Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden des globalen sekundären Index mit Schreib-Sharding für selektive Tabellenabfragen in DynamoDB
Wenn Sie aktuelle Daten innerhalb eines bestimmten Zeitfensters abfragen müssen, kann die Anforderung von DynamoDB, für die meisten Lesevorgänge einen Partitionsschlüssel bereitzustellen, eine Herausforderung darstellen. Um dieses Szenario zu bewältigen, können Sie mithilfe einer Kombination aus Schreib-Sharding und einem globalen sekundären Index (GSI) ein effektives Abfragemuster implementieren.
Mit diesem Ansatz können Sie zeitkritische Daten effizient abrufen und analysieren, ohne vollständige Tabellenscans durchführen zu müssen, die ressourcenintensiv und kostspielig sein können. Durch die strategische Gestaltung Ihrer Tabellenstruktur und Indizierung können Sie eine flexible Lösung entwickeln, die den zeitbasierten Datenabruf unterstützt und gleichzeitig eine optimale Leistung beibehält.
Themen
Musterdesign
Wenn Sie mit DynamoDB arbeiten, können Sie Probleme beim zeitbasierten Datenabruf bewältigen, indem Sie ein komplexes Muster implementieren, das Schreib-Sharding und globale sekundäre Indizes kombiniert, um flexible und effiziente Abfragen in aktuellen Datenfenstern zu ermöglichen.
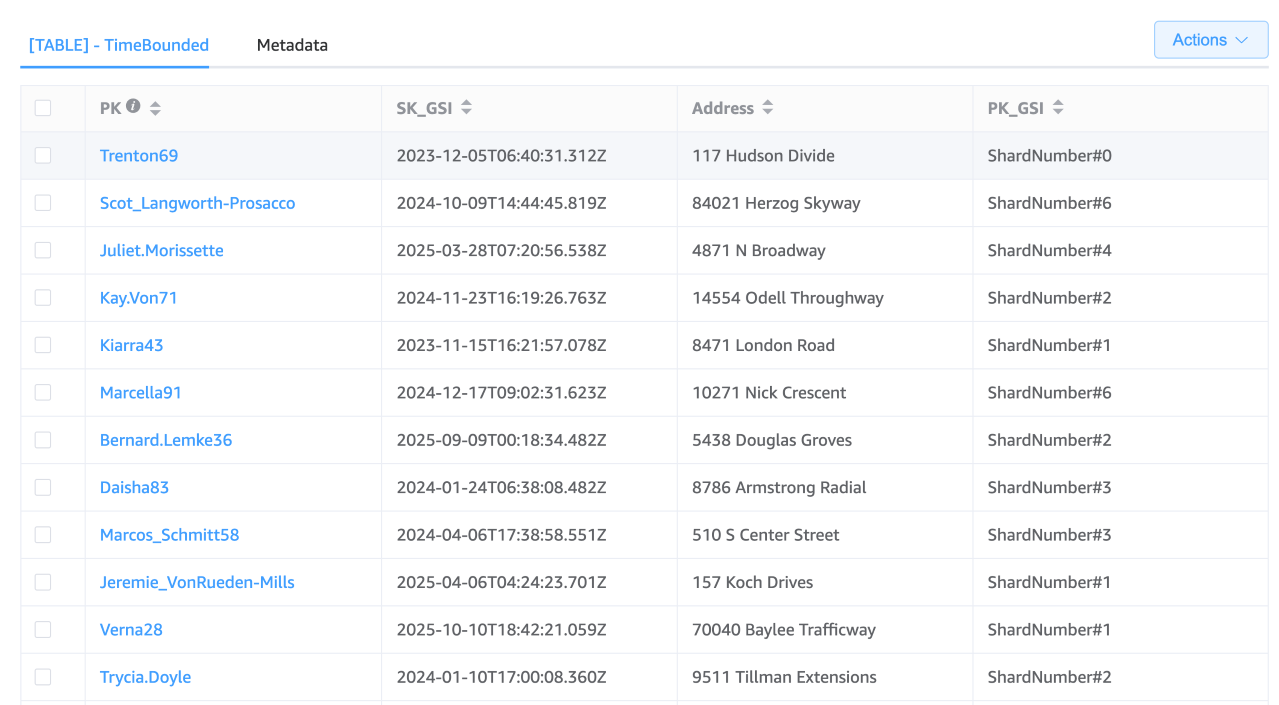
Struktur der Tabelle
Partitionsschlüssel (PK): „Benutzername“
Struktur des GSI
GSI-Partitionsschlüssel (PK_GSI): "#“ ShardNumber
GSI-Sortierschlüssel (SK_GSI): ISO 8601-Zeitstempel (z. B. „2030-04-01 „) T12:00:00Z
Sharding-Strategie
Wenn Sie sich für die Verwendung von 10 Shards entscheiden, könnten Ihre Shard-Nummern zwischen 0 und 9 liegen. Wenn Sie eine Aktivität protokollieren, berechnen Sie die Shard-Nummer (z. B. indem Sie eine Hash-Funktion für die Benutzer-ID verwenden und dann den Modulo der Anzahl der Shards ermitteln) und stellen diese dem GSI-Partitionsschlüssel voran. Bei dieser Methode werden die Einträge auf verschiedene Shards verteilt, wodurch das Risiko von Hot-Partitionen verringert wird.
