = "example" } }
NFM-Monitor
resource "aws_networkflowmonitor_monitor" "example" { monitor_name = "eks-cluster-name-monitor" scope_arn = aws_networkflowmonitor_scope.example.scope_arn local_resource { type = "AWS::EKS::Cluster" identifier = aws_eks_cluster.example.arn } remote_resource { type = "AWS::Region" identifier = "us-east-1" # this must be the same region that the cluster is in } tags = { Name = "example" } }
EKS-Add-on für NFM
resource "aws_eks_addon" "example" { cluster_name = aws_eks_cluster.example.name addon_name = "aws-network-flow-monitoring-agent" }
Funktionsweise
Leistungsmetriken
Systemmetriken
Wenn Sie Drittanbieter-Tools (3P) zur Überwachung Ihrer EKS-Umgebung (wie Prometheus und Grafana) verwenden, können Sie die unterstützten Systemmetriken direkt vom Network Flow Monitor-Agenten abrufen. Diese Metriken können an Ihren Monitoring-Stack gesendet werden, um die Messung der Netzwerkleistung Ihres Systems auf Pod- und Worker-Node-Ebene zu erweitern. Die verfügbaren Metriken sind in der Tabelle unter Unterstützte Systemmetriken aufgeführt.
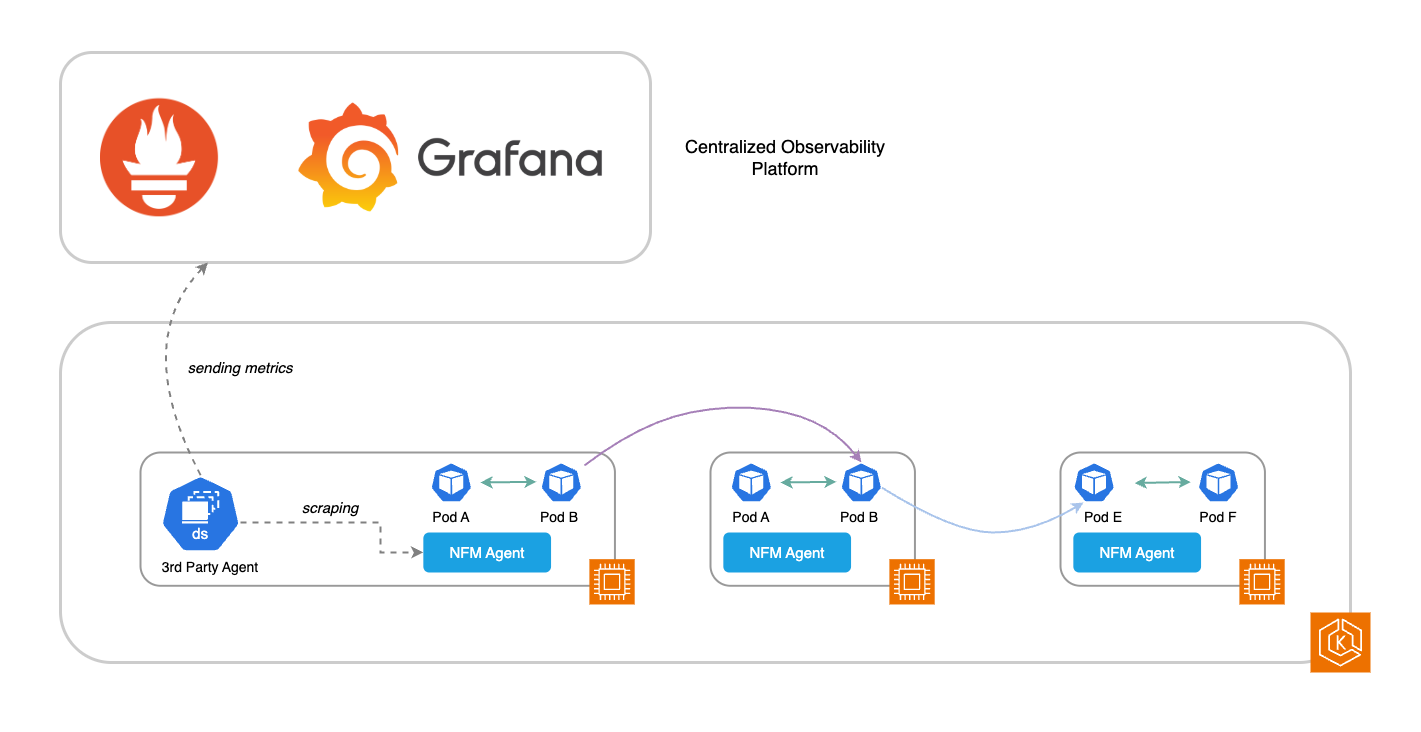
Um diese Metriken zu aktivieren, überschreiben Sie während des Installationsvorgangs die folgenden Umgebungsvariablen mithilfe der Konfigurationsvariablen (siehe:): https://aws.amazon.com/blogs/containers/amazon-eks-add-ons-advanced-configuration/
