Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
DDL-Einschränkungen und andere Informationen für Aurora PostgreSQL Limitless Database
In den folgenden Themen werden Einschränkungen beschrieben oder weitere Informationen zu DDL-SQL-Befehlen in Aurora PostgreSQL Limitless Database bereitgestellt.
Themen
ALTER TABLE
Der Befehl ALTER TABLE wird in Aurora PostgreSQL Limitless Database in der Regel unterstützt. Weitere Informationen finden Sie im Abschnitt ALTER TABLE
Einschränkungen
ALTER TABLE weist die folgenden Einschränkungen für unterstützte Optionen auf.
- Entfernen einer Spalte
-
-
In Sharded-Tabellen können Sie keine Spalten entfernen, die Teil des Shard-Schlüssels sind.
-
In Referenztabellen können Sie keine Primärschlüsselspalten entfernen.
-
- Ändern des Datentyps einer Spalte
-
-
Der Ausdruck
USINGwird nicht unterstützt. -
In Sharded-Tabellen können Sie den Datentyp von Spalten nicht ändern, die Teil des Shard-Schlüssels sind.
-
- Hinzufügen oder Entfernen einer Beschränkung
-
Einzelheiten darüber, was nicht unterstützt wird, finden Sie unter Beschränkungen.
- Ändern des Standardwerts einer Spalte
-
Standardwerte werden unterstützt. Weitere Informationen finden Sie unter Standardwerte.
Nicht unterstützte Optionen
Einige Optionen werden nicht unterstützt, da sie von nicht unterstützten Features wie Auslösern abhängen.
Die folgenden Optionen auf Tabellenebene für ALTER TABLE werden nicht unterstützt:
-
ALL IN TABLESPACE -
ATTACH PARTITION -
DETACH PARTITION -
ONLY-Flag -
RENAME CONSTRAINT
Die folgenden Optionen auf Spaltenebene für ALTER TABLE werden nicht unterstützt:
-
ADD GENERATED
-
DROP EXPRESSION [IF EXISTS]
-
DROP IDENTITY [IF EXISTS]
-
RESET
-
RESTART
-
SET
-
SET COMPRESSION
-
SET STATISTICS
CREATE DATABASE
In Aurora PostgreSQL Limitless Database werden nur uneingeschränkte Datenbanken unterstützt.
Während CREATE DATABASE ausgeführt wird, schlagen Datenbanken, die in einem oder mehreren Knoten erfolgreich erstellt wurden, möglicherweise in anderen Knoten fehl, da eine Datenbankerstellung ein nicht-transaktionaler Vorgang ist. In diesem Fall werden Datenbankobjekte, die erfolgreich erstellt wurden, innerhalb eines vordefinierten Zeitraums automatisch von allen Knoten entfernt, damit in der DB-Shard-Gruppe die Konsistenz erhalten bleibt. In diesem Zeitraum kann die Neuerstellung einer Datenbank mit demselben Namen zu einem Fehler führen, der darauf hinweist, dass die Datenbank bereits existiert.
Die folgenden Optionen werden unterstützt:
-
Kollation:
CREATE DATABASEnameWITH [LOCALE =locale] [LC_COLLATE =lc_collate] [LC_CTYPE =lc_ctype] [ICU_LOCALE =icu_locale] [ICU_RULES =icu_rules] [LOCALE_PROVIDER =locale_provider] [COLLATION_VERSION =collation_version]; -
CREATE DATABASE WITH OWNER:CREATE DATABASEnameWITH OWNER =user_name;
Die folgenden Optionen werden nicht unterstützt:
-
CREATE DATABASE WITH TABLESPACE:CREATE DATABASEnameWITH TABLESPACE =tablespace_name; -
CREATE DATABASE WITH TEMPLATE:CREATE DATABASEnameWITH TEMPLATE =template;
CREATE INDEX
CREATE INDEX CONCURRENTLY wird für Sharded-Tabellen unterstützt:
CREATE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX wird für alle Tabellentypen unterstützt:
CREATE UNIQUE INDEXindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX CONCURRENTLY wird nicht unterstützt:
CREATE UNIQUE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
Weitere Informationen finden Sie unter UNIQUE. Allgemeine Informationen zum Erstellen von Indizes finden Sie im Abschnitt CREATE INDEX
- Anzeigen von Indizes
-
Nicht alle Indizes sind auf Routern sichtbar, wenn Sie
\doder ähnliche Befehle verwenden. Verwenden Sie stattdessen die Ansichttable_namepg_catalog.pg_indexes, um Indizes abzurufen, wie im folgenden Beispiel gezeigt.SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"id"}'; CREATE TABLE items (id int PRIMARY KEY, val int); CREATE INDEX items_my_index on items (id, val); postgres_limitless=> SELECT * FROM pg_catalog.pg_indexes WHERE tablename='items'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+----------------+------------+------------------------------------------------------------------------ public | items | items_my_index | | CREATE INDEX items_my_index ON ONLY public.items USING btree (id, val) public | items | items_pkey | | CREATE UNIQUE INDEX items_pkey ON ONLY public.items USING btree (id) (2 rows)
CREATE SCHEMA
CREATE SCHEMA mit einem Schemaelement wird nicht unterstützt:
CREATE SCHEMAmy_schemaCREATE TABLE (column_nameINT);
Es tritt ein Fehler auf, der in etwa folgendermaßen aussieht:
ERROR: CREATE SCHEMA with schema elements is not supported
CREATE TABLE
Beziehungen in CREATE TABLE-Anweisungen werden nicht unterstützt, zum Beispiel:
CREATE TABLE orders (orderid int, customerId int, orderDate date) WITH (autovacuum_enabled = false);
IDENTITY-Spalten werden nicht unterstützt, zum Beispiel:
CREATE TABLE orders (orderid INT GENERATED ALWAYS AS IDENTITY);
Aurora PostgreSQL Limitless Database unterstützt bis zu 54 Zeichen für Namen von Sharded-Tabellen.
CREATE TABLE AS
Wenn Sie eine Tabelle mit CREATE TABLE AS erstellen möchten, müssen Sie die Variable rds_aurora.limitless_create_table_mode verwenden. Für Sharded-Tabellen müssen Sie außerdem die Variable rds_aurora.limitless_create_table_shard_key verwenden. Weitere Informationen finden Sie unter Erstellen von Limitless-Tabellen mithilfe von Variablen.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; CREATE TABLE ctas_table AS SELECT 1 a; -- "source" is the source table whose columns and data types are used to create the new "ctas_table2" table. CREATE TABLE ctas_table2 AS SELECT a,b FROM source;
Sie können CREATE TABLE AS nicht zum Erstellen von Referenztabellen verwenden, da sie Primärschlüsselbeschränkungen erfordern. CREATE TABLE
AS propagiert Primärschlüssel nicht an neue Tabellen.
