Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Kubernetes-Konzepte für Hybridknoten
Auf dieser Seite werden die wichtigsten Kubernetes-Konzepte erläutert, die der Systemarchitektur von EKS-Hybridknoten zugrunde liegen.
EKS-Steuerebene in der VPC
Die IPs der ENIs der EKS-Steuerebene werden im kubernetes Endpoints-Objekt im default-Namespace gespeichert. Wenn EKS neue ENIs erstellt oder ältere entfernt, aktualisiert EKS dieses Objekt, sodass die Liste der IPs immer auf dem neuesten Stand ist.
Sie können diese Endpunkte über den kubernetes-Service auch im default-Namespace verwenden. Diesem Service vom Typ ClusterIP wird immer die erste IP des Service-CIDR des Clusters zugewiesen. Beispielsweise lautet die Service-IP für den Service CIDR 172.16.0.0/16 172.16.0.1.
Im Allgemeinen greifen Pods (unabhängig davon, ob sie in der Cloud oder in Hybridknoten ausgeführt werden) auf diese Weise auf den EKS-Kubernetes-API-Server zu Pods verwenden die Service-IP als Ziel-IP, die in die tatsächlichen IPs einer der EKS-Steuerebenen-ENIs übersetzt wird. Die wichtigste Ausnahme ist kube-proxy, da es die Übersetzung einrichtet.
EKS-API-Server-Endpunkt
Die kubernetes-Service-IP ist nicht die einzige Möglichkeit, auf den EKS-API-Server zuzugreifen. EKS erstellt außerdem einen Route53-DNS-Namen, wenn Sie Ihren Cluster erstellen. Dies ist das Feld endpoint Ihres EKS-Clusters beim Aufruf der EKS-DescribeCluster-API-Aktion.
{ "cluster": { "endpoint": "https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com", "name": "my-cluster", "status": "ACTIVE" } }
In einem Cluster mit öffentlichem Endpunktzugriff oder öffentlichem und privatem Endpunktzugriff lösen Ihre Hybridknoten diesen DNS-Namen standardmäßig in eine öffentliche IP-Adresse auf, die über das Internet routingfähig ist. In einem Cluster mit privatem Endpunktzugriff wird der DNS-Name in die privaten IP-Adressen der EKS-Control-Plane-ENIs aufgelöst.
Auf diese Weise greifen kubelet und kube-proxy auf den Kubernetes-API-Server zu. Wenn Sie möchten, dass der gesamte Datenverkehr Ihres Kubernetes-Clusters über die VPC läuft, müssen Sie entweder Ihren Cluster im privaten Zugriffsmodus konfigurieren oder Ihren On-Premises-DNS-Server so ändern, dass der EKS-Cluster-Endpunkt zu den privaten IP-Adressen der EKS-Steuerebenen-ENIs aufgelöst wird.
kubelet-Endpunkt
Das kubelet stellt mehrere REST-Endpunkte bereit, sodass andere Teile des Systems mit jedem Knoten interagieren und Informationen von diesem erfassen können. In den meisten Clustern stammt der Großteil des Datenverkehrs zum kubelet-Server von der Steuerebene, aber auch bestimmte Überwachungsagenten können mit ihr interagieren.
Über diese Schnittstelle verarbeitet kubelet verschiedene Anfragen: das Abrufen von Protokollen (kubectl logs), das Ausführen von Befehlen in Containern (kubectl exec) und die Portweiterleitung des Datenverkehrs (kubectl port-forward). Jede dieser Anfragen interagiert über das kubelet mit der zugrunde liegenden Container-Laufzeitumgebung, was für Cluster-Administratoren und Entwickler nahtlos erscheint.
