Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Hinzufügen eines AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank
Sie können das folgende Verfahren verwenden, um einer vorhandenen globalen Datenbank einen zusätzlichen sekundären Cluster hinzuzufügen. Sie können auch eine globale Datenbank aus einem eigenständigen Aurora-DB-Cluster erstellen, indem Sie dieses Verfahren verwenden, um die erste sekundäre AWS Region hinzuzufügen.
Eine globale Aurora-Datenbank benötigt mindestens einen sekundären Aurora-DB-Cluster in einem anderen AWS-Region als dem primären Aurora-DB-Cluster. Sie können bis zu 10 sekundäre DB-Cluster an Ihre globale Aurora-Datenbank anhängen. Wiederholen Sie das folgende Verfahren für jeden neuen sekundären DB-Cluster. Reduzieren Sie für jeden sekundären DB-Cluster, den Sie Ihrer globalen Aurora-Datenbank hinzufügen, die Anzahl der Aurora-Replicas, die für den primären DB-Cluster zulässig sind, um eins.
Wenn Ihre globale Aurora-Datenbank beispielsweise 10 sekundäre Regionen hat, kann Ihr primärer DB-Cluster nur 5 (statt 15) Aurora-Replikate haben. Weitere Informationen finden Sie unter Anforderungen an die Konfiguration einer globalen Amazon-Aurora-Datenbank.
Die Anzahl der Aurora-Replikate (Reader-Instances) im primären DB-Cluster bestimmt die Anzahl der sekundären DB-Cluster, die Sie hinzufügen können. Die Gesamtzahl der Reader-Instances im primären DB-Cluster plus die Anzahl der sekundären Cluster darf nicht mehr als 15 betragen. Wenn Sie zum Beispiel 14 Reader-Instances im primären DB-Cluster und einen sekundären Cluster haben, können Sie der globalen Datenbank keinen weiteren sekundären Cluster hinzufügen.
Anmerkung
Wenn Sie für Aurora MySQL Version 3 einen sekundären Cluster erstellen, stellen Sie sicher, dass der Wert von lower_case_table_names mit dem Wert im primären Cluster übereinstimmt. Diese Einstellung ist ein Datenbankparameter, der beeinflusst, wie der Server die Groß- und Kleinschreibung von Bezeichnern behandelt. Weitere Informationen zu Datenbankparametern finden Sie unter Parametergruppen für Amazon Aurora.
Es wird empfohlen, beim Erstellen eines sekundären Clusters dieselbe DB-Engine-Version für den primären und den sekundären Cluster zu verwenden. Aktualisieren Sie bei Bedarf den primären Cluster auf die Version des sekundären Clusters. Weitere Informationen finden Sie unter Patch-Level-Kompatibilität für verwaltete regionsübergreifende Umstellungen und Failover.
Um ein hinzuzufügen AWS-Region zu einer globalen Aurora-Datenbank
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich AWS Management Console von Datenbanken aus.
-
Wählen Sie die Aurora globale Datenbank aus, die einen sekundären Aurora-DB-Cluster benötigt. Stellen Sie sicher, dass der primäre Aurora-DB-Cluster is
Available. -
Wählen Sie für Aktionen die Option AWS Region hinzufügen aus.
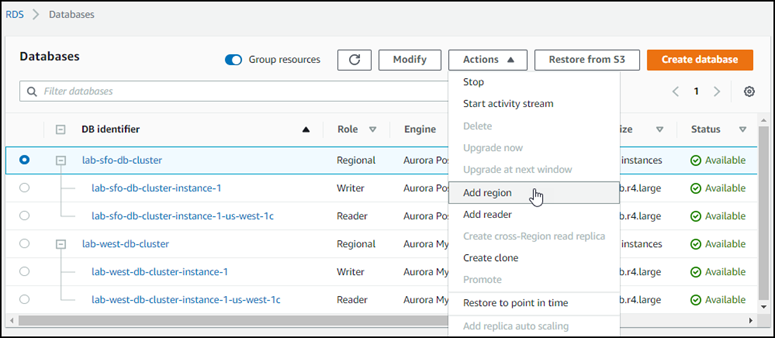
-
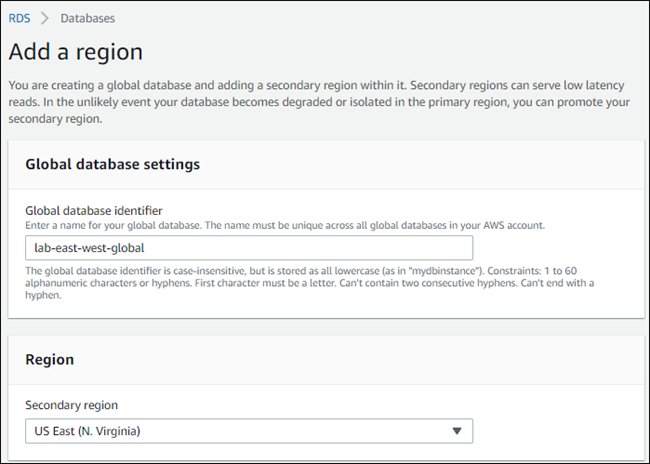
Wählen Sie auf der Seite „Region hinzufügen“ die sekundäre AWS-Region Region aus.