OPEN_METRICS: Enable or disable open metrics. Disabled if not supplied Type: String Values: [“on”, “off”] OPEN_METRICS_ADDRESS: Listening IP address for open metrics endpoint. Defaults to 127.0.0.1 if not supplied Type: String OPEN_METRICS_PORT: Listening port for open metrics endpoint. Defaults to 80 if not supplied Type: Integer Range: [0..65535]
Metriken auf Flussebene
Darüber hinaus erfasst Network Flow Monitor Netzwerkflussdaten zusammen mit Metriken auf Flussebene: Neuübertragungen, Zeitüberschreitungen bei der erneuten Übertragung und übertragene Daten. Diese Daten werden von Network Flow Monitor verarbeitet und in der EKS-Konsole visualisiert, um den Datenverkehr in der Umgebung Ihres Clusters zu ermitteln und anhand dieser Metriken auf Flussebene zu ermitteln, wie er abschneidet.
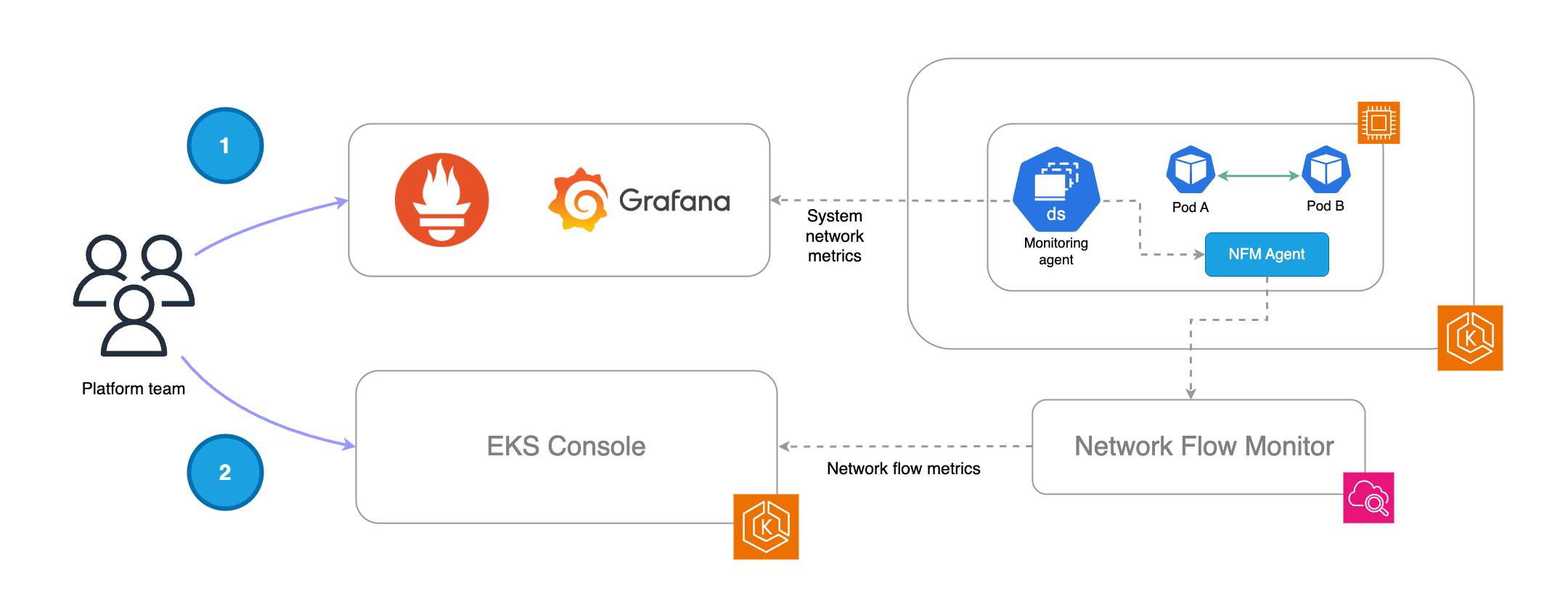
Das folgende Diagramm zeigt einen Workflow, in dem beide Arten von Metriken (System- und Flow-Ebene) genutzt werden können, um mehr betriebliche Informationen zu gewinnen.
-
Das Plattformteam kann Systemmetriken in seinem Monitoring-Stack sammeln und visualisieren. Wenn Warnmeldungen vorhanden sind, können sie mithilfe der Systemmetriken des NFM-Agenten Netzwerkanomalien oder Probleme erkennen, die sich auf Pods oder Worker-Knoten auswirken.
-