Der häufigste Nutzer dieser API ist der Kubernetes-API-Server. Wenn Sie einen der zuvor erwähnten kubectl-Befehle verwenden, sendet kubectl eine API-Anfrage an den API-Server, der dann die kubelet-API des Knotens aufruft, auf dem der Pod ausgeführt wird. Dies ist der Hauptgrund, warum die Knoten-IP von der EKS-Steuerebene aus erreichbar sein muss und warum Sie selbst bei ausgeführten Pods nicht auf deren Protokolle oder exec zugreifen können, wenn die Knoten-Route falsch konfiguriert ist.
Knoten-IPs
Wenn die EKS-Steuerebene mit einem Knoten kommuniziert, verwendet sie eine der im Node-Objektstatus (status.addresses) gemeldeten Adressen.
Bei EKS-Cloud-Knoten ist es üblich, dass der Kubelet die private IP-Adresse der EC2-Instance während der Knotenregistrierung als InternalIP meldet. Diese IP-Adresse wird dann vom Cloud Controller Manager (CCM) überprüft, um sicherzustellen, dass sie zur EC2-Instance gehört. Darüber hinaus fügt der CCM in der Regel die öffentlichen IP-Adressen (als ExternalIP) und DNS-Namen (InternalDNS und ExternalDNS) der Instance zum Knotenstatus hinzu.
Für Hybridknoten gibt es jedoch kein CCM. Wenn Sie einen Hybridknoten mit der EKS-Hybridknoten-CLI (nodeadm) registrieren, wird das kubelet so konfiguriert, dass es die IP-Adresse Ihres Rechners direkt im Status des Knotens meldet, ohne das CCM.
apiVersion: v1 kind: Node metadata: name: my-node-1 spec: providerID: eks-hybrid:///us-west-2/my-cluster/my-node-1 status: addresses: - address: 10.1.1.236 type: InternalIP - address: my-node-1 type: Hostname
Wenn Ihr Rechner über mehrere IP-Adressen verfügt, wählt das kubelet nach seiner eigenen Logik eine davon aus. Sie können die ausgewählte IP mit dem --node-ip-Flag steuern, das Sie in der nodeadm-Konfiguration in spec.kubelet.flags übergeben können. Nur die im Node-Objekt gemeldete IP benötigt eine Route von der VPC. Ihre Rechner können über andere IP-Adressen verfügen, die von der Cloud aus nicht erreichbar sind.
kube-proxy
kube-proxy ist für die Implementierung der Service-Abstraktion auf der Netzwerkebene jedes Knotens verantwortlich. Es agiert als Netzwerk-Proxy und Load Balancer für den Datenverkehr, der für Kubernetes-Services bestimmt ist. Durch die kontinuierliche Überwachung des Kubernetes-API-Servers auf Änderungen in Bezug auf Services und Endpunkte aktualisiert kube-proxy dynamisch die Netzwerkregeln des zugrunde liegenden Hosts, um sicherzustellen, dass der Datenverkehr richtig geleitet wird.
Im iptables-Modus programmiert kube-proxy mehrere netfilter-Ketten zur Handhabung des Service-Datenverkehrs. Die Regeln bilden die folgende Hierarchie:
-
KUBE-SERVICES-Kette: Der Einstiegspunkt für den gesamten Service-Datenverkehr. Sie verfügt über Regeln, die mit dem
ClusterIPund dem Port jedes Services übereinstimmen. -
KUBE-SVC-XXX-Ketten: Service-spezifische Ketten verfügen über Load-Balancing-Regeln für jeden einzelnen Service.
-
KUBE-SEP-XXX-Ketten: Endpunktspezifische Ketten enthalten die aktuellen
DNAT-Regeln.
Betrachten wir, was für einen Service-test-server im default-Namespace geschieht: * Service ClusterIP: 172.16.31.14 * Service-Port: 80 * Unterstützende Pods: 10.2.0.110, 10.2.1.39 und 10.2.2.254
Bei Überprüfung der iptables-Regeln (mit iptables-save –0— grep -A10 KUBE-SERVICES):
-
In der KUBE-SERVICES-Kette finden wir eine Regel, die zum Service passt:
-A KUBE-SERVICES -d 172.16.31.14/32 -p tcp -m comment --comment "default/test-server cluster IP" -m tcp --dport 80 -j KUBE-SVC-XYZABC123456-
Diese Regel gilt für Pakete, die für 172.16.31.14:80 bestimmt sind.
