Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migration von Couchbase Server
Einführung
In diesem Handbuch werden die wichtigsten Punkte vorgestellt, die bei der Migration von Couchbase Server zu Amazon DocumentDB zu beachten sind. Es werden Überlegungen zu den Ermittlungs-, Planungs-, Ausführungs- und Validierungsphasen Ihrer Migration erläutert. Außerdem wird erklärt, wie Sie Offline- und Online-Migrationen durchführen.
Vergleich mit Amazon DocumentDB
| Couchbase-Server | Amazon DocumentDB | |
|---|---|---|
| Organisation der Daten | In den Versionen 7.0 und höher sind Daten in Buckets, Bereichen und Sammlungen organisiert. In früheren Versionen wurden Daten in Buckets organisiert. | Daten sind in Datenbanken und Sammlungen organisiert. |
| Kompatibilität | APIs Für jeden Dienst (z. B. Daten, Index, Suche usw.) gibt es separate. Sekundäre Suchvorgänge verwenden SQL++ (früher bekannt als N1QL), eine Abfragesprache, die auf dem ANSI-Standard-SQL basiert und daher vielen Entwicklern vertraut ist. | Amazon DocumentDB ist mit der MongoDB-API kompatibel. |
| Architektur | Jeder Cluster-Instance ist Speicher zugeordnet. Sie können die Rechenleistung nicht unabhängig vom Speicher skalieren. | Amazon DocumentDB wurde für die Cloud entwickelt und vermeidet die Einschränkungen herkömmlicher Datenbankarchitekturen. Die Rechen- und Speicherebene sind in Amazon DocumentDB getrennt, und die Rechenschicht kann unabhängig vom Speicher skaliert werden. |
| Fügen Sie bei Bedarf Lesekapazität hinzu | Cluster können durch Hinzufügen von Instanzen skaliert werden. Da der Speicher an die Instanz angehängt wird, auf der der Dienst ausgeführt wird, hängt die Zeit, die für die Skalierung benötigt wird, von der Datenmenge ab, die auf die neue Instanz verschoben oder neu verteilt werden muss. | Sie können die Leseskalierung für Ihren Amazon DocumentDB-Cluster erreichen, indem Sie bis zu 15 Amazon DocumentDB DocumentDB-Replikate im Cluster erstellen. Es hat keine Auswirkungen auf die Speicherebene. |
| Schnelle Wiederherstellung nach einem Knotenausfall | Cluster verfügen über automatische Failover-Funktionen, aber die Zeit, bis der Cluster wieder voll funktionsfähig ist, hängt von der Datenmenge ab, die auf die neue Instanz verschoben werden muss. | Amazon DocumentDB kann in der Regel innerhalb von 30 Sekunden ein Failover auf den Primärserver durchführen und den Cluster innerhalb von 8 bis 10 Minuten wieder auf volle Stärke zurücksetzen, unabhängig von der Datenmenge im Cluster. |
| Skalieren Sie den Speicher, wenn die Datenmenge wächst | Für selbstverwaltete Cluster als Speicher und IOs nicht automatische Skalierung. | Automatische Speicherung und IOs Skalierung von Amazon DocumentDB. |
| Daten Backup, ohne die Leistung zu beeinträchtigen | Backups werden vom Backup-Dienst durchgeführt und sind standardmäßig nicht aktiviert. Da Speicher und Datenverarbeitung nicht getrennt sind, kann dies Auswirkungen auf die Leistung haben. | Amazon DocumentDB-Backups sind standardmäßig aktiviert und können nicht deaktiviert werden. Backups werden von der Speicherebene verwaltet, sodass sie keine Auswirkungen auf die Rechenebene haben. Amazon DocumentDB unterstützt die Wiederherstellung aus einem Cluster-Snapshot und die Wiederherstellung zu einem bestimmten Zeitpunkt. |
| Haltbarkeit der Daten | In einem Cluster können maximal 3 Replikatkopien von Daten vorhanden sein, also insgesamt 4 Kopien. Für jede Instanz, in der der Datendienst ausgeführt wird, sind 1, 2 oder 3 Replikatkopien der Daten aktiv. | Amazon DocumentDB verwaltet unabhängig von der Anzahl der Recheninstanzen 6 Kopien von Daten mit einem Schreibquorum von 4 und persist true. Kunden erhalten eine Bestätigung, nachdem die Speicherebene 4 Kopien der Daten gespeichert hat. |
