Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren aus einer relationalen Datenbank zu DynamoDB
Die Migration einer relationalen Datenbank zu DynamoDB erfordert eine sorgfältige Planung, damit ein erfolgreiches Ergebnis sichergestellt wird. In diesem Leitfaden erfahren Sie, wie dieser Prozess funktioniert, welche Tools Ihnen zur Verfügung stehen und wie Sie anschließend mögliche Migrationsstrategien bewerten und eine von ihnen auswählen können, die Ihren Anforderungen entspricht.
Themen
Überlegungen zum Migrieren einer relationalen Datenbank zu DynamoDB
Auswählen der geeigneten Strategie für die Migration zu DynamoDB
Durchführen einer Online-Migration zu DynamoDB mit 1:1-Migration aller Tabellen
Durchführen einer Online-Migration zu DynamoDB mithilfe einer benutzerdefinierten Staging-Tabelle
Gründe für die Migration zu DynamoDB
Die Migration zu Amazon DynamoDB bietet eine Reihe überzeugender Vorteile für Unternehmen und Organisationen. Hier finden Sie einige wichtige Vorteile, die DynamoDB zu einer attraktiven Wahl für die Datenbankmigration machen:
-
Skalierbarkeit: DynamoDB ist darauf ausgelegt, massive Workloads zu bewältigen, und lässt sich nahtlos skalieren, um wachsenden Datenmengen und Datenströmen gerecht zu werden. Mit DynamoDB können Sie die Datenbank je nach Bedarf einfach herauf- oder herunterskalieren und so sicherstellen, dass die Anwendungen plötzliche Spitzen im Datenverkehr ohne Leistungseinbußen bewältigen können.
-
Leistung: DynamoDB bietet Datenzugriff mit niedriger Latenz, sodass Anwendungen Daten mit außergewöhnlicher Geschwindigkeit abrufen und verarbeiten können. Die verteilte Architektur stellt sicher, dass Lese- und Schreibvorgänge auf mehrere Knoten verteilt werden, sodass selbst bei hohen Anforderungsraten konsistente Reaktionszeiten im einstelligen Millisekundenbereich erzielt werden.
-
Vollständige Verwaltung: DynamoDB ist ein vollständig von AWS verwalteter Service. Das bedeutet, dass es sich um die betrieblichen Aspekte des Datenbankmanagements AWS kümmert, einschließlich Bereitstellung, Konfiguration, Patching, Backups und Skalierung. Auf diese Weise können Sie sich stärker auf die Entwicklung von Anwendungen als auf Datenbankverwaltungsaufgaben konzentrieren.
-
Serverless-Architektur: DynamoDB unterstützt ein Serverless-Modell, bekannt als DynamoDB On-Demand, bei dem Sie nur für die tatsächlichen Lese- und Schreibanforderungen zahlen, die die Anwendung sendet, ohne dass vorab Kapazitäten bereitgestellt werden müssen. Dieses pay-per-request Modell bietet Kosteneffizienz und minimalen Betriebsaufwand, da Sie nur für die Ressourcen zahlen, die Sie verbrauchen, ohne dass Kapazitäten bereitgestellt und überwacht werden müssen.
-
NoSQL-Flexibilität: Im Gegensatz zu herkömmlichen relationalen Datenbanken folgt DynamoDB einem NoSQL-Datenmodell, das Flexibilität beim Schemadesign bietet. Mit DynamoDB können Sie strukturierte, halbstrukturierte und unstrukturierte Daten speichern, sodass sie sich gut für die Verarbeitung von unterschiedlichen und sich weiterentwickelnden Datentypen eignen. Diese Flexibilität ermöglicht schnellere Entwicklungszyklen und eine einfachere Anpassung an sich ändernde Geschäftsanforderungen.
-
Hohe Verfügbarkeit und Beständigkeit: DynamoDB repliziert Daten über mehrere Availability Zones innerhalb einer Region und gewährleistet so eine hohe Verfügbarkeit und Datenbeständigkeit. Replikation, Failover und Wiederherstellung von Daten werden automatisch übernommen, wodurch sich das Risiko von Datenverlusten oder Serviceunterbrechungen minimiert. Für DynamoDB gilt ein SLA mit einer Verfügbarkeit von bis zu 99,999 %.
-
Sicherheit und Compliance: DynamoDB lässt sich in AWS Identity and Access Management integrieren und ermöglicht eine differenzierte Zugriffskontrolle. Es bietet Verschlüsselung im Ruhezustand und während der Übertragung und gewährleistet so die Sicherheit der Daten. DynamoDB erfüllt außerdem verschiedene Compliance-Standards, darunter HIPAA, PCI DSS und DSGVO, und entspricht somit den gesetzlichen Anforderungen.
