Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ausführung hochverfügbarer Anwendungen
Ihre Kunden erwarten, dass Ihre Anwendung immer verfügbar ist, auch wenn Sie Änderungen vornehmen und insbesondere bei Verkehrsspitzen. Eine skalierbare und belastbare Architektur sorgt dafür, dass Ihre Anwendungen und Dienste unterbrechungsfrei laufen, sodass Ihre Benutzer zufrieden sind. Eine skalierbare Infrastruktur wächst und schrumpft je nach den Anforderungen des Unternehmens. Die Eliminierung einzelner Fehlerquellen ist ein entscheidender Schritt, um die Verfügbarkeit einer Anwendung zu verbessern und sie widerstandsfähiger zu machen.
Mit Kubernetes können Sie Ihre Anwendungen betreiben und hochverfügbar und belastbar ausführen. Die deklarative Verwaltung stellt sicher, dass Kubernetes, sobald Sie die Anwendung eingerichtet haben, kontinuierlich versucht, den aktuellen Status mit dem gewünschten Status abzugleichen
Empfehlungen
Konfigurieren Sie Pod-Disruption-Budgets
Budgets für Pod-Unterbrechungen
Vermeiden Sie es, Singleton-Pods auszuführen
Wenn Ihre gesamte Anwendung in einem einzigen Pod ausgeführt wird, ist Ihre Anwendung nicht verfügbar, wenn dieser Pod beendet wird. Anstatt Anwendungen mithilfe einzelner Pods bereitzustellen, erstellen Sie Bereitstellungen.
Führen Sie mehrere Replikate aus
Wenn Sie mehrere Replikate ausführen (Pods) einer App mithilfe eines Deployment, kann diese auf hochverfügbare Weise ausgeführt werden. Wenn ein Replikat ausfällt, funktionieren die verbleibenden Replikate weiterhin, wenn auch mit reduzierter Kapazität, bis Kubernetes einen weiteren Pod erstellt, um den Verlust auszugleichen. Darüber hinaus können Sie den Horizontal Pod Autoscaler verwenden, um Replikate automatisch auf der Grundlage der Arbeitslastanforderung
Planen Sie Replikate knotenübergreifend
Das Ausführen mehrerer Replikate ist nicht sehr nützlich, wenn alle Replikate auf demselben Knoten ausgeführt werden und der Knoten nicht mehr verfügbar ist. Erwägen Sie die Verwendung von Pod-Anti-Affinitäts- oder Pod-Topologie-Verbreitungsbeschränkungen, um Replikate einer Bereitstellung auf mehrere Worker-Knoten zu verteilen.
Sie können die Zuverlässigkeit einer typischen Anwendung weiter verbessern, indem Sie sie auf mehreren AZs ausführen.
Verwendung von Pod-Anti-Affinitätsregeln
Das folgende Manifest weist den Kubernetes-Scheduler an, Pods lieber auf separaten Knoten und AZs zu platzieren. Es sind keine eigenen Knoten oder AZ erforderlich, denn wenn dies der Fall wäre, kann Kubernetes keine Pods planen, sobald in jeder AZ ein Pod läuft. Wenn Ihre Anwendung nur drei Replikate benötigt, können Sie requiredDuringSchedulingIgnoredDuringExecution for verwendentopologyKey: topology.kubernetes.io/zone, und der Kubernetes-Scheduler plant nicht zwei Pods in derselben AZ.
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 4 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: topology.kubernetes.io/zone weight: 100 - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: kubernetes.io/hostname weight: 99 containers: - name: web-app image: nginx:1.16-alpine
Verbreitungsbeschränkungen mithilfe der Pod-Topologie
Ähnlich wie bei Pod-Anti-Affinitätsregeln können Sie mit Einschränkungen für die Verteilung der Pod-Topologie Ihre Anwendung für verschiedene Fehler- (oder Topologie-) Domänen wie Hosts oder AZs verfügbar machen. Dieser Ansatz funktioniert sehr gut, wenn Sie versuchen, sowohl Fehlertoleranz als auch Verfügbarkeit sicherzustellen, indem Sie mehrere Replikate in jeder der verschiedenen Topologiedomänen verwenden. Pod-Anti-Affinitätsregeln können dagegen leicht zu Ergebnissen führen, wenn Sie ein einzelnes Replikat in einer Topologiedomäne haben, da die Pods mit einer Anti-Affinität zueinander eine abstoßende Wirkung haben. In solchen Fällen ist ein einzelnes Replikat auf einem dedizierten Knoten weder ideal für die Fehlertoleranz noch für eine sinnvolle Nutzung von Ressourcen. Mit Einschränkungen der Topologieverteilung haben Sie mehr Kontrolle über die Verteilung oder Verteilung, die der Scheduler auf die Topologiedomänen anwenden sollte. Hier sind einige wichtige Eigenschaften, die bei diesem Ansatz verwendet werden sollten:
-
Der
maxSkewwird verwendet, um den maximalen Punkt zu steuern oder zu bestimmen, bis zu dem die Dinge in den Topologiedomänen ungleichmäßig sein können. Wenn eine Anwendung beispielsweise über 10 Replikate verfügt und über 3 AZs bereitgestellt wird, können Sie keine gleichmäßige Verteilung erzielen, aber Sie können beeinflussen, wie ungleichmäßig die Verteilung sein wird. In diesem FallmaxSkewkann der Wert zwischen 1 und 10 liegen. Ein Wert von 1 bedeutet, dass Sie möglicherweise einen Spread wie4,3,33,4,3oder3,3,4über die 3 AZs hinweg haben können. Im Gegensatz dazu bedeutet ein Wert von 10, dass Sie am Ende möglicherweise einen Spread wie10,0,00,10,0oder0,0,10über 3 AZs haben können. -
Das
topologyKeyist ein Schlüssel für eine der Knotenbezeichnungen und definiert den Typ der Topologiedomäne, die für die Pod-Verteilung verwendet werden soll. Ein zonaler Spread hätte beispielsweise das folgende Schlüssel-Wert-Paar:topologyKey: "topology.kubernetes.io/zone" -
Die
whenUnsatisfiableEigenschaft wird verwendet, um zu bestimmen, wie der Scheduler reagieren soll, wenn die gewünschten Einschränkungen nicht erfüllt werden können. -
Die
labelSelectorwird verwendet, um passende Pods zu finden, sodass der Scheduler sie erkennen kann, wenn er entscheidet, wo Pods gemäß den von Ihnen angegebenen Einschränkungen platziert werden sollen.
