Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Integrieren von DynamoDB in Amazon Managed Streaming für Apache Kafka
Amazon Managed Streaming für Apache Kafka (Amazon MSK) erleichtert das Erfassen und Verarbeiten von Streaming-Daten in Echtzeit mithilfe eines vollständig verwalteten, hochverfügbaren Apache Kafka-Service.
Apache Kafka
Aufgrund dieser Funktionen wird Apache Kafka häufig zur Erstellung von Echtzeit-Streaming-Datenpipelines verwendet. Eine Datenpipeline verarbeitet und verschiebt Daten zuverlässig von einem System in ein anderes. Sie kann ein wichtiger Bestandteil einer speziell entwickelten Datenbankstrategie sein, da sie die Verwendung mehrerer Datenbanken erleichtert, die jeweils unterschiedliche Anwendungsfälle unterstützen.
Amazon DynamoDB wird in diesen Datenpipelines häufig zur Unterstützung von Anwendungen eingesetzt, die Schlüssel-Wert- oder Dokumentdatenmodelle verwenden und für die eine grenzenlose Skalierbarkeit mit konsistenter Leistung im einstelligen Millisekundenbereich gewünscht ist.
Funktionsweise
Bei der Integration von Amazon MSK in DynamoDB wird eine Lambda-Funktion verwendet, die Datensätze von Amazon MSK verarbeitet und in DynamoDB schreibt.
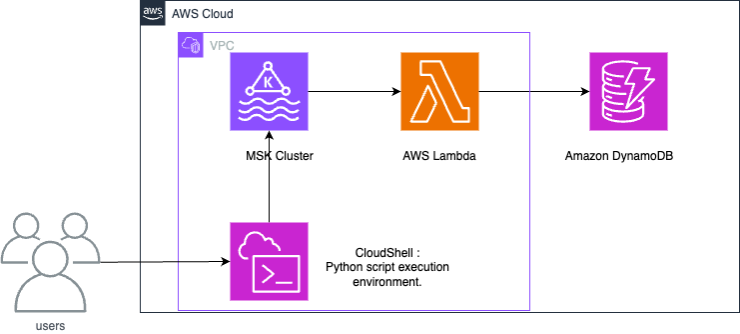
Lambda fragt intern neue Nachrichten von Amazon MSK ab und ruft dann synchron die Ziel-Lambda-Funktion auf. Die Ereignisnutzlast der Lambda-Funktion enthält Stapel von Nachrichten von Amazon MSK. Für die Integration von Amazon MSK in DynamoDB schreibt die Lambda-Funktion diese Nachrichten in DynamoDB.
Einrichten einer Integration von Amazon MSK in DynamoDB
Anmerkung
Sie können die in diesem Beispiel verwendeten Ressourcen im folgenden GitHub Repository
Die folgenden Schritte zeigen, wie Sie eine Beispielintegration von Amazon MSK in Amazon DynamoDB einrichten. Das Beispiel enthält Daten, die von IoT-Geräten (Internet der Dinge) generiert und in Amazon MSK erfasst wurden. In Amazon MSK erfasste Daten können in Analysedienste oder Tools von Drittanbietern integriert werden, die mit Apache Kafka kompatibel sind, was verschiedene Analyseanwendungsfälle ermöglicht. DynamoDB-Integration ermöglicht zudem auch die Suche nach Schlüssel-Wert-Paaren einzelner Gerätedatensätze.
Dieses Beispiel zeigt, wie ein Python-Skript Daten eines IoT-Sensors in Amazon MSK schreibt. Anschließend werden durch eine Lambda-Funktion Elemente mit dem Partitionsschlüssel "deviceid" in DynamoDB geschrieben.
Die bereitgestellte CloudFormation Vorlage erstellt die folgenden Ressourcen: einen Amazon S3 S3-Bucket, eine Amazon VPC, einen Amazon MSK-Cluster und einen AWS CloudShell zum Testen von Datenoperationen.
Um Testdaten zu generieren, erstellen Sie ein Amazon-MSK-Thema und anschließend eine DynamoDB-Tabelle. Sie können den Sitzungsmanager von der Managementkonsole aus verwenden, um sich beim Betriebssystem CloudShell des anzumelden und Python-Skripts auszuführen.
Nachdem Sie die CloudFormation Vorlage ausgeführt haben, können Sie die Erstellung dieser Architektur abschließen, indem Sie die folgenden Operationen ausführen.