Sie können keinen auswählen AWS-Region , der bereits über einen sekundären Aurora-DB-Cluster für dieselbe globale Aurora-Datenbank verfügt. Außerdem kann dies nicht dieselbe Region sein wie die des primären Aurora-DB-Clusters.
Anmerkung
Die globalen Datenbanken von Babelfish für Aurora PostgreSQL funktionieren nur in sekundären Regionen, wenn die Parameter, die die Babelfish-Einstellungen steuern, in diesen Regionen aktiviert sind. Weitere Informationen finden Sie unter Einstellungen der DB-Cluster-Parametergruppe für Babelfish.
-
Füllen Sie die restlichen Felder für den sekundären Aurora-Cluster in der neuen AWS -Region aus. Dies sind die gleichen Konfigurationsoptionen wie für jede Aurora-DB-Cluster-Instance, mit Ausnahme der folgenden Option nur für Aurora MySQL–basierte globale Aurora-Datenbanken:
Read Replica-Schreibweiterleitung aktivieren – Mit dieser optionalen Einstellung leiten die sekundären DB-Cluster Ihrer globalen Aurora-Datenbank Schreibvorgänge an den primären Cluster weiter. Weitere Informationen finden Sie unter Verwenden der Schreibweiterleitung in einer Amazon Aurora globalen Datenbank.

Wählen Sie „ AWS Region hinzufügen“.
Nachdem Sie die Region zu Ihrer globalen Aurora-Datenbank hinzugefügt haben, können Sie sie in der Liste der Datenbanken sehen, AWS Management Console wie im Screenshot gezeigt.
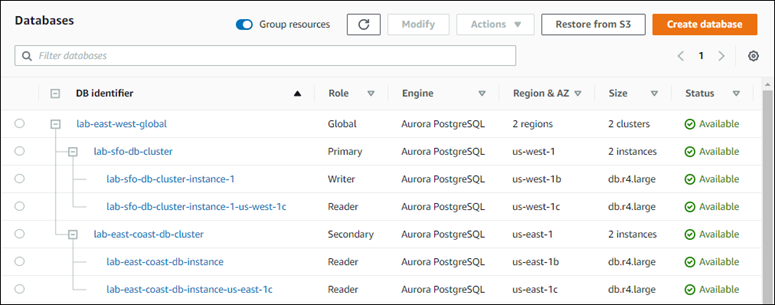
Um einen sekundären hinzuzufügen AWS-Region zu einer globalen Aurora-Datenbank
Um Ihrer globalen Datenbank mithilfe der CLI einen sekundären Cluster hinzuzufügen, müssen Sie bereits über das globale Cluster-Container-Objekt verfügen. Wenn Sie den create-global-cluster-Befehl noch nicht ausgeführt haben, finden Sie weitere Informationen zum CLI-Verfahren unter Erstellen einer globalen Datenbank von Amazon Aurora.
-
Verwenden Sie den
create-db-cluster-CLI-Befehl mit dem Namen (--global-cluster-identifier) Ihrer globalen Aurora-Datenbank. Für andere Parameter, führen Sie die folgenden Schritte aus: Wählen Sie für
--regioneine andere Region AWS-Region als die Ihrer Aurora-Primärregion.-
Wählen Sie bestimmte Werte für die Parameter
--engine-versionund--engineaus. Diese Werte entsprechen denen des primären Aurora-DB-Clusters in Ihrer globalen Aurora-Datenbank. Geben Sie für einen verschlüsselten Cluster Ihren primären Cluster AWS-Region als
--source-regionfür die Verschlüsselung an.
Im folgenden Beispiel wird ein neuer Aurora-DB-Cluster erstellt und als schreibgeschützter sekundärer Aurora-DB-Cluster an eine globale Aurora-Datenbank angehängt. Im letzten Schritt wird dem neuen Aurora-DB-Cluster eine Aurora-DB-Instance hinzugefügt.
Für Linux, macOS oder Unix:
aws rds --regionsecondary_region\ create-db-cluster \ --db-cluster-identifiersecondary_cluster_id\ --global-cluster-identifierglobal_database_id\ --engineaurora-mysql | aurora-postgresql\ --engine-versionversionaws rds --regionsecondary_region\ create-db-instance \ --db-instance-classinstance_class\ --db-cluster-identifiersecondary_cluster_id\ --db-instance-identifierdb_instance_id\ --engineaurora-mysql | aurora-postgresql
Für Windows:
aws rds --regionsecondary_region^ create-db-cluster ^ --db-cluster-identifiersecondary_cluster_id^ --global-cluster-identifierglobal_database_id_id^ --engineaurora-mysql | aurora-postgresql^ --engine-versionversionaws rds --regionsecondary_region^ create-db-instance ^ --db-instance-classinstance_class^ --db-cluster-identifiersecondary_cluster_id^ --db-instance-identifierdb_instance_id^ --engineaurora-mysql | aurora-postgresql
Um einer globalen Aurora-Datenbank mit der RDS-API eine neue AWS-Region hinzuzufügen, führen Sie den Vorgang CreateDBCluster aus. Geben Sie die Kennung der vorhandenen globalen Datenbank mithilfe des Parameters GlobalClusterIdentifier an.
