Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Klonen eines Volumes für einen Amazon-Aurora-DB-Cluster
Mithilfe der Aurora-Klonfunktion können Sie einen neuen Cluster erstellen, der anfänglich diesselben Datenseiten wie das Original enthält, aber ein separates und unabhängiges Volume darstellt. Der Prozess ist so konzipiert, dass er schnell und kostengünstig ist. Der neue Cluster mit dem zugehörigen Datenvolume wird als clone (Klon) bezeichnet. Das Erstellen eines Klons ist schneller und platzsparender als das physische Kopieren der Daten mit anderen Techniken, wie z. B. das Wiederherstellen eines Snapshots.
Themen
Übersicht über das Aurora-Klonen
Aurora verwendet ein Copy-on-Write-Protokoll, um einen Klon zu erstellen. Dieser Mechanismus verwendet minimalen zusätzlichen Speicherplatz, um einen ersten Klon zu erstellen. Wenn der Klon zum ersten Mal erstellt wird, behält Aurora eine einzelne Kopie der Daten, die vom Aurora-DB-Quellcluster und dem neuen (geklonten) Aurora-DB-Cluster verwendet werden. Zusätzlicher Speicher wird nur zugewiesen, wenn Änderungen an Daten (auf dem Aurora-Speicher-Volume) durch den Aurora-DB-Quellcluster oder den Aurora-DB-Clusterklon vorgenommen werden. Weitere Informationen zum Copy-on-Write-Protokoll finden Sie unter Funktionsweise des Klonens von Aurora.
Das Klonen von Aurora ist besonders nützlich, um Testumgebungen mit Ihren Produktionsdaten schnell einzurichten, ohne Datenbeschädigung zu riskieren. Sie können Klone für viele Arten von Anwendungen verwenden, z. B. für Folgende:
-
Experimentieren Sie mit möglichen Änderungen (z. B. Schemaänderungen und Parametergruppenänderungen), um alle Auswirkungen zu bewerten.
-
Führen Sie Workload-intensive Vorgänge aus, z. B. das Exportieren von Daten oder das Ausführen analytischer Abfragen auf dem Klon.
-
Erstellen Sie eine Kopie Ihres Produktions-DB-Clusters zu Entwicklungs-, Test- oder anderen Zwecken.
Sie können mehr als einen Klon aus demselben Aurora-DB-Cluster erstellen. Sie können auch mehrere Klone aus einem anderen Klon erstellen.
Nachdem Sie einen Aurora-Klon erstellt haben, können Sie die Aurora-DB-Instances anders als den Aurora-DB-Quellcluster konfigurieren. Beispielsweise benötigen Sie möglicherweise keinen Klon für Entwicklungszwecke, um dieselben Hochverfügbarkeitsanforderungen zu erfüllen wie der Aurora-DB-Cluster für die Quellproduktion. In diesem Fall können Sie den Klon mit einer einzelnen Aurora-DB-Instance konfigurieren, anstatt mit mehreren DB-Instances, die vom Aurora-DB-Cluster verwendet werden.
Wenn Sie einen Klon mit einer anderen Bereitstellungskonfiguration als der Quelle erstellen, wird der Klon mit der neuesten Nebenversion der Aurora-DB-Engine der Quelle erstellt.
Wenn Sie Klone aus Ihren Aurora-DB-Clustern erstellen, werden die Klone in Ihrem Konto erstellt AWS — demselben Konto, dem der Aurora-DB-Cluster als Quelle gehört. Sie können Aurora-DB-Cluster Aurora serverless und -Clones jedoch auch mit anderen AWS Konten teilen und bereitstellen. Weitere Informationen finden Sie unter Cross-account Klonen mit AWS RAM und Amazon Aurora.
Wenn Sie den Klon für Test-, Entwicklungs- oder andere Zwecke nicht mehr verwenden, können Sie ihn löschen.
Einschränkungen für das Aurora-Klonen
Das Klonen von Aurora hat derzeit die folgenden Einschränkungen:
-
Sie können so viele Klone erstellen, wie Sie möchten, bis zur maximalen Anzahl von DB-Clustern, die in der AWS-Region zulässig sind.
-
Sie können bis zu 15 Klone mit dem Copy-On-Write-Protokoll erstellen. Nachdem Sie jedoch 15 Klone erstellt haben, ist der nächste Klon, den Sie erstellen, eine vollständige Kopie. Das Full-Copy-Protokoll funktioniert wie eine zeitpunktbezogene Wiederherstellung.