Als nächsten Schritt können Plattformteams die nativen Visualisierungen in der EKS-Konsole nutzen, um den Untersuchungsbereich weiter einzugrenzen und die Fehlerbehebung auf der Grundlage von Ablaufdarstellungen und den zugehörigen Metriken zu beschleunigen.
Wichtiger Hinweis: Das Scraping von Systemmetriken aus dem NFM-Agenten und der Prozess, bei dem der NFM-Agent Metriken auf Flow-Ebene an das NFM-Backend überträgt, sind unabhängige Prozesse.
Unterstützte Systemmetriken
Wichtiger Hinweis: Systemmetriken werden im OpenMetrics
| Metrikname | Typ | Dimensionen | Description |
|---|---|---|---|
|
ingress_flow |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl eingehender TCP-Datenflüsse () TcpPassiveOpens |
|
Ausgangsfluss |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl der ausgehenden TCP-Datenflüsse () TcpActiveOpens |
|
Eingangspakete |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl eingehender Pakete (Delta) |
|
ausgehende Pakete |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl der ausgehenden Pakete (Delta) |
|
Ingress_Bytes |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl der eingehenden Byte (Delta) |
|
Ausgangs-Bytes |
Messinstrument |
instance_id, iface, pod, namespace, node |
Anzahl der ausgehenden Byte (Delta) |
|
bw_in_allowance_exceeded |
Messinstrument |
instance_id, eni, Knoten |
Pakete queued/dropped aufgrund der Bandbreitenbeschränkung für eingehende Nachrichten |
|
bw_out_allowance_exceeded |
Messinstrument |
instance_id, eni, Knoten |