Zusätzlich zu den oben genannten gibt es weitere Felder, über die Sie in der Kubernetes-Dokumentation
Die Einschränkungen der Pod-Topologie verteilen sich auf 3 AZs
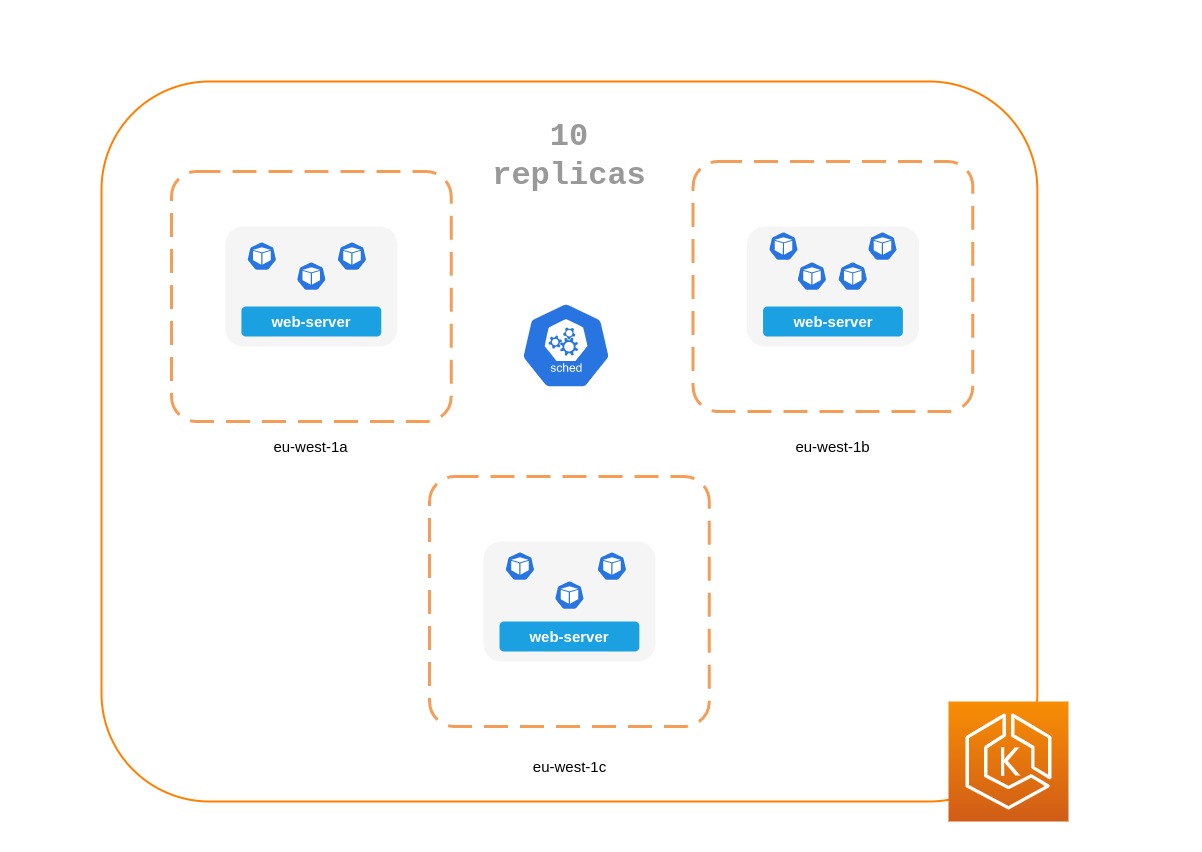
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 10 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test containers: - name: web-app image: nginx:1.16-alpine
Führen Sie den Kubernetes Metrics Server aus
Installieren Sie den Kubernetes Metrics Server, um Ihre Anwendungen
Der Metrik-Server speichert keine Daten und ist keine Überwachungslösung. Sein Zweck besteht darin, Metriken zur CPU- und Speichernutzung anderen Systemen zugänglich zu machen. Wenn Sie den Status Ihrer Anwendung im Laufe der Zeit verfolgen möchten, benötigen Sie ein Überwachungstool wie Prometheus oder Amazon. CloudWatch
Folgen Sie der EKS-Dokumentation, um den Metrics-Server in Ihrem EKS-Cluster zu installieren.
