Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
&Load-Serve-Modelle auf Amazon EKS
Tipp
Melden Sie sich
Die Schritte in diesem Abschnitt stellen ein Large Language Model (LLM) auf Amazon EKS bereit, stellen es mit vLLM bereit und interagieren mit dem Inferenzendpunkt.
In der exemplarischen Vorgehensweise werden die folgenden Tools verwendet:
-
vLLM
— Eine Inferenz-Engine mit hohem Durchsatz, die für LLM-Serving und GPU-Speicherverwaltung optimiert ist. -
Run:ai Model Streamer
— Streamt Modellgewichte direkt von Amazon S3 in den GPU-Speicher und reduziert so die Ladezeit von Minuten auf Sekunden. -
Open WebUI
— Ein selbst gehostetes Chat-Frontend, das eine Verbindung zur API von vLLM herstellt. OpenAI-compatible
In diesem Abschnitt wird das Ministral-3-8B-Instruct-2512 Modell
Wichtig
Verwenden Sie den Cluster, den Sie im Abschnitt erstellt haben. Amazon EKS-Cluster für AI/ML Workloads einrichten Die Anweisungen in dieser exemplarischen Vorgehensweise funktionieren sowohl für den EKS-Automodus als auch für den selbstverwalteten Karpenter.
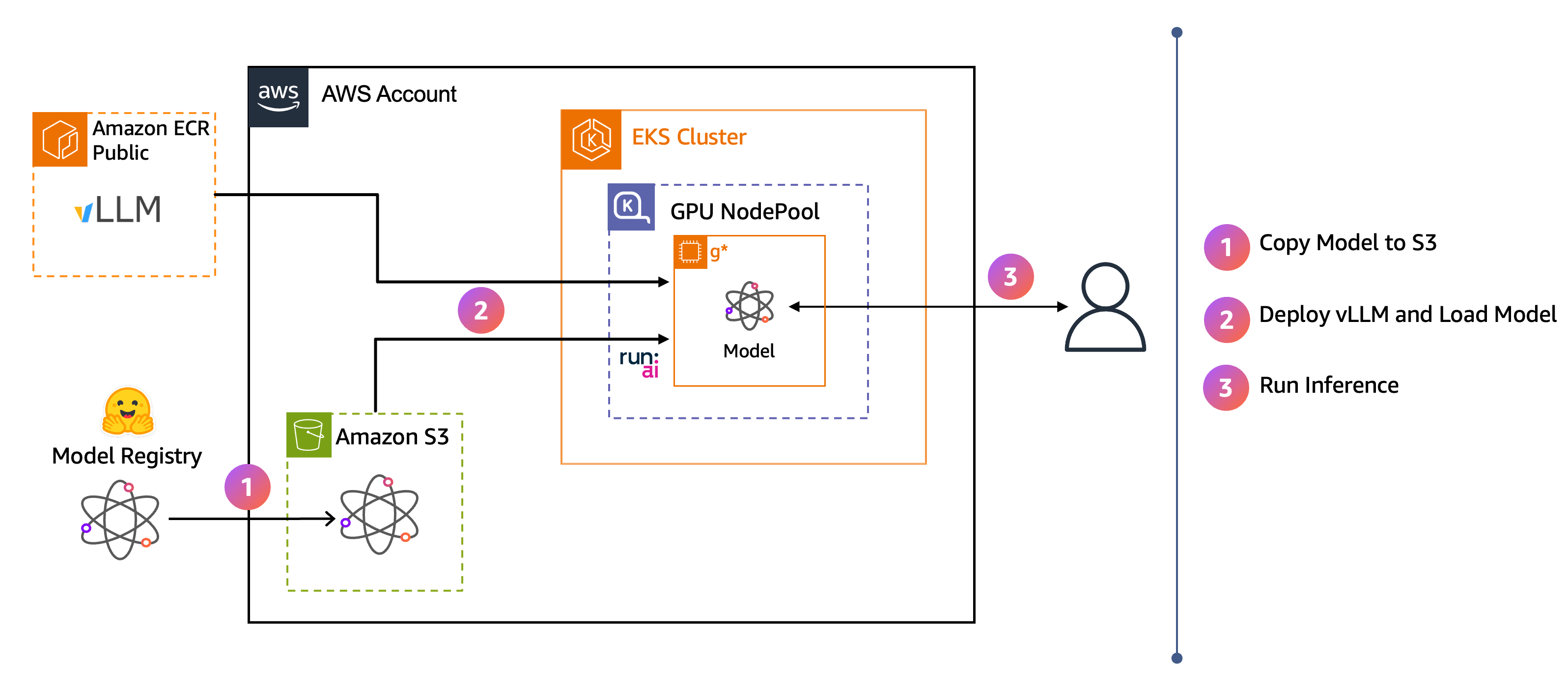
Das Architekturdiagramm zeigt den gesamten Ablauf:
-
Modellgewichte werden von Hugging Face auf Amazon S3 heruntergeladen.
