Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Verfahren zur Optimierung der Leistung von S3 Express One Zone
Bei der Entwicklung von Anwendungen, die Objekte zu Amazon S3 Express One Zone hochladen und daraus abrufen, sollten Sie unsere bewährten Methoden befolgen, um die Leistung zu optimieren. Um die Speicherklasse S3 Express One Zone zu verwenden, müssen Sie einen S3-Verzeichnis-Bucket erstellen. Die Speicherklasse S3 Express One Zone wird für die Verwendung mit S3-Allzweck-Buckets nicht unterstützt.
Leistungsrichtlinien für alle anderen Amazon-S3-Speicherklassen und S3-Allzweck-Buckets finden Sie unter Bewährte Methoden für Designmuster: Optimieren der Leistung von Amazon S3.
Für eine optimale Leistung und Skalierbarkeit mit der Speicherklasse S3 Express One Zone und Verzeichnis-Buckets in hochskalierten Workloads ist es wichtig zu verstehen, wie sich Verzeichnis-Buckets von Allzweck-Buckets unterscheiden. Anschließend stellen wir bewährte Verfahren vor, mit denen Sie Ihre Anwendungen an die Funktionsweise von Verzeichnis-Buckets anpassen können.
Funktionsweise von Verzeichnis-Buckets
Die Speicherklasse Amazon S3 Express One Zone kann Workloads mit bis zu 2 000 000 GET- und bis zu 200 000 PUT-Transaktionen pro Sekunde (TPS) pro Verzeichnis-Bucket unterstützen. Bei S3 Express One Zone werden die Daten in S3-Verzeichnis-Buckets in Availability Zones gespeichert. Auf Objekte in Verzeichnis-Buckets kann innerhalb eines hierarchischen Namespaces zugegriffen werden, ähnlich wie bei einem Dateisystem und im Gegensatz zu S3-Allzweck-Buckets, die einen flachen Namespace haben. Im Gegensatz zu Allzweck-Buckets organisieren Verzeichnis-Buckets Schlüssel hierarchisch in Verzeichnissen statt nach Präfixen. Ein Präfix ist eine Zeichenfolge am Anfang des Objektschlüsselnamens. Sie können Präfixe verwenden, um Ihre Daten zu organisieren und eine flache Objektspeicherarchitektur in Allzweck-Buckets zu verwalten. Weitere Informationen finden Sie unter Organisieren von Objekten mit Präfixen.
In Verzeichnis-Buckets werden Objekte in einem hierarchischen Namespace organisiert, wobei der Schrägstrich (/) das einzige unterstützte Trennzeichen ist. Wenn Sie ein Objekt mit einem Schlüssel wie dir1/dir2/file1.txt hochladen, werden die Verzeichnisse dir1/ und dir2/ automatisch von Amazon S3 erstellt und verwaltet. Verzeichnisse werden während PutObject- oder CreateMultiPartUpload-Operationen erstellt und automatisch entfernt, wenn sie nach DeleteObject- oder AbortMultiPartUpload-Vorgängen leer werden. Es gibt keine Obergrenze für die Anzahl der Objekte und Unterverzeichnisse in einem Verzeichnis.
Die Verzeichnisse, die erstellt werden, wenn Objekte in Verzeichnis-Buckets hochgeladen werden, können sofort skaliert werden, um die Wahrscheinlichkeit von HTTP-503 (Slow Down)-Fehlern zu verringern. Diese automatische Skalierung ermöglicht Ihren Anwendungen, Lese- und Schreibanforderungen innerhalb von Verzeichnissen und zwischen Verzeichnissen nach Bedarf zu parallelisieren. Für S3 Express One Zone sind die einzelnen Verzeichnisse so ausgelegt, dass sie die maximale Anforderungsrate eines Verzeichnis-Buckets unterstützen. Eine Randomisierung der Schlüsselpräfixe ist nicht erforderlich, um eine optimale Leistung zu erzielen, da das System die Objekte automatisch verteilt, um eine gleichmäßige Lastverteilung zu erreichen, was jedoch zur Folge hat, dass die Schlüssel nicht lexikografisch in den Buckets des Verzeichnisses gespeichert werden. Dies steht im Gegensatz zu S3-Allzweck-Buckets, bei denen lexikografisch näher beieinander liegende Schlüssel eher auf demselben Server gespeichert werden.