Horizontaler Pod-Autoscaler (HPA)
HPA kann Ihre Anwendung je nach Bedarf automatisch skalieren und Ihnen helfen, zu vermeiden, dass Ihre Kunden zu Spitzenzeiten beeinträchtigt werden. Es ist als Regelkreis in Kubernetes implementiert, der regelmäßig Metriken von APIs abfragt, die Ressourcenmetriken bereitstellen.
HPA kann Metriken von den folgenden APIs abrufen: 1. metrics.k8s.ioauch bekannt als Resource Metrics API — Stellt die CPU- und Speicherauslastung für Pods 2 bereit. custom.metrics.k8s.io — Stellt Metriken von anderen Metriksammlern wie Prometheus bereit. Diese Metriken sind intern in Ihrem Kubernetes-Cluster. 3. external.metrics.k8s.io — Stellt Metriken bereit, die sich außerhalb Ihres Kubernetes-Clusters befinden (E.g., SQS Queue Depth, ELB-Latenz).
Sie müssen eine dieser drei APIs verwenden, um die Metrik für die Skalierung Ihrer Anwendung bereitzustellen.
Skalierung von Anwendungen auf der Grundlage benutzerdefinierter oder externer Metriken
Sie können benutzerdefinierte oder externe Metriken verwenden, um Ihre Anwendung anhand anderer Messwerte als der CPU- oder Speicherauslastung zu skalieren. API-Server für benutzerdefinierte Metrikencustom-metrics.k8s.io API bereit, mit der HPA Anwendungen automatisch skalieren kann.
Sie können die Prometheus Adapter for Kubernetes Metrics APIs verwenden, um Metriken
Sobald Sie den Prometheus-Adapter bereitgestellt haben, können Sie benutzerdefinierte Metriken mit kubectl abfragen. kubectl get —raw /apis/custom.metrics.k8s.io/v1beta1/
Externe Metriken bieten, wie der Name schon sagt, dem Horizontal Pod Autoscaler die Möglichkeit, Bereitstellungen mithilfe von Metriken zu skalieren, die sich außerhalb des Kubernetes-Clusters befinden. Bei Workloads zur Stapelverarbeitung ist es beispielsweise üblich, die Anzahl der Replikate auf der Grundlage der Anzahl der laufenden Jobs in einer SQS-Warteschlange zu skalieren.
Um Kubernetes-Workloads automatisch zu skalieren, können Sie KEDA (Kubernetes Event-driven Autoscaling) verwenden, ein Open-Source-Projekt, das die Container-Skalierung auf der Grundlage einer Reihe von benutzerdefinierten Ereignissen vorantreiben kann. In diesem AWS-Blog
Vertikaler Pod-Autoscaler (VPA)
VPA passt die CPU- und Speicherreservierung für Ihre Pods automatisch an, damit Sie Ihre Anwendungen „richtig dimensionieren“ können. Für Anwendungen, die vertikal skaliert werden müssen — was durch Erhöhung der Ressourcenzuweisung erreicht wird — können Sie VPA
Ihre Anwendung ist möglicherweise vorübergehend nicht verfügbar, wenn VPA sie skalieren muss, da die aktuelle Implementierung von VPA keine direkten Anpassungen an Pods vornimmt. Stattdessen wird der Pod, der skaliert werden muss, neu erstellt.
Die EKS-Dokumentation enthält eine Anleitung zur Einrichtung von VPA.
Das Fairwinds Goldilocks-Projekt
Anwendungen aktualisieren
Moderne Anwendungen erfordern schnelle Innovationen mit einem hohen Maß an Stabilität und Verfügbarkeit. Kubernetes bietet Ihnen die Tools, mit denen Sie Ihre Anwendungen kontinuierlich aktualisieren können, ohne Ihre Kunden zu stören.
Schauen wir uns einige der Best Practices an, die es ermöglichen, Änderungen schnell umzusetzen, ohne die Verfügbarkeit zu beeinträchtigen.
Haben Sie einen Mechanismus zur Durchführung von Rollbacks
Mit einer Schaltfläche zum Rückgängigmachen können Katastrophen vermieden werden. Es hat sich bewährt, Bereitstellungen in einer separaten unteren Umgebung (Test- oder Entwicklungsumgebung) zu testen, bevor der Produktionscluster aktualisiert wird. Mithilfe einer CI/CD Pipeline können Sie Bereitstellungen automatisieren und testen. Mit einer kontinuierlichen Bereitstellungspipeline können Sie schnell zur älteren Version zurückkehren, falls das Upgrade defekt sein sollte.