-
Führen Sie die CloudFormation Vorlage aus
S3bucket.yaml, um einen S3-Bucket zu erstellen. Führen Sie sie für alle nachfolgenden Skripts oder Operationen in derselben Region aus. Geben SieForMSKTestS3den Namen des CloudFormation Stacks ein.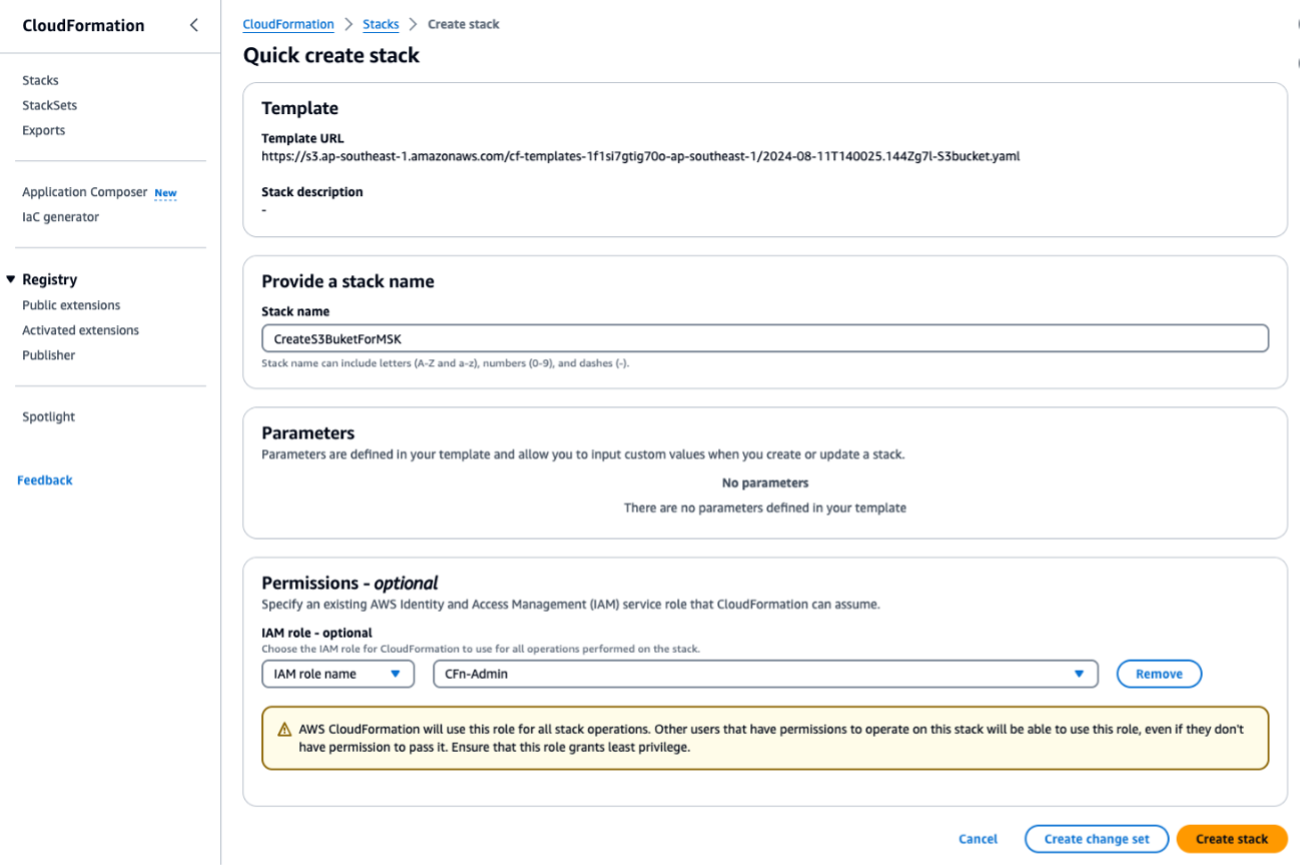
Wenn der Vorgang abgeschlossen ist, notieren Sie sich den unter Ausgaben angezeigten Namen des S3-Buckets. Sie benötigen den Namen in Schritt 3.