Weitere Hinweise zu Beispielen für Verzeichnis-Bucket-Operationen und Verzeichnisinteraktionen finden Sie unter Beispiele für den Betrieb von Buckets und die Interaktion mit Verzeichnissen.
Bewährte Methoden
Befolgen Sie die Best Practices, um die Leistung Ihres Verzeichnis-Bucket zu optimieren und Ihre Workloads mit der Zeit abzuskalieren.
Verzeichnisse verwenden, die viele Einträge enthalten (Objekte oder Unterverzeichnisse)
Verzeichnis-Buckets bieten standardmäßig eine hohe Leistung für alle Workloads. Für eine noch größere Leistungsoptimierung bei bestimmten Operationen führt die Konsolidierung von mehr Einträgen (die Objekte oder Unterverzeichnisse sind) in Verzeichnissen zu einer geringeren Latenz und einer höheren Abrufrate:
Mutierende API-Operationen wie
PutObject,DeleteObject,CreateMultiPartUploadundAbortMultiPartUploaderzielen eine optimale Leistung, wenn sie mit weniger, dichteren Verzeichnissen mit Tausenden von Einträgen implementiert werden, anstatt mit einer großen Anzahl kleinerer Verzeichnisse.ListObjectsV2-Operationen funktionieren besser, wenn weniger Verzeichnisse durchsucht werden müssen, um eine Ergebnisseite zu füllen.
Keine Entropie in Präfixen verwenden
Bei Amazon S3-Vorgängen bezieht sich Entropie auf die Zufälligkeit bei der Benennung von Präfixen, die dazu beiträgt, Arbeitslasten gleichmäßig auf Speicherpartitionen zu verteilen. Da Verzeichnis-Buckets jedoch intern die Lastverteilung verwalten, ist es nicht empfehlenswert, Entropie in Präfixen zu verwenden, um die beste Leistung zu erzielen. Der Grund dafür ist, dass Entropie bei Verzeichnis-Buckets dazu führen kann, dass Anfragen langsamer werden, weil die bereits erstellten Verzeichnisse nicht wiederverwendet werden.
Ein Schlüsselmuster, wie $HASH/directory/object könnte dazu führen, dass viele Zwischenverzeichnisse entstehen. Im folgenden Beispiel sind alle job-1 s verschiedene Verzeichnisse, da ihre Eltern unterschiedlich sind. Verzeichnisse werden spärlich sein und Mutations- und Listenanfragen werden langsamer sein. In diesem Beispiel gibt es 12 Zwischenverzeichnisse, die alle einen einzigen Eintrag haben.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
Um die Leistung zu verbessern, können wir stattdessen die Komponente $HASH entfernen und job-1 zu einem einzigen Verzeichnis werden lassen, was die Dichte eines Verzeichnisses verbessert. Im folgenden Beispiel kann ein einzelnes Zwischenverzeichnis mit 6 Einträgen zu einer besseren Leistung führen als im vorherigen Beispiel.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
Dieser Leistungsvorteil entsteht dadurch, dass bei der erstmaligen Erstellung eines Objektschlüssels, dessen Schlüsselname ein Verzeichnis enthält, das Verzeichnis automatisch für das Objekt erstellt wird. Bei nachfolgenden Objekt-Uploads in dasselbe Verzeichnis muss das Verzeichnis nicht erstellt werden, wodurch die Latenz beim Hochladen von Objekten in bestehende Verzeichnisse reduziert wird.