Pakete queued/dropped aufgrund der Bandbreitenbeschränkung für ausgehende Nachrichten |
|
pps_allowance_exceeded |
Messinstrument |
instance_id, eni, Knoten |
Pakete queued/dropped aufgrund des bidirektionalen PPS-Limits |
|
conntrack_allowance_exceeded |
Messinstrument |
instance_id, eni, Knoten |
Pakete wurden aufgrund des Limits für die Verbindungsverfolgung verworfen |
|
linklocal_allowance_exceeded |
Messinstrument |
instance_id, eni, Knoten |
Pakete wurden aufgrund des PPS-Limits für den lokalen Proxydienst verworfen |
Unterstützte Metriken auf Flussebene
| Metrikname | Typ | Description |
|---|---|---|
|
TCP-Neuübertragungen |
Zähler |
Gibt an, wie oft ein Absender ein Paket erneut sendet, das während der Übertragung verloren gegangen oder beschädigt wurde. |
|
Timeouts bei TCP-Neuübertragung |
Zähler |
Gibt an, wie oft ein Absender eine Wartezeit eingeleitet hat, um festzustellen, ob ein Paket während der Übertragung verloren gegangen ist. |
|
Übertragene Daten (Byte) |
Zähler |
Datenmenge, die für einen bestimmten Datenfluss zwischen einer Quelle und einem Ziel übertragen wird. |
Servicekarte und Datenflusstabelle
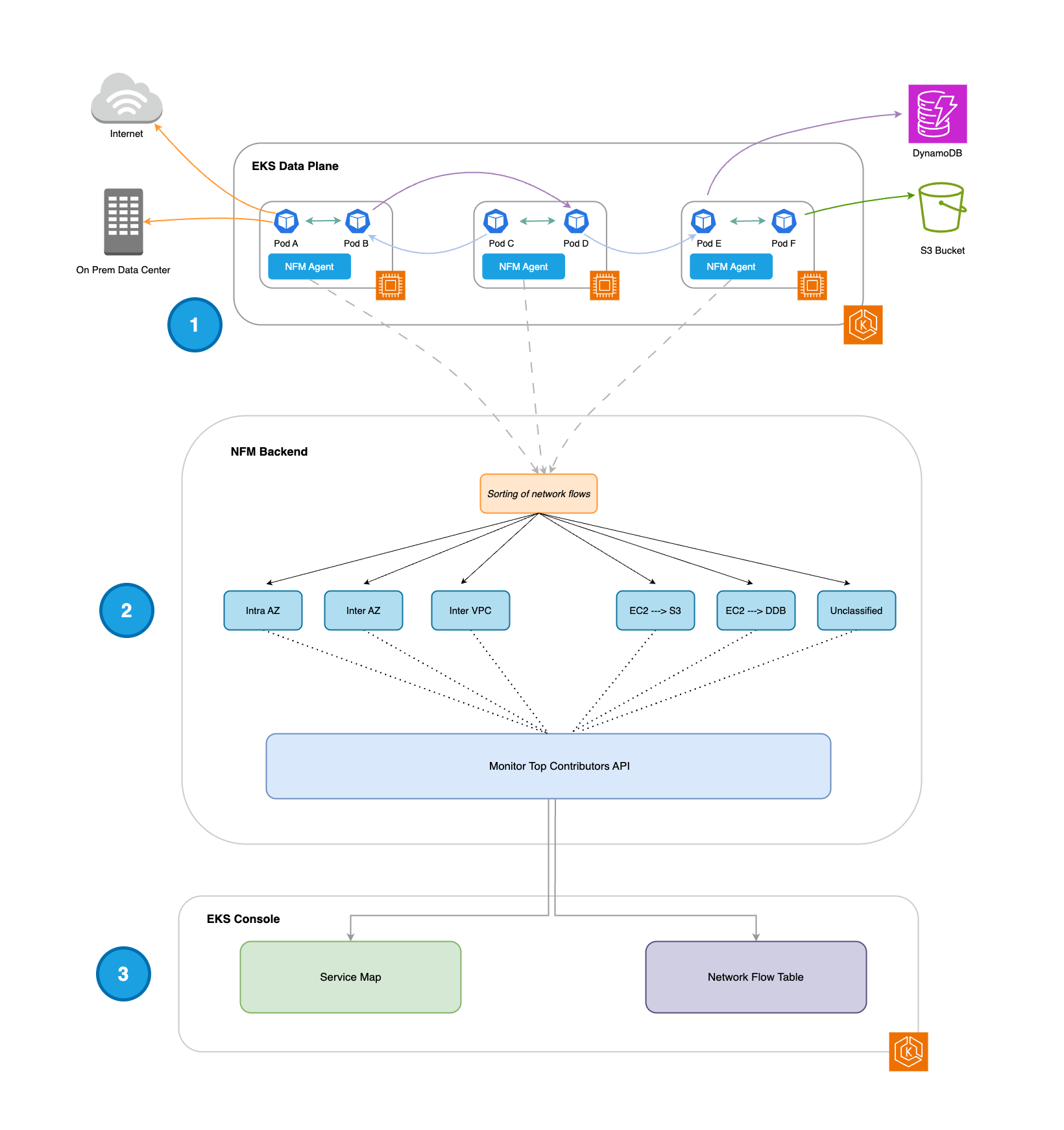
-
Nach der Installation wird der Network Flow Monitor-Agent DaemonSet auf jedem Worker-Node ausgeführt und erfasst alle 30 Sekunden die 500 wichtigsten Netzwerkflüsse (basierend auf dem übertragenen Datenvolumen).