-
Der Kommentar gibt an, wozu diese Regel dient:
default/test-server cluster IP -
Übereinstimmende Pakete werden zur
KUBE-SVC-XYZABC123456-Kette weitergeleitet
-
-
Die KUBE-SVC-XYZABC123456-Kette verfügt über wahrscheinlichkeitsbasierte Lastausgleichsregeln:
-A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-POD1XYZABC -A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-POD2XYZABC -A KUBE-SVC-XYZABC123456 -j KUBE-SEP-POD3XYZABC-
Erste Regel: 33,3 % Wahrscheinlichkeit, dass zu
KUBE-SEP-POD1XYZABCweitergeleitet wird -
Zweite Regel: 50 % Wahrscheinlichkeit, dass der verbleibende Datenverkehr (33,3 % der Gesamtmenge) zu
KUBE-SEP-POD2XYZABCweitergeleitet wird -
Letzte Regel: Der gesamte verbleibende Datenverkehr (33,3 % der Gesamtmenge) wird zu
KUBE-SEP-POD3XYZABCweitergeleitet
-
-
Die einzelnen KUBE-SEP-XXX-Ketten führen das DNAT (Destination NAT) durch:
-A KUBE-SEP-POD1XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.0.110:80 -A KUBE-SEP-POD2XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.1.39:80 -A KUBE-SEP-POD3XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.2.254:80-
Diese DNAT-Regeln schreiben die Ziel-IP und den Ziel-Port neu, um den Datenverkehr an bestimmte Pods weiterzuleiten.
-
Jede Regel verarbeitet etwa 33,3 % des Datenverkehrs und sorgt für eine gleichmäßige Lastverteilung zwischen
10.2.0.110,10.2.1.39und10.2.2.254.
-
Diese mehrstufige Kettenstruktur ermöglicht kube-proxy die effiziente Implementierung des Service-Load-Balancings und der Umleitung durch Paketmanipulation auf Kernelebene, ohne dass ein Proxy-Prozess im Datenpfad erforderlich ist.
Auswirkungen auf den Kubernetes-Betrieb
Ein defekter kube-proxy in einem Knoten verhindert, dass dieser Knoten den Service-Datenverkehr ordnungsgemäß weiterleitet. Dies führt zu Zeitüberschreitungen oder Verbindungsfehlern für Pods, die auf Cluster-Services angewiesen sind. Dies kann insbesondere bei der erstmaligen Registrierung eines Knotens zu Störungen führen. Das CNI muss mit dem Kubernetes-API-Server kommunizieren, um Informationen wie die Pod-CIDR des Knotens abzurufen, bevor es die Pod-Vernetzung konfigurieren kann. Dazu verwendet es die kubernetes-Service-IP. Wenn kube-proxy jedoch nicht gestartet werden konnte oder die richtigen iptables-Regeln nicht festgelegt wurden, werden die an die kubernetes-Service-IP gesendeten Anfragen nicht in die tatsächlichen IPs der ENIs der EKS-Steuerebene übersetzt. Infolgedessen gerät das CNI in eine Absturzsituation, und keiner der Pods kann ordnungsgemäß ausgeführt werden.
Es ist bekannt, dass Pods die kubernetes-Service-IP verwenden, um mit dem Kubernetes-API-Server zu kommunizieren, jedoch muss kube-proxy zunächst iptables-Regeln festlegen, damit dies funktioniert.