Verwenden Sie ein anderes Trennzeichen als das Trennzeichen/, um Teile Ihres Schlüssels zu trennen, wenn Sie Objekte bei V2-Aufrufen nicht logisch gruppieren müssen ListObjects
Da das Begrenzungszeichen / für Verzeichnis-Buckets besonders behandelt wird, sollte es mit Bedacht verwendet werden. Verzeichnis-Buckets ordnen Objekte zwar nicht lexikografisch, aber Objekte innerhalb eines Verzeichnisses werden dennoch in ListObjectsV2-Ausgaben gruppiert. Wenn Sie diese Funktion nicht benötigen, können Sie / durch ein anderes Zeichen als Trennzeichen ersetzen, damit keine Zwischenverzeichnisse entstehen.
Nehmen wir zum Beispiel an, dass die folgenden Schlüssel in einem Präfixmuster YYYY/MM/DD/HH/ enthalten sind
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
Wenn Sie Objekte in den ListObjectsV2-Ergebnissen nicht nach Stunden oder Tagen gruppieren müssen, sondern Objekte nach Monaten gruppieren müssen, führt das folgende Schlüsselmuster von YYYY/MM/DD-HH- zu deutlich weniger Verzeichnissen und zu einer besseren Leistung des ListObjectsV2-Vorgangs.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Verwenden Sie nach Möglichkeit abgegrenzte Listenoperationen
Eine ListObjectsV2-Anfrage ohne delimiter führt eine rekursive Durchquerung aller Verzeichnisse nach der Tiefe durch. Eine ListObjectsV2-Anfrage mit delimiter ruft nur Einträge in dem durch den prefix Parameter angegebenen Verzeichnis ab, wodurch die Latenz der Anfrage reduziert und die Anzahl der aggregierten Schlüssel pro Sekunde erhöht wird. Verwenden Sie für Verzeichnis-Buckets nach Möglichkeit Operationen mit abgegrenzten Listen. Abgegrenzte Listen führen dazu, dass Verzeichnisse weniger oft besucht werden, was zu mehr Schlüsseln pro Sekunde und einer geringeren Anfragelatenz führt.
Zum Beispiel für die folgenden Verzeichnisse und Objekte in Ihrem Verzeichnis-Bucket:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
Um eine bessere ListObjectsV2 Leistung zu erzielen, verwenden Sie eine durch Trennzeichen getrennte Liste, um Ihre Unterverzeichnisse und Objekte aufzulisten, wenn die Logik Ihrer Anwendung dies zulässt. Sie können zum Beispiel den folgenden Befehl für die Operation "Begrenzte Liste" ausführen,
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
Die Ausgabe ist die Liste der Unterverzeichnisse.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
Um die einzelnen Unterverzeichnisse mit besserer Leistung aufzulisten, können Sie einen Befehl wie das folgende Beispiel ausführen:
Befehl:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Ausgabe:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Co-locate S3 Express One Zone-Speicher mit Ihren Rechenressourcen
Mit S3 Express One Zone befindet sich jeder Verzeichnis-Bucket in einer einzigen Availability Zone, die Sie bei der Erstellung des Buckets auswählen. Sie können damit beginnen, indem Sie neuen Verzeichnis-Bucket in einer Availability Zone erstellen, die für Ihre Computing-Workloads oder Ressourcen lokal ist. Sie können dann sofort mit Lese- und Schreibvorgängen mit sehr niedriger Latenz beginnen. Verzeichnis-Buckets sind eine Art von S3-Buckets, in denen Sie die Availability Zone auswählen können, AWS-Region um die Latenz zwischen Datenverarbeitung und Speicher zu reduzieren.
Wenn Sie über Availability Zones hinweg auf Verzeichnis-Buckets zugreifen, kann es zu einer leicht erhöhten Latenz kommen. Um die Leistung zu optimieren, empfehlen wir, dass Sie von Amazon Elastic Container Service-, Amazon Elastic Kubernetes Service- und Amazon Elastic Compute Cloud-Instances, die sich nach Möglichkeit in derselben Availability Zone befinden, auf einen Directory-Bucket zugreifen.
Verwenden Sie gleichzeitige Verbindungen, um einen hohen Durchsatz mit Objekten über 1 MB zu erreichen.