-
Sie können keinen Clone in einer anderen AWS Region als dem Aurora-DB-Cluster der Quelle erstellen.
-
Sie können keinen Klon von einem Aurora-DB-Cluster ohne die parallele Abfragefunktion für einen Cluster erstellen, der parallele Abfragen verwendet. Um Daten in einen Cluster zu bringen, der parallele Abfragen verwendet, erstellen Sie einen Snapshot des ursprünglichen Clusters und stellen Sie ihn in dem Cluster wieder her, der die parallele Abfragefunktion verwendet.
-
Sie können keinen Klon aus einem Aurora DB-Cluster erstellen, der keine DB-Instances hat. Sie können nur Aurora-DB-Cluster klonen, die über mindestens eine DB-Instance verfügen.
-
Sie können einen Klon in einer anderen Virtual Private Cloud (VPC) als der des Aurora-DB-Clusters erstellen. In diesem Fall müssen die Subnetze der VPCs denselben Availability Zones zugeordnet sein.
-
Sie können einen von Aurora bereitgestellten Klon aus einem bereitgestellten Aurora-DB-Cluster erstellen.
-
Cluster mit Aurora serverless-Instances folgen den gleichen Regeln wie bereitgestellte Cluster.
Funktionsweise des Klonens von Aurora
Das Klonen von Aurora funktioniert auf der Speicherschicht eines Aurora-DB-Clusters. Es verwendet ein Copy-on-Write-Protokoll, das sowohl schnell als auch platzsparend in Bezug auf die zugrunde liegenden langlebigen Medien ist, die das Aurora-Speichervolumen unterstützen. Weitere Informationen zu Aurora-Cluster-Volumes finden Sie unterÜbersicht über Amazon-Aurora-Speicher.
Copy-On-Write-Protokoll verstehen
Ein Aurora-DB-Cluster speichert Daten in Seiten im zugrunde liegenden Aurora-Speicher-Volume.
Im folgenden Diagramm finden Sie beispielsweise einen Aurora-DB-Cluster (A) mit vier Datenseiten 1, 2, 3 und 4. Stellen Sie sich vor, dass ein Klon, Klon B, aus dem Aurora-DB-Cluster erstellt wird. Wenn der Klon erstellt wird, werden keine Daten kopiert. Stattdessen verweist der Klon auf denselben Seitensatz wie der Aurora-DB-Quellcluster.

Wenn der Klon erstellt wird, ist normalerweise kein zusätzlicher Speicher erforderlich. Das Copy-on-Write-Protokoll verwendet dasselbe Segment auf dem physischen Speichermedium wie das Quellsegment. Zusätzlicher Speicher ist nur erforderlich, wenn die Kapazität des Quellsegments für das gesamte Klonsegment nicht ausreicht. Wenn dies der Fall ist, wird das Quellsegment auf ein anderes physisches Gerät kopiert.
In den folgenden Diagrammen finden Sie ein Beispiel für das Copy-on-Write-Protokoll in Aktion mit demselben Cluster A und dessen Klon, B, wie oben gezeigt. Nehmen wir an, Sie nehmen eine Änderung an Ihrem Aurora-DB-Cluster (A) vor, was zu einer Änderung der Daten auf Seite 1 führt. Anstatt auf die ursprüngliche Seite 1 zu schreiben, erstellt Aurora eine neue Seite 1 [A]. Das Aurora-DB-Cluster-Volume für Cluster (A) verweist nun auf Seite 1 [A], 2, 3 und 4, während der Klon (B) weiterhin auf die ursprünglichen Seiten verweist.
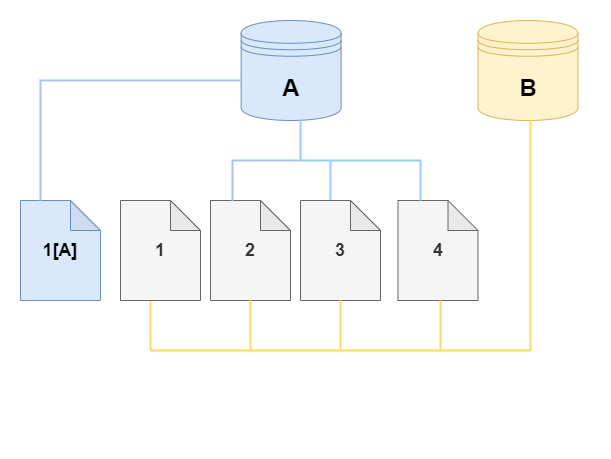
Auf dem Klon wird eine Änderung an Seite 4 auf dem Speichervolume vorgenommen. Anstatt auf die ursprüngliche Seite 4 zu schreiben, erstellt Aurora eine neue Seite, 4 [B]. Der Klon verweist nun auf die Seiten 1, 2, 3 und auf Seite 4[B], während der Cluster (A) weiterhin auf 1[A], 2, 3 und 4 verweist.