-
vLLM streamt das Modell mithilfe von Model Streamer direkt von S3 in den GPU-Speicher. Run:ai
-
Benutzer senden Inferenzanfragen an den vLLM-Endpunkt.
Wenn Sie diese Schritte abgeschlossen haben, verfügen Sie über einen vLLM-Inferenzendpunkt, mit dem Sie über eine Chat-Frontend-Anwendung mit einem Ministral-Modell interagieren können.
Voraussetzungen
Führen Sie die Schritte im Abschnitt Cluster-Setup aus.
Wenn Sie ein neues Terminal geöffnet haben, legen Sie den Clusternamen und die Region fest, die Sie im Abschnitt Cluster-Setup via CLI verwendet haben:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Suchen Sie nach dem Bucket für Modellgewichte, das Sie im Schritt Modellgewichte S3 erstellt haben:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Schritt 1: Laden Sie das Modell von Hugging Face herunter
In diesem Schritt stellen Sie einen Kubernetes-Job bereit, der das Modell von Hugging Face herunterlädt und in den S3-Bucket hochlädt, den Sie im Abschnitt Voraussetzungen erstellt haben.
Wenden Sie das folgende Job-Manifest an, um das Modell herunterzuladen:
cat << EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-download namespace: default labels: guide: ai-eks-docs spec: backoffLimit: 10 activeDeadlineSeconds: 3600 ttlSecondsAfterFinished: 86400 template: spec: restartPolicy: Never serviceAccountName: model-storage-sa containers: - name: downloader image: python:3.11-slim command: ["/bin/bash", "-c"] args: - | set -e pip install -q huggingface_hub boto3 echo "Downloading Ministral-3-8B-Instruct-2512 from Hugging Face..." python3 -c "from huggingface_hub import snapshot_download; snapshot_download('mistralai/Ministral-3-8B-Instruct-2512', local_dir='/tmp/mistral', allow_patterns=['*.json', '*.txt', '*.md', 'consolidated.safetensors'], ignore_patterns=['model-*.safetensors', 'model.safetensors.index.json'])" echo "Uploading to S3 bucket: \${MODEL_BUCKET}" python3 << 'PYTHON' import boto3 import os from pathlib import Path s3 = boto3.client('s3') bucket = os.environ.get('MODEL_BUCKET') local_dir = Path("/tmp/mistral") for file_path in local_dir.rglob("*"): if file_path.is_file(): if '.cache' in file_path.parts: continue s3_key = f"Ministral-3-8B-Instruct-2512/{file_path.relative_to(local_dir)}" print(f"Uploading {file_path.name}...") s3.upload_file(str(file_path), bucket, s3_key) print("Upload complete!") PYTHON env: - name: MODEL_BUCKET value: "${MODEL_BUCKET}" - name: HF_HUB_DISABLE_XET value: "1" resources: requests: memory: "2Gi" cpu: "1" limits: memory: "4Gi" cpu: "2" EOF
Warten Sie, bis der Job abgeschlossen ist. Die Gewichte des Modells (consolidated.safetensors) betragen ungefähr 10,4 GB, und dieser Schritt dauert in der Regel 3 bis 5 Minuten.