Allgemeine Informationen finden Sie im Abschnitt CREATE TABLE AS
DROP DATABASE
Sie können Datenbanken, die Sie erstellt haben, löschen.
Der Befehl DROP DATABASE wird asynchron im Hintergrund ausgeführt. Während der Ausführung erhalten Sie eine Fehlermeldung, wenn Sie versuchen, eine neue Datenbank mit demselben Namen zu erstellen.
SELECT INTO
SELECT INTO funktioniert ähnlich wie CREATE TABLE AS. Sie müssen die Variable rds_aurora.limitless_create_table_mode verwenden. Für Sharded-Tabellen müssen Sie außerdem die Variable rds_aurora.limitless_create_table_shard_key verwenden. Weitere Informationen finden Sie unter Erstellen von Limitless-Tabellen mithilfe von Variablen.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; -- "source" is the source table whose columns and data types are used to create the new "destination" table. SELECT * INTO destination FROM source;
Derzeit wird der Vorgang SELECT INTO über den Router ausgeführt, nicht direkt über die Shards. Dies kann die Leistung beeinträchtigen.
Weitere Informationen dazu finden Sie im Abschnitt SELECT INTO
Beschränkungen
Die folgenden Einschränkungen gelten für Beschränkungen in Aurora PostgreSQL Limitless Database.
- CHECK
-
Einfache Beschränkungen, die Vergleichsoperatoren mit Literalen beinhalten, werden unterstützt. Komplexere Ausdrücke und Beschränkungen, die Funktionsvalidierungen erfordern, werden nicht unterstützt, wie in den folgenden Beispielen gezeigt.
CREATE TABLE my_table ( id INT CHECK (id > 0) -- supported , val INT CHECK (val > 0 AND val < 1000) -- supported , tag TEXT CHECK (length(tag) > 0) -- not supported: throws "Expression inside CHECK constraint is not supported" , op_date TIMESTAMP WITH TIME ZONE CHECK (op_date <= now()) -- not supported: throws "Expression inside CHECK constraint is not supported" );Sie können Beschränkungen explizite Namen geben, wie im folgenden Beispiel gezeigt.
CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , val INT CONSTRAINT val_in_range CHECK (val > 0 AND val < 1000) );Sie können die Beschränkungssyntax auf Tabellenebene mit der Beschränkung
CHECKverwenden, wie im folgenden Beispiel gezeigt.CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , min_val INT CONSTRAINT min_val_in_range CHECK (min_val > 0 AND min_val < 1000) , max_val INT , CONSTRAINT max_val_in_range CHECK (max_val > 0 AND max_val < 1000 AND max_val > min_val) ); - EXCLUDE
-
Ausschlussbeschränkungen werden in Aurora PostgreSQL Limitless Database nicht unterstützt.
- FOREIGN KEY
-
Weitere Informationen finden Sie unter Fremdschlüssel.
- NOT NULL
-
NOT NULL-Beschränkungen werden uneingeschränkt unterstützt. - PRIMARY KEY
-
Der Primärschlüssel impliziert eindeutige Beschränkungen, weshalb die Einschränkungen für eindeutige Beschränkungen auch für den Primärschlüssel gelten. Das bedeutet Folgendes:
-
Wenn eine Tabelle in eine Sharded-Tabelle konvertiert wird, muss der Shard-Schlüssel eine Teilmenge des Primärschlüssels sein. Das heißt, der Primärschlüssel enthält alle Spalten des Shard-Schlüssels.
-
Wenn eine Tabelle in eine Referenztabelle konvertiert wird, muss sie einen Primärschlüssel haben.
Die folgenden Beispiele veranschaulichen die Verwendung von Primärschlüsseln.
-- Create a standard table. CREATE TABLE public.my_table ( item_id INT , location_code INT , val INT , comment text ); -- Change the table to a sharded table using the 'item_id' and 'location_code' columns as shard keys. CALL rds_aurora.limitless_alter_table_type_sharded('public.my_table', ARRAY['item_id', 'location_code']);Hier wird versucht, einen Primärschlüssel hinzuzufügen, der keinen Shard-Schlüssel enthält:
-- Add column 'item_id' as the primary key. -- Invalid because the primary key doesnt include all columns from the shard key: -- 'location_code' is part of the shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR -- add column "val" as primary key -- Invalid because primary key does not include all columns from shard key: -- item_id and location_code iare part of shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERRORHier wird versucht, einen Primärschlüssel hinzuzufügen, der einen Shard-Schlüssel enthält:
-- Add the 'item_id' and 'location_code' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code); -- OK -- Add the 'item_id', 'location_code', and 'val' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code, val); -- OKIn diesem Beispiel wird eine Standardtabelle in eine Referenztabelle konvertiert:
-- Create a standard table. CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR); -- Convert the table to a reference table. CALL rds_aurora.limitless_alter_table_type_reference('public.zipcode');Weitere Informationen zum Erstellen von Sharded-Tabellen und Referenztabellen finden Sie unter Erstellen von Tabellen in Aurora PostgreSQL Limitless Database.
-
- UNIQUE
-
In Sharded-Tabellen muss der eindeutige Schlüssel den Shard-Schlüssel enthalten, das heißt, der Shard-Schlüssel muss eine Teilmenge des eindeutigen Schlüssels sein. Dies wird überprüft, wenn der Tabellentyp in „Sharded“ geändert wird. In Referenztabellen gibt es keine Einschränkung.
CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT UNIQUE );Table-level
UNIQUEEinschränkungen werden unterstützt, wie im folgenden Beispiel gezeigt.CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT , CONSTRAINT zipcode_and_email UNIQUE (zipcode, email) );Das folgende Beispiel zeigt die gemeinsame Verwendung eines Primärschlüssels und eines eindeutigen Schlüssels. Beide Schlüssel müssen den Shard-Schlüssel enthalten.
SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"p_id"}'; CREATE TABLE t1 ( p_id BIGINT NOT NULL, c_id BIGINT NOT NULL, PRIMARY KEY (p_id), UNIQUE (p_id, c_id) );
Weitere Informationen finden Sie im Abschnitt Beschränkungen
Standardwerte
Aurora PostgreSQL Limitless Database unterstützt Ausdrücke in Standardwerten.
Das folgende Beispiel veranschaulicht die Verwendung von Standardwerten.
CREATE TABLE t ( a INT DEFAULT 5, b TEXT DEFAULT 'NAN', c NUMERIC ); CALL rds_aurora.limitless_alter_table_type_sharded('t', ARRAY['a']); INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c ---+-----+--- 5 | NAN | (1 row)
Ausdrücke werden unterstützt, wie im folgenden Beispiel gezeigt.