Sie können Deployments verwenden, um eine laufende Anwendung zu aktualisieren. Dies erfolgt in der Regel durch die Aktualisierung des Container-Images. Sie können kubectl ein Deployment wie folgt aktualisieren:
kubectl --record deployment.apps/nginx-deployment set image nginx-deployment nginx=nginx:1.16.1
Das --record Argument zeichnet die Änderungen am Deployment auf und hilft Ihnen, wenn Sie ein Rollback durchführen müssen. kubectl rollout history deploymentzeigt Ihnen die aufgezeichneten Änderungen an Bereitstellungen in Ihrem Cluster. Sie können eine Änderung rückgängig machen mit. kubectl rollout undo deployment <DEPLOYMENT_NAME>
Wenn Sie ein Deployment aktualisieren, das eine Neuerstellung der Pods erfordert, führt Deployment standardmäßig ein fortlaufendes UpdateRollingUpdateStrategy
Wenn Sie ein fortlaufendes Update eines Deployments durchführen, können Sie die Max UnavailableMax Surge Eigenschaft Deployment können Sie die maximale Anzahl von Pods festlegen, die über die gewünschte Anzahl von Pods hinweg erstellt werden können.
Erwägen Sie Anpassungen, max unavailable um sicherzustellen, dass ein Rollout Ihre Kunden nicht stört. Kubernetes legt beispielsweise max unavailable standardmäßig 25% fest, was bedeutet, dass bei 100 Pods möglicherweise nur 75 Pods während eines Rollouts aktiv sind. Wenn Ihre Anwendung mindestens 80 Pods benötigt, kann dieser Rollout störend sein. Stattdessen können Sie einen Wert von 20% festlegenmax unavailable, um sicherzustellen, dass während des gesamten Rollouts mindestens 80 funktionsfähige Pods vorhanden sind.
Verwenden Sie Bereitstellungen blue/green
Änderungen sind von Natur aus riskant, aber Änderungen, die nicht rückgängig gemacht werden können, können potenziell katastrophal sein. Änderungsverfahren, mit denen Sie die Zeit durch ein Rollback effektiv zurückdrehen können, machen Verbesserungen und Experimente sicherer. Blue/green Bereitstellungen bieten Ihnen eine Methode, um die Änderungen schnell rückgängig zu machen, falls etwas schief geht. In dieser Bereitstellungsstrategie erstellen Sie eine Umgebung für die neue Version. Diese Umgebung ist identisch mit der aktuellen Version der Anwendung, die aktualisiert wird. Sobald die neue Umgebung bereitgestellt ist, wird der Datenverkehr an die neue Umgebung weitergeleitet. Wenn die neue Version die gewünschten Ergebnisse liefert, ohne Fehler zu generieren, wird die alte Umgebung beendet. Andernfalls wird der Verkehr auf die alte Version zurückgesetzt.
Sie können blue/green Bereitstellungen in Kubernetes durchführen, indem Sie ein neues Deployment erstellen, das mit dem Deployment der vorhandenen Version identisch ist. Sobald Sie sichergestellt haben, dass die Pods im neuen Deployment fehlerfrei ausgeführt werden, können Sie damit beginnen, Traffic an das neue Deployment zu senden, indem Sie die selector Spezifikation im Service ändern, der den Datenverkehr an die Pods Ihrer Anwendung weiterleitet.
Mit vielen Tools für die kontinuierliche Integration wie Flux
Verwenden Sie kanarische Bereitstellungen
Bei Bereitstellungen auf Kanaren handelt es sich um eine Variante von blue/green Bereitstellungen, mit denen das Risiko von Änderungen erheblich verringert werden kann. Bei dieser Bereitstellungsstrategie erstellen Sie ein neues Deployment mit weniger Pods neben Ihrem alten Deployment und leiten einen kleinen Teil des Traffics auf das neue Deployment um. Wenn die Messwerte darauf hindeuten, dass die neue Version genauso gut oder besser funktioniert als die bestehende Version, erhöhen Sie den Traffic zur neuen Bereitstellung schrittweise und skalieren sie gleichzeitig, bis der gesamte Datenverkehr auf die neue Bereitstellung umgeleitet wird. Wenn ein Problem auftritt, können Sie den gesamten Datenverkehr an das alte Deployment weiterleiten und das Senden von Traffic an das neue Deployment beenden.
Kubernetes bietet zwar keine native Möglichkeit, kanarische Bereitstellungen durchzuführen, aber Sie können Tools wie Flagger
Gesundheitschecks und Selbstheilung
Keine Software ist fehlerfrei, aber Kubernetes kann Ihnen helfen, die Auswirkungen von Softwareausfällen zu minimieren. In der Vergangenheit musste jemand, wenn eine Anwendung abstürzte, die Situation beheben, indem er die Anwendung manuell neu startete. Kubernetes bietet Ihnen die Möglichkeit, Softwarefehler in Ihren Pods zu erkennen und sie automatisch durch neue Replikate zu ersetzen. Mit Kubernetes können Sie den Zustand Ihrer Anwendungen überwachen und fehlerhafte Instanzen automatisch ersetzen.