-
Integration mit dem AWS Ökosystem: Als Teil des AWS Ökosystems lässt sich DynamoDB nahtlos in andere AWS Dienste wie AWS Lambda CloudFormation, und integrieren. AWS AppSync Diese Integration ermöglicht es Ihnen, Serverless-Architekturen zu erstellen, Infrastruktur als Code zu nutzen und datengesteuerte Echtzeitanwendungen zu entwickeln.
Überlegungen zum Migrieren einer relationalen Datenbank zu DynamoDB
Relationale Datenbanksysteme und NoSQL-Datenbanken weisen unterschiedliche Vor- und Nachteile auf. Diese Unterschiede führen dazu, dass sich die Datenbankdesigns der beiden Systeme voneinander unterscheiden.
| Aufgabentyp | Relationale Datenbank | NoSQL-Datenbank |
|---|---|---|
| Abfragen der Datenbank | In relationalen Datenbanken können Daten flexibel abgerufen werden, Abfragen sind jedoch vergleichsweise kostspielig und können bei einer großen Zahl von Zugriffen nicht gut skaliert werden (siehe Erste Schritte für die Modellierung relationaler Daten in DynamoDB). Eine relationale Datenbankanwendung kann Geschäftslogik in gespeicherten Prozeduren, SQL-Unterabfragen, Massenaktualisierungsabfragen und Aggregationsabfragen implementieren. | In einer NoSQL-Datenbank wie DynamoDB können Daten effizient mithilfe einer begrenzten Anzahl von Möglichkeiten abgerufen werden, die ansonsten möglicherweise kostspielig und langsam sind. Schreibvorgänge in DynamoDB sind Singletons. Die Geschäftslogik von Anwendungen, die früher in gespeicherten Prozeduren ausgeführt wurden, muss so umgestaltet werden, dass sie außerhalb von DynamoDB in benutzerdefiniertem Code ausgeführt wird, der auf einem Host wie Amazon Amazon EC2 oder ausgeführt wird. AWS Lambda |
| Entwerfen der Datenbank | Sie entwerfen das Design im Hinblick auf Flexibilität, ohne sich um Implementierungsdetails oder Leistung zu kümmern. Die Optimierung von Abfragen wirkt sich im Allgemeinen nicht auf das Schemadesign aus, eine Standardisierung ist jedoch wichtig. | Sie entwerfen das Schema im Hinblick darauf, die häufigsten und wichtigsten Abfragen so schnell und kostengünstig wie möglich ausführen zu können. Die Datenstrukturen sind an die spezifischen Anforderungen Ihrer geschäftlichen Anwendungsfälle angepasst. |
Die Entwicklung einer NoSQL-Datenbank erfordert einen anderen Ansatz als die Entwicklung eines relationalen Datenbankmanagementsystems (RDBMS). Sie können ein standardisiertes Datenmodell für ein RDBMS entwickeln, ohne sich Gedanken über Zugriffsmuster machen zu müssen. Anschließend können Sie es erweitern, wenn neue Fragen und Abfrageanforderungen entstehen. Sie können jeden einzelnen Typ von Daten in einer eigenen Tabelle organisieren.
Mit dem NoSQL-Design können Sie das Schema für DynamoDB entwerfen, wenn Sie die Fragen kennen, die es beantworten soll. Es ist äußerst wichtig, die geschäftlichen Probleme und die Lese- und Schreibmuster der Anwendung zu kennen. Zudem sollten Sie in einer DynamoDB-Anwendung möglichst wenige Tabellen verwenden. Weniger Tabellen sorgen dafür, dass die Dinge besser skalierbar sind, weniger Berechtigungsmanagement erforderlich sind und der Overhead für Ihre DynamoDB-Anwendung reduziert wird. Dies kann auch dazu beitragen, die Backup-Kosten insgesamt niedrig zu halten.
Die Aufgabe der Modellierung relationaler Daten für DynamoDB und der Erstellung einer neuen Version der Front-End-Anwendung wird in einem eigenständigen Thema behandelt. In diesem Leitfaden wird davon ausgegangen, dass Sie über eine neue Version Ihrer Anwendung verfügen, die für die Verwendung von DynamoDB entwickelt wurde, Sie jedoch noch herausfinden müssen, wie Sie historische Daten beim Cutover am besten migrieren und synchronisieren können.
Größenüberlegungen
Die maximale Größe der einzelnen Elemente (Zeilen), die Sie in einer DynamoDB-Tabelle speichern können, beträgt 400 KB. Weitere Informationen finden Sie unter Kontingente in Amazon DynamoDB. Die Elementgröße wird durch die Gesamtgröße aller Attributnamen und Attributwerte in einem Element bestimmt. Weitere Informationen finden Sie unter Elementgrößen und -formate in DynamoDB.