kubectl wait --for=condition=complete job/model-download --timeout=600s
Erwartete Ausgabe:
job.batch/model-download condition met
Stellen Sie sicher, dass die Modellgewichte auf S3 hochgeladen wurden:
aws s3 ls s3://$(kubectl get job model-download -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="MODEL_BUCKET")].value}')/Ministral-3-8B-Instruct-2512/ --recursive
Erwartete Ausgabe:
2026-05-18 10:29:53 20311 Ministral-3-8B-Instruct-2512/README.md 2026-05-18 10:29:53 2361 Ministral-3-8B-Instruct-2512/SYSTEM_PROMPT.txt 2026-05-18 10:29:53 1903 Ministral-3-8B-Instruct-2512/config.json 2026-05-18 10:29:54 10420633176 Ministral-3-8B-Instruct-2512/consolidated.safetensors 2026-05-18 10:29:53 131 Ministral-3-8B-Instruct-2512/generation_config.json 2026-05-18 10:29:53 1185 Ministral-3-8B-Instruct-2512/params.json 2026-05-18 10:29:53 976 Ministral-3-8B-Instruct-2512/processor_config.json 2026-05-18 10:29:53 16753777 Ministral-3-8B-Instruct-2512/tekken.json 2026-05-18 10:29:53 17077402 Ministral-3-8B-Instruct-2512/tokenizer.json 2026-05-18 10:29:53 21168 Ministral-3-8B-Instruct-2512/tokenizer_config.json
Die konsolidierte.safetensors-Datei enthält die Modellgewichte (ca. 10,4 GB). Bei den verbleibenden Dateien handelt es sich um Konfigurations- und Tokenizer-Dateien, die VllM benötigt, um das Modell bereitzustellen.
Schritt 2: Stellen Sie den Inferenzcontainer bereit
In diesem Abschnitt stellen Sie vLLM als Kubernetes-Bereitstellung bereit, um das Modell bereitzustellen, das Sie auf Amazon S3 hochgeladen haben.
In diesem Abschnitt werden AWS Deep Learning Containers
Diese Bereitstellung verwendet den folgenden AWS DLC für vLLM 0.21.0
public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci
Das Image-Tag weist auf vLLM 0.21.0 mit GPU-Unterstützung, Python 3.12, CUDA 13.0, Ubuntu 22.04 hin, optimiert für Workloads und für EC2-based einen schnelleren Container-Start. SOCI-enabled
Dieses Manifest erstellt ein Deployment, das vLLM auf einem GPU-Knoten ausführt und das Modell mithilfe von Model Streamer direkt von S3 in den GPU-Speicher streamt. Run:ai Das Manifest erstellt auch einen ClusterIP-Dienst, der den vLLM-Endpunkt auf Port 8000 für den Clusterzugriff verfügbar macht.
Wenden Sie das Manifest an:
cat << EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app labels: guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app guide: ai-eks-docs spec: serviceAccountName: model-storage-sa tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule nodeSelector: karpenter.sh/nodepool: gpu-inf containers: - name: vllm-inference image: public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci ports: - containerPort: 8000 args: - "--model=s3://${MODEL_BUCKET}/Ministral-3-8B-Instruct-2512/" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" - "--load-format=runai_streamer" - "--enforce-eager" - "--tokenizer_mode=mistral" - "--config_format=mistral" - "--enable-auto-tool-choice" - "--tool-call-parser=mistral" resources: limits: nvidia.com/gpu: 1 requests: memory: "40Gi" cpu: "8" --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc namespace: default labels: app: vllm-inference-app spec: selector: app: vllm-inference-app ports: - name: http port: 8000 targetPort: 8000 protocol: TCP EOF
Vergewissern Sie sich, dass sich der vLLM-Pod im Status Bereit befindet:
kubectl get pod -l app=vllm-inference-app -w
Erwartete Ausgabe:
NAME READY STATUS RESTARTS AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 Running 0 86s
Es kann ~2 Minuten dauern, bis das Container-Image abgerufen wird und vLLM Modellgewichte von S3 in den GPU-Speicher streamt. Warten Sie, bis der Pod 1/1 in der Spalte READY angezeigt wird, bevor Sie fortfahren.
Die Kombination aus EKS, SOCI und Run:ai Model Streamer ermöglicht einen schnellen Pod-Start. Um die Startzeit für jede Phase zu überprüfen, sehen Sie sich die Pod-Ereignisse an:
kubectl describe pod -l app=vllm-inference-app | grep -A 20 "Events:"
Erwartete Ausgabe:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 86s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). Normal Nominated 85s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-kqkq6 Normal Scheduled 55s default-scheduler Successfully assigned default/vllm-inference-app-d9d54586d-csmd7 to i-04f8792414384d2d3 Normal Pulling 52s kubelet Pulling image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" Normal Pulled 4s kubelet Successfully pulled image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" in 48.376s (48.376s including waiting). Image size: 8802823997 bytes. Normal Created 4s kubelet Created container vllm-inference Normal Started 4s kubelet Started container vllm-inference
In diesem Beispiel wurde der GPU-Knoten innerhalb von 30 Sekunden bereitgestellt und das 8,8-GB-Container-Image wurde mithilfe von SOCI in etwa 48 Sekunden abgerufen. Schnelle Image-Pulls reduzieren die Kaltstartzeiten für große Inferenzcontainer, sodass Sie GPU-Pods dynamisch skalieren können, anstatt ungenutzte GPU-Kapazität zu viel bereitzustellen.