Kubernetes unterstützt drei Arten von Zustandsprüfungen:
-
Lebendigkeitstest
-
Startprobe (unterstützt in Kubernetes Version 1.16+)
-
Bereitschaftstest
Kubelet
Wenn Sie sich für eine exec basierte Probe entscheiden, die ein Shell-Skript in einem Container ausführt, stellen Sie sicher, dass der Shell-Befehl beendet wird, bevor der Wert abläuft. timeoutSeconds Andernfalls wird Ihr Knoten über <defunct> Prozesse verfügen, was zu einem Ausfall des Knotens führt.
Empfehlungen
Verwenden Sie Liveness Probe, um ungesunde Pods zu entfernen
Der Liveness Test kann Deadlock-Bedingungen erkennen, bei denen der Prozess zwar weiter ausgeführt wird, die Anwendung aber nicht mehr reagiert. Wenn Sie beispielsweise einen Webdienst ausführen, der Port 80 überwacht, können Sie einen Liveness-Test so konfigurieren, dass er eine HTTP-GET-Anforderung an den Port 80 des Pods sendet. Kubelet sendet regelmäßig eine GET-Anfrage an den Pod und erwartet eine Antwort. Wenn der Pod zwischen 200 und 399 antwortet, geht das Kubelet davon aus, dass der Pod fehlerfrei ist. Andernfalls wird der Pod als fehlerhaft markiert. Wenn ein Pod die Integritätsprüfungen kontinuierlich nicht besteht, wird er vom Kubelet beendet.
Sie können es verwenden, initialDelaySeconds um die erste Sonde zu verzögern.
Wenn Sie die Liveness Probe verwenden, stellen Sie sicher, dass Ihre Anwendung nicht in eine Situation gerät, in der alle Pods gleichzeitig die Liveness Probe nicht bestehen, da Kubernetes versucht, alle Ihre Pods zu ersetzen, wodurch Ihre Anwendung offline geschaltet wird. Darüber hinaus wird Kubernetes weiterhin neue Pods erstellen, bei denen auch die Liveness Probes nicht funktionieren, was die Kontrollebene unnötig belastet. Vermeiden Sie es, die Liveness Probe so zu konfigurieren, dass sie von einem Faktor abhängt, der sich außerhalb Ihres Pods befindet, z. B. von einer externen Datenbank. Mit anderen Worten: Eine nicht reagierende External-to-your-Pod-Datenbank sollte nicht dazu führen, dass Ihre Pods ihre Liveness Probes nicht bestehen.
Der Beitrag LIVENESS PROBES ARE DANGEROUS von Sandor Szücs beschreibt Probleme, die durch falsch konfigurierte Sonden verursacht
Verwenden Sie Startup Probe für Anwendungen, deren Start länger dauert
Wenn Ihre App zusätzliche Zeit zum Starten benötigt, können Sie die Startup Probe verwenden, um den Liveness and Readiness Test zu verzögern. Beispielsweise kann eine Java-App, die den Cache aus einer Datenbank hydratisieren muss, bis zu zwei Minuten dauern, bis sie voll funktionsfähig ist. Jede Liveness- oder Readiness Probe kann fehlschlagen, bis sie voll funktionsfähig ist. Durch die Konfiguration einer Startup Probe kann die Java-App wieder funktionsfähig sein, bevor Liveness oder Readiness Probe ausgeführt werden.
Bis die Startup Probe erfolgreich ist, sind alle anderen Probes deaktiviert. Sie können festlegen, wie lange Kubernetes maximal auf den Start der Anwendung warten soll. Wenn der Pod nach der konfigurierten Höchstzeit die Startup Probes immer noch nicht bestanden hat, wird er beendet und ein neuer Pod wird erstellt.
Die Startup Probe ähnelt der Liveness Probe — wenn sie fehlschlagen, wird der Pod neu erstellt. Wie Ricardo A. in seinem Beitrag Fantastic Probes And How To Configure TheminitialDelaySeconds
Verwenden Sie Readiness Probe, um eine teilweise Nichtverfügbarkeit zu erkennen
Während der Liveness Test Fehler in einer App erkennt, die durch das Beenden des Pods (also durch einen Neustart der App) behoben werden, erkennt Readiness Probe Situationen, in denen die App möglicherweise vorübergehend nicht verfügbar ist. In diesen Situationen reagiert die App möglicherweise vorübergehend nicht mehr. Es wird jedoch davon ausgegangen, dass sie wieder fehlerfrei ist, sobald dieser Vorgang abgeschlossen ist.
Beispielsweise können Anwendungen während intensiver I/O Festplattenoperationen vorübergehend nicht zur Bearbeitung von Anfragen zur Verfügung stehen. In diesem Fall ist das Beenden des Pods der Anwendung keine Lösung. Gleichzeitig können zusätzliche Anfragen, die an den Pod gesendet werden, fehlschlagen.