Sie erreichen die beste Leistung durch die Ausgabe mehrerer gleichzeitiger Anfragen an Verzeichnis-Buckets zur Verteilung Ihrer Anforderungen auf separate Verbindungen und zur Maximierung der verfügbaren Bandbreite. Wie bei Allzweck-Buckets gibt es auch bei S3 Express One Zone keine Beschränkungen für die Anzahl der Verbindungen zu Ihrem Verzeichnis-Bucket. Einzelne Verzeichnisse können die Leistung horizontal und automatisch skalieren, wenn eine große Anzahl gleichzeitiger Schreibvorgänge in dasselbe Verzeichnis stattfindet.
Für einzelne TCP-Verbindungen zu Verzeichnis-Buckets gilt eine feste Obergrenze für die Anzahl der Bytes, die pro Sekunde hoch- oder heruntergeladen werden können. Wenn die Objekte größer werden, wird die Anforderungszeit eher durch Byte-Streaming als durch Transaktionsverarbeitung dominiert. Wenn Sie mehrere Verbindungen verwenden, um das Hoch- oder Herunterladen größerer Objekte zu parallelisieren, können Sie die End-to-End-Latenz verringern. Wenn Sie das Java 2.x SDK verwenden, sollten Sie die Verwendung des S3 Transfer Manager in Betracht ziehen, der Leistungsverbesserungen wie die mehrteiligen Upload-API-Operationen und Byte-Range-Fetches für den parallelen Datenzugriff nutzt.
Gateway VPC-Endpunkte verwenden
Gateway-Endpunkte bieten eine direkte Verbindung von Ihrem VPC zu Verzeichnis-Buckets, ohne dass ein Internet-Gateway oder ein NAT-Gerät für Ihren VPC erforderlich ist. Um die Zeit zu verkürzen, die Ihre Pakete im Netzwerk verbringen, sollten Sie Ihre VPC mit einem Gateway-VPC-Endpunkt für Verzeichnis-Buckets konfigurieren. Weitere Informationen finden Sie unter Netzwerke für Verzeichnis-Buckets.
Sitzungsauthentifizierung und Wiederverwendung von Sitzungstoken, solange sie gültig sind
Verzeichnis-Buckets bieten einen Sitzungs-Token-Authentifizierungsmechanismus, um die Latenz bei leistungsempfindlichen API-Vorgängen zu verringern. Sie können einen einzigen Aufruf von CreateSession tätigen, um ein Sitzungstoken zu erhalten, das dann in den folgenden 5 Minuten für alle Anfragen gültig ist. Um die geringste Latenzzeit bei Ihren API-Aufrufen zu erreichen, sollten Sie ein Sitzungs-Token erwerben und es für die gesamte Lebensdauer dieses Tokens wiederverwenden, bevor Sie es aktualisieren.
Wenn Sie AWS SDKs verwenden, kümmern sich die SDKs automatisch um die Aktualisierung des Sitzungstokens, um Dienstunterbrechungen nach Ablauf einer Sitzung zu vermeiden. Wir empfehlen, dass Sie die AWS SDKs verwenden, um Anfragen an den API-Vorgang zu initiieren und zu verwalten. CreateSession
Mehr über CreateSession erfahren Sie unter Autorisieren zonaler Endpunkt-API-Operationen mit CreateSession.
Verwenden Sie einen Client CRT-based
Die AWS Common Runtime (CRT) besteht aus modularen, performanten und effizienten Bibliotheken, die in C geschrieben wurden und als Basis für die SDKs dienen sollen. AWS Der CRT bietet einen verbesserten Durchsatz, ein verbessertes Verbindungsmanagement und kürzere Startup-Zeiten. Die CRT ist in allen SDKs außer Go verfügbar. AWS
Weitere Informationen zur Konfiguration der CRT für das von Ihnen verwendete SDK finden Sie unter AWS Common Runtime (CRT) -Bibliotheken, Beschleunigen Sie den Amazon S3 S3-Durchsatz mit der AWS Common Runtime
Verwenden Sie die neueste Version von AWS SDKs
Die AWS SDKs bieten integrierte Unterstützung für viele der empfohlenen Richtlinien zur Optimierung der Amazon S3 S3-Leistung. Die SDKs bieten eine einfachere API für die Nutzung von Amazon S3 innerhalb einer Anwendung und werden regelmäßig aktualisiert, um den neuesten Best Practices zu entsprechen. Die SDKs wiederholen beispielsweise Anfragen nach HTTP-503-Fehlern automatisch und verarbeiten langsame Verbindungsantworten.