CREATE TABLE t1 (a NUMERIC DEFAULT random());
Im folgenden Beispiel wird eine neue Spalte hinzugefügt, die NOT NULL ist und einen Standardwert hat.
ALTER TABLE t ADD COLUMN d BOOLEAN NOT NULL DEFAULT FALSE; SELECT * FROM t; a | b | c | d ---+-----+---+--- 5 | NAN | | f (1 row)
Im folgenden Beispiel wird eine vorhandene Spalte geändert und ein Standardwert hinzugefügt.
ALTER TABLE t ALTER COLUMN c SET DEFAULT 0.0; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f (2 rows)
Im folgenden Beispiel wird ein Standardwert entfernt.
ALTER TABLE t ALTER COLUMN a DROP DEFAULT; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f | NAN | 0.0 | f (3 rows)
Weitere Informationen finden Sie im Abschnitt Standardwerte
Erweiterungen
Die folgenden PostgreSQL-Erweiterungen werden in Aurora PostgreSQL Limitless Database unterstützt:
-
aurora_limitless_fdw: Diese Erweiterung ist vorinstalliert. Sie können sie nicht löschen. -
aws_s3: Diese Erweiterung funktioniert in Aurora PostgreSQL Limitless Database ähnlich wie in Aurora PostgreSQL.Sie können Daten aus einem Amazon-S3-Bucket in den DB-Cluster einer Aurora PostgreSQL Limitless Database importieren oder Daten aus dem DB-Cluster einer Aurora PostgreSQL Limitless Database in einen Amazon-S3-Bucket exportieren. Weitere Informationen erhalten Sie unter Importieren von Amazon S3 in einen Aurora-PostgreSQL-DB-Cluster und Exportieren von Daten aus einem/einer Aurora PostgreSQL-DB-Cluster zu Amazon S3.
-
btree_gin -
citext -
ip4r -
pg_buffercache: Diese Erweiterung verhält sich in Aurora PostgreSQL Limitless Database anders als in der PostgreSQL-Community. Weitere Informationen finden Sie unter pg_buffercache-Unterschiede in Aurora PostgreSQL Limitless Database. -
pg_stat_statements -
pg_trgm -
pgcrypto -
pgstattuple: Diese Erweiterung verhält sich in Aurora PostgreSQL Limitless Database anders als in der PostgreSQL-Community. Weitere Informationen finden Sie unter pgstattuple-Unterschiede in Aurora PostgreSQL Limitless Database. -
pgvector -
plpgsql: Diese Erweiterung ist vorinstalliert, aber Sie können sie löschen. -
PostGIS: Lange Transaktionen und Tabellenverwaltungsfunktionen werden nicht unterstützt. Die Geo-Referenztabelle lässt sich nicht ändern. -
unaccent -
uuid
Die meisten PostgreSQL-Erweiterungen werden in Aurora PostgreSQL Limitless Database derzeit nicht unterstützt. Sie können jedoch weiterhin die Konfigurationseinstellung shared_preload_libraries
So können Sie beispielsweise die Erweiterung pg_hint_plan zwar laden, es bleibt aber ungewiss, ob die in den Abfragekommentaren übergebenen Hinweise verwendet werden.
Anmerkung
Sie können keine Objekte ändern, die der Erweiterung pg_stat_statementspg_stat_statements finden Sie unter limitless_stat_statements.
Sie können die Funktionen pg_available_extensions und pg_available_extension_versions verwenden, um die Erweiterungen zu finden, die in Aurora PostgreSQL Limitless Database unterstützt werden.
Die folgenden DDLs werden für Erweiterungen unterstützt:
- CREATE EXTENSION
-
Sie können Erweiterungen wie in PostgreSQL erstellen.
CREATE EXTENSION [ IF NOT EXISTS ]extension_name[ WITH ] [ SCHEMAschema_name] [ VERSIONversion] [ CASCADE ]Weitere Informationen finden Sie im Abschnitt CREATE EXTENSION
der PostgreSQL-Dokumentation. - ALTER EXTENSION
-
Die folgenden DDLs werden unterstützt:
ALTER EXTENSIONnameUPDATE [ TOnew_version] ALTER EXTENSIONnameSET SCHEMAnew_schemaWeitere Informationen finden Sie im Abschnitt ALTER EXTENSION
der PostgreSQL-Dokumentation. - DROP EXTENSION
-
Sie können Erweiterungen wie in PostgreSQL löschen.
DROP EXTENSION [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]Weitere Informationen finden Sie im Abschnitt DROP EXTENSION
der PostgreSQL-Dokumentation.
Die folgenden DDLs werden für Erweiterungen nicht unterstützt:
- ALTER EXTENSION
-
Sie können keine Mitgliedsobjekte zu Erweiterungen hinzufügen oder daraus löschen.
ALTER EXTENSIONnameADDmember_objectALTER EXTENSIONnameDROPmember_object
pg_buffercache-Unterschiede in Aurora PostgreSQL Limitless Database
Wenn Sie in Aurora PostgreSQL Limitless Database die Erweiterung pg_buffercachepg_buffercache verwenden, erhalten Sie pufferbezogene Informationen nur von dem Knoten, mit dem Sie gerade verbunden sind: dem Router. Ähnlich erhalten Sie bei Verwendung der Funktion pg_buffercache_summary oder pg_buffercache_usage_counts nur Informationen vom verbundenen Knoten.
Sie können über zahlreiche Knoten verfügen und müssen möglicherweise für jeden Knoten einzeln auf Pufferinformationen zugreifen, um Probleme effektiv zu diagnostizieren. Daher stellt Limitless Database die folgenden Funktionen bereit:
-
rds_aurora.limitless_pg_buffercache(subcluster_id) -
rds_aurora.limitless_pg_buffercache_summary(subcluster_id) -
rds_aurora.limitless_pg_buffercache_usage_counts(subcluster_id)
Durch Eingabe der Subcluster-ID eines beliebigen Knotens, unabhängig davon, ob es sich um einen Router oder einen Shard handelt, können Sie einfach auf die für diesen Knoten spezifischen Pufferinformationen zugreifen. Diese Funktionen sind direkt verfügbar, wenn Sie die Erweiterung pg_buffercache in Limitless Database installieren.
Anmerkung
Aurora PostgreSQL Limitless Database unterstützt diese Funktionen für Version 1.4 und höher der Erweiterung pg_buffercache.
