Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verteilte Deadlocks in Aurora PostgreSQL Limitless Database
In einer DB-Shard-Gruppe können Deadlocks zwischen Transaktionen auftreten, die auf verschiedene Router und Shards verteilt sind. Beispielsweise werden zwei gleichzeitige verteilte Transaktionen mit zwei Shards ausgeführt, wie in der folgenden Abbildung dargestellt.
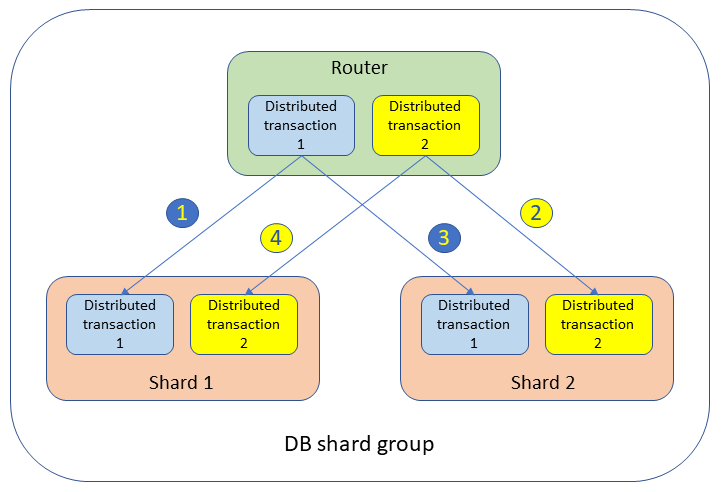
Die Transaktionen sperren Tabellen und erzeugen Warteereignisse in den beiden Shards wie folgt:
-
Verteilte Transaktion 1:
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';Shard 1 bleibt gesperrt.
-
Verteilte Transaktion 2:
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';Shard 2 bleibt gesperrt.
-
Verteilte Transaktion 1:
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';Die verteilte Transaktion 1 wartet auf Shard 2.
-
Verteilte Transaktion 2:
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';Die verteilte Transaktion 2 wartet auf Shard 1.
In diesem Szenario erkennen weder Shard 1 noch Shard 2 das Problem: Transaktion 1 wartet auf Shard 2 auf Transaktion 2 und Transaktion 2 wartet auf Shard 1 auf Transaktion 1. Aus globaler Sicht wartet Transaktion 1 auf Transaktion 2 und Transaktion 2 wartet auf Transaktion 1. Diese Situation, in der zwei Transaktionen auf zwei verschiedenen Shards aufeinander warten, wird als verteilter Deadlock bezeichnet.
Aurora PostgreSQL Limitless Database kann verteilte Deadlocks automatisch erkennen und lösen. Ein Router in der DB-Shard-Gruppe wird benachrichtigt, wenn eine Transaktion zu lange auf den Erwerb einer Ressource wartet. Der Router, der die Benachrichtigung empfängt, beginnt, die erforderlichen Informationen von allen Routern und Shards innerhalb der DB-Shard-Gruppe zu sammeln. Der Router beendet daraufhin Transaktionen, die an einem verteilten Deadlock beteiligt sind, bis die restlichen Transaktionen in der DB-Shard-Gruppe weiter ausgeführt werden können, ohne sich gegenseitig zu blockieren.
Sie erhalten die folgende Fehlermeldung, wenn Ihre Transaktion Teil eines verteilten Deadlocks war und dann vom Router beendet wurde:
ERROR: aborting transaction participating in a distributed deadlock
Der DB-Cluster-Parameter rds_aurora.limitless_distributed_deadlock_timeout legt fest, wie lange jede Transaktion auf einer Ressource wartet, bevor der Router aufgefordert wird, nach einem verteilten Deadlock zu suchen. Sie können den Parameterwert erhöhen, wenn Ihre Workload weniger anfällig für Deadlock-Situationen ist. Der Standardwert ist 1000 Millisekunden (1 Sekunde).
Der Zyklus eines verteilten Deadlocks wird in den PostgreSQL-Protokollen veröffentlicht, wenn ein knotenübergreifender Deadlock gefunden und behoben wurde. Zu den Informationen über jeden Prozess, der Teil des Deadlocks ist, gehören die folgenden:
-
Koordinatorknoten, der die Transaktion gestartet hat
-
ID der virtuellen Transaktions (xid) auf dem Koordinatorknoten im Format
backend_id/backend_local_xid -
ID der verteilten Sitzung der Transaktion