Wenn die Anwendung mehr Daten in einem Element speichern muss, als es die Größenbeschränkung von DynamoDB zulässt, teilen Sie das Element in eine Elementauflistung auf, komprimieren Sie die Elementdaten oder speichern Sie das Element als Objekt in Amazon Simple Storage Service (Amazon S3), während Sie die Amazon-S3-Objekt-ID in dem DynamoDB-Element speichern. Siehe Bewährte Methoden für das Speichern großer Elemente und Attribute in DynamoDB. Die Kosten für die Aktualisierung eines Elements basiert auf der Gesamtgröße des Elements. Bei Workloads, in denen vorhandene Elemente häufig aktualisiert werden müssen, kostet die Aktualisierung kleiner Elemente mit einer Größe von 1 oder 2 KB weniger als die Aktualisierung größerer Elemente. Weitere Informationen zu Elementauflistungen finden Sie unter Elementsammlungen — wie man one-to-many Beziehungen in DynamoDB modelliert.
Lesen Sie vor der Auswahl der Attribute für die Partitions- und Sortierschlüssel, anderer Tabelleneinstellungen, der Elementgröße und -struktur und der Entscheidung, ob Sekundärindizes erstellt werden sollen, unbedingt die Dokumentation zur DynamoDB-Modellierung sowie den Leitfaden für Optimierung der Kosten für DynamoDB-Tabellen. Testen Sie unbedingt Ihren Migrationsplan, damit Ihre DynamoDB-Lösung kosteneffizient ist und zu den Features und Einschränkungen von DynamoDB passen.
Verstehen, wie eine Migration zu DynamoDB funktioniert
Bevor Sie sich mit den zur Verfügung stehenden Migrationstools befassen, sollten Sie sich darüber Gedanken machen, wie Schreibvorgänge von DynamoDB verarbeitet werden.
Die standardmäßige und am häufigsten verwendete Schreiboperation ist eine einzelne PutItem-API-Operation. Sie können eine PutItem-Operation in einer Schleife ausführen, um Datensätze zu verarbeiten. DynamoDB unterstützt praktisch unbegrenzt viele gleichzeitige Verbindungen. Wenn Sie also eine umfangreiche Multithread-Laderoutine wie MapReduce oder Spark konfigurieren und ausführen können, ist die Geschwindigkeit von Schreibvorgängen nur durch die Kapazität der Zieltabelle begrenzt (die im Allgemeinen ebenfalls unbegrenzt ist).
Wenn Sie Daten in DynamoDB laden, ist es wichtig, die Schreibgeschwindigkeit des Loaders zu kennen. Wenn die Größe der geladenen Elemente (Zeilen) 1 KB beträgt oder geringer ist, entspricht die Geschwindigkeit einfach die Anzahl der Elemente pro Sekunde. Die Zieltabelle kann dann mit einer ausreichenden Anzahl von WCUs (Write Capacity Units, Schreibkapazitätseinheiten) ausgestattet werden, um diese Rate zu bewältigen. Wenn der Loader die bereitgestellte Kapazität in einer einzelnen Sekunde überschreitet, werden die zusätzlichen Anfragen möglicherweise gedrosselt oder ganz zurückgewiesen. Sie können in den CloudWatch Diagrammen auf der Registerkarte Überwachung der DynamoDB-Konsole nach Drosselungen suchen.
Für den zweiten ausführbaren Vorgang wird eine zugehörige API namens BatchWriteItem verwendet. In BatchWriteItemkönnen Sie bis zu 25 Schreibanforderungen in einem API-Aufruf kombinieren. Diese werden vom Service empfangen und als separate PutItem-Anfragen an die Tabelle verarbeitet. Derzeit können Sie bei der Auswahl nicht den Vorteil der automatischen Wiederholungsversuche nutzenBatchWriteItem, die im AWS SDK enthalten sind, wenn Sie Singleton-Aufrufe mit tätigen. PutItem Wenn also Fehler auftreten (z. B. Drosselungsausnahmen), müssen Sie beim Antwortaufruf an BatchWriteItem nach der Liste aller fehlgeschlagenen Schreibvorgänge suchen. Weitere Informationen zum Umgang mit Drosselungswarnungen für den Fall, dass diese in den Drosselungstabellen erkannt werden, finden Sie CloudWatch unter. Beheben von Drosselungsereignissen in Amazon DynamoDB
Der Import des dritten Datentyps ist mit dem Feature zum Importieren von DynamoDB-Daten aus S3PutItem ist hier ein Upstream-Prozess erforderlich und die Daten werden in dem von Ihnen ausgewählten Format in einen Amazon-S3-Bucket geschrieben.