Überprüfen Sie als Nächstes die vLLM-Protokolle, um die Ladezeit des Modells zu überprüfen:
kubectl logs $(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') | grep -i 'Model loading took'
Erwartete Ausgabe:
INFO 05-18 18:41:49 [gpu_model_runner.py:4959] Model loading took 9.81 GiB memory and 5.023344 seconds
Das Protokoll bestätigt, dass Run:ai Model Streamer die 10,4-GB-Modellgewichte innerhalb von etwa 5 Sekunden direkt von S3 in den GPU-Speicher geladen hat und dabei 9,8 GiB GPU-Speicher verbraucht hat.
Beim Herunterladen von Bildern wurde in diesem Beispiel eine g6e.4xlarge-Instance verwendet, die über eine kontinuierliche Netzwerkbandbreite von 20 Gbit/s verfügt. Das Abrufen von Bildern und die Ladezeiten des Modells variieren je nach verfügbarer Netzwerkbandbreite bei anderen Instance-Typen.
Schritt 3: Inferenz ausführen
Validieren Sie bei laufender vLLM-Bereitstellung den Inferenzendpunkt und stellen Sie ein Chat-Frontend bereit, um mit dem Modell zu interagieren.
Führen Sie einen Modellvalidierungstest durch
Machen Sie den Inferenzendpunkt per Portweiterleitung verfügbar:
kubectl port-forward svc/vllm-inference-svc 8000:8000
Öffnen Sie ein neues Terminalfenster und überprüfen Sie dann, ob der Inferenzcontainer reagiert:
curl -sI -X GET http://localhost:8000/health
Erwartete Ausgabe:
HTTP/1.1 200 OK date: Fri, 18 May 2026 00:39:23 GMT server: uvicorn content-length: 0
Schritt 4: Überwachen Sie vLLM
vLLM stellt sofort einsatzbereite Prometheus-Metriken bereit, darunter Anforderungsrate, Token-Durchsatz, End-to-End-Latenz und GPU-KV-Cache-Auslastung. In diesem Abschnitt verwenden Sie diese Metriken mit dem Monitoring-Stack, den Sie in den Schritten zur Clustereinrichtung eingerichtet haben, und zeigen sie auf einem vorab bereitgestellten Grafana-Dashboard an.
Wichtig
Sie müssen den Unterabschnitt Überwachung des Abschnitts Cluster-Setup über CLI abschließen, bevor Sie fortfahren können. Dieser Schritt hängt davon ab, ob der Kube-Prometheus-Stack installiert ist und ob das vLLM Grafana-Dashboard bereits in der Wertedatei bereitgestellt wurde.
Wenden Sie das vLLM an ServiceMonitor
A ServiceMonitor teilt Prometheus mit, wo die vLLM-Metriken gescrapt werden sollen.
cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: vllm-inference-app namespace: default labels: release: kube-prometheus-stack spec: selector: matchLabels: app: vllm-inference-app endpoints: - port: http path: /metrics interval: 15s EOF
Stellen Sie sicher, dass das erstellt wurde: ServiceMonitor
kubectl get servicemonitor vllm-inference-app
Erwartete Ausgabe:
NAME AGE vllm-inference-app 5s
Um das Dashboard mit Metriken zu füllen, generieren Sie Inferenzdatenverkehr für den vLLM-Endpunkt, den Sie im Validierungsschritt bereits über Port-Forward verfügbar gemacht haben.