-
Diese Netzwerkflüsse sind in die folgenden Kategorien unterteilt: Intra AZ, Inter AZ, EC2 → S3, EC2 → DynamoDB (DDB) und Unclassified. Jedem Datenfluss sind drei Metriken zugeordnet: Neuübertragungen, Zeitüberschreitungen bei der erneuten Übertragung und übertragene Daten (in Byte).
-
Intra AZ — Netzwerkflüsse zwischen Pods in derselben AZ
-
Inter AZ — Netzwerkflüsse zwischen Pods in verschiedenen AZs
-
EC2 → S3 — Netzwerkflüsse von Pods zu S3
-
EC2 → DDB — Netzwerkflüsse von Pods zu DDB
-
Nicht klassifiziert — Netzwerkflüsse von Pods ins Internet oder vor Ort
-
-
Netzwerkflüsse aus der Network Flow Monitor Top Contributors API werden verwendet, um die folgenden Funktionen in der EKS-Konsole bereitzustellen:
-
Service-Map: Visualisierung der Netzwerkflüsse innerhalb des Clusters (Intra AZ und Inter AZ).
-
Flow-Tabelle: Tabellendarstellung der Netzwerkflüsse innerhalb des Clusters (Intra AZ und Inter AZ), von Pods zu AWS Diensten (EC2 → S3 und EC2 → DDB) und von Pods zu externen Zielen (nicht klassifiziert).
-
Die Netzwerkflüsse, die aus der Top Contributors API abgerufen werden, sind auf einen Zeitraum von 1 Stunde begrenzt und können bis zu 500 Datenflüsse aus jeder Kategorie umfassen. Für die Service Map bedeutet dies, dass bis zu 1000 Datenflüsse aus den Datenflusskategorien Intra AZ und Inter AZ über einen Zeitraum von 1 Stunde abgerufen und dargestellt werden können. Für die Flow-Tabelle bedeutet dies, dass bis zu 2500 Netzwerkflüsse aus allen fünf Netzwerkflusskategorien über einen Zeitraum von 2 Stunden abgerufen und dargestellt werden können.