Abfragen der GSI-Shards
Für das Abfragen aller Shards nach Elementen innerhalb eines bestimmten Zeitbereichs in einer DynamoDB-Tabelle, in der Daten auf mehrere Partitionsschlüssel aufgeteilt werden, erfordert einen anderen Ansatz als die Abfrage einer einzelnen Partition. Da DynamoDB-Abfragen jeweils auf einen einzelnen Partitionsschlüssel beschränkt sind, können Sie nicht direkt mehrere Shards mit einem einzigen Abfragevorgang abfragen. Sie können jedoch mithilfe von Logik auf Anwendungsebene das gewünschte Ergebnis erzielen, indem Sie mehrere Abfragen ausführen, von denen jede auf einen bestimmten Shard abzielt, und dann die Ergebnisse aggregieren. Wie Sie dazu vorgehen müssen, ist im unten stehenden Verfahren erläutert.
So fragen Sie Shards ab und aggregieren die Ergebnisse
Identifizieren Sie den Bereich der Shard-Nummern, die in Ihrer Sharding-Strategie verwendet werden. Wenn Sie beispielsweise 10 Shards haben, liegen Ihre Shard-Nummern zwischen 0 und 9.
Erstellen Sie für jeden Shard eine Abfrage und führen Sie sie aus, um Elemente innerhalb des gewünschten Zeitraums abzurufen. Diese Abfragen können parallel ausgeführt werden, um die Effizienz zu verbessern. Verwenden Sie für diese Abfragen den Partitionsschlüssel mit der Shard-Nummer und den Sortierschlüssel mit Ihrem Zeitraum. Hier ist ein Beispiel für eine Abfrage für einen einzelnen Shard:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'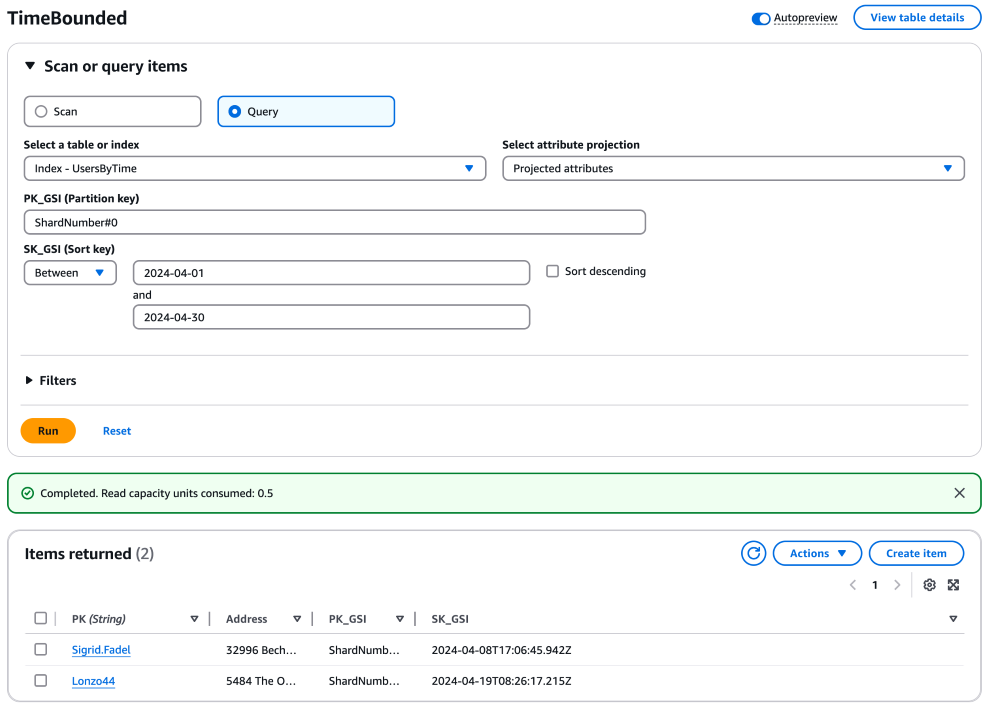
Sie würden diese Abfrage für jeden Shard replizieren und den Partitionsschlüssel entsprechend anpassen (z. B. "ShardNumber#1 „," #2 „,...," #9 „). ShardNumber ShardNumber
Nachdem alle Abfragen abgeschlossen sind, aggregieren Sie die Ergebnisse jeder Abfrage. Führen Sie diese Aggregation in Ihrem Anwendungscode durch und kombinieren Sie die Ergebnisse zu einem einzigen Datensatz, der die Elemente aus allen Shards innerhalb des angegebenen Zeitraums darstellt.