Wenn Sie das Java 2.x SDK verwenden, sollten Sie den S3 Transfer Manager in Betracht ziehen, der Verbindungen automatisch horizontal skaliert, um Tausende von Anfragen pro Sekunde zu erreichen, wobei gegebenenfalls Bytebereichsanforderungen verwendet werden. Byte-range Anfragen können die Leistung verbessern, da Sie gleichzeitige Verbindungen zu S3 verwenden können, um verschiedene Bytebereiche innerhalb desselben Objekts abzurufen. Dies hilft beim Erreichen eines höheren aggregierten Durchsatzes als bei einer einzelnen Anforderung eines ganzen Objekts. Daher ist es wichtig, die neueste Version der AWS SDKs zu verwenden, um die neuesten Funktionen zur Leistungsoptimierung zu erhalten.
Fehlerbehebung bei der Leistung
Haben Sie Wiederholungsanforderungen für latenzempfindliche Anwendungen festgelegt?
S3 Express One Zone wurde speziell für gleichbleibende Leistung ohne zusätzliche Anpassungen entwickelt. Die Festlegung aggressiver Timeout-Werte und Wiederholungsversuche kann jedoch weiter zu einer gleichbleibenden Latenz und Leistung beitragen. Die AWS SDKs verfügen über konfigurierbare Timeout- und Wiederholungswerte, die Sie an die Toleranzen Ihrer spezifischen Anwendung anpassen können.
Verwenden Sie AWS Common Runtime (CRT) -Bibliotheken und optimale Amazon EC2 EC2-Instance-Typen?
Anwendungen, die eine große Anzahl von Lese- und Schreibvorgängen ausführen, benötigen wahrscheinlich mehr Arbeitsspeicher oder Computing-Kapazitäten als Anwendungen, bei denen dies nicht der Fall ist. Wählen Sie beim Starten Ihrer Amazon-Elastic-Compute-Cloud (Amazon EC2)-Instances für Ihre leistungsfordernde Workloads die Instance-Typen aus, die über die Menge dieser Ressourcen verfügen, die Ihre Anwendung benötigt. Die S3-Express-One-Zone-Hochleistungsspeicherung lässt sich ideal mit größeren und neueren Instance-Typen mit größerem Systemspeicher und leistungsstärkeren CPUs und GPUs kombinieren, die die Vorteile von leistungsfähigerem Speicher nutzen können. Wir empfehlen außerdem, die neuesten Versionen der CRT-enabled AWS SDKs zu verwenden, mit denen Lese- und Schreibanforderungen parallel besser beschleunigt werden können.
Benutzt du AWS SDKs für die sitzungsbasierte Authentifizierung?
Mit Amazon S3 können Sie auch die Leistung optimieren, wenn Sie HTTP-REST-API-Anfragen verwenden, indem Sie dieselben bewährten Methoden befolgen, die Teil der AWS SDKs sind. Angesichts des sitzungsbasierten Autorisierungs- und Authentifizierungsmechanismus, der von S3 Express One Zone verwendet wird, empfehlen wir Ihnen jedoch dringend, die AWS SDKs zur Verwaltung CreateSession und das zugehörige verwaltete Sitzungstoken zu verwenden. Die AWS SDKs erstellen und aktualisieren mithilfe der API-Operation automatisch Token in Ihrem Namen. CreateSession Bei der Autorisierung der einzelnen Anfragen wird die Round-Trip-Latenz pro Anfrage AWS Identity and Access Management (IAM) CreateSession eingespart.
Beispiele für den Betrieb von Buckets und die Interaktion mit Verzeichnissen
Die folgenden drei Beispiele zeigen, wie Verzeichnis-Buckets funktionieren.