Beispiel: Serviceübersicht
Bereitstellungsansicht
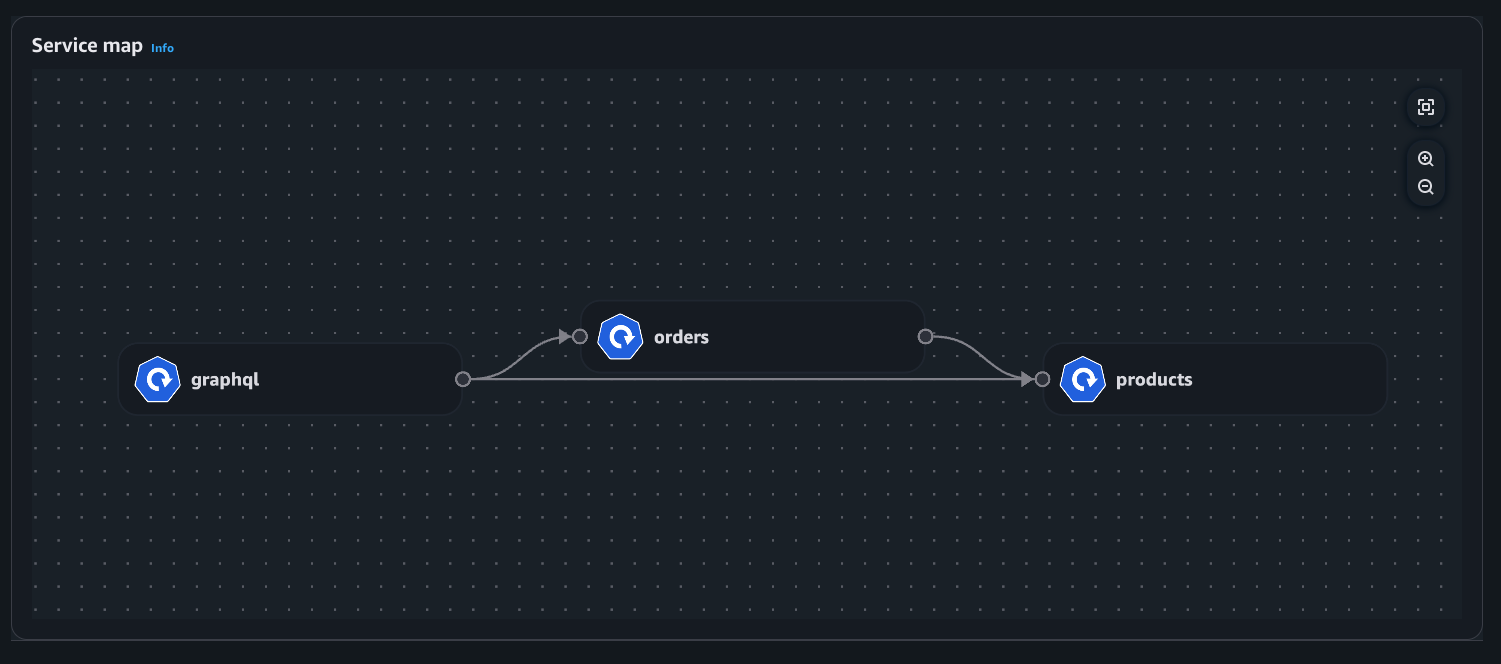
Pod-Ansicht
Bereitstellungsansicht
Pod-Ansicht
Beispiel: Flow-Tabelle
AWS Serviceansicht
Cluster-Ansicht
Überlegungen und Einschränkungen
-
Container Network Observability in EKS ist nur in Regionen verfügbar, in denen Network Flow Monitor unterstützt wird.
-
Unterstützte Systemmetriken sind OpenMetrics formatiert und können direkt vom Network Flow Monitor (NFM) -Agenten abgerufen werden.
-
Um Container Network Observability in EKS mithilfe von Infrastructure as Code (IaC) wie Terraform
zu aktivieren, müssen Sie die folgenden Abhängigkeiten in Ihren Konfigurationen definiert und erstellt haben: NFM-Bereich, NFM-Monitor und NFM-Agent. -
Network Flow Monitor unterstützt bis zu etwa 5 Millionen Datenflüsse pro Minute. Das sind ungefähr 5.000 EC2-Instances (EKS-Worker-Knoten), auf denen der Network Flow Monitor-Agent installiert ist. Die Installation von Agenten auf mehr als 5000 Instances kann die Überwachungsleistung beeinträchtigen, bis zusätzliche Kapazität verfügbar ist.
-
Sie müssen eine Mindestversion von 1.1.0 für das EKS-Add-on des NFM-Agenten ausführen.
-
Sie müssen Version 6.21.0 oder höher des Terraform AWS Providers verwenden, um die Network Flow Monitor-Ressourcen
zu unterstützen. -
Um die Netzwerkflüsse mit Pod-Metadaten anzureichern, sollten Ihre Pods in ihrem eigenen isolierten Netzwerk-Namespace ausgeführt werden, nicht im Host-Netzwerk-Namespace.