-
Laden Sie die heruntergeladene ZIP-Datei
fromMSK.zipin den soeben erstellten S3-Bucket hoch.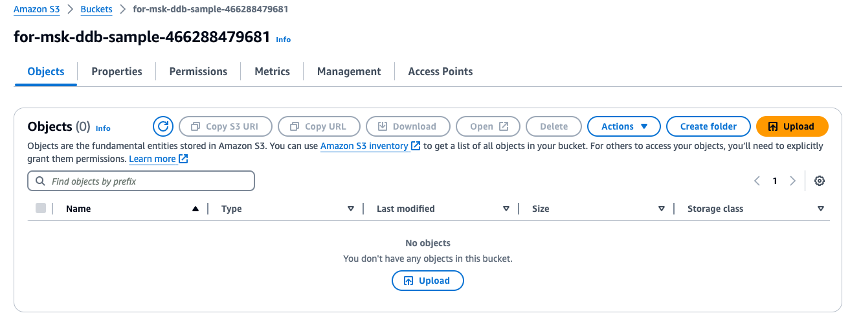
-
Führen Sie die CloudFormation Vorlage aus
VPC.yaml, um eine VPC, einen Amazon MSK-Cluster und eine Lambda-Funktion zu erstellen. Geben Sie auf dem Bildschirm für die Parametereingabe auf Anforderung den Namen des S3-Buckets ein, den Sie in Schritt 1 erstellt haben. Setzen Sie den CloudFormation Stack-Namen auf.ForMSKTestVPC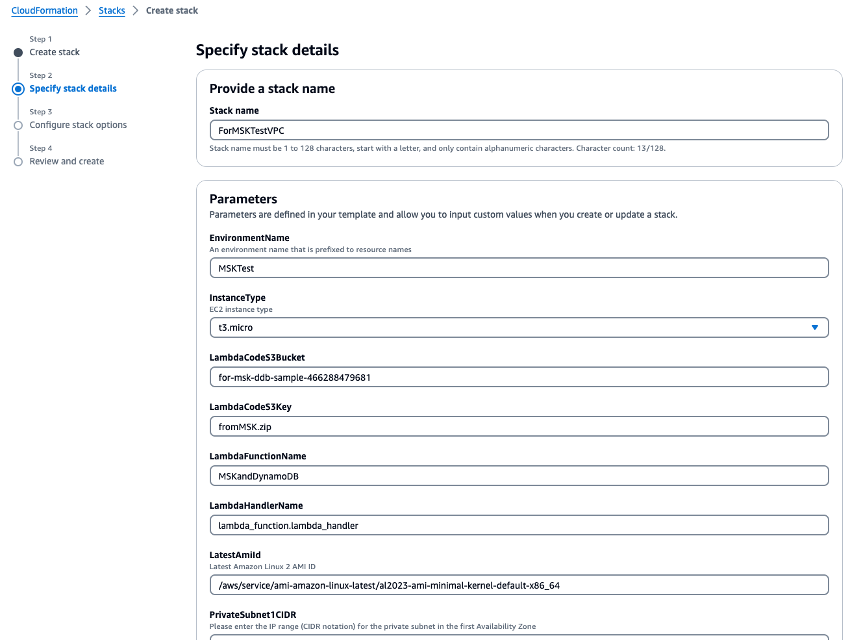
-
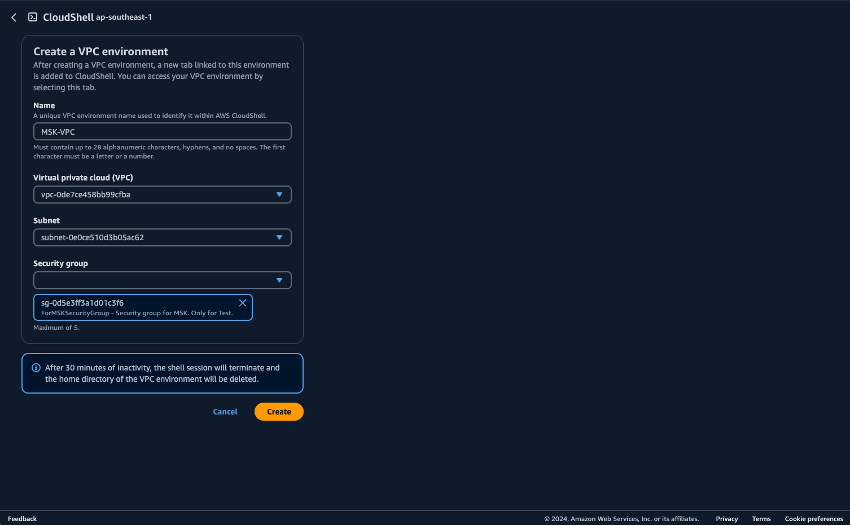
Bereiten Sie die Umgebung für die Ausführung von Python-Skripten vor CloudShell. Sie können CloudShell auf dem verwenden AWS-Managementkonsole. Weitere Informationen zur Verwendung CloudShell finden Sie unter Erste Schritte mit AWS CloudShell. Erstellen Sie nach dem Start eine CloudShell, CloudShell die zu der VPC gehört, die Sie gerade erstellt haben, um eine Verbindung zum Amazon MSK-Cluster herzustellen. Erstellen Sie das CloudShell in einem privaten Subnetz. Füllen Sie die folgenden Felder aus:
-
Name: Ein beliebiger Name. Ein Beispiel ist MSK-VPC.