| Konsistenz | Sofortige Konsistenz der K/V Abläufe wird unterstützt. Das Couchbase SDK leitet K/V Anfragen an die spezifische Instanz weiter, die die aktive Kopie der Daten enthält. Sobald ein Update bestätigt wurde, kann der Client dieses Update garantiert lesen. Die Replikation von Updates auf andere Dienste (Index, Suche, Analytik, Eventing) ist letztlich konsistent. | Amazon DocumentDB DocumentDB-Replikate sind letztendlich konsistent. Wenn sofortige Konsistenzlesevorgänge erforderlich sind, kann der Client von der primären Instance aus lesen. |
| Replikation | Cross-Data Center Replication (XDCR) ermöglicht eine gefilterte, aktiv-passive/aktiv-aktive Replikation von Daten in vielen Topologien. | Globale Amazon DocumentDB-Cluster bieten Aktiv-Passiv-Replikation in 1:many (bis zu 10) Topologien. |
Erkennung
Die Migration zu Amazon DocumentDB erfordert ein gründliches Verständnis der bestehenden Datenbank-Arbeitslast. Bei der Workload-Erkennung werden Ihre Couchbase-Cluster-Konfiguration und die Betriebsmerkmale — Datensatz, Indizes und Arbeitslast — analysiert, um einen reibungslosen Übergang mit minimalen Unterbrechungen zu gewährleisten.
Cluster-Konfiguration
Couchbase verwendet eine serviceorientierte Architektur, bei der jede Funktion einem Dienst entspricht. Führen Sie den folgenden Befehl für Ihren Couchbase-Cluster aus, um festzustellen, welche Dienste verwendet werden (siehe Informationen zu Knoten abrufen
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
Beispielausgabe:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Die Couchbase-Dienste umfassen Folgendes:
Datendienst (kv)
Der Datendienst ermöglicht read/write den Zugriff auf Daten im Speicher und auf der Festplatte.
Amazon DocumentDB unterstützt K/V Operationen mit JSON-Daten über die MongoDB-API.
Abfragedienst (n1ql)
Der Abfragedienst unterstützt das Abfragen von JSON-Daten über SQL++.
Amazon DocumentDB unterstützt die Abfrage von JSON-Daten über die MongoDB-API.
Indexdienst (Index)
Der Indexdienst erstellt und verwaltet Indizes für Daten und ermöglicht so eine schnellere Abfrage.
Amazon DocumentDB unterstützt einen Standard-Primärindex und die Erstellung von Sekundärindizes für JSON-Daten über die MongoDB-API.
Suchdienst (fts)
Der Suchdienst unterstützt die Erstellung von Indizes für die Volltextsuche.
Mit der nativen Volltextsuchfunktion von Amazon DocumentDB können Sie mithilfe von speziellen Textindizes über die MongoDB-API eine Textsuche in großen Textdatensätzen durchführen. Für erweiterte Suchanwendungsfälle bietet die Amazon DocumentDB Zero-ETL-Integration mit Amazon OpenSearch Service
Analysedienst (CBAS)
Der Analysedienst unterstützt die Analyse von JSON-Daten nahezu in Echtzeit.
Amazon DocumentDB unterstützt Ad-hoc-Abfragen von JSON-Daten über die MongoDB-API. Sie können mit Apache Spark, der auf Amazon EMR läuft, auch komplexe Abfragen für Ihre JSON-Daten in Amazon DocumentDB ausführen
Veranstaltungsservice (Eventing)
Der Eventing-Dienst führt als Reaktion auf Datenänderungen eine benutzerdefinierte Geschäftslogik aus.
Amazon DocumentDB automatisiert ereignisgesteuerte Workloads, indem es jedes Mal AWS Lambda Funktionen aufruft, wenn sich Daten mit Ihrem Amazon DocumentDB-Cluster ändern.
Backup-Dienst (Backup)
Der Backup-Service plant vollständige und inkrementelle Datensicherungen und Zusammenführungen früherer Datensicherungen.