Die in der Ansicht limitless_pg_buffercache angezeigten Spalten unterscheiden sich geringfügig von denen in der Ansicht pg_buffercache:
-
bufferid: bleibt unverändert gegenüberpg_buffercache -
relname: Anstatt wie inpg_buffercachedie Dateiknotennummer anzuzeigen, bildetlimitless_pg_buffercacheden zugehörigenrelnameab, sofern dieser Name in der aktuellen Datenbank oder in gemeinsam genutzten Systemkatalogen verfügbar ist. Andernfalls wirdNULLangezeigt. -
parent_relname: In dieser neuen Spalte, die inpg_buffercachenicht vorhanden ist, wird der übergeordneterelnameangezeigt, wenn der Wert in der Spalterelnameeine partitionierte Tabelle darstellt (im Fall von Sharded-Tabellen). Andernfalls wirdNULLangezeigt. -
spcname: Anstatt wie inpg_buffercacheden Tablespace-Objektbezeichner (OID) anzuzeigen, bildetlimitless_pg_buffercacheden Tablespace-Namen ab. -
datname: Anstatt wie inpg_buffercachedie Datenbank-OID anzuzeigen, bildetlimitless_pg_buffercacheden Datenbanknamen ab. -
relforknumber: bleibt unverändert gegenüberpg_buffercache -
relblocknumber: bleibt unverändert gegenüberpg_buffercache -
isdirty: bleibt unverändert gegenüberpg_buffercache -
usagecount: bleibt unverändert gegenüberpg_buffercache -
pinning_backends: bleibt unverändert gegenüberpg_buffercache
Die Spalten in den Ansichten limitless_pg_buffercache_summary und limitless_pg_buffercache_usage_counts sind dieselben wie in den regulären Ansichten pg_buffercache_summary und pg_buffercache_usage_counts.
Mithilfe dieser Funktionen können Sie auf detaillierte Informationen zum Puffercache aller Knoten in Ihrer Limitless-Database-Umgebung zugreifen und so eine effektivere Diagnose und Verwaltung Ihrer Datenbanksysteme ermöglichen.
pgstattuple-Unterschiede in Aurora PostgreSQL Limitless Database
In Aurora PostgreSQL unterstützt die Erweiterung pgstattuple
Wir wissen, wie wichtig diese Erweiterung für das Abrufen von Statistiken auf Tupel-Ebene ist – eine wichtige Voraussetzung, um Tabellen- und Indexüberlastungen vermeiden und Diagnoseinformationen erfassen zu können. Daher unterstützt Aurora PostgreSQL Limitless Database die Erweiterung pgstattuple in unbegrenzten Datenbanken.
Aurora PostgreSQL Limitless Database enthält die folgenden Funktionen im Schema rds_aurora:
- Tuple-level Statistikfunktionen
-
rds_aurora.limitless_pgstattuple(relation_name)-
Zweck: Statistiken auf Tupel-Ebene für Standardtabellen und deren Indizes extrahieren
-
Eingabe:
relation_name(Text): der Beziehungsname -
Ausgabe: Spalten, die mit denen übereinstimmen, die von der Funktion
pgstattuplein Aurora PostgreSQL zurückgegeben werden
rds_aurora.limitless_pgstattuple(relation_name,subcluster_id)-
Zweck: Statistiken auf Tupel-Ebene für Referenztabellen, Sharded-Tabellen, Katalogtabellen und deren Indizes extrahieren
-
Eingabe:
-
relation_name(Text): der Beziehungsname -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Statistiken extrahiert werden sollen
-
-
Ausgabe:
-
Bei Referenz- und Katalogtabellen (einschließlich ihrer Indizes) stimmen die Spalten mit denen in Aurora PostgreSQL überein.
-
Bei Sharded-Tabellen stellen die Statistiken nur die Partition der Tabelle dar, die sich auf dem angegebenen Subcluster befindet.
-
-
- Funktionen für Indexstatistiken
-
rds_aurora.limitless_pgstatindex(relation_name)-
Zweck: Extrahieren Sie Statistiken für B-tree Indizes in Standardtabellen
-
Eingabe:
relation_name(Text) — Der Name des Indexes B-tree -
Ausgabe: Alle Spalten außer
root_block_nowerden zurückgegeben. Die zurückgegebenen Spalten stimmen mit denen überein, die die Funktionpgstatindexin Aurora PostgreSQL liefert.
rds_aurora.limitless_pgstatindex(relation_name,subcluster_id)-
Zweck: Extrahieren Sie Statistiken für B-tree Indizes in Referenztabellen, Shard-Tabellen und Katalogtabellen.
-
Eingabe:
-
relation_name(Text) — Der Name des Indexes B-tree -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Statistiken extrahiert werden sollen
-
-
Ausgabe:
-
Bei Indizes von Referenz- und Katalogtabellen werden alle Spalten (außer
root_block_no) zurückgegeben. Die zurückgegebenen Spalten stimmen mit denen in Aurora PostgreSQL überein. -
Bei Sharded-Tabellen stellen die Statistiken nur die Partition des Indexes der Tabelle dar, die sich auf dem angegebenen Subcluster befindet. Die Spalte
tree_levelzeigt den Durchschnitt aller Tabellenausschnitte im angeforderten Subcluster.
-
rds_aurora.limitless_pgstatginindex(relation_name)-
Zweck: Statistiken für GINs (Generalized Inverted Indexes) von Standardtabellen extrahieren
-
Eingabe:
relation_name(Text): der Name des GIN -
Ausgabe: Spalten, die mit denen übereinstimmen, die von der Funktion
pgstatginindexin Aurora PostgreSQL zurückgegeben werden
rds_aurora.limitless_pgstatginindex(relation_name,subcluster_id)-
Zweck: Statistiken für GINs von Referenz-, Sharded- und Katalogtabellen extrahieren
-
Eingabe:
-
relation_name(Text): der Name des Indexes -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Statistiken extrahiert werden sollen
-
-
Ausgabe:
-
Bei GINs von Referenz- und Katalogtabellen stimmen die Spalten mit denen in Aurora PostgreSQL überein.
-
Bei Sharded-Tabellen stellen die Statistiken nur die Partition des Indexes der Tabelle dar, die sich auf dem angegebenen Subcluster befindet.
-
rds_aurora.limitless_pgstathashindex(relation_name)-
Zweck: Statistiken für Hash-Indizes von Standardtabellen extrahieren
-
Eingabe:
relation_name(Text): der Name des Hash-Indexes -
Ausgabe: Spalten, die mit denen übereinstimmen, die von der Funktion
pgstathashindexin Aurora PostgreSQL zurückgegeben werden
rds_aurora.limitless_pgstathashindex(relation_name,subcluster_id)-
Zweck: Statistiken für Hash-Indizes von Referenz-, Sharded- und Katalogtabellen extrahieren
-
Eingabe:
-
relation_name(Text): der Name des Indexes -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Statistiken extrahiert werden sollen
-
-
Ausgabe:
-
Bei Hash-Indizes von Referenz- und Katalogtabellen stimmen die Spalten mit denen in Aurora PostgreSQL überein.