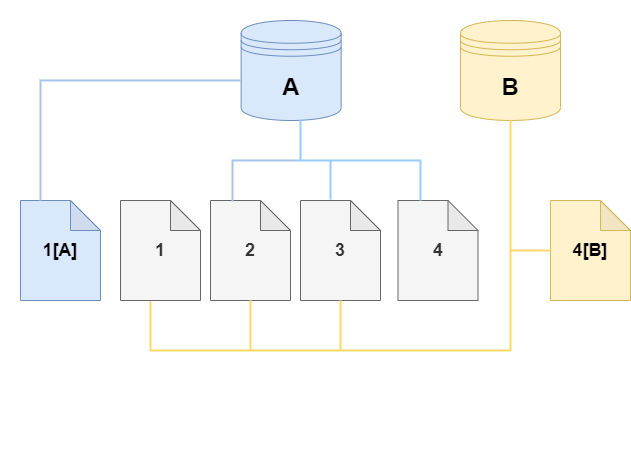
Da im Laufe der Zeit mehr Änderungen sowohl im Aurora-DB-Cluster-Quellvolume als auch im Klon auftreten, wird mehr Speicherplatz benötigt, um die Änderungen zu erfassen und zu speichern.
Löschen eines Quell-Cluster-Volumes
Anfänglich verwendet das Klon-Volume dieselben Datenseiten wie das ursprüngliche Volume, aus dem der Klon erstellt wurde. Solange das ursprüngliche Volume existiert, gilt das Klon-Volume nur als Eigentümer der Seiten, die der Klon erstellt oder geändert hat. Die VolumeBytesUsed-Metrik für das Klon-Volume ist also zunächst gering und steigt nur, wenn die Daten zwischen dem ursprünglichen Cluster und dem Klon voneinander abweichen. Für Seiten, die beim Quell-Volume und dem Klon identisch sind, gelten die Speichergebühren nur für den ursprünglichen Cluster. Für weitere Informationen über die VolumeBytesUsed-Metrik siehe Cluster-level Metriken für Amazon Aurora.
Wenn Sie ein Quell-Cluster-Volume löschen, dem ein oder mehrere Klone zugeordnet sind, werden die Daten in den Cluster-Volumes der Klone nicht geändert. Aurora behält die Seiten bei, die zuvor im Besitz des Quell-Cluster-Volumes waren. Aurora verteilt die Speicherabrechnung für die Seiten, die dem gelöschten Cluster gehörten, neu. Nehmen wir zum Beispiel an, ein ursprünglicher Cluster hatte zwei Klone und dann wurde der ursprüngliche Cluster gelöscht. Die Hälfte der Datenseiten, die dem ursprünglichen Cluster gehörten, würde jetzt einem Klon gehören. Die andere Hälfte der Seiten würde dem anderen Klon gehören.
Wenn Sie den ursprünglichen Cluster löschen und weitere Klone erstellen oder löschen, verteilt Aurora weiterhin den Besitz der Datenseiten auf alle Klone, die dieselben Seiten gemeinsam nutzen. Daher stellen Sie möglicherweise fest, dass sich der Wert der VolumeBytesUsed-Metrik für das Cluster-Volume eines Klons ändert. Der Metrikwert kann sinken, wenn mehr Klone erstellt werden und der Seitenbesitz auf mehr Cluster verteilt wird. Der Metrikwert kann auch steigen, wenn Klone gelöscht werden und der Seitenbesitz einer kleineren Anzahl von Clustern zugewiesen wird. Informationen dazu, wie sich Schreiboperationen auf Datenseiten auf Klon-Volumes auswirken, finden Sie unter Copy-On-Write-Protokoll verstehen.