Amazon DocumentDB sichert Ihre Daten kontinuierlich auf Amazon S3 mit einer Aufbewahrungsdauer von 1—35 Tagen, sodass Sie innerhalb des Aufbewahrungszeitraums für Backups an jedem beliebigen Punkt schnell wiederherstellen können. Amazon DocumentDB erstellt im Rahmen dieses kontinuierlichen Backup-Prozesses auch automatische Schnappschüsse Ihrer Daten. Sie können auch die Sicherung und Wiederherstellung von Amazon DocumentDB mit AWS Backup verwalten
Betriebliche Eigenschaften
Verwenden Sie das Discovery Tool for Couchbase
Dataset
Das Tool ruft die folgenden Bucket-, Bereichs- und Sammlungsinformationen ab:
Bucket-Name
Bucket-Typ
Name des Bereichs
Name der Sammlung
Gesamtgröße (Byte)
Gesamtzahl der Artikel
Artikelgröße (Byte)
Indizes
Das Tool ruft die folgenden Indexstatistiken und alle Indexdefinitionen für alle Buckets ab. Beachten Sie, dass Primärindizes ausgeschlossen sind, da Amazon DocumentDB automatisch einen Primärindex für jede Sammlung erstellt.
Bucket-Name
Name des Bereichs
Name der Sammlung
Indexname
Indexgröße (Byte)
Workload
Das Tool ruft Metriken ab K/V und fragt N1QL ab. K/V Metrikwerte werden auf Bucket-Ebene und SQL++-Metriken auf Cluster-Ebene gesammelt.
Die Befehlszeilenoptionen des Tools lauten wie folgt:
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
Hier sehen Sie ein Beispiel für einen Befehl.
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
Die K/V-Metrikwerte werden auf Stichproben basieren, die in der letzten Woche alle 10 Minuten abgerufen wurden (siehe HTTP-Methode und URI
collection-stats.csv — Informationen zu Bereich, Umfang und Sammlung
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv — Indexnamen und -größen
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv — Metriken für alle Buckets abrufen, festlegen und löschen
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv — SQL++ wählt Metriken für den Cluster aus, löscht sie und fügt sie ein
selects,deletes,inserts 0,132,87
indexes- .txt <bucket-name>— Indexdefinitionen aller Indizes im Bucket. Beachten Sie, dass Primärindizes ausgeschlossen sind, da Amazon DocumentDB automatisch einen Primärindex für jede Sammlung erstellt.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
Planung
In der Planungsphase legen Sie die Anforderungen an den Amazon DocumentDB-Cluster und die Zuordnung der Couchbase-Buckets, -Bereiche und -Sammlungen zu Amazon DocumentDB DocumentDB-Datenbanken und -Sammlungen fest.
Anforderungen für Amazon DocumentDB-Cluster
Verwenden Sie die in der Ermittlungsphase gesammelten Daten, um die Größe Ihres Amazon DocumentDB-Clusters zu bestimmen. Weitere Informationen zur Dimensionierung Ihres Amazon DocumentDB-Clusters finden Sie unter Instance-Größe.
Zuordnung von Buckets, Bereichen und Sammlungen zu Datenbanken und Sammlungen
Ermitteln Sie die Datenbanken und Sammlungen, die in Ihren Amazon DocumentDB-Clustern vorhanden sein werden. Ziehen Sie die folgenden Optionen in Betracht, je nachdem, wie die Daten in Ihrem Couchbase-Cluster organisiert sind. Dies sind nicht die einzigen Optionen, aber sie bieten Ausgangspunkte, die Sie in Betracht ziehen sollten.
Couchbase Server 6.x oder früher
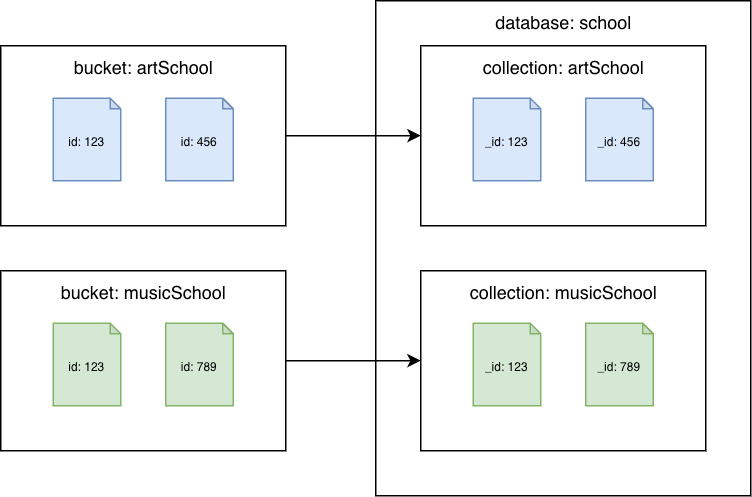
Couchbase-Buckets zu Amazon DocumentDB-Sammlungen
Migrieren Sie jeden Bucket in eine andere Amazon DocumentDB-Sammlung. In diesem Szenario wird der id Couchbase-Dokumentwert als Amazon DocumentDB _id DocumentDB-Wert verwendet.