-
Bei Sharded-Tabellen stellen die Statistiken nur die Partition des Indexes der Tabelle dar, die sich auf dem angegebenen Subcluster befindet.
-
-
- Funktionen zur Seitenanzahl
-
rds_aurora.limitless_pg_relpages(relation_name)-
Zweck: die Seitenanzahl für Standardtabellen und deren Indizes extrahieren
-
Eingabe:
relation_name(Text): der Beziehungsname -
Ausgabe: die Seitenanzahl der angegebenen Beziehung
rds_aurora.limitless_pg_relpages(relation_name,subcluster_id)-
Zweck: die Seitenanzahl für Referenz-, Sharded- und Katalogtabellen (einschließlich ihrer Indizes) extrahieren
-
Eingabe:
-
relation_name(Text): der Beziehungsname -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Seitenanzahl extrahiert werden soll
-
-
Ausgabe: Bei Sharded-Tabellen entspricht die Seitenanzahl der Summe der Seiten aus allen Tabellenausschnitten des angegebenen Subclusters.
-
- Funktionen für annähernde Statistiken auf Tupel-Ebene
-
rds_aurora.limitless_pgstattuple_approx(relation_name)-
Zweck: annähernde Statistiken auf Tupel-Ebene für Standardtabellen und deren Indizes extrahieren
-
Eingabe:
relation_name(Text): der Beziehungsname -
Ausgabe: Spalten, die mit denen übereinstimmen, die von der Funktion pgstattuple_approx in Aurora PostgreSQL zurückgegeben werden
rds_aurora.limitless_pgstattuple_approx(relation_name,subcluster_id)-
Zweck: annähernde Statistiken auf Tupel-Ebene für Referenz-, Sharded- und Katalogtabellen (sowie deren Indizes) extrahieren
-
Eingabe:
-
relation_name(Text): der Beziehungsname -
subcluster_id(Text): die Subcluster-ID des Knotens, auf dem die Statistiken extrahiert werden sollen
-
-
Ausgabe:
-
Bei Referenz- und Katalogtabellen (einschließlich ihrer Indizes) stimmen die Spalten mit denen in Aurora PostgreSQL überein.
-
Bei Sharded-Tabellen stellen die Statistiken nur die Partition der Tabelle dar, die sich auf dem angegebenen Subcluster befindet.
-
-
Anmerkung
Derzeit unterstützt Aurora PostgreSQL Limitless Database die Erweiterung pgstattuple für materialisierte Ansichten, TOAST-Tabellen oder temporäre Tabellen nicht.
In Aurora PostgreSQL Limitless Database müssen Sie die Eingabe als Text bereitstellen, obwohl Aurora PostgreSQL auch andere Formate unterstützt.
Fremdschlüssel
Beschränkungen bezüglich Fremdschlüsseln (FOREIGN KEY) werden mit einigen Einschränkungen unterstützt:
-
CREATE TABLEmitFOREIGN KEYwird nur für Standardtabellen unterstützt. Wenn SieFOREIGN KEYverwenden möchten, um eine Sharded- oder Referenztabelle anzufertigen, erstellen Sie zunächst die Tabelle ohne Fremdschlüsselbeschränkung. Ändern Sie sie dann mit der folgenden Anweisung:ALTER TABLE ADD CONSTRAINT; -
Eine Standardtabelle kann nicht in eine Sharded- oder Referenztabelle konvertiert werden, wenn für die Tabelle eine Fremdschlüsselbeschränkung gilt. Löschen Sie die Beschränkung und fügen Sie sie nach der Konvertierung hinzu.
-
Die folgenden Einschränkungen gelten für die verschiedenen Tabellentypen, was Fremdschlüsselbeschränkungen betrifft:
-
Für eine Standardtabelle kann eine Fremdschlüsselbeschränkung hinsichtlich einer anderen Standardtabelle gelten.
-
Für eine Sharded-Tabelle kann eine Fremdschlüsselbeschränkung gelten, wenn die übergeordneten und untergeordneten Tabellen nebeneinander angeordnet sind und der Fremdschlüssel eine Obermenge des Shard-Schlüssels bildet.
-
Für eine Sharded-Tabelle kann eine Fremdschlüsselbeschränkung hinsichtlich einer Referenztabelle gelten.
-
Für eine Referenztabelle kann eine Fremdschlüsselbeschränkung hinsichtlich einer anderen Referenztabelle gelten.
-
Fremdschlüsseloptionen
Fremdschlüssel werden in Aurora PostgreSQL Limitless Database für einige DDL-Optionen unterstützt. In der folgenden Tabelle sind Optionen aufgeführt, die zwischen Tabellen in Aurora PostgreSQL Limitless Database unterstützt und nicht unterstützt werden.
| DDL-Option | Referenz zu Referenz | Sharded zu Sharded (nebeneinander angeordnet) | Sharded zu Referenz | Standard zu Standard |
|---|---|---|---|---|
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Nein | Nein | Nein | Nein |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Nein | Nein | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Nein | Nein | Nein | Nein |
|
|
Ja | Nein | Nein | Ja |
|
|
Nein | Nein | Nein | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Ja | Ja | Ja | Ja |
|
|
Nein | Nein | Nein | Nein |
|
|
Ja | Nein | Nein | Ja |
Beispiele
-
Standard zu Standard:
set rds_aurora.limitless_create_table_mode='standard'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer REFERENCES products (product_no), quantity integer ); SELECT constraint_name, table_name, constraint_type FROM information_schema.table_constraints WHERE constraint_type='FOREIGN KEY'; constraint_name | table_name | constraint_type -------------------------+-------------+----------------- orders_product_no_fkey | orders | FOREIGN KEY (1 row) -
Sharded zu Sharded (nebeneinander angeordnet):
set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"product_no"}'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; set rds_aurora.limitless_create_table_collocate_with='products'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Sharded zu Referenz:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Referenz zu Referenz:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no);
Funktionen
Funktionen werden in Aurora PostgreSQL Limitless Database unterstützt.
Die folgenden DDLs werden für Funktionen unterstützt:
- CREATE FUNCTION
-
Mit diesem Befehl können Sie Funktionen wie in Aurora PostgreSQL erstellen. Sie können damit nur nicht ihre Volatilität ändern, während Sie sie ersetzen.
Weitere Informationen finden Sie im Abschnitt CREATE FUNCTION
der PostgreSQL-Dokumentation. - ALTER FUNCTION
-
Mit diesem Befehl können Sie Funktionen wie in Aurora PostgreSQL ändern, nur nicht ihre Volatilität.