Beispiel 1: Interaktion von S3 PutObject-Anfragen an einen Verzeichnis-Bucket mit Verzeichnissen
-
Wenn der Vorgang
PUT(<bucket>, "documents/reports/quarterly.txt")in einem leeren Bucket ausgeführt wird, wird das Verzeichnisdocuments/im Stammverzeichnis des Buckets erstellt, das Verzeichnisreports/innerhalb vondocuments/erstellt und das Objektquarterly.txtinnerhalb vonreports/erstellt. Für diesen Vorgang wurden zusätzlich zum Objekt zwei Verzeichnisse angelegt.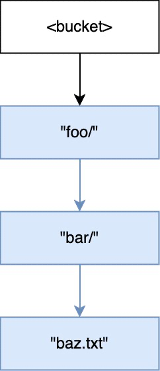
-
Wenn dann eine weitere Operation
PUT(<bucket>, "documents/logs/application.txt")ausgeführt wird, ist das Verzeichnisdocuments/bereits vorhanden, das Verzeichnislogs/innerhalb vondocuments/existiert nicht und wird erstellt, und das Objektapplication.txtinnerhalb vonlogs/wird erstellt. Bei diesem Vorgang wurde nur ein Verzeichnis zusätzlich zum Objekt erstellt.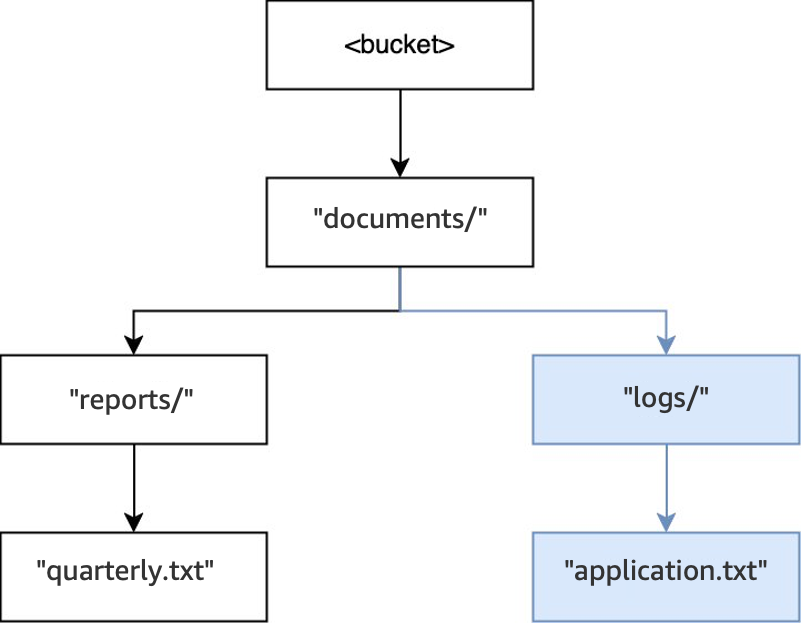
-
Wenn schließlich eine
PUT(<bucket>, "documents/readme.txt")Operation ausgeführt wird, existiert das Verzeichnisdocuments/im Stammverzeichnis bereits und das Objektreadme.txtwird erstellt. Bei diesem Vorgang werden keine Verzeichnisse erstellt.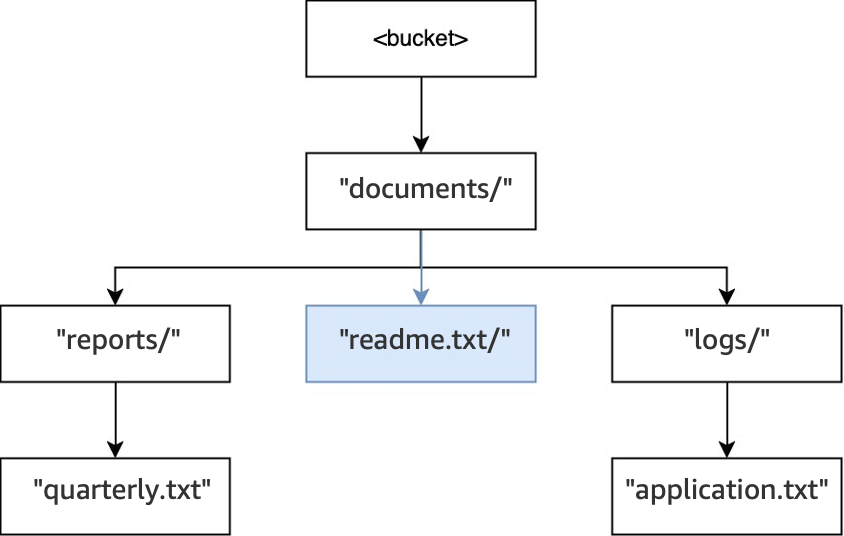
Beispiel 2: Wie S3 ListObjectsV2-Anfragen an einen Verzeichnis-Bucket mit Verzeichnissen interagieren