-
VPC: Wählen Sie MSKTest aus
-
Subnetz: Wählen Sie MSKTest Private Subnet (AZ1) aus
-
SecurityGroup- wählen ForMSKSecurityGroup
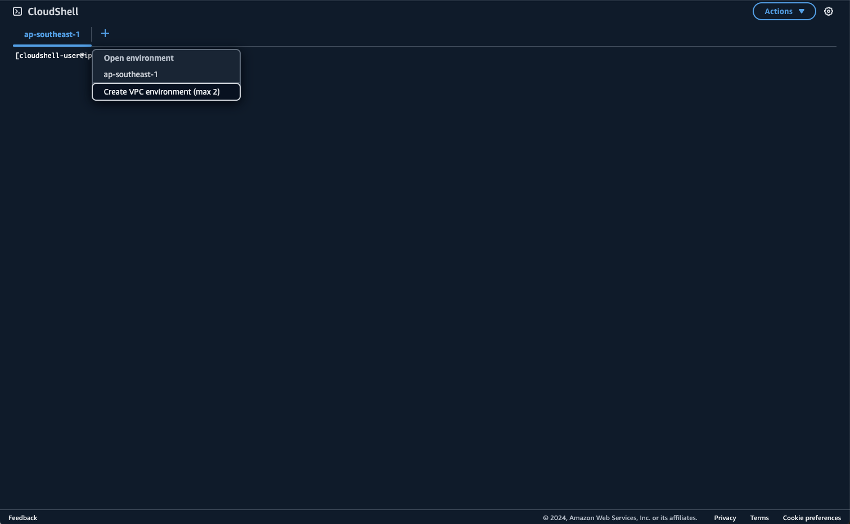
Sobald die CloudShell Zugehörigkeit zum privaten Subnetz gestartet wurde, führen Sie den folgenden Befehl aus:
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
Laden Sie Python-Skripte aus dem S3-Bucket herunter.
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
Überprüfen Sie die Management-Konsole und legen Sie die Umgebungsvariablen für die Broker-URL und den Regionswert in den Python-Skripten fest. Überprüfen Sie den Endpunkt des Amazon-MSK-Clusters in der Management-Konsole.
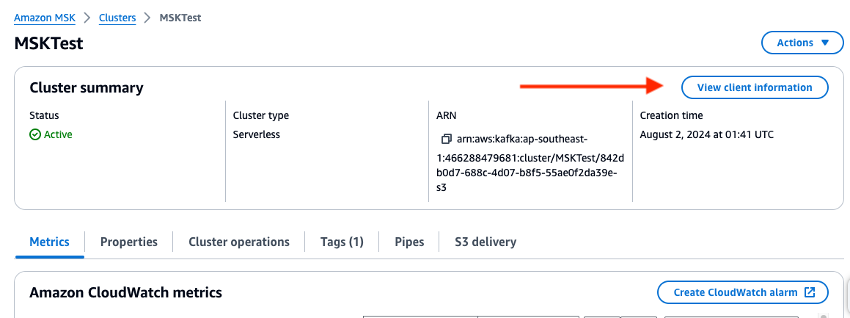
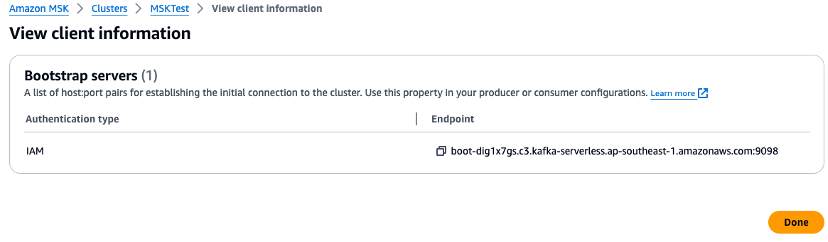
-
Legen Sie die Umgebungsvariablen auf dem fest CloudShell. Bei Verwendung der Region „USA West (Oregon)“:
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
Führen Sie die folgenden Python-Skripte aus.