Tools für die Migration zu DynamoDB
Es gibt mehrere gängige Migrations- und ETL-Tools, mit denen Daten zu DynamoDB migriert werden können.
Amazon stellt eine Vielzahl von Datentools für die Migration bereit, darunter AWS Database Migration Service (DMS), AWS Glue, Amazon EMR und Amazon Managed Streaming für Apache Kafka. Diese Tools können für eine Migration mit Ausfallzeit verwendet werden und sie nutzen die CDC-Features (Change Data Capture, Erfassung von Datenänderungen) von relationalen Datenbanken für die Online-Migration. Bei der Auswahl ist es hilfreich, Fähigkeiten und Erfahrungen Ihrer Organisation mit den einzelnen Tools sowie deren Features, Leistung und Kosten zu berücksichtigen.
Viele Kunden entscheiden sich dafür, eigene Migrationsskripte und -aufträge zu schreiben und erstellen benutzerdefinierte Datentransformationen für den Migrationsprozess. Wenn Sie eine DynamoDB-Tabelle mit starkem Schreibverkehr oder regelmäßigen umfangreichen Massenladeaufgaben betreiben möchten, können Sie den Migrationscode selbst schreiben, um sich mit dem Verhalten von DynamoDB bei hohem Schreibverkehr vertraut zu machen. Szenarien wie der Umgang mit Drosselungen und die effiziente Bereitstellung von Tabellen können so bereits zu Beginn der Testmigration erprobt werden.
Auswählen der geeigneten Strategie für die Migration zu DynamoDB
Eine große relationale Datenbankanwendung kann mehr als einhundert Tabellen umfassen und mehrere verschiedene Anwendungsfunktionen unterstützen. Wenn Sie eine große Migration planen, sollten Sie erwägen, die Anwendung in kleinere Komponenten oder Microservices aufzuteilen und jeweils nur eine kleine Anzahl von Tabellen zu migrieren. Anschließend können Sie in Wellen weitere Komponenten zu DynamoDB migrieren.
Bei der Auswahl einer Migrationsstrategie hängt die Entscheidung für eine Lösung von verschiedenen Faktoren ab. Wir können die Optionen, die uns je nach unseren Anforderungen und Ressourcen zur Verfügung stehen, in einem Entscheidungsbaum veranschaulichen. Die Konzepte werden hier kurz vorgestellt (und an späterer Stelle im Leitfaden ausführlicher behandelt):
-
Offline-Migration: Wenn die Anwendung während der Migration eine gewisse Ausfallzeit toleriert, vereinfacht diese den Migrationsprozess.
-
Hybridmigration: Bei diesem Ansatz wird der Betrieb während der Migration teilweise aufrechterhalten; so sind z. B. Lese-, aber keine Schreibvorgänge, und Lese- und Einfügevorgänge, aber keine Aktualisierungen und Löschungen möglich.
-
Online-Migration: Die Migration von Anwendungen, die ohne Ausfallzeiten weiterlaufen müssen, ist weniger einfach und erfordert möglicherweise eine umfangreiche Planung und benutzerdefinierte Entwicklung. Eine wichtige Entscheidung besteht darin, die Kosten für die Erstellung eines benutzerdefinierten Migrationsprozesses anhand der Kosten abzuwägen, die dem Unternehmen durch ein Ausfallzeitfenster während des Cutovers entstehen.