Wie kommuniziert kube-proxy mit dem API-Server?
kube-proxy muss so konfiguriert werden, dass es die tatsächlichen IPs des Kubernetes-API-Servers oder einen DNS-Namen verwendet, der auf diese aufgelöst wird. Im Fall von EKS konfiguriert EKS die Standard-kube-proxy so, dass es auf den Route53-DNS-Namen verweist, den EKS beim Erstellen des Clusters erstellt. Sie können diesen Wert in der kube-proxy-ConfigMap im kube-system-Namespace sehen. Der Inhalt dieser ConfigMap ist ein kubeconfig, das in den kube-proxy-Pod eingefügt wird. Suchen Sie also nach dem clusters–0—.cluster.server-Feld. Dieser Wert entspricht dem endpoint-Feld Ihres EKS-Clusters (beim Aufruf der EKS-DescribeCluster-API).
apiVersion: v1 data: kubeconfig: |- kind: Config apiVersion: v1 clusters: - cluster: certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt server: https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com name: default contexts: - context: cluster: default namespace: default user: default name: default current-context: default users: - name: default user: tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token kind: ConfigMap metadata: name: kube-proxy namespace: kube-system
Routingfähige Fern-Pod-CIDRs
Auf der Seite Netzwerkkonzepte für Hybridknoten werden die Anforderungen zum Ausführen von Webhooks in Hybridknoten oder zum Kommunizieren von Pods in Cloud-Knoten mit Pods in Hybridknoten detailliert beschrieben. Die wichtigste Voraussetzung ist, dass der On-Premises-Router weiß, welcher Knoten für eine bestimmte Pod-IP zuständig ist. Es gibt mehrere Möglichkeiten, dies zu erreichen, darunter Border Gateway Protocol (BGP), statische Routen und Address Resolution Protocol (ARP)-Proxying. Diese werden in den folgenden Abschnitten behandelt.
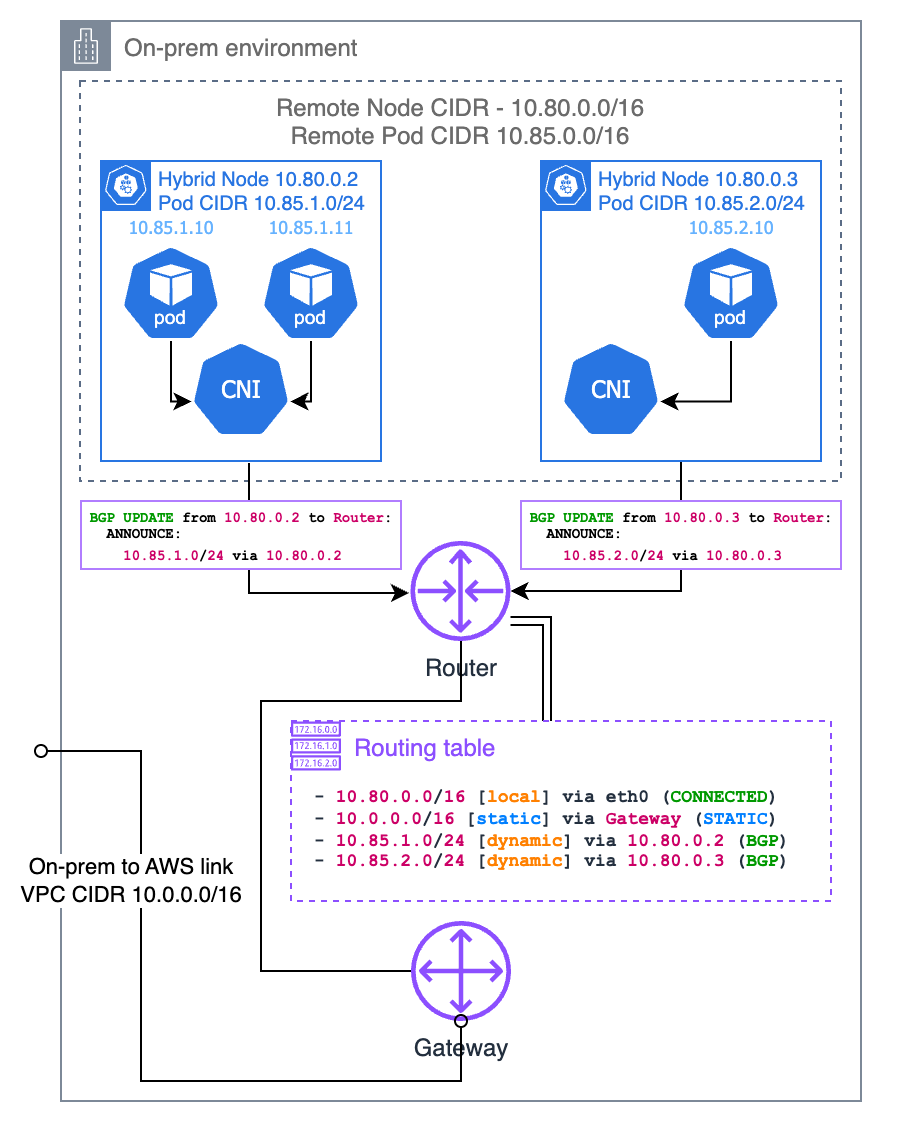
Border Gateway Protocol (BGP)
Wenn Ihr CNI dies unterstützt (z. B. Cilium und Calico), können Sie den BGP-Modus Ihres CNI verwenden, um Routen zu Ihren Pod-CIDRs pro Knoten von Ihren Knoten an Ihren lokalen Router weiterzuleiten. Bei Verwendung des BGP-Modus des CNI agiert Ihr CNI als virtueller Router, sodass Ihr lokaler Router davon ausgeht, dass die Pod-CIDR zu einem anderen Subnetz gehört und Ihr Knoten das Gateway zu diesem Subnetz ist.
Statische Routen