Weitere Informationen finden Sie im Abschnitt ALTER FUNCTION
der PostgreSQL-Dokumentation. - DROP FUNCTION
-
Sie können Funktionen wie in Aurora PostgreSQL löschen.
DROP FUNCTION [ IF EXISTS ]name[ ( [ [argmode] [argname]argtype[, ...] ] ) ] [, ...] [ CASCADE | RESTRICT ]Weitere Informationen finden Sie im Abschnitt DROP FUNCTION
der PostgreSQL-Dokumentation.
Verteilung der Funktionen
Wenn alle Anweisungen einer Funktion auf einen einzelnen Shard ausgerichtet sind, empfiehlt es sich, die gesamte Funktion auf den Ziel-Shard zu übertragen. Auf diese Weise wird das Ergebnis zurück an den Router propagiert und die Funktion wird nicht am Router selbst aufgedröselt. Die Pushdown-Option für Funktionen und gespeicherte Verfahren ist nützlich für Kunden, die ihre Funktion oder ihr gespeichertes Verfahren näher an der Datenquelle, also dem Shard, ausführen möchten.
Um eine Funktion zu verteilen, müssen Sie sie zuerst erstellen und dann das Verfahren rds_aurora.limitless_distribute_function aufrufen. Für diese Funktion gilt folgende Syntax:
SELECT rds_aurora.limitless_distribute_function('function_prototype', ARRAY['shard_key'], 'collocating_table');
Die Funktion nutzt die folgenden Parameter:
-
function_prototypeWenn eines der Argumente als
OUT-Parameter definiert ist, nehmen Sie seinen Typ nicht in die Argumente vonfunction_prototypeauf. -
ARRAY[': die Liste der Funktionsargumente, die als Shard-Schlüssel für die Funktion identifiziert wurdenshard_key'] -
collocating_table
Um den Shard zu identifizieren, auf dem diese Funktion ausgeführt werden soll, hasht das System das Argument ARRAY[' und erkennt in shard_key']collocating_table
- Einschränkungen
-
Wenn Sie eine Funktion oder ein Verfahren verteilen, befasst sie oder es sich nur mit Daten, die durch den Shard-Schlüsselbereich in diesem Shard begrenzt sind. In Fällen, in denen Funktionen oder Verfahren versuchen, auf Daten von einem anderen Shard zuzugreifen, unterscheiden sich die von den verteilten Funktionen oder Verfahren zurückgegeben Ergebnisse von denen der nicht verteilten Funktionen oder Verfahren.
Sie erstellen beispielsweise eine Funktion, die Abfragen enthält, die mehrere Shards betreffen werden, rufen dann aber das Verfahren
rds_aurora.limitless_distribute_functionauf, um sie zu verteilen. Wenn Sie diese Funktion aufrufen, indem Sie Argumente für einen Shard-Schlüssel angeben, werden die Ergebnisse ihrer Ausführung wahrscheinlich durch die in diesem Shard vorhandenen Werte begrenzt. Die Ergebnisse unterscheiden sich von denen, die ohne Verteilung der Funktion generiert wurden. - Beispiele
-
Nehmen wir an, wir haben die Funktion
func, die Sharded-Tabellecustomersund den Shard-Schlüsselcustomer_id.postgres_limitless=> CREATE OR REPLACE FUNCTION func(c_id integer, sc integer) RETURNS int language SQL volatile AS $$ UPDATE customers SET score = sc WHERE customer_id = c_id RETURNING score; $$;Jetzt verteilen wir diese Funktion:
SELECT rds_aurora.limitless_distribute_function('func(integer, integer)', ARRAY['c_id'], 'customers');Im Folgenden sehen Sie Beispiel-Abfragepläne.
EXPLAIN(costs false, verbose true) SELECT func(27+1,10); QUERY PLAN -------------------------------------------------- Foreign Scan Output: (func((27 + 1), 10)) Remote SQL: SELECT func((27 + 1), 10) AS func Single Shard Optimized (4 rows)EXPLAIN(costs false, verbose true) SELECT * FROM customers,func(customer_id, score) WHERE customer_id=10 AND score=27; QUERY PLAN --------------------------------------------------------------------- Foreign Scan Output: customer_id, name, score, func Remote SQL: SELECT customers.customer_id, customers.name, customers.score, func.func FROM public.customers, LATERAL func(customers.customer_id, customers.score) func(func) WHERE ((customers.customer_id = 10) AND (customers.score = 27)) Single Shard Optimized (10 rows)Das folgende Beispiel zeigt ein Verfahren mit
IN- undOUT-Parametern als Argumente.CREATE OR REPLACE FUNCTION get_data(OUT id INTEGER, IN arg_id INT) AS $$ BEGIN SELECT customer_id, INTO id FROM customer WHERE customer_id = arg_id; END; $$ LANGUAGE plpgsql;Das folgende Beispiel verteilt das Verfahren nur unter Verwendung von
IN-Parametern.EXPLAIN(costs false, verbose true) SELECT * FROM get_data(1); QUERY PLAN ----------------------------------- Foreign Scan Output: id Remote SQL: SELECT customer_id FROM get_data(1) get_data(id) Single Shard Optimized (6 rows)
Funktionsvolatilität
Sie können feststellen, ob eine Funktion unveränderlich, stabil oder volatil ist, indem Sie den Wert provolatile in der Ansicht pg_procprovolatile gibt an, ob das Ergebnis der Funktion nur von ihren Eingabeargumenten abhängt oder auch von externen Faktoren beeinflusst wird.
Der Wert ist einer der folgenden:
-
i: unveränderliche Funktionen, die immer dasselbe Ergebnis für dieselben Eingaben liefern -
s: stabile Funktionen, deren Ergebnisse (für feste Eingaben) sich innerhalb eines Scans nicht ändern -
v: flüchtige Funktionen, deren Ergebnisse sich jederzeit ändern können Nutzen Sievauch für Funktionen mit Nebeneffekten, sodass deren Aufrufe nicht einfach optimiert werden können.
Die folgenden Beispiele zeigen flüchtige Funktionen.
SELECT proname, provolatile FROM pg_proc WHERE proname='pg_sleep'; proname | provolatile ----------+------------- pg_sleep | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='uuid_generate_v4'; proname | provolatile ------------------+------------- uuid_generate_v4 | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='nextval'; proname | provolatile ---------+------------- nextval | v (1 row)
Die Volatilität einer vorhandenen Funktion lässt sich in Aurora PostgreSQL Limitless Database nicht ändern. Dies gilt gleichermaßen für Befehle des Typs ALTER FUNCTION und des Typs CREATE OR REPLACE FUNCTION, wie in den folgenden Beispielen gezeigt.