| Bedingung 1 | Bedingung 2 | Empfehlung |
|---|---|---|
| Es ist möglich, die Anwendung während eines Wartungsfensters für einige Zeit herunterzufahren, damit die Datenmigration durchgeführt werden kann. Dies ist eine Offline-Migration. |
Verwenden Sie eine Offlinemigration AWS DMS und führen Sie sie mithilfe einer Vollladeaufgabe durch. Strukturieren Sie die Quelldaten gegebenenfalls mit einem SQL |
|
| Es ist möglich, die Anwendung während der Migration im schreibgeschützten Modus ausführen. Dies ist eine Hybridmigration. | Deaktivieren Sie Schreibvorgänge in der Anwendungs- oder Quelldatenbank. Verwenden AWS DMS und führen Sie eine Offline-Migration mithilfe einer Vollladetask durch. | |
| Es ist möglich, die Anwendung während der Migration mit Lese- und Einfügungsvorgängen neuer Datensätze, aber ohne Aktualisierungen oder Löschungen ausführen. Dies ist eine Hybridmigration. | Sie verfügen über Kenntnisse in der Anwendungsentwicklung und können die vorhandene relationale Datenbankanwendung aktualisieren, um für alle neuen Datensätze duale Schreibvorgänge durchzuführen, auch in DynamoDB. | Verwenden AWS DMS und führen Sie eine Offline-Migration mithilfe einer Vollladetask durch. Stellen Sie gleichzeitig eine Version der vorhandenen Anwendung bereit, die Lesevorgänge und duale Schreibvorgänge ermöglicht. |
| Es ist eine Migration mit minimalen Ausfallzeiten erforderlich. Dies ist eine Online-Migration. |
|
Wird verwendet AWS DMS , um eine Online-Datenmigration durchzuführen. Führen Sie eine Massenladeaufgabe gefolgt von einer CDC-Synchronisierungsaufgabe durch. |
| Es ist eine Migration mit minimalen Ausfallzeiten erforderlich. Dies ist eine Online-Migration. |
|
Erstellen Sie die NoSQL-fähige Tabelle in der SQL-Datenbank. Füllen und synchronisieren Sie es mithilfe von JOINs, UNIONs VIEWs, Triggern und gespeicherten Prozeduren. |
| Es ist eine Migration mit minimalen Ausfallzeiten erforderlich. Dies ist eine Online-Migration. |
|
Ziehen Sie eine Hybrid- oder Offline-Migration in Betracht. |
| Es ist eine Migration mit minimalen Ausfallzeiten erforderlich. Dies ist eine Online-Migration. | Es ist möglich, die Migration historischer Transaktionsdaten zu überspringen oder die Daten in Amazon S3 archivieren, anstatt sie zu migrieren. Es müssen nur einige kleine statische Tabellen migriert werden. | Schreiben Sie ein Skript oder verwenden Sie für die Migration der Tabellen ein beliebiges ETL-Tool. Strukturieren Sie die Quelldaten gegebenenfalls mit einem SQL VIEW vor. |
Durchführen einer Offline-Migration zu DynamoDB
Offline-Migrationen eignen sich, wenn Sie für die Durchführung der Migration ein Ausfallzeitfenster einplanen können. Bei relationalen Datenbanken kommt es in der Regel jeden Monat zu einer gewissen Ausfallzeit aufgrund von Wartungsarbeiten und Patches oder längeren Ausfallzeiten aufgrund von Hardware-Upgrades oder Upgrades auf Hauptversionen.
Amazon S3 kann während einer Migration als Staging-Bereich verwendet werden. Im CSV- oder DynamoDB-JSON-Format gespeicherte Daten können mit dem Feature zum Importieren von DynamoDB-Daten aus S3 automatisch in eine neue DynamoDB-Tabelle importiert werden.
Sie können Tabellen kombinieren, um eindeutige NoSQL-Zugriffsmuster zu nutzen (z. B. die Umwandlung von vier Legacy-Tabellen in eine einzige DynamoDB-Tabelle). Bei der Anforderung eines Dokuments mit einem einzigen Schlüsselwert oder der Abfrage einer vorgruppierten Elementauflistung ist die Latenz in der Regel besser als einer SQL-Datenbank, in der ein Verbund aus mehreren Tabellen hergestellt wird. Dies macht die Migrationsaufgabe jedoch schwieriger. Eine SQL-Ansicht könnte die Arbeit innerhalb der Quelldatenbank übernehmen und einen einzelnen Datensatz vorbereiten, der alle vier Tabellen in einem Satz darstellt.
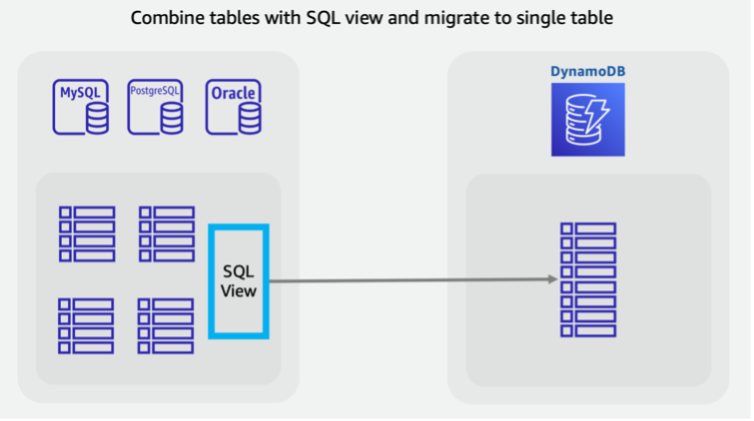
In dieser Ansicht können Tabellen per JOIN in eine denormalisierte Form umgewandelt oder die Entitäten normalisiert und Tabellen mithilfe eines SQL UNION gestapelt werden. Die wichtigsten Entscheidungen im Zusammenhang mit der Umstrukturierung relationaler Daten finden Sie in diesem Video
Plan
Offline-Migration mit Amazon S3 durchführen
Tools
-
Ein ETL-Auftrag zum Extrahieren und Transformieren von SQL-Daten und zum Speichern in einem S3-Bucket, z. B.:
-
AWS Database Migration Service, ein Dienst, mit dem eine Massenladung historischer Daten und auch die Verarbeitung von CDC-Datensätzen möglich ist, um Quell- und Zieltabellen zu synchronisieren.