Bei den S3 ListObjectsV2 -Anfragen ohne Angabe eines Trennzeichens wird ein Bucket in der Tiefe durchlaufen. Die Ausgaben werden in einer einheitlichen Reihenfolge zurückgegeben. Diese Reihenfolge bleibt zwar zwischen den Anfragen gleich, ist aber nicht lexikografisch. Für den Bucket und die Verzeichnisse, die im vorherigen Beispiel erstellt wurden:
-
Wenn
LIST(<bucket>)ausgeführt wird, wird das Verzeichnisdocuments/eingegeben und das Traversieren beginnt. -
Das Unterverzeichnis
logs/wird betreten und die Durchsuchung beginnt. -
Das Objekt
application.txtbefindet sich inlogs/. -
Darin sind keine weiteren Einträge in
logs/vorhanden. Der Listenvorgang wird beendetlogs/und gibtdocuments/erneut ein. -
Das Verzeichnis
documents/wird weiter durchlaufen und das Objektreadme.txtwird gefunden. -
Das Verzeichnis
documents/wird weiter durchlaufen und das Unterverzeichnisreports/wird betreten und das Durchlaufen beginnt. -
Das Objekt
quarterly.txtbefindet sich inreports/. -
Darin sind keine weiteren Einträge in
reports/vorhanden. Die Liste verlässtreports/und geht zurück zudocuments/. -
Es sind keine weiteren Einträge vorhanden in
documents/und die Liste kehrt zurück.
In diesem Beispiel wird logs/ vor readme.txt bestellt und readme.txt wird vor reports/ bestellt.
