Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
io/aurora_redo_log_flush
Dieses io/aurora_redo_log_flush-Ereignis tritt ein, wenn eine Sitzung persistente Daten in den Amazon-Aurora-Speicher schreibt.
Unterstützte Engine-Versionen
Diese Warteereignisinformationen werden für die folgenden Engine-Versionen unterstützt:
-
Aurora-MySQL-Version 2
Kontext
Das io/aurora_redo_log_flush Ereignis bezieht sich auf eine write input/output (I/O) -Operation in Aurora MySQL.
Anmerkung
In Aurora MySQL Version 3 hat dieses Wartungsereignis einen Namen io/redo_log_flush.
Wahrscheinliche Ursachen für erhöhte Wartezeiten
Aus Gründen der Datenpersistenz erfordern Commits ein dauerhaftes Schreiben in einen stabilen Speicher. Wenn die Datenbank zu viele Commits durchführt, gibt es bei der I/O Schreiboperation ein Wartungsereignis, das io/aurora_redo_log_flush Wait-Ereignis.
In den folgenden Beispielen werden 50 000 Datensätze mithilfe der db.r5.xlarge DB-Instance-Klasse in einen Aurora-MySQL-DB-Cluster eingefügt:
-
Im ersten Beispiel fügt jede Sitzung zeilenweise 10 000 Datensätze ein. Wenn sich ein DML-Befehl (Data Manipulation Language) nicht innerhalb einer Transaktion befindet, verwendet Aurora MySQL standardmäßig implizite Commits. Autocommit ist aktiviert. Dies bedeutet, dass für jede Zeileneinfügung ein Commit vorhanden ist. Performance Insights zeigt, dass die Verbindungen die meiste Zeit damit verbringen, auf das
io/aurora_redo_log_flush-Warteereignis zu warten.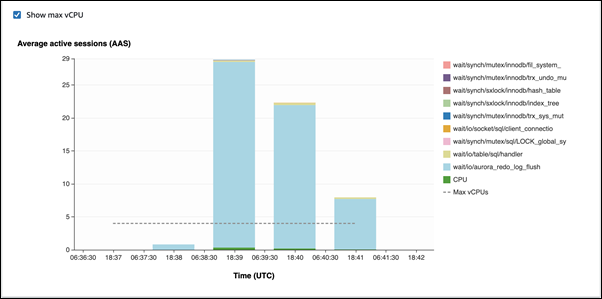
Dies wird durch die verwendeten einfachen Einfügungsanweisungen verursacht.
Die 50 000 Datensätze benötigen 3,5 Minuten, um eingefügt zu werden.
-
Im zweiten Beispiel werden Einfügungen in 1 000 Batches vorgenommen, d.h. jede Verbindung führt 10 Commits statt 10 000 aus. Performance Insights zeigt, dass die Verbindungen nicht die meiste Zeit mit dem
io/aurora_redo_log_flush-Warteereignis verbringen.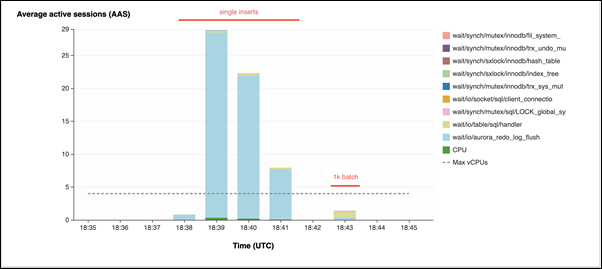
Die 50 000 Datensätze benötigen 4 Sekunden, um eingefügt zu werden.
Aktionen
Abhängig von den Ursachen Ihres Warteereignisses empfehlen wir verschiedene Aktionen.
Themen
Identifizieren Sie die problematischen Sitzungen und Abfragen
Wenn Ihre DB-Instance einen Engpass hat, besteht Ihre erste Aufgabe darin, die Sitzungen und Abfragen zu finden, die ihn verursachen. Einen nützlichen AWS Datenbank-Blogbeitrag finden Sie unter Analysieren von Amazon Aurora MySQL-Workloads mit Performance Insights
So identifizieren Sie Sitzungen und Abfragen, die einen Engpass verursachen
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Performance-Insights aus.
-
Wählen Sie Ihre DB-Instance aus.
-
Wählen Sie unter Datenbanklast die Option Nach Wartezeit aufteilen.
-
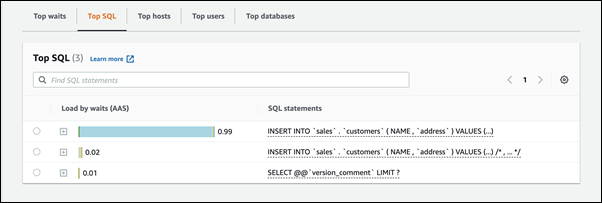
Wählen Sie unten auf der Seite Top-SQL aus.
Die Abfragen oben in der Liste verursachen die höchste Belastung der Datenbank.
Gruppieren Sie Ihre Schreiboperationen
Die folgenden Beispiele lösen das io/aurora_redo_log_flush-Warteereignis aus. (Autocommit ist aktiviert.)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
Um die Wartezeit auf das io/aurora_redo_log_flush-Wartezeitereignis zu verkürzen, gruppieren Sie Ihre Schreibvorgänge logisch in einem einzigen Commit, um persistente Speicheraufrufe zu reduzieren.
Deaktivieren Sie Autocommit
Deaktivieren Sie Autocommit, bevor Sie große Änderungen vornehmen, die nicht in einer Transaktion enthalten sind, wie im folgenden Beispiel gezeigt.
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
Transaktionen verwenden
Sie können Transaktionen verwenden, wie im folgenden Beispiel gezeigt.
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
Verwenden von Batches
Sie können Änderungen in Batches vornehmen, wie im folgenden Beispiel gezeigt. Die Verwendung von zu großen Batches kann jedoch Leistungsprobleme verursachen, insbesondere bei Lesereplikaten oder bei zeitpunktbezogener Wiederherstellung (PITR).
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