-
AWS Glue
-
Amazon EMR
-
Eigener benutzerdefinierter Code
-
-
Feature zum Importieren von DynamoDB-Daten aus S3
Schritte für die Offline-Migration:
-
Erstellen Sie einen ETL-Auftrag, der die SQL-Datenbank abfragen, Tabellendaten in das DynamoDB-JSON- oder CSV-Format umwandeln und in einem S3-Bucket speichern kann.
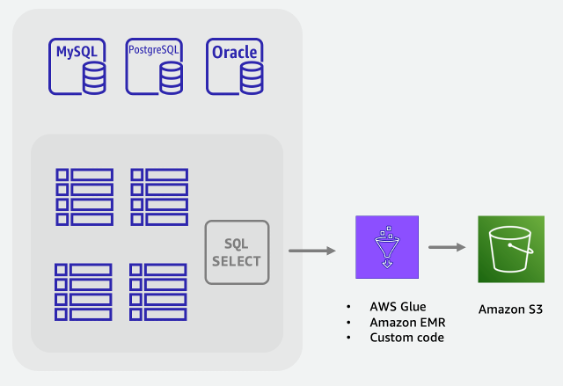
-
Das Feature zum Importieren von DynamoDB-Daten aus S3 wird aufgerufen; es wird eine neue Tabelle erstellt und es werden automatisch Daten aus dem S3-Bucket geladen.
Die vollständige Offline-Migration ist zwar einfach, aber bei Anwendungsbesitzern und -benutzern möglicherweise weniger beliebt. Für die Benutzer wäre es von Vorteil, wenn die Anwendung während der Migration zumindest einen geringeren Service-Level aufrecht erhalten könnte.
Es besteht die Möglichkeit, Funktionen hinzuzufügen, die Schreibvorgänge während der Offline-Migration unterbinden, Lesevorgänge aber aufrecht erhalten. Die Benutzer der Anwendung könnten dann während der Migration der relationalen Daten weiterhin sicher nach vorhandenen Daten suchen und Abfragen dafür durchführen. Wenn Sie genau das suchen, lesen Sie weiter, um mehr über Hybridmigrationen zu erfahren.
Durchführen einer Hybridmigration zu DynamoDB
Lese- und Schreibvorgänge werden zwar in alle Datenbankanwendungen durchgeführt, bei der Planung einer Hybrid- oder Online-Migration ist allerdings die Art des jeweiligen Vorgangs zu berücksichtigen. Datenbankschreibvorgänge lassen sich in drei Bereiche unterteilen: Einfügungen, Aktualisierungen und Löschungen. Es gibt Anwendungen, in den Datenlöschungen nicht sofort verarbeitet werden müssen. Hier können die Löschungen beispielsweise in einem Massenbereinigungsprozess am Monatsende erfolgen. Solche Anwendungen lassen sich einfacher und unter teilweiser Aufrechterhaltung der Betriebszeit migrieren.
Plan
Führen Sie eine online/offline Hybridmigration mit dualen Schreibvorgängen für Anwendungen durch
Tools
-
Ein ETL-Auftrag zum Extrahieren und Transformieren von SQL-Daten und zum Speichern in einem S3-Bucket, z. B.:
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
Eigener benutzerdefinierter Code
-
Schritte für die Hybridmigration:
-
Erstellen Sie die DynamoDB-Zieltabelle. In diese Tabelle gehen sowohl historische Massendaten als auch neue Live-Daten ein.
-
Erstellen Sie eine Version der Legacy-Anwendung, bei der Löschungen und Aktualisierungen deaktiviert sind, alle Einfügungen in die SQL-Datenbank und in DynamoDB jedoch als duale Schreibvorgänge ausgeführt werden.
-
Beginnen Sie mit dem ETL-Job oder der AWS DMS ETL-Aufgabe, um bestehende Daten aufzufüllen und gleichzeitig die neue Anwendungsversion bereitzustellen
-
Nach Abschluss des Backfill-Auftrags enthält DynamoDB alle vorhandenen und neuen Datensätze und der Cutover der Anwendung kann beginnen.