Sie können die Readiness Probe verwenden, um eine vorübergehende Nichtverfügbarkeit in Ihrer App zu erkennen und das Senden von Anfragen an den zugehörigen Pod zu beenden, bis dieser wieder funktionsfähig ist. Im Gegensatz zu Liveness Probe, bei der ein Ausfall zur Neuerstellung des Pods führen würde, würde ein fehlgeschlagener Readiness Probe bedeuten, dass der Pod keinen Traffic vom Kubernetes-Service empfängt. Wenn die Readiness Probe erfolgreich ist, empfängt der Pod wieder Datenverkehr vom Service.
Vermeiden Sie es, genau wie bei der Liveness Probe, Readiness Probes zu konfigurieren, die von einer externen Ressource des Pods abhängen (z. B. einer Datenbank). Hier ist ein Szenario, in dem eine schlecht konfigurierte Readiness dazu führen kann, dass die Anwendung nicht mehr funktioniert. Wenn die Readiness Probe eines Pods fehlschlägt, obwohl die Datenbank der App nicht erreichbar ist, fallen auch andere Pod-Replikate gleichzeitig aus, da sie dieselben Integritätsprüfkriterien verwenden. Wenn Sie den Test auf diese Weise einrichten, wird sichergestellt, dass die Readiness Probes des Pods immer dann fehlschlagen, wenn die Datenbank nicht verfügbar ist, und Kubernetes den Datenverkehr an alle Pods nicht mehr sendet.
Ein Nebeneffekt der Verwendung von Readiness Probes besteht darin, dass sie die für die Aktualisierung von Bereitstellungen benötigte Zeit verlängern können. Neue Replikate empfangen keinen Datenverkehr, es sei denn, die Readiness Probes sind erfolgreich. Bis dahin empfangen alte Replikate weiterhin Datenverkehr.
Umgang mit Störungen
Pods haben eine begrenzte Lebensdauer. Selbst wenn Sie Pods mit langer Laufzeit haben, sollten Sie sicherstellen, dass die Pods zu gegebener Zeit korrekt beendet werden. Abhängig von Ihrer Upgrade-Strategie müssen Sie bei Kubernetes-Cluster-Upgrades möglicherweise neue Worker-Knoten erstellen. Dazu müssen alle Pods auf neueren Knoten neu erstellt werden. Durch die richtige Bearbeitung von Terminierungen und Budgets für Pod-Unterbrechungen können Sie Serviceunterbrechungen vermeiden, da Pods aus älteren Knoten entfernt und auf neueren Knoten neu erstellt werden.
Die bevorzugte Methode zur Aktualisierung von Worker-Knoten besteht darin, neue Worker-Knoten zu erstellen und alte zu beenden. Bevor Sie Worker-Knoten beenden, sollten drain Sie dies tun. Wenn ein Worker-Knoten leer ist, werden alle seine Pods sicher entfernt. Sicher ist hier ein Schlüsselwort. Wenn Pods auf einem Worker geräumt werden, wird ihnen nicht einfach ein Signal gesendet. SIGKILL Stattdessen wird ein SIGTERM Signal an den Hauptprozess (PID 1) jedes Containers in den Pods gesendet, der geräumt wird. Nachdem das SIGTERM Signal gesendet wurde, gibt Kubernetes dem Prozess eine gewisse Zeit (Gnadenfrist), bevor ein SIGKILL Signal gesendet wird. Diese Übergangszeit beträgt standardmäßig 30 Sekunden. Sie können die Standardeinstellung überschreiben, indem Sie grace-period flag in kubectl verwenden oder in Ihrer Podspec deklarierenterminationGracePeriodSeconds.
kubectl delete pod <pod name> —grace-period=<seconds>
Es ist üblich, Container zu haben, in denen der Hauptprozess nicht die PID 1 hat. Stellen Sie sich diesen Python-based Probenbehälter vor:
$ kubectl exec python-app -it ps PID USER TIME COMMAND 1 root 0:00 {script.sh} /bin/sh ./script.sh 5 root 0:00 python app.py
In diesem Beispiel empfängt das Shell-SkriptSIGTERM, der Hauptprozess, der in diesem Beispiel zufällig eine Python-Anwendung ist, erhält kein SIGTERM Signal. Wenn der Pod beendet wird, wird die Python-Anwendung abrupt beendet. Dies kann behoben werden, indem der ENTRYPOINT
Sie können Container-HooksPreStop Hook-Aktion wird ausgeführt, bevor der Container ein SIGTERM Signal empfängt, und muss abgeschlossen sein, bevor dieses Signal gesendet wird. Der terminationGracePeriodSeconds Wert gilt ab dem Zeitpunkt, zu dem die PreStop Hook-Aktion ausgeführt wird, nicht ab dem Zeitpunkt, zu dem das SIGTERM Signal gesendet wird.