-- Create an immutable function CREATE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$IMMUTABLE; -- Altering the volatility throws an error ALTER FUNCTION immutable_func1 STABLE; -- Replacing the function with altered volatility throws an error CREATE OR REPLACE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$VOLATILE;
Wir empfehlen Ihnen dringend, Funktionen die richtigen Volatilitäten zuzuweisen. Wenn Ihre Funktion beispielsweise SELECT aus mehreren Tabellen verwendet oder auf Datenbankobjekte verweist, legen Sie sie nicht als IMMUTABLE fest. Wenn sich der Tabelleninhalt jemals ändert, geht damit die Unveränderlichkeit verloren.
Aurora PostgreSQL erlaubt SELECT innerhalb von unveränderlichen Funktionen, aber die Ergebnisse könnten falsch sein. Aurora PostgreSQL Limitless Database kann sowohl Fehler als auch falsche Ergebnisse zurückgeben. Weitere Informationen finden Sie im Abschnitt Volatilitätskategorien von Funktionen
Sequenzen
Benannte Sequenzen sind Datenbankobjekte, die eindeutige Zahlen in auf- oder absteigender Reihenfolge generieren. CREATE SEQUENCE erstellt einen Generator für neue Sequenznummern. Sequenzwerte sind garantiert eindeutig.
Wenn Sie eine benannte Sequenz in Aurora PostgreSQL Limitless Database erstellen, wird ein verteiltes Sequenzobjekt erstellt. Daraufhin verteilt Aurora PostgreSQL Limitless Database nicht überlappende Blöcke von Sequenzwerten auf alle Distributed Transaction Router (Router). Blöcke werden auf Routern als lokale Sequenzobjekte dargestellt; daher werden Sequenzoperationen wie nextval und currval lokal ausgeführt. Router arbeiten unabhängig voneinander und fordern bei Bedarf neue Blöcke aus der verteilten Sequenz an.
Weitere Informationen zu Sequenzen finden Sie im Abschnitt CREATE SEQUENCE
Themen
Anfordern eines neuen Blocks
Sie konfigurieren die Größe der Blöcke, die Routern zugewiesen werden, mithilfe des Parameters rds_aurora.limitless_sequence_chunk_size. Der Standardwert ist 250000. Jeder Router besitzt zunächst zwei Blöcke: einen aktiven und einen reservierten. Aktive Blöcke werden verwendet, um lokale Sequenzobjekte zu konfigurieren (Einstellung minvalue undmaxvalue), und reservierte Blöcke werden in einer internen Katalogtabelle gespeichert. Wenn ein aktiver Block den Mindest- oder Höchstwert erreicht, wird er durch den reservierten Block ersetzt. Dazu wird ALTER SEQUENCE intern verwendet, was bedeutet, dass AccessExclusiveLock erworben wird.
Hintergrund-Worker werden alle 10 Sekunden auf Router-Knoten ausgeführt, um Sequenzen nach verwendeten reservierten Blöcken zu durchsuchen. Wenn ein verwendeter Block gefunden wird, fordert der Worker bei der verteilten Sequenz einen neuen Block an. Achten Sie darauf, die Blockgröße so festzulegen, dass die Hintergrund-Worker genügend Zeit haben, neue Blöcke anzufordern. Remoteanfragen treten niemals im Kontext von Benutzersitzungen auf, was bedeutet, dass Sie nicht direkt eine neue Sequenz anfordern können.
Einschränkungen
Die folgenden Einschränkungen gelten für Sequenzen in Aurora PostgreSQL Limitless Database:
-
Der
pg_sequence-Katalog, diepg_sequences-Funktion und dieSELECT * FROM-Anweisung zeigen alle nur den lokalen Sequenzstatus, nicht den verteilten Status.sequence_name -
Sequenzwerte sind garantiert eindeutig und innerhalb einer Sitzung garantiert monoton. Sie können jedoch bei
nextval-Anweisungen, die in anderen Sitzungen ausgeführt werden, in Unordnung geraten, wenn diese Sitzungen mit anderen Routern verbunden sind. -
Stellen Sie sicher, dass die Sequenzgröße (Anzahl der verfügbaren Werte) ausreicht, um auf alle Router verteilt zu werden. Verwenden Sie den Parameter
rds_aurora.limitless_sequence_chunk_size, um diechunk_sizezu konfigurieren. (Jeder Router hat zwei Blöcke.) -
Die
CACHE-Option wird unterstützt, aber der Cache muss kleiner sein alschunk_size.
Nicht unterstützte Optionen
Die folgenden Optionen werden für Sequenzen in Aurora PostgreSQL Limitless Database nicht unterstützt.
- Sequenz-Bearbeitungsfunktionen
-
Die Funktion
setvalwird nicht unterstützt. Weitere Informationen finden Sie im Abschnitt Sequenz-Bearbeitungsfunktionenin der PostgreSQL-Dokumentation. - CREATE SEQUENCE
-
Die folgenden Optionen werden nicht unterstützt.
CREATE [{ TEMPORARY | TEMP} | UNLOGGED] SEQUENCE [[ NO ] CYCLE]Weitere Informationen finden Sie im Abschnitt CREATE SEQUENCE
der PostgreSQL-Dokumentation. - ALTER SEQUENCE
-
Die folgenden Optionen werden nicht unterstützt.
ALTER SEQUENCE [[ NO ] CYCLE]Weitere Informationen finden Sie im Abschnitt ALTER SEQUENCE
der PostgreSQL-Dokumentation. - ALTER TABLE
-
Der Befehl
ALTER TABLEwird für Sequenzen nicht unterstützt.
Beispiele
- CREATE/DROP SEQUENZ
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 1 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16960 | 20 | 1 | 1 | 10000 | 1 | 1 | f (1 row) % connect to another router postgres_limitless=> SELECT nextval('s'); nextval --------- 10001 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16959 | 20 | 10001 | 1 | 20000 | 10001 | 1 | f (1 row) postgres_limitless=> DROP SEQUENCE s; DROP SEQUENCE - ALTER SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> ALTER SEQUENCE s RESTART 500; ALTER SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 500 (1 row) postgres_limitless=> SELECT currval('s'); currval --------- 500 (1 row) - Sequenz-Bearbeitungsfunktionen
-
postgres=# CREATE TABLE t(a bigint primary key, b bigint); CREATE TABLE postgres=# CREATE SEQUENCE s minvalue 0 START 0; CREATE SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b ---+--- 0 | 0 1 | 1 (2 rows) postgres=# ALTER SEQUENCE s RESTART 10000; ALTER SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b -------+------- 0 | 0 1 | 1 10000 | 10000 (3 rows)
Sequenzansichten
Aurora PostgreSQL Limitless Database bietet die folgenden Ansichten für Sequenzen.