Wenn der ursprüngliche Cluster und die Klone demselben AWS Konto gehören, fallen alle Speichergebühren für diese Cluster auf dasselbe AWS Konto an. Wenn es sich bei einigen Clustern um kontenübergreifende Klone handelt, kann das Löschen des ursprünglichen Clusters zu zusätzlichen Speichergebühren für die AWS Konten führen, denen die kontenübergreifenden Klone gehören.
Nehmen wir beispielsweise an, dass ein Cluster-Volume 1 000 verwendete Datenseiten hat, bevor Sie Klone erstellen. Wenn Sie diesen Cluster klonen, hat das Klon-Volume zunächst keine verwendeten Seiten. Wenn der Klon Änderungen an 100 Datenseiten vornimmt, werden nur diese 100 Seiten auf dem Klon-Volume gespeichert und als verwendet markiert. Die anderen 900 unveränderten Seiten des übergeordneten Volumes werden von beiden Clustern gemeinsam genutzt. In diesem Fall fallen für den übergeordneten Cluster Speichergebühren für 1 000 Seiten und für das Klon-Volume für 100 Seiten an.
Wenn Sie das Quell-Volume löschen, umfassen die Speichergebühren für den Klon die 100 Seiten, die er geändert hat, plus die 900 gemeinsam genutzten Seiten aus dem ursprünglichen Volume, also insgesamt 1 000 Seiten.
Erstellen eines Amazon-Aurora-DB-Klons
Sie können einen Clone in demselben AWS Konto wie der Aurora-DB-Cluster als Quelle erstellen. Dazu können Sie das AWS-Managementkonsole oder das AWS CLI und die folgenden Verfahren verwenden.
Gehen Sie wie unter beschrieben vor, um einem anderen AWS Konto die Erstellung eines Klons oder die gemeinsame Nutzung eines Klons mit einem anderen AWS Konto zu ermöglichenCross-account Klonen mit AWS RAM und Amazon Aurora.
Das folgende Verfahren beschreibt das Klonen eines Aurora-DB-Clusters mittels der AWS-Managementkonsole.
Erstellen eines Klons anhand der AWS-Managementkonsole Ergebnisse in einem Aurora-DB-Cluster mit einer Aurora-DB-Instance.
Diese Anweisungen gelten für DB-Cluster, die demselben AWS Konto gehören, das den Clone erstellt. Wenn der DB-Cluster einem anderen AWS Konto gehört, finden Sie Cross-account Klonen mit AWS RAM und Amazon Aurora stattdessen weitere Informationen unter.
Um einen Klon eines DB-Clusters zu erstellen, der Ihrem gehört AWS Konto mit dem AWS-Managementkonsole
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Wählen Sie im Navigationsbereich Databases (Datenbanken) aus.
Wählen Sie Ihren Aurora-DB-Cluster aus der Liste aus, und wählen Sie für Aktionen die Option Klon erstellen aus.
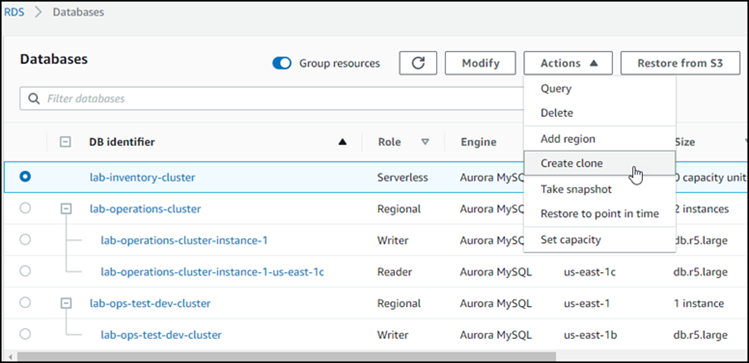
Die Seite „Klon erstellen“ wird geöffnet, auf der Sie Einstellungen, Konnektivität und andere Optionen für den Klon des Aurora-DB-Clusters konfigurieren können.
-
Geben Sie als DB-Instance-ID den Namen ein, den Sie Ihrem geklonten Aurora-DB-Cluster geben möchten.
-
Wählen Sie für Aurora serverless- oder bereitgestellte DB-Cluster entweder Aurora I/O-Optimized oder Aurora Standard für Konfiguration des Cluster-Speichers aus.
Weitere Informationen finden Sie unter Speicherkonfigurationen für DB-Cluster von Amazon Aurora.