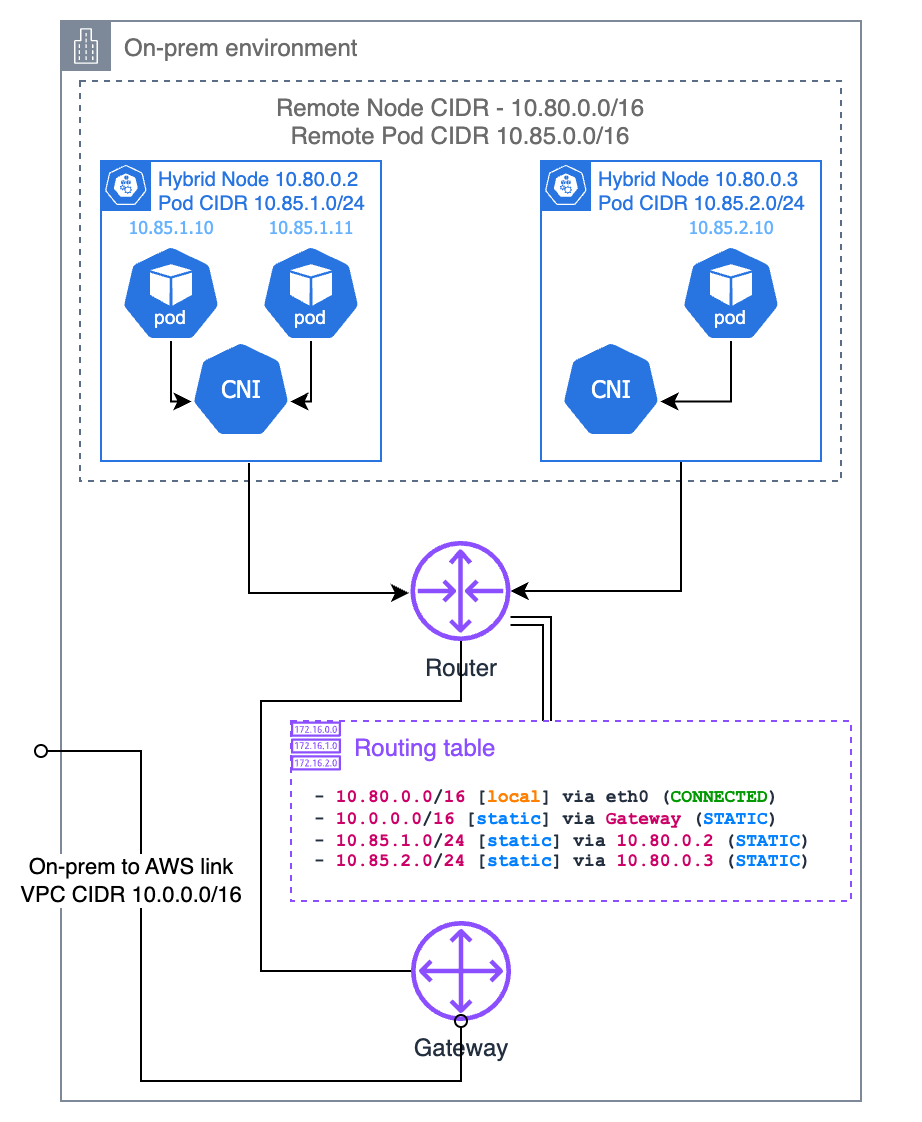
Oder Sie können statische Routen in Ihrem lokalen Router konfigurieren. Dies ist die einfachste Methode, um die CIDR des On-Premises-Pods zu Ihrer VPC weiterzuleiten. Allerdings ist sie auch die fehleranfälligste und am schwierigsten zu wartende Methode. Sie müssen sicherstellen, dass die Routen stets mit den vorhandenen Knoten und den ihnen zugewiesenen Pod-CIDRs auf dem neuesten Stand sind. Wenn die Anzahl Ihrer Knoten gering und die Infrastruktur statisch ist, ist dies eine sinnvolle Option und macht die BGP-Unterstützung in Ihrem Router überflüssig. Wenn Sie sich dafür entscheiden, empfehlen wir Ihnen, Ihr CNI mit dem Pod-CIDR-Segment zu konfigurieren, das Sie jedem Knoten zuweisen möchten, anstatt dies Ihrem IPAM zu überlassen.
Address Resolution Protocol (ARP)-Proxying
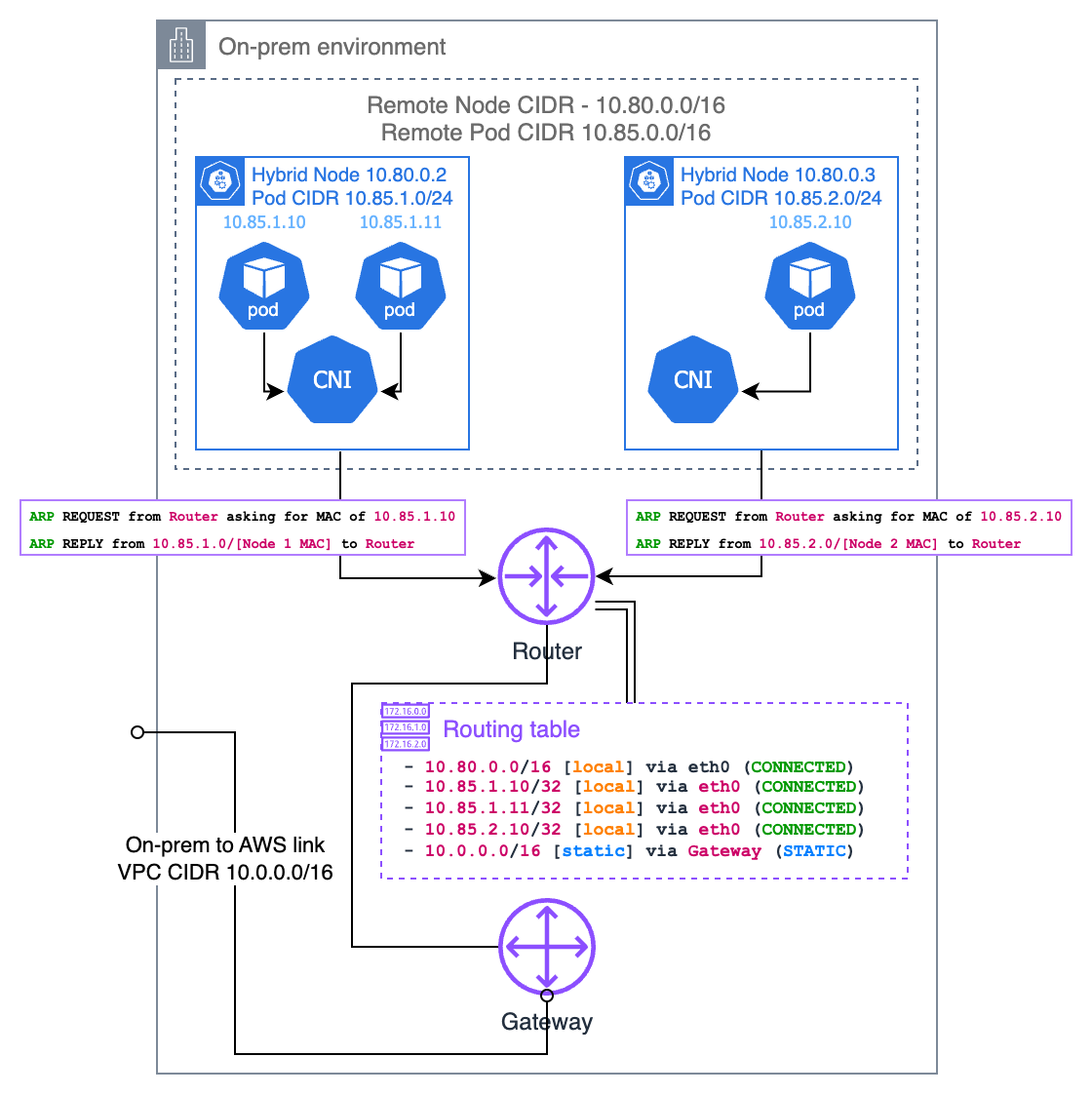
ARP-Proxying ist ein weiterer Ansatz, um On-Premises-Pod-IPs routingfähig zu machen. Dies ist besonders nützlich, wenn sich Ihre Hybridknoten im selben Layer-2-Netzwerk wie Ihr lokaler Router befinden. Wenn ARP-Proxying aktiviert ist, antwortet ein Knoten auf ARP-Anfragen für Pod-IPs, die er hostet, auch wenn diese IPs zu einem anderen Subnetz gehören.