- rds_aurora.limitless_distributed_sequence
-
Diese Ansicht zeigt den Status und die Konfiguration einer verteilten Sequenz. Die Spalten
minvalue,maxvalue,start,incundcachehaben dieselbe Bedeutung wie in der Ansicht pg_sequencesund zeigen die Optionen, mit denen die Sequenz erstellt wurde. Die Spalte lastvalzeigt den letzten zugewiesenen oder reservierten Wert in einem verteilten Sequenzobjekt. Dies bedeutet nicht, dass der Wert bereits verwendet wurde, da Router Sequenzblöcke lokal speichern.postgres_limitless=> SELECT * FROM rds_aurora.limitless_distributed_sequence WHERE sequence_name='test_serial_b_seq'; schema_name | sequence_name | lastval | minvalue | maxvalue | start | inc | cache -------------+-------------------+---------+----------+------------+-------+-----+------- public | test_serial_b_seq | 1250000 | 1 | 2147483647 | 1 | 1 | 1 (1 row) - rds_aurora.limitless_sequence_metadata
-
Diese Ansicht zeigt verteilte Sequenzmetadaten und aggregiert Sequenzmetadaten von Cluster-Knoten. Sie verwendet die folgenden Spalten:
-
subcluster_id: die ID des Cluster-Knotens, dem ein Block gehört -
Aktiver Block: ein Block einer Sequenz, der verwendet wird (
active_minvalue,active_maxvalue) -
Reservierter Block: der lokale Block, der als Nächstes verwendet wird (
reserved_minvalue,reserved_maxvalue) -
local_last_value: der zuletzt beobachtete Wert aus einer lokalen Sequenz -
chunk_size: die Größe eines Blocks, wie sie bei der Erstellung konfiguriert wurde
postgres_limitless=> SELECT * FROM rds_aurora.limitless_sequence_metadata WHERE sequence_name='test_serial_b_seq' order by subcluster_id; subcluster_id | sequence_name | schema_name | active_minvalue | active_maxvalue | reserved_minvalue | reserved_maxvalue | chunk_size | chunk_state | local_last_value ---------------+-------------------+-------------+-----------------+-----------------+-------------------+-------------------+------------+-------------+------------------ 1 | test_serial_b_seq | public | 500001 | 750000 | 1000001 | 1250000 | 250000 | 1 | 550010 2 | test_serial_b_seq | public | 250001 | 500000 | 750001 | 1000000 | 250000 | 1 | (2 rows) -
Beheben von Sequenzproblemen
Die folgenden Probleme können bei Sequenzen auftreten.
- Blockgröße reicht nicht aus
-
Wenn für die Blockgröße ein zu geringer Wert festgelegt wurde und die Transaktionsrate hoch ist, haben die Hintergrund-Worker möglicherweise nicht genug Zeit, um neue Blöcke anzufordern, bevor die aktiven Blöcke verbraucht sind. Dies kann zu Konflikten und Warteereignissen wie
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationundLWlock:bufferscontentführen.Erhöhen Sie den Wert des Parameters
rds_aurora.limitless_sequence_chunk_size. - Sequenz-Cache zu hoch
-
In PostgreSQL erfolgt das Sequenz-Caching auf Sitzungsebene. Jede Sitzung weist während eines Zugriffs auf das Sequenzobjekt aufeinanderfolgende Sequenzwerte zu und erhöht den
last_valuedes Sequenzobjekts entsprechend. Sobaldnextvalinnerhalb dieser Sitzung erneut verwendet wird, werden dann einfach die vorab zugewiesenen Werte zurückgegeben, ohne dass auf das Sequenzobjekt zugegriffen wird.Alle Nummern, die innerhalb einer Sitzung zugewiesen, aber nicht verwendet wurden, gehen verloren, wenn die Sitzung endet, was zu „Lücken“ in der Sequenz führt. Dies kann zu einem raschen Verbrauch des sequence_chunk und somit zu Konflikten und Warteereignissen wie
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationundLWlock:bufferscontentführen.Verringern Sie den festgelegten Wert für den Sequenz-Cache.
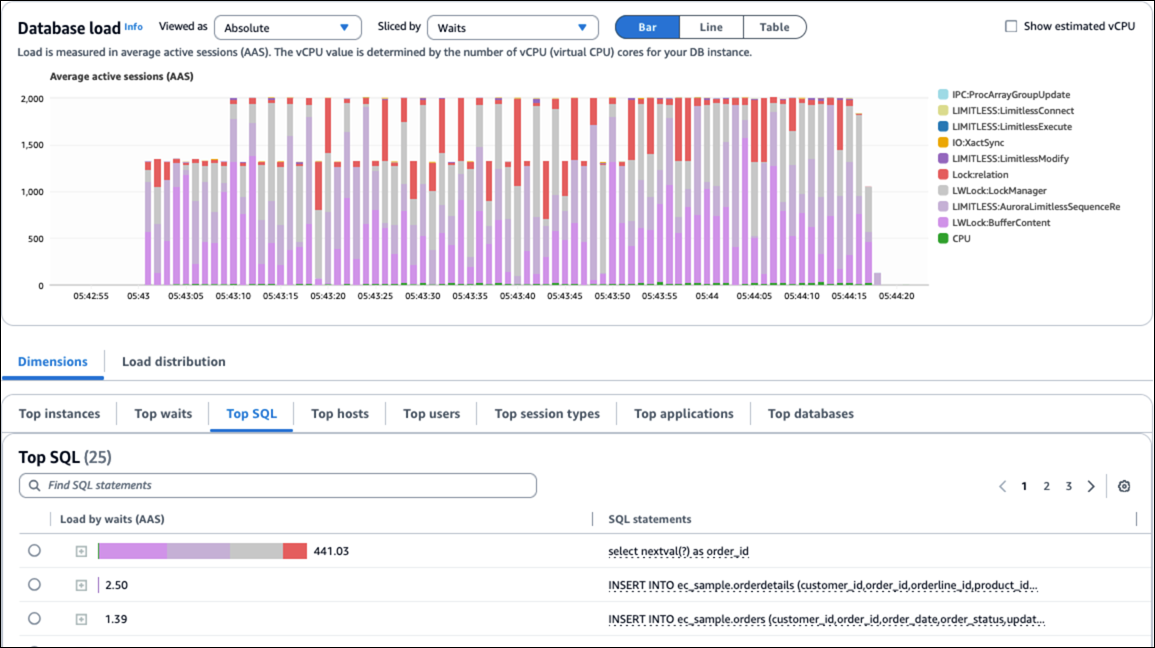
Die folgende Abbildung zeigt Warteereignisse, die durch Sequenzprobleme verursacht wurden.