-
Wählen Sie die Größe der DB-Instance oder die DB-Cluster-Kapazität aus:
-
Wählen Sie für einen bereitgestellten Klon eine DB-Instance-Klasse aus.
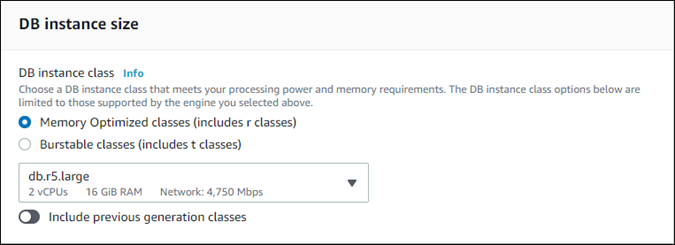
Sie können die bereitgestellte Einstellung akzeptieren oder eine andere DB-Instance-Klasse für Ihren Klon verwenden.
-
Wählen Sie für einen Aurora serverless Clone die Kapazitätseinstellungen.
Sie können die bereitgestellten Einstellungen übernehmen oder für Ihren Klon ändern.
-
-
Wählen Sie nach Bedarf weitere Einstellungen für Ihren Klon aus. Weitere Informationen zu Aurora DB-Cluster- und -Instance-Einstellungen finden Sie unter Erstellen eines Amazon Aurora-DB Clusters.
-
Wählen Sie Klon erstellen aus.
Wenn der Klon erstellt wird, wird er mit Ihren anderen Aurora-DB-Clustern im Abschnitt Datenbanken der Konsole aufgelistet und zeigt seinen aktuellen Status an. Ihr Klon ist einsatzbereit, wenn sein Status Verfügbar ist.
Die Verwendung des AWS CLI zum Klonen Ihres Aurora-DB-Clusters umfasst separate Schritte zum Erstellen des Klon-Clusters und zum Hinzufügen einer oder mehrerer DB-Instances zu ihm.
Der restore-db-cluster-to-point-in-time AWS CLI Befehl, den Sie verwenden, führt zu einem Aurora-DB-Cluster mit denselben Speicherdaten wie der ursprüngliche Cluster, aber ohne Aurora-DB-Instances. Sie erstellen die DB-Instances separat, nachdem der Klon verfügbar ist. Sie können die Anzahl der DB-Instances und ihrer Instance-Klassen wählen, um dem Klon mehr oder weniger Rechenkapazität als der ursprüngliche Cluster zuzuweisen. Der Prozess umfasst folgende Schritte:
-
Erstellen Sie den Klon mit dem CLI-Befehl restore-db-cluster-to-point-in-time.
-
Erstellen Sie die Writer-DB-Instance für den Klon mit dem CLI-Befehl create-db-instance.
-
(Optional) Führen Sie zusätzliche create-db-instance-CLI-Befehle aus, um dem Klon-Cluster eine oder mehrere Reader-Instances hinzuzufügen. Die Verwendung von Reader-Instances trägt dazu bei, die Hochverfügbarkeit und die Leseskalierbarkeit des Klons zu verbessern. Sie können diesen Schritt überspringen, wenn Sie den Klon nur für Entwicklungs- und Testzwecke verwenden möchten.
Themen
Erstellen des Klons
Verwenden Sie den CLI-Befehl restore-db-cluster-to-point-in-time, um den ersten Klon-Cluster zu erstellen.
So erstellen Sie einen Klon aus einem Aurora-DB-Quellcluster
-
Verwenden Sie den
restore-db-cluster-to-point-in-time-CLI-Befehl. Geben Sie Werte für die folgenden Parameter an. In diesem typischen Fall verwendet der Klon denselben Engine-Modus wie der ursprüngliche Cluster, entweder bereitgestellt oder Aurora serverless.-
--db-cluster-identifier– Wählen Sie einen aussagekräftigen Namen für Ihren Klon. Sie benennen den Klon, wenn Sie den CLI-Befehl restore-db-cluster-to-point-in-time verwenden. Anschließend übergeben Sie den Namen des Klons im CLI-Befehl create-db-instance. -
--restore-type– Verwenden Siecopy-on-write, um einen Klon des Quell-DB-Clusters zu erstellen. Ohne diesen Parameter stelltrestore-db-cluster-to-point-in-timeden Aurora-DB-Cluster wieder her, anstatt einen Klon zu erstellen. -
--source-db-cluster-identifier– Verwenden Sie den Namen des Aurora-DB-Quell-Clusters, den Sie klonen möchten. -
--use-latest-restorable-time– Dieser Wert verweist auf die neuesten wiederherstellbaren Volume-Daten für den Quell-DB-Cluster. Verwenden Sie ihn, um Klone zu erstellen.