Überlegungen zur parallelen Abfrageausführung
Jede Abfrage verbraucht Lesekapazität aus Ihrer Tabelle oder Ihrem Index. Wenn Sie den bereitgestellten Durchsatz verwenden, stellen Sie sicher, dass Ihre Tabelle über genügend Kapazität verfügt, um den Anstieg paralleler Abfragen zu verarbeiten. Wenn Sie On-Demand-Kapazität verwenden, sollten Sie die möglichen Auswirkungen auf die Kosten berücksichtigen.
Codebeispiel
Um parallel Abfragen zwischen Shards in DynamoDB mit Python auszuführen, können Sie die boto3-Bibliothek verwenden, d. h. das Amazon Web Services SDK for Python. In diesem Beispiel wird davon ausgegangen, dass Sie boto3 installiert und mit den entsprechenden Anmeldeinformationen konfiguriert haben. AWS
Der folgende Python-Code zeigt, wie parallele Abfragen über mehrere Shards für einen bestimmten Zeitraum durchgeführt werden. Er verwendet gleichzeitige Futures, um Abfragen parallel auszuführen, wodurch die Gesamtausführungszeit im Vergleich zur sequenziellen Ausführung reduziert wird.
import boto3 from concurrent.futures import ThreadPoolExecutor, as_completed # Initialize a DynamoDB client dynamodb = boto3.client('dynamodb') # Define your table name and the total number of shards table_name = 'YourTableName' total_shards = 10 # Example: 10 shards numbered 0 to 9 time_start = "2030-03-15T09:00:00Z" time_end = "2030-03-15T10:00:00Z" def query_shard(shard_number): """ Query items in a specific shard for the given time range. """ response = dynamodb.query( TableName=table_name, IndexName='YourGSIName', # Replace with your GSI name KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end", ExpressionAttributeValues={ ":pk_val": {"S": f"ShardNumber#{shard_number}"}, ":date_start": {"S": time_start}, ":date_end": {"S": time_end}, } ) return response['Items'] # Use ThreadPoolExecutor to query across shards in parallel with ThreadPoolExecutor(max_workers=total_shards) as executor: # Submit a future for each shard query futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)} # Collect and aggregate results from all shards all_items = [] for future in as_completed(futures): shard_number = futures[future] try: shard_items = future.result() all_items.extend(shard_items) print(f"Shard {shard_number} returned {len(shard_items)} items") except Exception as exc: print(f"Shard {shard_number} generated an exception: {exc}") # Process the aggregated results (e.g., sorting, filtering) as needed # For example, simply printing the count of all retrieved items print(f"Total items retrieved from all shards: {len(all_items)}")
Bevor Sie diesen Code ausführen, stellen Sie sicher, dass Sie YourTableName und YourGSIName durch die tatsächlichen Tabellen- und GSI-Namen aus Ihrem DynamoDB-Setup ersetzen. Passen Sie außerdem die Variablen total_shards, time_start und time_end an Ihre spezifischen Anforderungen an.
Dieses Skript fragt jeden Shard nach Elementen innerhalb des angegebenen Zeitraums ab und aggregiert die Ergebnisse.