Couchbase Server 7.0 oder höher
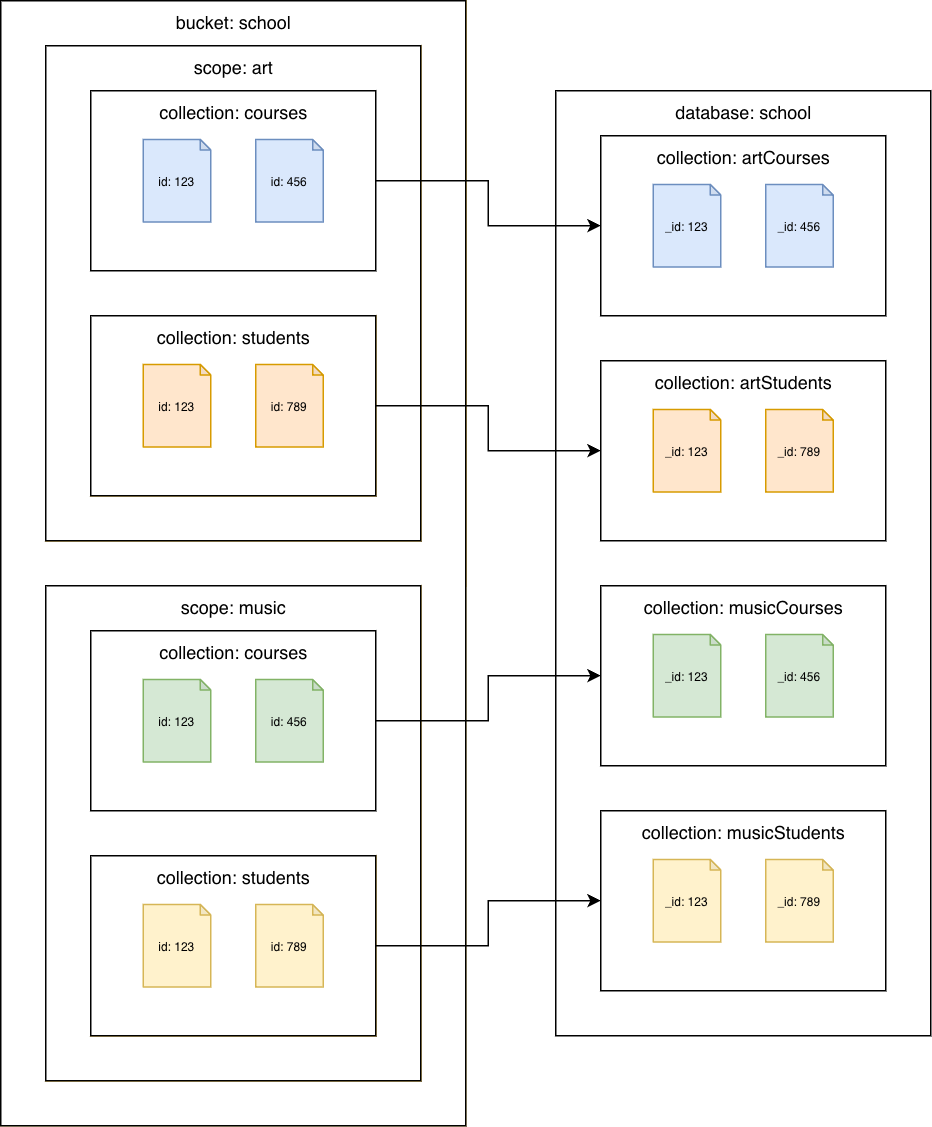
Couchbase-Sammlungen zu Amazon DocumentDB-Sammlungen
Migrieren Sie jede Sammlung zu einer anderen Amazon DocumentDB-Sammlung. In diesem Szenario wird der id Couchbase-Dokumentwert als Amazon DocumentDB _id DocumentDB-Wert verwendet.