Wenn ein Gerät in Ihrem lokalen Netzwerk versucht, eine Pod-IP zu erreichen, sendet es zunächst eine ARP-Anfrage mit der Frage „Wer hat diese IP?“. Der Hybridknoten, der diesen Pod hostet, antwortet mit seiner eigenen MAC-Adresse und sagt: „Ich kann den Datenverkehr für diese IP verarbeiten.“ Dadurch wird eine direkte Verbindung zwischen den Geräten in Ihrem lokalen Netzwerk und den Pods hergestellt, ohne dass eine Router-Konfiguration erforderlich ist.
Damit dies funktioniert, muss Ihr CNI die Proxy-ARP-Funktionalität unterstützen. Cilium verfügt über integrierten Support für Proxy-ARP, den Sie über die Konfiguration aktivieren können. Der wichtigste Aspekt besteht darin, dass sich das Pod-CIDR nicht mit anderen Netzwerken in Ihrer Umgebung überschneiden darf, da dies zu Routing-Konflikten führen könnte.
Dieser Ansatz bietet mehrere Vorteile: * Sie müssen Ihren Router nicht mit BGP konfigurieren oder statische Routen verwalten. * Funktioniert gut in Umgebungen, in denen Sie keine Kontrolle über Ihre Router-Konfiguration haben.