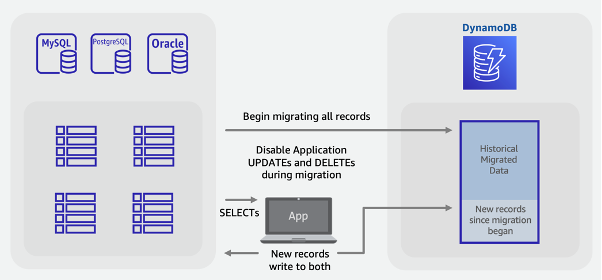
Anmerkung
Beim Backfill-Auftrag werden die Daten direkt von SQL nach DynamoDB geschrieben. Das Feature für den Import aus S3 kann nicht wie im Beispiel für die Offline-Migration verwendet werden, da hierdurch eine neue Tabelle erstellt wird, die erst verfügbar ist, nachdem die Daten in DynamoDB geladen wurden.
Durchführen einer Online-Migration zu DynamoDB mit 1:1-Migration aller Tabellen
Viele relationale Datenbanken verfügen über das Feature „Erfassung von Datenänderungen“ (Change Data Capture, CDC), mit dem Benutzer eine Liste der Änderungen an einer Datenbanktabelle anfordern können, die vor oder nach einem bestimmten Zeitpunkt vorgenommen wurden. CDC aktiviert dieses Feature mit internen Protokollen, sodass die Tabelle keine Spalte mit Zeitstempel enthalten muss, damit dies funktioniert.
Wenn Sie ein Schema von SQL-Tabellen in eine NoSQL-Datenbank migrieren, können Sie die Daten kombinieren und so umstrukturieren, dass weniger Tabellen erforderlich sind. Auf diese Weise werden Daten an einem einzigen Ort erfasst, wobei verwandte Daten nicht manuell in mehrstufigen Lesevorgängen zusammengefügt werden müssen. Die Strukturierung von Daten in einer Tabelle ist jedoch nicht immer erforderlich; manchmal werden die Tabellen auch 1:1 zu DynamoDB migriert. Solche 1:1-Migrationen sind weniger kompliziert, da Sie das CDC-Feature der Quelldatenbank nutzen und gängige ETL-Tools verwenden können, die diese Art der Migration unterstützen. Die Daten jeder Zeile können dann weiterhin transformiert werden, aber der Umfang der einzelnen Tabellen bleibt gleich.
Erwägen Sie die 1:1-Migration von SQL-Tabellen zu DynamoDB unter dem Vorbehalt, dass DynamoDB keine serverseitigen Joins unterstützt. Sie müssen Ihrer Anwendung Logik hinzufügen, um Daten aus mehreren Tabellen zu kombinieren.
Plan
Führen Sie eine Online-Migration jeder Tabelle zu DynamoDB durch, indem Sie AWS DMS
Tools
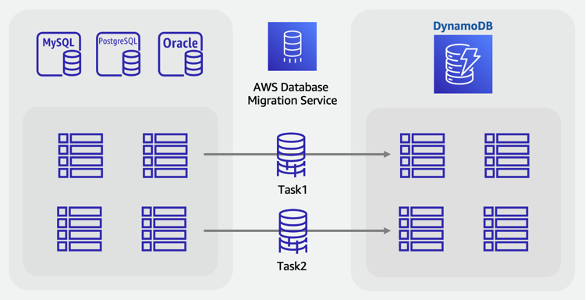
Schritte für die Online-Migration:
-
Identifizieren Sie in Ihrem Quellschema die zu migrierenden Tabellen.
-
Erstellen Sie in DynamoDB dieselbe Anzahl von Tabellen mit identischer Schlüsselstruktur wie in der Quelle.
-
Erstellen Sie einen Replikationsserver auf AWS DMS und konfigurieren Sie die Quell- und Zielendpunkte
-
Definieren Sie alle erforderlichen Transformationen pro Zeile (z. B. Verkettung von Spalten oder Umrechnung von Datumsangaben in das Zeichenfolgenformat ISO-8601).
-
Erstellen Sie für jede Tabelle eine Migrationsaufgabe für Volllast und CDC.
-
Überwachen Sie diese Aufgaben, bis die laufende Replikationsphase begonnen hat
-
Zu diesem Zeitpunkt können Sie alle Validierungsaudits durchführen und dann Benutzer zu der Anwendung umleiten, die in DynamoDB liest und schreibt.