Empfehlungen
Schützen Sie kritische Workloads mit Pod Disruption Budgets
Pod Disruption Budget oder PDB können den Räumungsprozess vorübergehend unterbrechen, wenn die Anzahl der Replikate einer Anwendung unter den angegebenen Schwellenwert fällt. Der Räumungsprozess wird fortgesetzt, sobald die Anzahl der verfügbaren Replikate den Schwellenwert überschreitet. Sie können PDB verwenden, um die Anzahl minAvailable und maxUnavailable Anzahl der Replikate zu deklarieren. Wenn Sie beispielsweise möchten, dass mindestens drei Kopien Ihrer App verfügbar sind, können Sie eine PDB erstellen.
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: my-svc-pdb spec: minAvailable: 3 selector: matchLabels: app: my-svc
Die obige PDB-Richtlinie weist Kubernetes an, den Räumungsprozess anzuhalten, bis drei oder mehr Replikate verfügbar sind. Das PodDisruptionBudgets Entleeren von Knoten wird respektiert. Während eines Upgrades einer verwalteten EKS-Knotengruppe werden die Knoten mit einem Zeitlimit von fünfzehn Minuten entlastet. Wenn das Update nach fünfzehn Minuten nicht erzwungen wird (die Option wird in der EKS-Konsole als fortlaufendes Update bezeichnet), schlägt das Update fehl. Wenn das Update erzwungen wird, werden die Pods gelöscht.
Für selbstverwaltete Knoten können Sie auch Tools wie AWS Node Termination Handler
Sie können Pod-Anti-Affinität verwenden, um die Pods eines Deployments auf verschiedenen Knoten zu planen und PDB-bedingte Verzögerungen bei Knoten-Upgrades zu vermeiden.
Üben Sie sich in Chaos Engineering
Chaos Engineering ist die Disziplin des Experimentierens an einem verteilten System, um Vertrauen in die Fähigkeit des Systems aufzubauen, turbulenten Produktionsbedingungen standzuhalten.
In seinem Blog erklärt Dominik Tornow, dass Kubernetes ein deklaratives System ist, bei dem "der Benutzer dem Systemreplica Absturz eine neuereplica Auf diese Weise beheben Kubernetes-Controller Fehler automatisch.
Chaos-Engineering-Tools wie Gremlin
Verwenden Sie ein Service Mesh
Sie können ein Service Mesh verwenden, um die Ausfallsicherheit Ihrer Anwendung zu verbessern. Service Meshes ermöglichen die Kommunikation zwischen Diensten und erhöhen die Beobachtbarkeit Ihres Microservices-Netzwerks. Die meisten Service Mesh-Produkte funktionieren so, dass neben jedem Dienst ein kleiner Netzwerk-Proxy läuft, der den Netzwerkverkehr der Anwendung abfängt und überprüft. Sie können Ihre Anwendung in einem Mesh platzieren, ohne Ihre Anwendung zu ändern. Mithilfe der integrierten Funktionen des Service-Proxys können Sie Netzwerkstatistiken generieren, Zugriffsprotokolle erstellen und ausgehenden Anfragen HTTP-Header für die verteilte Ablaufverfolgung hinzufügen.
Ein Service Mesh kann Ihnen dabei helfen, Ihre Microservices mit Funktionen wie automatischen Wiederholungen von Anfragen, Timeouts, Unterbrechungen und Ratenbegrenzung widerstandsfähiger zu machen.
Wenn Sie mehrere Cluster betreiben, können Sie ein Service Mesh verwenden, um eine clusterübergreifende Service-to-Service-Kommunikation zu ermöglichen.
Service Meshes
Beobachtbarkeit
Observability ist ein Überbegriff, der Überwachung, Protokollierung und Rückverfolgung umfasst. Anwendungen, die auf Microservices basieren, werden von Natur aus vertrieben. Im Gegensatz zu monolithischen Anwendungen, bei denen die Überwachung eines einzelnen Systems ausreicht, müssen Sie in einer verteilten Anwendungsarchitektur die Leistung der einzelnen Komponenten überwachen. Sie können Überwachungs-, Protokollierungs- und verteilte Ablaufverfolgungssysteme auf Clusterebene verwenden, um Probleme in Ihrem Cluster zu identifizieren, bevor sie Ihre Kunden stören.
Die in Kubernetes integrierten Tools zur Fehlerbehebung und Überwachung sind begrenzt. Der Metrics-Server sammelt Ressourcenmetriken und speichert sie im Speicher, speichert sie aber nicht dauerhaft. Sie können die Logs eines Pods mit kubectl einsehen, aber Kubernetes speichert Logs nicht automatisch. Und die Implementierung der verteilten Ablaufverfolgung erfolgt entweder auf der Ebene des Anwendungscodes oder mithilfe von Services-Meshes.
Die Erweiterbarkeit von Kubernetes kommt hier besonders gut zur Geltung. Mit Kubernetes können Sie Ihre bevorzugte zentralisierte Überwachungs-, Protokollierungs- und Tracing-Lösung einsetzen.