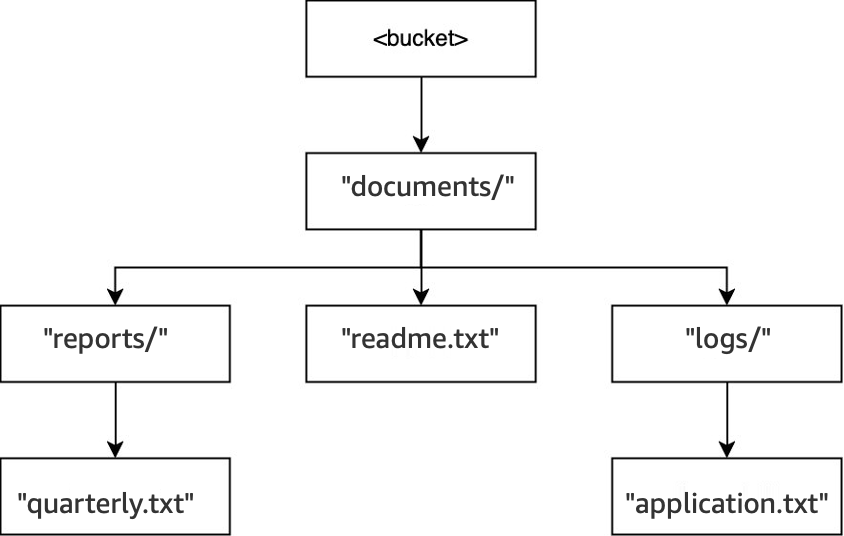
Beispiel 3: Wie S3-DeleteObject-Anfragen an einen Verzeichnis-Bucket mit Verzeichnissen interagieren
-
Wenn der Vorgang
DELETE(<bucket>, "documents/reports/quarterly.txt")in demselben Bucket ausgeführt wird, wird das Objektquarterly.txtgelöscht, sodass das Verzeichnisreports/leer bleibt und es sofort gelöscht wird. Das Verzeichnisdocuments/ist nicht leer, da es sowohl das Verzeichnislogs/als auch dasreadme.txtObjekt enthält, sodass es nicht gelöscht wird. Bei diesem Vorgang wurden nur ein Objekt und ein Verzeichnis gelöscht.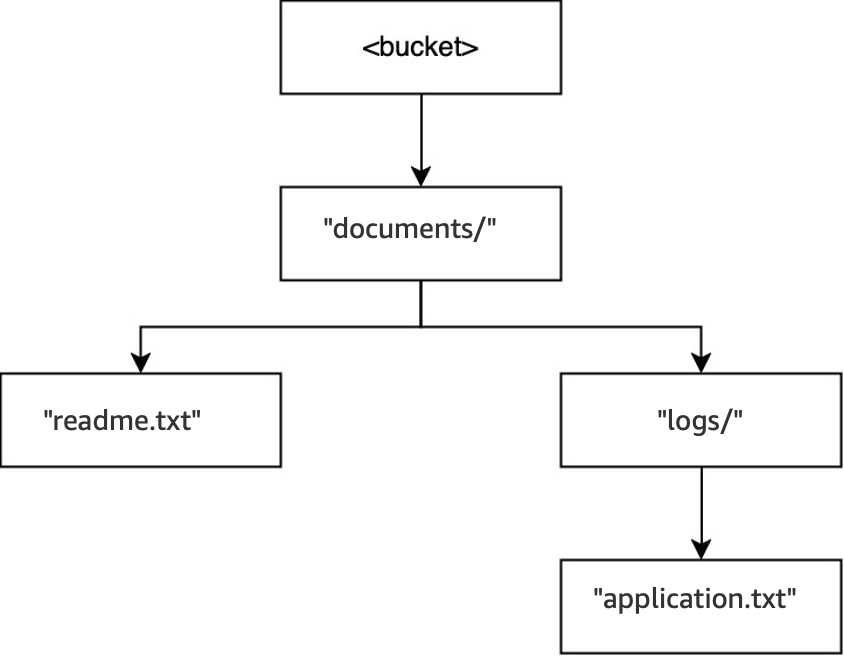
-
Wenn der Vorgang
DELETE(<bucket>, "documents/readme.txt")ausgeführt wird, wird das Objektreadme.txtgelöscht.documents/ist immer noch nicht leer, weil es das Verzeichnislogs/enthält, also wurde es nicht gelöscht. Bei diesem Vorgang werden keine Verzeichnisse gelöscht, sondern nur das Objekt.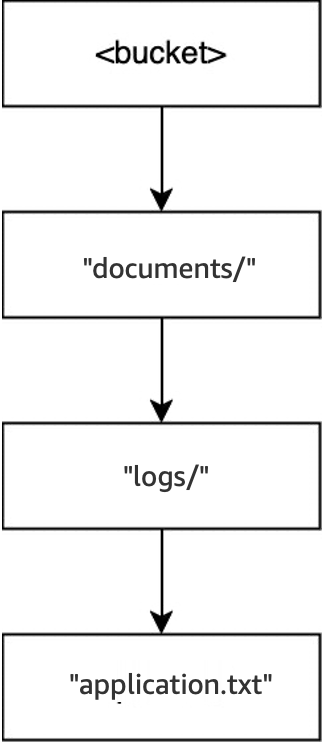
-
Wenn die Operation
DELETE(<bucket>, "documents/logs/application.txt")ausgeführt wird, wirdapplication.txtschließlich gelöscht, sodasslogs/leer bleibt und sofort gelöscht wird. Dadurch bleibtdocuments/leer und wird auch sofort gelöscht. Bei diesem Vorgang werden zwei Verzeichnisse und ein Objekt gelöscht. Der Bucket ist nun leer.