Migration
Indexmigration
Bei der Migration zu Amazon DocumentDB werden nicht nur Daten, sondern auch Indizes übertragen, um die Abfrageleistung aufrechtzuerhalten und den Datenbankbetrieb zu optimieren. In diesem Abschnitt wird der detaillierte step-by-step Prozess für die Migration von Indizes zu Amazon DocumentDB beschrieben, wobei Kompatibilität und Effizienz gewährleistet werden.
Verwenden Sie Amazon Q, um CREATE INDEX SQL++-Anweisungen in Amazon DocumentDB DocumentDB-Befehle createIndex() zu konvertieren.
Laden Sie die Index-.txt-Datei <bucket name>(en) hoch, die mit dem Discovery Tool for Couchbase erstellt wurden.
Geben Sie die folgende Aufforderung ein:
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q generiert entsprechende Amazon DocumentDB createIndex() DocumentDB-Befehle. Beachten Sie, dass Sie die Sammlungsnamen möglicherweise aktualisieren müssen, je nachdem, wie Sie die Couchbase-Buckets, Bereiche und Sammlungen Amazon DocumentDB-Sammlungen zugeordnet haben.
Beispiel:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Beispiel für eine Amazon Q-Ausgabe (Auszug):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Weitere Informationen zu Indizes, die Amazon Q nicht konvertieren kann, finden Sie unter Amazon DocumentDB DocumentDB-Indizes verwalten und Indizes und Indexeigenschaften.
Code umgestalten, um die MongoDB zu verwenden APIs
Clients verwenden die Couchbase, um eine Verbindung zum SDKs Couchbase-Server herzustellen. Amazon DocumentDB-Clients verwenden MongoDB-Treiber, um eine Verbindung zu Amazon DocumentDB herzustellen. Alle von Couchbase unterstützten Sprachen SDKs werden auch von MongoDB-Treibern unterstützt. Weitere Informationen zum Treiber für Ihre Sprache finden Sie unter MongoDB-Treiber
Da sie APIs sich zwischen Couchbase Server und Amazon DocumentDB unterscheiden, müssen Sie Ihren Code umgestalten, um die entsprechende MongoDB zu verwenden. APIs Sie können Amazon Q verwenden, um die K/V API-Aufrufe und SQL++-Abfragen in die entsprechende APIs MongoDB zu konvertieren:
Laden Sie die Quellcodedatei (en) hoch.
Geben Sie die folgende Aufforderung ein:
Convert the Couchbase API code to Amazon DocumentDB API code
Mithilfe des Python-Codebeispiels Hello Couchbase
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Beispiele für das Herstellen einer Verbindung zu Amazon DocumentDB in Python, Node.js, PHP, Go, Java, C#/.NET, R und Ruby finden Sie unter Programmgesteuert mit Amazon DocumentDB verbinden.
Wählen Sie den Migrationsansatz
Bei der Migration von Daten zu Amazon DocumentDB gibt es zwei Optionen:
Offline-Migration
Ziehen Sie eine Offline-Migration in Betracht, wenn:
Ausfallzeiten sind akzeptabel: Bei der Offline-Migration werden Schreibvorgänge in die Quelldatenbank gestoppt, die Daten exportiert und anschließend in Amazon DocumentDB importiert. Dieser Vorgang führt zu Ausfallzeiten für Ihre Anwendung. Wenn Ihre Anwendung oder Ihr Workload diesen Zeitraum der Nichtverfügbarkeit verträgt, ist eine Offline-Migration eine praktikable Option.
Migration kleinerer Datensätze oder Durchführung von Machbarkeitsnachweisen: Bei kleineren Datensätzen ist der Zeitaufwand für den Export- und Importvorgang relativ kurz, sodass die Offline-Migration eine schnelle und einfache Methode darstellt. Es eignet sich auch gut für Entwicklungs-, Test- und proof-of-concept Umgebungen, in denen Ausfallzeiten weniger kritisch sind.
Einfachheit hat Priorität: Die Offline-Methode mit cbexport und mongoimport ist im Allgemeinen der einfachste Ansatz zur Datenmigration. Sie vermeidet die Komplexität der Erfassung von Änderungsdaten (CDC), die mit Online-Migrationsmethoden verbunden ist.
Es müssen keine laufenden Änderungen repliziert werden: Wenn die Quelldatenbank während der Migration nicht aktiv Änderungen empfängt oder wenn diese Änderungen nicht unbedingt erfasst und während des Migrationsprozesses auf das Ziel angewendet werden müssen, ist ein Offline-Ansatz angemessen.