Erstellen Sie ein Amazon-MSK-Thema.
python ./createTopic.pyErstellen Sie eine DynamoDB-Tabelle.
python ./createTable.pySchreiben Sie Testdaten in das Amazon MSK-Thema:
python ./kafkaDataGen.py -
Überprüfen Sie die CloudWatch Metriken für die erstellten Amazon MSK-, Lambda- und DynamoDB-Ressourcen und überprüfen Sie die in der
device_statusTabelle gespeicherten Daten mithilfe des DynamoDB-Daten-Explorers, um sicherzustellen, dass alle Prozesse korrekt ausgeführt wurden. Wenn jeder Prozess ohne Fehler ausgeführt wird, können Sie überprüfen, ob die Testdaten, die von Amazon MSK geschrieben wurden CloudShell , auch in DynamoDB geschrieben werden.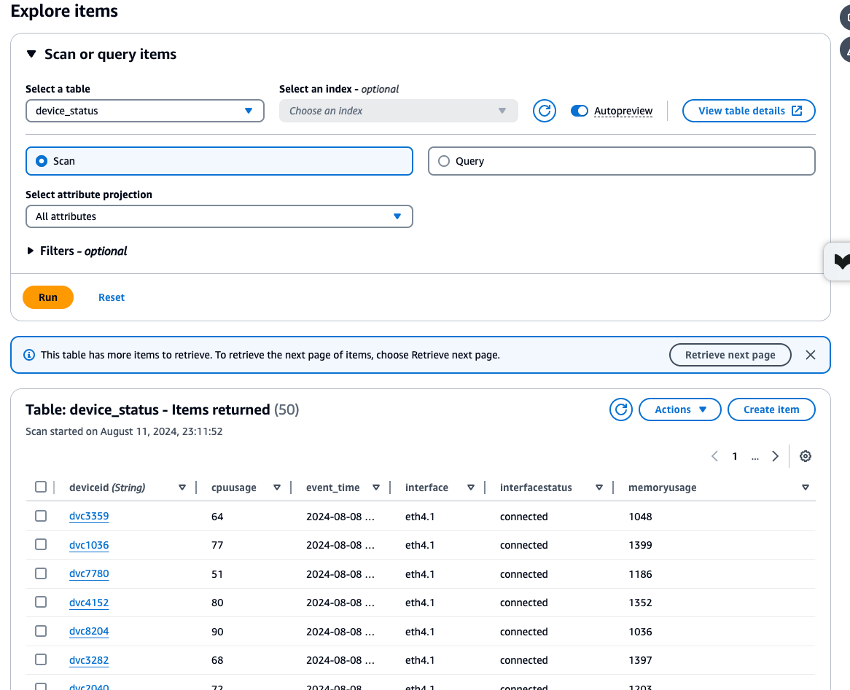
-
Wenn Sie mit diesem Beispiel fertig sind, löschen Sie die in diesem Tutorial erstellten Ressourcen. Löschen Sie die beiden CloudFormation Stapel: und.
ForMSKTestS3ForMSKTestVPCWenn das Löschen des Stacks erfolgreich war, werden alle Ressourcen gelöscht.
Nächste Schritte
Anmerkung
Wenn Sie im Rahmen dieses Beispiels Ressourcen erstellt haben, denken Sie daran, diese wieder zu löschen, damit keine unerwarteten Gebühren anfallen.
Die Integration hat eine Architektur identifiziert, die Amazon MSK und DynamoDB miteinander verbindet, sodass Stream-Daten OLTP-Workloads unterstützen können. Von hier aus können komplexere Suchen realisiert werden, indem DynamoDB mit OpenSearch Service verknüpft wird. Erwägen Sie die Integration mit EventBridge für komplexere ereignisgesteuerte Anforderungen und Erweiterungen wie Amazon Managed Service für Apache Flink für höheren Durchsatz und geringere Latenzanforderungen.