Finden Sie den Namen des bereitgestellten Modells heraus:
MODEL_NAME=$(curl -s http://localhost:8000/v1/models | jq -r '.data[0].id') echo "Using model: $MODEL_NAME"
Senden Sie 50 Anfragen zum Abschluss des Chats parallel:
for i in $(seq 1 50); do curl -s -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d "{\"model\": \"$MODEL_NAME\", \"messages\": [{\"role\": \"user\", \"content\": \"Write a short poem about Kubernetes.\"}], \"max_tokens\": 128}" \ > /dev/null & done wait
Während des Datenverkehrs (oder unmittelbar danach) können Sie die Token-Durchsatzmetriken direkt vom vLLM-Endpunkt aus überprüfen: /metrics
curl -s http://localhost:8000/metrics | grep -E '^vllm:(prompt_tokens_total|generation_tokens_total|avg_generation_throughput_toks_per_s|avg_prompt_throughput_toks_per_s)' | head
Bei den vllm:generation_tokens_total Metriken vllm:prompt_tokens_total und handelt es sich um monoton ansteigende Zähler der bereitgestellten Eingabe- und Ausgabetokens. Bei den vllm:avg_generation_throughput_toks_per_s Messwerten vllm:avg_prompt_throughput_toks_per_s und handelt es sich um Messwerte für den gleitenden Durchschnitt des Durchsatzes. Dieselben Metriken bilden die Grundlage für das Grafana-Dashboard, das Sie im folgenden Unterabschnitt öffnen.
Sehen Sie sich das vLLM Grafana-Dashboard an
Die Datei mit den kube-prometheus-stack-Werten aus dem Abschnitt Monitoring stellt bereits das Community-VllM-Dashboard (gNetID 25263) im Ordner GPU
Um auf Grafana zuzugreifen, starten Sie einen Port-Forward zum Grafana-Dienst:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Öffnen Sie http://localhost:3000
VllM Grafana-Armaturenbrett

Das Dashboard zeigt die Anforderungsrate, den Durchsatz von Eingabeaufforderung und Generierungstoken, die Latenzperzentile und die GPU-KV-Cachenutzung für den vLLM-Inferenzendpunkt an.
Schritt 5: Stellen Sie die Chat-Anwendung bereit
In diesem Schritt stellen Sie Open WebUI als Chat-Frontend bereit, um mit dem Modell zu interagieren. Open WebUI ist eine selbst gehostete Open-Source-KI-Schnittstelle, die OpenAI-compatible APIs unterstützt und eine Chat-Oberfläche mit Konversationsverlauf und Markdown-Rendering bietet. Da vLLM eine OpenAI-compatible API verfügbar macht, stellt Open WebUI als Backend eine direkte Verbindung zu ihr her.