-
Im folgenden Beispiel wird ein Klon namens my-clone aus einem Cluster namens my-source-cluster erstellt.
Für Linux, macOS oder Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Für Windows:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
Der Befehl gibt das JSON-Objekt zurück, das Details des Klons enthält. Stellen Sie sicher, dass Ihr geklonter DB-Cluster verfügbar ist, bevor Sie versuchen, die DB-Instance für Ihren Klon zu erstellen. Weitere Informationen finden Sie unter Überprüfen des Status und Abrufen von Klon-Details.
Angenommen, Sie haben einen Cluster mit dem Namen tpch100g, den Sie klonen möchten. Im folgenden Linux-Beispiel werden ein geklonter Cluster namens tpch100g-clone, eine Aurora serverless-Writer-Instance mit dem Namen tpch100g-clone-instance sowie eine bereitgestellte Reader-Instance namens tpch100g-clone-instance-2 für den neuen Cluster erstellt.
Einige Parameter wie --master-username und --master-user-password müssen nicht angegeben werden. Aurora ermittelt diese automatisch aus dem ursprünglichen Cluster. Sie müssen die zu verwendende DB-Engine angeben. Daher testet das Beispiel den neuen Cluster, um den richtigen Wert für den Parameter --engine zu ermitteln.
Dieses Beispiel beinhaltet auch die --serverless-v2-scaling-configuration-Option beim Erstellen des Klon-Clusters. Auf diese Weise können Sie dem Klon Aurora serverless-Instances hinzufügen, auch wenn der ursprüngliche Cluster Aurora serverless nicht verwendet hat.
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
Überprüfen des Status und Abrufen von Klon-Details
Mit dem folgenden Befehl können Sie den Status Ihres neu erstellten Klon-Clusters überprüfen.
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
Oder Sie können den Status und die anderen Werte, die Sie zum Erstellen der DB-Instance für Ihren Clone benötigen, mithilfe der folgenden AWS CLI Abfrage abrufen.
Für Linux, macOS oder Unix:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Für Windows:
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
Diese Abfrage gibt eine Ausgabe ähnlich der folgenden zurück.
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
Erstellen einer Aurora-DB-Instance für Ihren Klon
Verwenden Sie den CLI-Befehl create-db-instance, um die DB-Instance für Ihren Aurora serverless- oder bereitgestellten Klon zu erstellen.
Die DB-Instance erbt die --master-username- und --master-user-password-Eigenschaft vom Quell-DB-Cluster.
Im folgenden Beispiel wird eine DB-Instance für einen bereitgestellten Klon erstellt.
Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Für Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
Im folgenden Beispiel wird eine Aurora serverless-DB-Instance für einen Klon erstellt, der eine Engine-Version verwendet, die Aurora serverless unterstützt.
Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Für Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
Zu verwendende Parameter für das Klonen
Die folgende Tabelle fasst die verschiedenen Parameter zusammen, die mit restore-db-cluster-to-point-in-time zum Klonen von Aurora-DB-Clustern verwendet werden.
| Parameter | Description |
|---|---|
|
|
Verwenden Sie den Namen des Aurora-DB-Quell-Clusters, den Sie klonen möchten. |
|
|
Wählen Sie einen aussagekräftigen Namen für Ihren Klon, wenn Sie ihn mit dem |
|
|
Geben Sie |
|
|
Dieser Wert verweist auf die neuesten wiederherstellbaren Volume-Daten für den Quell-DB-Cluster. Verwenden Sie ihn, um Klone zu erstellen. |
|
|
(Neuere Versionen, die Aurora serverless unterstützen) Verwenden Sie diesen Parameter, um die minimale und maximale Kapazität für einen Aurora serverless-Klon zu konfigurieren. Wenn Sie diesen Parameter nicht angeben, können Sie keine Aurora serverless-Instances im Klon-Cluster erstellen, bis Sie den Cluster so ändern, dass dieses Attribut hinzugefügt wird. |
Informationen zu VPC- und kontoübergreifendem Klonen finden Sie in den folgenden Abschnitten.