Couchbase Server 6.x oder früher
Couchbase-Bucket zur Amazon DocumentDB-Sammlung
Exportieren Sie Daten mit cbexport json--format Option können Sie oder verwenden. lines list
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importieren Sie die Daten mithilfe von mongoimport in eine Amazon DocumentDB-Sammlung mit der entsprechenden Option zum Importieren der Zeilen oder Listen:
Zeilen:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
Liste:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 oder höher
Verwenden Sie die Tools cbexport und mongoimport, um eine Offline-Migration durchzuführen:
Couchbase-Bucket mit Standardbereich und Standardsammlung
Exportieren Sie Daten mit cbexport json--format Option können Sie oder verwenden. lines list
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importieren Sie die Daten mithilfe von mongoimport in eine Amazon DocumentDB-Sammlung mit der entsprechenden Option zum Importieren der Zeilen oder Listen:
Zeilen:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
Liste:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase-Sammlungen zu Amazon DocumentDB-Sammlungen
Exportieren Sie Daten mit cbexport json--include-data Option, um jede Sammlung zu exportieren. Für die --format Option können Sie lines oder verwendenlist. Verwenden Sie die --collection-field Optionen --scope-field und, um den Namen des Bereichs und der Sammlung in den angegebenen Feldern in jedem JSON-Dokument zu speichern.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
Da cbexport die _collection Felder _scope und zu jedem exportierten Dokument hinzugefügt hat, können Sie sie mit Suchen und Ersetzen oder einer beliebigen Methode aus jedem Dokument in der Exportdatei entfernen. sed
Importieren Sie die Daten für jede Sammlung mithilfe von mongoimport in eine Amazon DocumentDB-Sammlung mit der entsprechenden Option zum Importieren der Zeilen oder Listen:
Zeilen:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
Liste:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Online-Migration
Ziehen Sie eine Online-Migration in Betracht, wenn Sie Ausfallzeiten minimieren möchten und laufende Änderungen nahezu in Echtzeit auf Amazon DocumentDB repliziert werden müssen.
Unter So führen Sie eine Live-Migration von Couchbase zu Amazon DocumentDB durch, um
Couchbase Server 6.x oder früher
Couchbase-Bucket zur Amazon DocumentDB-Sammlung
Das Migrationsprogramm für Couchbasedocument.id.strategy Parameter so konfiguriert, dass er den Nachrichtenschlüsselwert als _id Feldwert verwendet (siehe Eigenschaften der Sink-Connector-ID-Strategie
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 oder höher
Couchbase-Bucket mit Standardbereich und Standardsammlung
Das Migrationsprogramm für Couchbasedocument.id.strategy Parameter so konfiguriert, dass er den Nachrichtenschlüsselwert als _id Feldwert verwendet (siehe Eigenschaften der Sink-Connector-ID-Strategie
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase-Sammlungen zu Amazon DocumentDB-Sammlungen
Konfigurieren Sie den Quell-Connector
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
Konfigurieren Sie den Sink Connector
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
Validierung
Dieser Abschnitt enthält einen detaillierten Validierungsprozess zur Überprüfung der Datenkonsistenz und Integrität nach der Migration zu Amazon DocumentDB. Die Validierungsschritte gelten unabhängig von der Migrationsmethode.
Topics
Stellen Sie sicher, dass alle Sammlungen im Ziel vorhanden sind
Couchbase-Quelle
Option 1: Abfrage-Workbench
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
Option 2: CBQ-Tool
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Amazon DocumentDB DocumentDB-Ziel
mongosh (siehe Connect zu Ihrem Amazon DocumentDB-Cluster herstellen):
db.getSiblingDB('<database>') db.getCollectionNames()
Überprüfen Sie die Anzahl der Dokumente zwischen Quell- und Zielclustern
Couchbase-Quelle
Couchbase Server 6.x oder früher
Option 1: Query Workbench
SELECT COUNT(*) FROM `<bucket>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 oder höher
Option 1: Query Workbench
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB DocumentDB-Ziel
mongosh (siehe Connect zu Ihrem Amazon DocumentDB-Cluster herstellen):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
Dokumente zwischen Quell- und Zielclustern vergleichen
Couchbase-Quelle
Couchbase Server 6.x oder früher
Option 1: Query Workbench
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 oder höher
Option 1: Query Workbench
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB DocumentDB-Ziel
mongosh (siehe Connect zu Ihrem Amazon DocumentDB-Cluster herstellen):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