Wenden Sie das folgende Manifest an, um die Open WebUI-Anwendung bereitzustellen:
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: open-webui namespace: default labels: app: open-webui guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui guide: ai-eks-docs spec: containers: - name: open-webui image: ghcr.io/open-webui/open-webui:v0.9.2 ports: - containerPort: 8080 resources: requests: cpu: "500m" memory: "500Mi" limits: cpu: "1000m" memory: "1Gi" env: - name: OPENAI_API_BASE_URLS value: "http://vllm-inference-svc:8000/v1" - name: OPENAI_API_KEY value: "dummy" - name: WEBUI_AUTH value: "False" - name: ENABLE_OLLAMA_API value: "False" - name: ENABLE_EVALUATION_ARENA_MODELS value: "False" volumeMounts: - name: webui-volume mountPath: /app/backend/data volumes: - name: webui-volume emptyDir: {} --- apiVersion: v1 kind: Service metadata: name: open-webui namespace: default labels: app: open-webui spec: type: ClusterIP selector: app: open-webui ports: - protocol: TCP port: 80 targetPort: 8080 EOF
Warten Sie, bis der Open WebUI Pod bereit ist:
kubectl wait --for=condition=ready pod -l app=open-webui --timeout=300s
Erwartete Ausgabe:
pod/open-webui-6cbfc9867f-jf9w9 condition met
Um auf die Anwendung zuzugreifen, richten Sie die Portweiterleitung ein und öffnen Sie die Anwendung in Ihrem Browser:
kubectl port-forward svc/open-webui 8080:80 & sleep 5 echo "Open WebUI: http://localhost:8080"
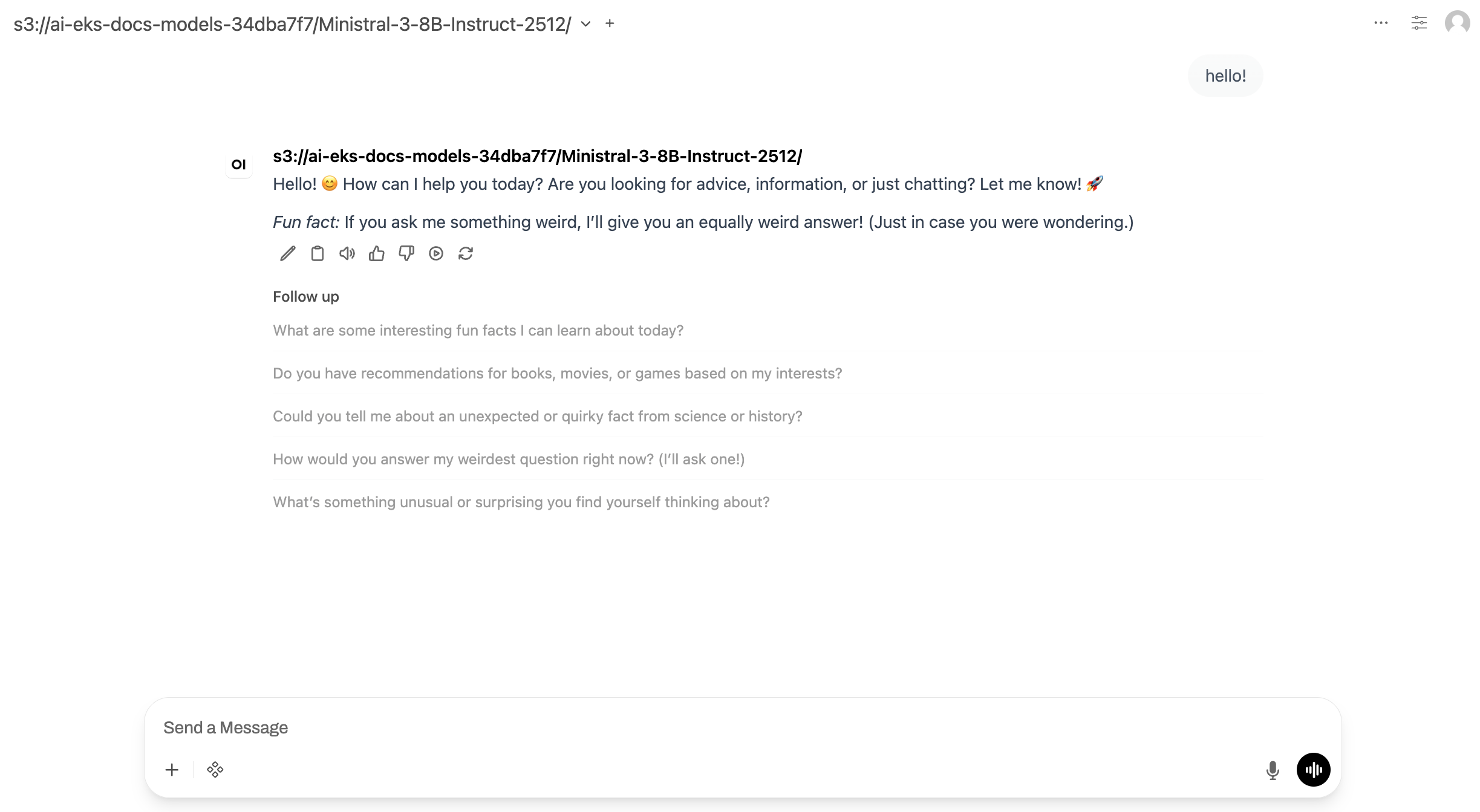
Öffnen Sie http://localhost:8080
Die Chat-Oberfläche wird angezeigt, in der Sie mit dem Ministral-Modell interagieren können.
Wenn Sie mit dem Testen fertig sind, beenden Sie die Port-Forward-Prozesse im Hintergrund, indem Sie sie ausführen kill %1 %2 (oder starten, jobs um sie aufzulisten und kill %<jobspec> für jeden Prozess).
Bereinigen
Um die Workload-Ressourcen zu entfernen, die Sie in diesem Abschnitt erstellt haben, löschen Sie die Open WebUI-Anwendung, den vLLM-Inferenzserver und den Model-Download-Job:
kubectl delete deployment open-webui kubectl delete service open-webui kubectl delete deployment vllm-inference-app kubectl delete service vllm-inference-svc kubectl delete servicemonitor vllm-inference-app kubectl delete job model-download