Empfehlungen
Überwachen Sie Ihre Anwendungen
Die Anzahl der Metriken, die Sie in modernen Anwendungen überwachen müssen, wächst kontinuierlich. Es ist hilfreich, wenn Sie Ihre Anwendungen automatisiert verfolgen können, sodass Sie sich darauf konzentrieren können, die Herausforderungen Ihrer Kunden zu lösen. Cluster-wide Monitoring-Tools wie Prometheus
Mit Überwachungstools können Sie Warnmeldungen erstellen, die Ihr Betriebsteam abonnieren kann. Erwägen Sie Regeln zur Aktivierung von Alarmen für Ereignisse, die, wenn sie sich verschärfen, zu einem Ausfall führen oder die Anwendungsleistung beeinträchtigen können.
Wenn Sie sich nicht sicher sind, welche Kennzahlen Sie überwachen sollten, können Sie sich von diesen Methoden inspirieren lassen:
-
RED-Methode
. Steht für Anfragen, Fehler und Dauer. -
USE-Methode
. Steht für Auslastung, Sättigung und Fehler.
Der Beitrag Best Practices for Alerting on Kubernetes
Verwenden Sie die Prometheus-Clientbibliothek, um Anwendungsmetriken bereitzustellen
Neben der Überwachung des Status der Anwendung und der Aggregation von Standardmetriken können Sie auch die Prometheus-Clientbibliothek
Verwenden Sie zentralisierte Protokollierungstools, um Protokolle zu sammeln und zu speichern
Die Protokollierung in EKS lässt sich in zwei Kategorien einteilen: Protokolle der Steuerungsebene und Anwendungsprotokolle. Die Protokollierung auf der EKS-Kontrollebene stellt Prüf- und Diagnoseprotokolle direkt von der Steuerungsebene in die CloudWatch Protokolle in Ihrem Konto bereit. Anwendungsprotokolle sind Protokolle, die von Pods erstellt werden, die in Ihrem Cluster ausgeführt werden. Zu den Anwendungsprotokollen gehören Protokolle, die von Pods erstellt wurden, auf denen die Geschäftslogikanwendungen und Kubernetes-Systemkomponenten wie CoreDNS, Cluster Autoscaler, Prometheus usw. ausgeführt werden.
EKS bietet fünf Arten von Protokollen auf der Kontrollebene:
-
Protokolle der Kubernetes-API-Serverkomponenten
-
Audit
-
Authentifikator
-
Leiter des Controllers
-
Scheduler
Die Controller-Manager- und Scheduler-Protokolle können bei der Diagnose von Problemen mit der Steuerungsebene wie Engpässen und Fehlern helfen. Standardmäßig werden die Protokolle der EKS-Steuerungsebene nicht an Logs gesendet. CloudWatch Sie können die Protokollierung der Kontrollebene aktivieren und die Arten von Protokollen der EKS-Kontrollebene auswählen, die Sie für jeden Cluster in Ihrem Konto erfassen möchten
Das Sammeln von Anwendungsprotokollen erfordert die Installation eines Protokollaggregator-Tools wie Fluent Bit
Die Log-Aggregator-Tools von Kubernetes werden als DaemonSets Knoten ausgeführt und entfernen Container-Logs von Knoten. Anwendungsprotokolle werden dann zur Speicherung an ein zentrales Ziel gesendet. CloudWatch Container Insights kann beispielsweise entweder Fluent Bit oder Fluentd verwenden, um Protokolle zu sammeln und sie zur Speicherung an CloudWatch Logs zu senden. Fluent Bit und Fluentd unterstützen viele beliebte Protokollanalysesysteme wie Elasticsearch und InfluxDB, sodass Sie das Speicher-Backend für Ihre Logs ändern können, indem Sie Fluent Bit oder die Log-Konfiguration von Fluentd ändern.
Verwenden Sie ein verteiltes Tracing-System, um Engpässe zu identifizieren
Eine typische moderne Anwendung besteht aus Komponenten, die über das Netzwerk verteilt sind, und ihre Zuverlässigkeit hängt vom ordnungsgemäßen Funktionieren der einzelnen Komponenten ab, aus denen die Anwendung besteht. Sie können eine verteilte Ablaufverfolgungslösung verwenden, um zu verstehen, wie Anfragen fließen und wie Systeme kommunizieren. Mithilfe von Ablaufverfolgungen können Sie erkennen, wo in Ihrem Anwendungsnetzwerk Engpässe bestehen, und Probleme verhindern, die zu kaskadierenden Ausfällen führen können.
Sie haben zwei Möglichkeiten, die Ablaufverfolgung in Ihren Anwendungen zu implementieren: Sie können entweder die verteilte Ablaufverfolgung auf Codeebene mithilfe gemeinsam genutzter Bibliotheken implementieren oder ein Service Mesh verwenden.
Die Implementierung von Tracing auf Codeebene kann nachteilig sein. Bei dieser Methode müssen Sie Änderungen an Ihrem Code vornehmen. Dies ist noch komplizierter, wenn Sie mehrsprachige Anwendungen haben. Sie sind auch für die Verwaltung einer weiteren Bibliothek in all Ihren Diensten verantwortlich.
Service Meshes wie LinkerD
Tracing-Tools wie AWS X-Ray
Erwägen Sie, ein Tracing-Tool wie AWS X-Ray