Pod-zu-Pod-Kapselung
In On-Premises-Umgebungen verwenden CNIs in der Regel Kapselungsprotokolle, um Überlagerungsnetzwerke zu erstellen, die auf dem physischen Netzwerk betrieben werden können, ohne dass dieses neu konfiguriert werden muss. In diesem Abschnitt wird erläutert, wie diese Kapselung funktioniert. Beachten Sie, dass einige Details je nach dem von Ihnen verwendeten CNI variieren können.
Bei der Kapselung werden ursprüngliche Pod-Netzwerkpakete in ein anderes Netzwerkpaket eingebunden, das durch das zugrunde liegende physische Netzwerk geleitet werden kann. Dadurch können Pods über Knoten hinweg kommunizieren, auf denen dasselbe CNI ausgeführt wird, ohne dass das physische Netzwerk wissen muss, wie diese Pod-CIDRs weitergeleitet werden sollen.
Das am häufigsten verwendete Kapselungsprotokoll mit Kubernetes ist Virtual Extensible LAN (VXLAN). Abhängig von Ihrem CNI sind jedoch auch andere Protokolle verfügbar (z. B. Geneve).
VXLAN-Kapselung
VXLAN kapselt Layer-2-Ethernet-Frames in UDP-Paketen. Wenn ein Pod Datenverkehr an einen anderen Pod auf einem anderen Knoten sendet, führt das CNI Folgendes aus:
-
Das CNI fängt Pakete von Pod A ab
-
Das CNI verpackt das ursprüngliche Paket in einen VXLAN-Header
-
Dieses verpackte Paket wird dann über den regulären Netzwerk-Stack des Knotens an den Zielknoten gesendet
-
Das CNI auf dem Zielknoten entpackt das Paket und übermittelt es an Pod B
Folgendes passiert mit der Paketstruktur während der VXLAN-Kapselung:
Ursprüngliches Pod-zu-Pod-Paket:
+-----------------+---------------+-------------+-----------------+ | Ethernet Header | IP Header | TCP/UDP | Payload | | Src: Pod A MAC | Src: Pod A IP | Src Port | | | Dst: Pod B MAC | Dst: Pod B IP | Dst Port | | +-----------------+---------------+-------------+-----------------+
Nach der VXLAN-Kapselung:
+-----------------+-------------+--------------+------------+---------------------------+ | Outer Ethernet | Outer IP | Outer UDP | VXLAN | Original Pod-to-Pod | | Src: Node A MAC | Src: Node A | Src: Random | VNI: xx | Packet (unchanged | | Dst: Node B MAC | Dst: Node B | Dst: 4789 | | from above) | +-----------------+-------------+--------------+------------+---------------------------+
Der VXLAN Network Identifier (VNI) unterscheidet zwischen verschiedenen Überlagerungsnetzwerken.
Szenarien für die Pod-Kommunikation
Pods auf demselben Hybridknoten
Wenn Pods auf demselben Hybridknoten kommunizieren, ist normalerweise keine Kapselung erforderlich. Das CNI richtet lokale Routen ein, die den Datenverkehr zwischen Pods über die internen virtuellen Schnittstellen des Knotens leiten:
Pod A -> veth0 -> node's bridge/routing table -> veth1 -> Pod B
Das Paket verlässt den Knoten nie und erfordert keine Kapselung.
Pods auf verschiedenen Hybridknoten
Die Kommunikation zwischen Pods auf verschiedenen Hybridknoten erfordert eine Kapselung:
Pod A -> CNI -> [VXLAN encapsulation] -> Node A network -> router or gateway -> Node B network -> [VXLAN decapsulation] -> CNI -> Pod B
Dadurch kann der Pod-Datenverkehr die physische Netzwerkinfrastruktur durchlaufen, ohne dass das physische Netzwerk das Pod-IP-Routing verstehen muss.