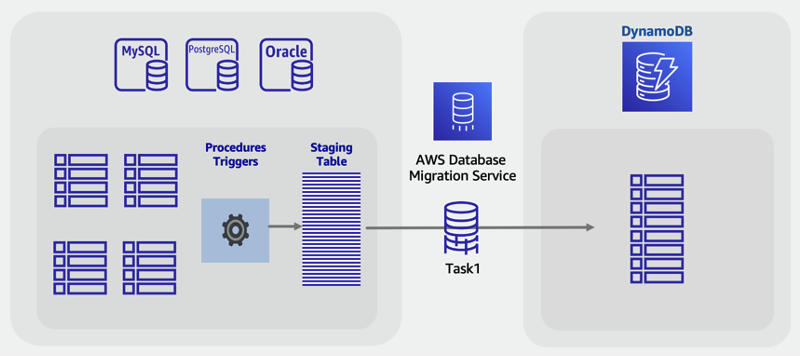
Durchführen einer Online-Migration zu DynamoDB mithilfe einer benutzerdefinierten Staging-Tabelle
Wie im obigen Offline-Migrationsszenario können Sie Tabellen kombinieren, um eindeutige NoSQL-Zugriffsmuster zu nutzen (z. B. Transformation von vier Legacy-Tabellen in eine einzige DynamoDB-Tabelle). Eine SQL VIEW könnte die Arbeit innerhalb der Quelldatenbank übernehmen und einen einzelnen Datensatz vorbereiten, der alle vier Tabellen in einem Satz darstellt.
Bei Online-Migrationen mit sich ändernden Live-Daten können Sie allerdings keine CDC-Features nutzen, da sie von VIEWs nicht unterstützt werden. Wenn die Tabellen eine Spalte mit den Zeitstempeln der letzten Aktualisierung enthalten und diese in die VIEW integriert werden, können Sie einen benutzerdefinierten ETL-Auftrag erstellen, der anhand dieser Zeitstempel einen Massenladevorgang mit Synchronisation durchführt.
Ein neuer Ansatz zur Bewältigung dieser Herausforderung besteht darin, mithilfe von SQL-Standardfunktionen wie Ansichten, gespeicherten Prozeduren und Triggern eine neue SQL-Tabelle zu erstellen, die im endgültig gewünschten DynamoDB-NoSQL-Format vorliegt.
Wenn der Datenbankserver freie Kapazitäten aufweist, kann diese einzelne Staging-Tabelle vor Beginn der Migration erstellt werden. Schreiben Sie dazu eine gespeicherte Prozedur, die Daten aus vorhandenen Tabellen liest, Daten nach Bedarf transformiert und in die neue Staging-Tabelle schreibt. Sie können eine Reihe von Triggern hinzufügen, damit Änderungen an Tabellen in Echtzeit in der Staging-Tabelle repliziert werden. Wenn die Unternehmensrichtlinie keine Trigger zulässt, lässt sich durch Änderungen an gespeicherten Prozeduren dasselbe Ergebnis erzielen. Sie fügen dann jeder Prozedur, die Daten schreibt, einige Codezeilen hinzu, sodass dieselben Änderungen zusätzlich in die Staging-Tabelle geschrieben werden.
Diese Staging-Tabelle, die vollständig mit den Legacy-Anwendungstabellen synchronisiert wird, stellt einen guten Ausgangspunkt für eine Live-Migration dar. Tools, die Datenbank-CDC verwenden, um Live-Migrationen durchzuführen, wie z. B. AWS DMS, können jetzt für diese Tabelle verwendet werden. Ein Vorteil dieses Ansatzes besteht darin, dass er auf vertraute SQL-Kenntnisse und -Features zurückgreift, die in der relationalen Datenbank-Engine verfügbar sind.
Plan
Führen Sie eine Online-Migration mit einer SQL-Staging-Tabelle durch AWS DMS
Tools
-
Benutzerdefinierte gespeicherte SQL-Prozeduren oder -Trigger
Schritte für die Online-Migration:
-
Vergewissern Sie sich, dass die relationale Quelldatenbank-Engine ausreichend Festplattenspeicher und Verarbeitungskapazität aufweist.
-
Erstellen Sie eine neue Staging-Tabelle in der SQL-Datenbank mit aktivierten Zeitstempeln oder CDC-Features.
-
Schreiben Sie eine gespeicherte Prozedur und führen Sie sie aus, um vorhandene relationale Tabellendaten in die Staging-Tabelle zu kopieren.
-
Stellen Sie Trigger bereit oder ändern Sie bestehende Prozeduren, um in der neuen Staging-Tabelle duales Schreiben und gleichzeitig in vorhandenen Tabellen normale Schreibvorgänge zuzulassen.
-
Ausführen AWS DMS , um diese Quelltabelle zu migrieren und mit einer DynamoDB-Zieltabelle zu synchronisieren
In diesem Leitfaden wurden verschiedene Überlegungen und Ansätze für die Migration relationaler Datenbankdaten zu DynamoDB vorgestellt, wobei der Schwerpunkt auf der Minimierung von Ausfallzeiten und der Verwendung gängiger Datenbanktools und -techniken lag. Weitere Informationen finden Sie hier:
