Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Servicelevel-Ziele (SLOs)
Sie können Application Signals verwenden, um Servicelevel-Ziele für die Services für Ihre kritischen Geschäftsabläufe oder Abhängigkeiten zu erstellen. Wenn Sie SLOs für diese Services erstellen, können Sie sie im SLO-Dashboard verfolgen, sodass Sie auf einen Blick eine Übersicht Ihrer wichtigsten Abläufe haben.
Neben der Erstellung einer Schnellansicht, in der sich Ihre Mitarbeiter über den aktuellen Status kritischer Vorgänge informieren können, können Sie mit Hilfe von SLOs auch die längerfristige Leistung Ihrer Services verfolgen, um sicherzustellen, dass sie Ihren Erwartungen entsprechen. Wenn Sie Service Level Agreements mit Kunden abgeschlossen haben, sind SLOs ein hervorragendes Instrument, um sicherzustellen, dass diese eingehalten werden.
Die Bewertung des Zustands Ihrer Services mithilfe von SLOs beginnt mit der Festlegung klarer, messbarer Ziele auf der Grundlage wichtiger Leistungsmetriken – Servicelevel-Indikator (SLIs). Mit einem SLO wird die SLI-Leistung anhand des von Ihnen festgelegten Schwellenwerts und Ziels verglichen und es wird gemeldet, wie weit oder wie nahe Ihre Anwendungsleistung am Schwellenwert liegt.
Application Signals hilft Ihnen dabei, SLOs für Ihre wichtigsten Leistungsmetriken festzulegen. Application Signals erfasst automatisch Latency- und Availability-Metriken für jeden Service und Vorgang, den es entdeckt, und diese Metriken eignen sich oft ideal für die Verwendung als SLIs. Mit dem Assistenten zur SLO-Erstellung können Sie diese Metriken für Ihre SLOs verwenden. Anschließend können Sie den Status all Ihrer SLOs mit den Dashboards von Application Signals verfolgen.
Sie können SLOs für bestimmte Vorgänge oder Abhängigkeiten einrichten, die Ihr Service aufruft oder verwendet. Sie können zusätzlich zu den Metriken Latency und Availability jede beliebige CloudWatch Metrik oder jeden beliebigen metrischen Ausdruck als SLI verwenden.
Die Erstellung von SLOs ist sehr wichtig, um den größtmöglichen Nutzen aus CloudWatch Application Signals zu ziehen. Nachdem Sie SLOs erstellt haben, können Sie ihren Status in der Application Signals Console einsehen, um schnell zu sehen, welche Ihrer kritischen Services und Vorgänge gut funktionieren und welche nicht. Die Tatsache, dass SLOs nachverfolgt werden können, bietet die folgenden großen Vorteile:
Es ist für Ihre Servicebetreiber einfacher, den aktuellen Betriebsstatus kritischer Services, gemessen am SLI, zu ermitteln. Auf diese Weise können sie schnell fehlerhafte Services und Betriebsabläufe untersuchen und identifizieren.
Sie können Ihre Serviceleistung anhand messbarer Geschäftsziele über längere Zeiträume hinweg verfolgen.
Indem Sie entscheiden, worauf Sie SLOs setzen möchten, priorisieren Sie das, was für Sie wichtig ist. Die Dashboards von Application Signals enthalten automatisch Informationen darüber, was Sie priorisiert haben.
Wenn Sie ein SLO erstellen, können Sie sich auch dafür entscheiden, gleichzeitig CloudWatch Alarme zu erstellen, um die SLOs zu überwachen. Sie können Alarme einrichten, die sowohl auf Überschreitungen des Schwellenwerts als auch auf Warnstufen achten. Diese Alarme können Sie automatisch benachrichtigen, wenn die SLO-Metriken den von Ihnen festgelegten Schwellenwert überschreiten oder wenn sie sich einem Warnschwellenwert nähern. Wenn sich ein SLO beispielsweise seinem Warnschwellenwert nähert, können Sie darüber informiert werden, dass Ihr Team möglicherweise die Kundenabwanderung in der Anwendung verlangsamen muss, um sicherzustellen, dass die langfristigen Leistungsziele erreicht werden.
Themen
SLO-Konzepte
Ein SLO-Konzept enthält die folgenden Komponenten:
Ein Servicelevel-Indikator (SLI), bei dem es sich um eine wichtige Leistungsmetrik handelt, die Sie angeben. Der SLI stellt das gewünschte Leistungsniveau für Ihre Anwendung dar. Application Signals erfasst automatisch die wichtigen
Latency- undAvailability-Metriken für jeden Service und Vorgang, den es entdeckt, und diese Metriken eignen sich oft ideal für die Verwendung mit SLOs.Sie wählen den Schwellenwert, den Sie für Ihr SLI verwenden möchten. Zum Beispiel 200 ms für die Latenz.
Ein Ziel oder Erreichungsziel. Dabei handelt es sich um den Prozentsatz der Zeit oder Anforderungen, in der der SLI den Schwellenwert voraussichtlich in jedem Zeitintervall erreicht. Die Zeitintervalle können so kurz wie Stunden oder so lang wie ein Jahr sein.
Intervalle können entweder Kalenderintervalle oder fortlaufende Intervalle sein.
Kalenderintervalle richten sich nach dem Kalender, z. B. ein SLO, das pro Monat erfasst wird. CloudWatch passt die Zahlen für Gesundheit, Budget und Leistungen automatisch an die Anzahl der Tage in einem Monat an. Kalenderintervalle eignen sich besser für Geschäftsziele, die kalendergerecht gemessen werden.
Rollende Intervalle werden fortlaufend berechnet. Rollende Intervalle eignen sich besser, um das aktuelle Benutzererlebnis Ihrer Anwendung nachzuverfolgen.
Der Zeitraum ist kürzer, und viele Zeiträume bilden ein Intervall. Die Leistung der Anwendung wird in jedem Zeitraum innerhalb des Intervalls mit der SLI verglichen. Für jeden Zeitraum wird festgestellt, ob die Anwendung entweder die erforderliche Leistung erreicht hat oder nicht.
Ein Ziel von 99 % bei einem Kalenderintervall von einem Tag und einem Zeitraum von 1 Minute bedeutet beispielsweise, dass die Anwendung die Erfolgsschwelle in 99 % der Zeiträume von 1 Minute am Tag erreichen oder erreichen muss. Ist dies der Fall, ist der SLO für diesen Tag erfüllt. Der nächste Tag ist ein neues Bewertungsintervall, und die Anwendung muss während 99 % der Zeiträume von 1 Minute am zweiten Tag die Erfolgsschwelle erreichen oder erreichen, um den SLO für diesen zweiten Tag zu erfüllen.
Ein SLI kann auf einer der neuen Standard-Anwendungsmetriken basieren, die von Application Signals erfasst wurden. Alternativ kann es sich um eine beliebige CloudWatch Metrik oder einen beliebigen metrischen Ausdruck handeln. Die Standard-Anwendungsmetriken, die Sie für eine SLI verwenden können, sind Latency und Availability. Availability stellt die erfolgreichen Antworten geteilt durch die Gesamtzahl der Anforderungen dar. Sie wird als (1 - Störungsrate)*100 berechnet, wobei es sich bei Fehlerantworten um 5xx-Fehler handelt. Erfolgsantworten sind Antworten ohne 5XX-Fehler. 4XX-Antworten werden als erfolgreich behandelt.
Sie können nicht nur SLOs für einen einzelnen Vorgang oder für alle Operationen eines Dienstes erstellen, sondern auch zusammengesetzte SLOs erstellen, die eine Teilmenge von Vorgängen für einen Dienst überwachen. Zusammengesetzte SLOs aggregieren die Availability Metrik für mehrere Operationen und bieten Ihnen so einen einheitlichen Überblick über die Zuverlässigkeit einer Gruppe verwandter Operationen. Sie können zwischen 2 und 20 Operationen auswählen, die in ein zusammengesetztes SLO aufgenommen werden sollen. Weitere Informationen finden Sie unter Erstellen Sie ein zusammengesetztes SLO für mehrere Operationen.
Fehlerbudget und Erreichung für periodenbasierte SLOs berechnen
Wenn Sie Informationen zu einem SLO anzeigen, sehen Sie dessen aktuellen Zustand und sein Fehlerbudget. Das Fehlerbudget gibt an, wie lange innerhalb des Intervalls der Schwellenwert überschritten werden kann, wobei der SLO aber trotzdem eingehalten werden kann. Das Gesamtfehlerbudget ist die Gesamtdauer der Sicherheitsverletzung, die während des gesamten Intervalls toleriert werden kann. Das verbleibende Fehlerbudget ist die verbleibende Dauer der Sicherheitsverletzung, die im aktuellen Intervall toleriert werden kann. Dies ist der Fall, nachdem die bereits eingetretene Zeit für Verstöße vom Gesamtfehlerbudget abgezogen wurde.
Die folgende Abbildung veranschaulicht die Konzepte für das Erreichungs- und das Fehlerbudget für ein Ziel mit einem Intervall von 30 Tagen, Zeiträumen von 1 Minute und einer Zielerreichung von 99 %. 30 Tage beinhalten 43 200 Zeiträume von einer Minute. 99 % von 43 200 entsprechen 42 768 Minuten im Monat, sodass 42 768 Minuten im Monat einwandfrei sein müssen, damit der SLO eingehalten werden kann. Bisher waren 130 der 1-Minuten-Zeiträume im aktuellen Intervall fehlerbehaftet.
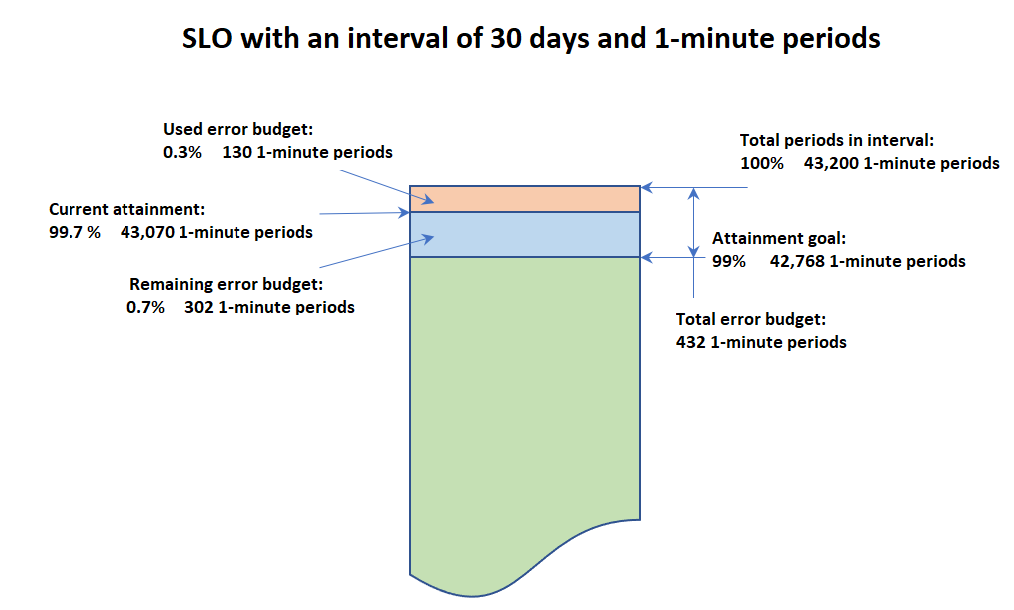
Den Erfolg innerhalb der einzelnen Zeiträumen ermitteln
Innerhalb jedes Zeitraums werden die SLI-Daten auf der Grundlage der für den SLI verwendeten Statistik zu einem einzigen Datenpunkt zusammengefasst. Dieser Datenpunkt stellt die gesamte Länge des Zeitraums dar. Dieser einzelne Datenpunkt wird mit dem SLI-Schwellenwert verglichen, um festzustellen, ob der Zeitraum fehlerfrei ist. Wenn Sie auf dem Dashboard fehlerhafte Perioden während des aktuellen Zeitraums sehen, können Ihre Servicemitarbeiter darauf aufmerksam gemacht werden, dass der Service untersucht werden muss.
Wenn festgestellt wird, dass der Zeitraum fehlerhaft ist, wird die gesamte Dauer des Zeitraums im Fehlerbudget als fehlerhaft gewertet. Wenn Sie das Fehlerbudget verfolgen, können Sie feststellen, ob der Service über einen längeren Zeitraum die von Ihnen gewünschte Leistung erzielt.
Zeitfenster-Ausschlüsse
Bei Auszuschließenden Zeitfenstern handelt es sich um einen Zeitblock mit einem definierten Start- und Enddatum. Dieser Zeitraum ist in den Leistungsmetriken des SLO nicht enthalten, und Sie können Zeitfenster für einmalige oder wiederkehrende Zeitausschlüsse festlegen. Zum Beispiel geplante Wartungsarbeiten.
Anmerkung
Bei zeitraumbasierten SLOs gelten SLI-Daten im Ausschlussfenster als nicht verletzend.
Bei anforderungsbasierten SLOs werden alle guten und schlechten Anforderungen im Ausschlussfenster ausgeschlossen.
Wenn ein Intervall für ein anforderungsbasiertes SLO vollständig ausgeschlossen wird, wird eine Standardkennzahl für die Erreichungsquote von 100 % veröffentlicht.
Sie können nur Zeitfenster mit einem Startdatum in der Zukunft angeben.
Fehlerbudget und Erreichung für anforderungsbasierte SLOs berechnen
Nachdem Sie ein SLO erstellt haben, können Sie Fehlerbudgetberichte für dieses SLO abrufen. Ein Fehlerbudget ist die Anzahl der Anforderungen, bei denen Ihre Anwendung möglicherweise nicht dem Ziel des SLO entspricht und Ihre Anwendung trotzdem das Ziel erreicht. Bei einem anforderungsbasierten SLO ist das verbleibende Fehlerbudget dynamisch und kann je nach Verhältnis der guten Anforderungen zur Gesamtzahl der Anforderungen steigen oder sinken
Die folgende Tabelle zeigt die Berechnung für ein anforderungsbasiertes SLO mit einem Intervall von 5 Tagen und einer Zielerreichung von 85 %. In diesem Beispiel nehmen wir an, dass es vor Tag 1 keinen Verkehr gibt. Der SLO hat das Ziel an Tag 10 nicht erreicht.
Anmerkung
Für anforderungsbasierte SLOs TotalRequestCountPerMinute und BadRequestCountPerMinute werden im Vergleich zu periodenbasierten SLO-Metriken als zusätzliche Metriken ausgegeben. Diese Metriken werden aus Gründen der Beobachtbarkeit bereitgestellt und nicht als Input für Berechnungen der Erfolgsquote verwendet.
Da diese Metriken aus regelmäßig ausgewerteten Metrikdaten generiert werden, können ihre Werte gelegentlich aufgrund von Zeitverzögerungen oder Verzögerungen bei der Veröffentlichung von Kennzahlen von den erwarteten Anforderungszahlen abweichen. Solche Diskrepanzen wirken sich nicht auf die Berechnungen des SLO-Erreichens aus, die unabhängig von den ausgegebenen Messwerten pro Minute berechnet werden.
| Zeit | Anforderungen insgesamt | Ungültige Anforderungen | Gesamtzahl der Anforderungen in den letzten 5 Tagen | Gesamtzahl der guten Anforderungen in den letzten 5 Tagen | Request-based Erreichen | Budgetanforderungen insgesamt | Restliche Budgetanforderungen |
|---|---|---|---|---|---|---|---|
|
Tag 1 |
10 | 1 |
10 |
9 |
9/10 = 90% |
1.5 |
0.5 |
|
Tag 2 |
5 |
1 |
15 |
13 |
13/15= 86% |
2.3 |
0.3 |
|
Tag 3 |
1 |
1 |
16 |
13 |
13/16= 81% |
2.4 |
-0,6 |
|
Tag 4 |
24 |
0 |
40 |
37 |
37/40= 92% |
6.0 |
3.0 |
|
Tag 5 |
20 |
5 |
60 |
52 |
52/60= 87% |
9.0 |
1,0 |
|
Tag 6 |
6 |
2 |
56 |
47 |
47/56= 84% |
8,4 |
-0,6 |
|
Tag 7 |
10 |
3 |
61 |
50 |
50/61= 82% |
9.2 |
-1,8 |
|
Tag 8 |
15 |
6 |
75 |
59 |
59/75= 79% |
11,3 |
-4,7 |
| Tag 9 |
12 |
1 |
63 |
46 |
46/63= 73% |
9.5 |
-7,5 |
|
Tag 10 |
5 |
57 |
40 |
40/57= 70% |
8,5 |
-8,5 | |
|
Endgültige Erreichung der letzten 5 Tage |
|
70% |
Berechnen der Verbrauchsraten und optionale Einstellung der Verbrauchsratenalarme
Sie können Application Signals verwenden, um die Verbrauchsraten für Ihre Service-Level-Ziele zu berechnen. Eine Verbrauchsrate ist eine Kennzahl, die angibt, wie schnell der Service das Fehlerbudget im Verhältnis zum Erreichen des SLO-Ziels verbraucht. Sie wird als Vielfaches der Basisfehlerquote ausgedrückt.
Die Verbrauchsrate wird anhand der Basisfehlerquote berechnet, die vom Erreichungsziel abhängt. Das Erreichungsziel gibt an, in welchem Prozentsatz entweder fehlerfreie Zeiträume oder erfolgreiche Anforderungen erreicht werden müssen, um das SLO-Ziel zu erreichen. Die Basisfehlerquote liegt bei (100 % – Prozentsatz des Erreichungsziels), und diese Zahl würde das gesamte Fehlerbudget am Ende des SLO-Zeitintervalls aufbrauchen. Ein SLO mit einem Erreichungsziel von 99 % hätte also eine Basisfehlerquote von 1 %.
Durch die Überwachung der Verbrauchsrate erfahren wir, wie weit wir von der Basisfehlerquote entfernt sind. Nehmen wir erneut das Beispiel eines Erreichungsziels von 99 %, so gilt Folgendes:
Verbrauchsrate = 1: Wenn die Verbrauchsrate immer exakt auf der Basisfehlerquote bleibt, erreichen wir genau das SLO-Ziel.
Verbrauchsrate < 1: Wenn die Verbrauchsrate unter der Basisfehlerquote liegt, sind wir auf dem besten Weg, das SLO-Ziel zu übertreffen.
Verbrauchsrate > 1: Wenn die Verbrauchsrate höher als die Basisfehlerquote ist, besteht die Möglichkeit, dass wir das SLO-Ziel nicht erreichen.
Wenn Sie Brennraten für Ihre SLOs erstellen, können Sie sich auch dafür entscheiden, gleichzeitig CloudWatch Alarme zu erstellen, um die Brennraten zu überwachen. Sie können einen Schwellenwert für die Verbrauchsraten festlegen und die Alarme können Sie automatisch benachrichtigen, wenn die Verbrauchsraten-Metriken den von Ihnen festgelegten Schwellenwert überschreiten. Wenn sich eine Verbrauchsrate beispielsweise seinem Schwellenwert nähert, können Sie darüber informiert werden, dass der SLO das Fehlerbudget schneller aufbraucht, als Ihr Team tolerieren kann, und Ihr Team muss möglicherweise die Kundenabwanderung in der Anwendung verlangsamen, um sicherzustellen, dass die langfristigen Leistungsziele erreicht werden.
Für die Erstellung von Alarmen fallen Gebühren an. Weitere Informationen zur CloudWatch Preisgestaltung finden Sie unter CloudWatch Amazon-Preise
Die Verbrauchsrate berechnen
Um die Verbrauchsrate zu berechnen, müssen Sie ein Lookback-Fenster angeben. Das Lookback-Fenster ist die Zeitdauer, über die die Fehlerquote gemessen werden soll.
burn rate = error rate over the look-back window / (100% - attainment goal)
Anmerkung
Liegen keine Daten für den Zeitraum der Verbrauchsrate vor, berechnet Application Signals die Verbrauchsrate auf der Grundlage des erreichten Werts.
Die Fehlerrate wird als Verhältnis der Anzahl der fehlerhaften Ereignisse zur Gesamtzahl der Ereignisse während des Verbrauchsratenfensters berechnet:
Bei zeitraumbasierten SLOs wird die Fehlerquote berechnet, indem schlechte Zeiträume durch die Gesamtzahl der Zeiträume geteilt werden. Die Gesamtzahl der Zeiträume entspricht der Gesamtheit der Zeiträume während des Lookback-Fensters.
Bei anforderungsbasierten SLOs ist dies ein Maß für fehlerhafte Anforderungen geteilt durch die Gesamtzahl der Anforderungen. Die Gesamtzahl der Anforderungen entspricht der Anzahl der Anforderungen während des Lookback-Fensters.
Das Lookback-Fenster muss ein Vielfaches des SLO-Zeitraums sein und muss kleiner als das SLO-Intervall sein.
Ermitteln Sie den geeigneten Schwellenwert für einen Alarm für die Verbrauchsrate
Wenn Sie einen Alarm für die Verbrauchsrate konfigurieren, müssen Sie einen Wert für die Verbrauchsrate als Alarmschwellenwert auswählen. Der Wert für diesen Schwellenwert hängt von der Länge des SLO-Intervalls und dem Lookback-Fenster ab und hängt davon ab, welche Methode oder welches mentale Modell Ihr Team anwenden möchte. Für die Bestimmung des Schwellenwerts stehen zwei Hauptmethoden zur Verfügung.
Methode 1: Ermitteln Sie den Prozentsatz des geschätzten Gesamtfehlerbudgets, den Ihr Team bereit ist, im Lookback-Fenster aufzubrauchen.
Wenn Sie einen Alarm erhalten möchten, wenn X % des geschätzten Fehlerbudgets innerhalb der letzten Lookback-Stunden mit Blick auf die Verbrauchsrate aufgebraucht werden, ist der Schwellenwert für die Ausfallrate wie folgt:
burn rate threshold = X% * SLO interval length / look-back window size
Beispiel: Für 5 % eines Fehlerbudgets von 30 Tagen (720 Stunden), das über eine Stunde aufgewendet wurde, ist eine Ausfallrate von 5% * 720 / 1 = 36 erforderlich. Wenn das Lookback-Fenster für die Verbrauchsrate also 1 Stunde beträgt, legen wir den Schwellenwert für die Verbrauchsrate auf 36 fest.
Sie können die CloudWatch Konsole verwenden, um mithilfe dieser Methode Alarme für die Brennrate zu erstellen. Sie können die Zahl X angeben, und der Schwellenwert wird anhand der obigen Formel bestimmt.
Die Länge des SLO-Intervalls wird anhand des SLO-Intervalltyps bestimmt:
Bei SLOs mit einem gleitenden Intervall ist dies die Länge des Intervalls in Stunden.
Für SLOs mit einem kalenderbasierten Intervall:
Wenn es sich bei der Einheit um Tage oder Wochen handelt, ist dies die Länge des Intervalls in Stunden.
Wenn es sich bei der Einheit um einen Monat handelt, nehmen wir 30 Tage als geschätzte Dauer und rechnen sie in Stunden um.
Methode 2: Ermitteln Sie die Zeit bis zur Erschöpfung des Budgets für das nächste Intervall
Damit Sie vom Alarm benachrichtigt werden, wenn die aktuelle Fehlerquote im letzten Lookback-Fenster anzeigt, dass die Zeit bis zur Erschöpfung des Budgets weniger als X Stunden beträgt (vorausgesetzt, das verbleibende Budget liegt derzeit bei 100 %), können Sie die folgende Formel verwenden, um den Schwellenwert für die Verbrauchsrate zu ermitteln.
burn rate threshold = SLO interval length / X
Wir betonen, dass die Zeit bis zur Erschöpfung des Budgets (X) in der obigen Formel davon ausgeht, dass das verbleibende Gesamtbudget derzeit 100 % beträgt, und dass daher die Höhe des Budgets, das in diesem Zeitraum bereits verbraucht wurde, nicht berücksichtigt wird. Wir können uns das auch als die Zeit bis zur Erschöpfung des Budgets für das nächste Intervall vorstellen.
Anleitungen für Verbrauchsratenalarme
Nehmen wir als Beispiel ein SLO mit einem fortlaufenden Intervall von 28 Tagen. Das Festlegen eines Verbrauchsratenalarms für diesen SLO umfasst zwei Schritte:
Stellen Sie die Verbrauchsrate und das Lookback-Fenster ein.
Erstellen Sie einen CloudWatch Alarm, der die Brennrate überwacht.
Stellen Sie zunächst fest, wie viel vom gesamten Fehlerbudget der Service bereit ist, innerhalb eines bestimmten Zeitraums aufzuwenden. Mit anderen Worten, formulieren Sie Ihr Ziel anhand des folgenden Satzes: „Ich möchte benachrichtigt werden, wenn X % meines gesamten Fehlerbudgets innerhalb von M Minuten aufgebraucht sind.“
Sie könnten beispielsweise festlegen, dass für das Ziel eine Warnung ausgegeben wird, wenn innerhalb von 60 Minuten 2 % des gesamten Fehlerbudgets aufgebraucht sind.
Um die Verbrauchsrate festzulegen, definieren Sie zunächst das Lookback-Fenster. Das Lookback-Fenster ist M, was in diesem Beispiel 60 Minuten entspricht.
Als Nächstes erstellen Sie den CloudWatch Alarm. Wenn Sie dies tun, müssen Sie einen Schwellenwert für die Verbrauchsrate angeben. Wenn die Verbrauchsrate diesen Schwellenwert überschreitet, werden Sie vom Alarm benachrichtigt. Verwenden Sie die folgende Formel, um den Schwellenwert zu ermitteln:
burn rate threshold = X% * SLO interval length/ look-back window size
In diesem Beispiel ist X gleich 2, weil wir eine Warnung erhalten möchten, wenn innerhalb von 60 Minuten 2 % des Fehlerbudgets aufgebraucht sind. Die Länge des Intervalls beträgt 40.320 Minuten (28 Tage), und 60 Minuten sind das Lookback-Fenster. Die Antwort lautet also:
burn rate threshold = 2% * 40,320 / 60 = 13.44.
In diesem Beispiel würden Sie 13,44 als Alarmschwellenwert festlegen.
Mehrere Alarme mit unterschiedlichen Fenstern
Durch die Einrichtung von Alarmen in mehreren Lookback-Fenstern können Sie schnell einen starken Anstieg der Fehlerquote bei einem kurzen Fenster erkennen und gleichzeitig kleinere Erhöhungen der Fehlerquote erkennen, die letztendlich das Fehlerbudget aufbrauchen, wenn sie unbemerkt bleiben.
Darüber hinaus könnten Sie einen kombinierten Alarm für eine Brennrate mit langem Fenster und für eine Brennrate mit kurzem Fenster (1/12th des langen Fensters) einrichten und nur dann informiert werden, wenn beide Brennraten einen Schwellenwert überschreiten. Auf diese Weise können Sie sicherstellen, dass Sie nur über noch andauernde Situationen benachrichtigt werden. Weitere Informationen zu kombinierten Alarmen finden Sie unterEinen zusammengesetzten Alarm erstellen. CloudWatch
Anmerkung
Sie können bei der Erstellung der Verbrauchsrate einen Metrikalarm für eine Verbrauchsrate einrichten. Um einen Verbundalarm für mehrere Verbrauchsratenalarme einzurichten, müssen Sie die Anweisungen unter Einen zusammengesetzten Alarm erstellen befolgen.
Eine Strategie für Verbundalarme, die in der Arbeitsmappe Google Site Reliability Engineering
Ein Verbundalarm, der zwei Alarme überwacht, einen mit einem Zeitfenster von einer Stunde und einen mit einem Zeitfenster von fünf Minuten.
Ein zweiter Verbundalarm, der zwei Alarme überwacht, einen mit einem Sechsstundenfenster und einen mit einem 30-Minuten-Fenster.
Ein dritter Verbundalarm, der zwei Alarme überwacht, einen mit einem Drei-Tage-Fenster und einen mit einem Sechs-Stunden-Fenster.
Im Folgenden finden Sie die Schritte, die Sie für diese Konfiguration benötigen:
-
Erstellen Sie fünf Verbrauchsraten mit einem Zeitfenster von fünf Minuten, 30 Minuten, einer Stunde, sechs Stunden und drei Tagen.
Erstellen Sie die folgenden drei CloudWatch Alarmpaare. Jedes Paar umfasst ein langes Fenster und ein kurzes Fenster, das zum langen Fenster gehört 1/12th . Die Schwellenwerte werden anhand der Schritte unter bestimmt. Ermitteln Sie den geeigneten Schwellenwert für einen Alarm für die Verbrauchsrate Wenn Sie den Schwellenwert für jeden Alarm im Paar berechnen, verwenden Sie bei Ihrer Berechnung das längere Lookback-Fenster des Paares.
Alarme für die Verbrauchsraten von 1 Stunde und 5 Minuten (der Schwellenwert wird durch 2 % des Gesamtbudgets bestimmt)
Alarme für die Verbrauchsraten von 6 Stunde und 30 Minuten (der Schwellenwert wird durch 5 % des Gesamtbudgets bestimmt)
Alarme für die Verbrauchsrate von 3 Tagen und 6 Stunden (der Schwellenwert wird durch 10 % des Gesamtbudgets bestimmt)
Erstellen Sie für jedes dieser Paare einen Verbundalarm, um eine Warnung zu erhalten, wenn beide Einzelalarme in den ALARM-Status wechseln. Weitere Informationen zum Erstellen eines Verbundalarms finden Sie unter Einen zusammengesetzten Alarm erstellen.
Wenn Ihre Alarme für das erste Paar (Ein-Stunden-Fenster und Fünf-Minuten-Fenster) beispielsweise den Namen
OneHourBurnRateUnd habenFiveMinuteBurnRate, würde die Regel für CloudWatch zusammengesetzte Alarme lautenALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)
Die vorherige Strategie ist nur für SLOs mit einer Intervalldauer von mindestens drei Stunden möglich. Für SLOs mit kürzeren Intervallen empfehlen wir, mit einem Paar von Brandratenalarmen zu beginnen, wobei ein Alarm ein Rückblickfenster hat, das dem Rückblickfenster 1/12th des anderen Alarms entspricht. Stellen Sie dann einen Verbundalarm für dieses Paar ein.
Ein SLO erstellen
Wir empfehlen, dass Sie für Ihre kritischen Anwendungen sowohl Latenz- als auch Verfügbarkeits-SLOs festlegen. Diese von Application Signals gesammelten Metriken entsprechen den gemeinsamen Geschäftszielen.
Sie können SLOs auch für jede CloudWatch Metrik oder jeden metrischen mathematischen Ausdruck festlegen, der zu einer einzigen Zeitreihe führt.
Wenn Sie zum ersten Mal ein SLO in Ihrem Konto erstellen, CloudWatch wird automatisch die AWSServiceRoleForCloudWatchApplicationSignalsserviceverknüpfte Rolle in Ihrem Konto erstellt, sofern sie noch nicht vorhanden ist. Diese dienstgebundene Rolle ermöglicht CloudWatch das Sammeln von CloudWatch Logdaten, X-Ray Trace-Daten, CloudWatch Metrikdaten und Tagging-Daten von Anwendungen in Ihrem Konto. Weitere Informationen zu CloudWatch dienstbezogenen Rollen finden Sie unter. Verwenden von serviceverknüpften Rollen für CloudWatch
Wenn Sie ein SLO erstellen, geben Sie an, ob es sich um ein zeitraumbasiertes SLO oder ein anforderungsbasiertes SLO handelt. Jeder SLO-Typ hat eine andere Methode, um die Leistung Ihrer Anwendung im Vergleich zum Erreichungsziels zu bewerten.
Ein zeitraumbasiertes SLO verwendet definierte Zeiträume innerhalb eines bestimmten Gesamtzeitintervalls. Für jeden Zeitraum bestimmt Application Signals, ob die Anwendung ihr Ziel erreicht hat. Die Erreichungsquote wird berechnet als die
number of good periods/number of total periods.Bei einem zeitraumbasierten SLO bedeutet das Erreichen eines Erreichungsziels von 99,9 % beispielsweise, dass Ihre Anwendung innerhalb Ihres Intervalls ihr Leistungsziel in mindestens 99,9 % der Zeiträume erreichen muss.
Ein anforderungsbasiertes SLO verwendet keine vordefinierten Zeiträume. Stattdessen misst der SLO
number of good requests/number of total requestswährend des Intervalls. Sie können jederzeit das Verhältnis zwischen guten Anforderungen und der Gesamtzahl der Anforderungen für das Intervall bis zu dem von Ihnen angegebenen Zeitstempel ermitteln und dieses Verhältnis im Vergleich mit dem in Ihrem SLO festgelegten Ziel messen.
Themen
Ein zeitraumbasiertes SLO erstellen
Gehen Sie wie folgt vor, um ein zeitraumbasiertes SLO zu erstellen.
So erstellen Sie ein zeitraumbasiertes SLO
Öffnen Sie die CloudWatch Konsole unter. https://console.aws.amazon.com/cloudwatch/
Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Wählen Sie SLO erstellen.
Führen Sie für Servicelevel-Indikator (SLI) festlegen einen der folgenden Schritte aus:
Um den SLO für einen Dienstvorgang, alle Operationen oder die Abhängigkeit eines Dienstes festzulegen, verwenden Sie eine der Standardanwendungsmetriken
LatencyoderAvailability:Wählen Sie als Typ die Option Service aus.
Wählen Sie ein Konto aus, das dieses SLO überwachen soll.
Wählen Sie den Service aus, den dieses SLO überwachen soll.
Wählen Sie für Typ eine der folgenden Optionen aus:
Service Operations — um ein SLO für einen Servicevorgang, alle Operationen oder eine Teilmenge von Vorgängen zu erstellen.
Serviceabhängigkeit — um ein SLO von einer Abhängigkeit des Dienstes zu erstellen.
Wenn Sie Service Operations ausgewählt haben, wählen Sie den Vorgang aus, den dieser SLO überwachen soll. Um ein SLO auf Service-Ebene zu erstellen, das den Gesamtstatus Ihres Service in allen Vorgängen überwacht, wählen Sie Alle Operationen aus. Wählen Sie andernfalls einen bestimmten Vorgang aus, der überwacht werden soll.
Informationen zum Erstellen eines SLO, das eine Teilmenge von Vorgängen überwacht, finden Sie unterErstellen Sie ein zusammengesetztes SLO für mehrere Operationen.
Wenn Sie Service Dependency ausgewählt haben, gehen Sie wie folgt vor:
Wählen Sie unter Vorgang auswählen einen bestimmten Vorgang aus, oder wählen Sie Alle Operationen aus, um die Metriken aller Operationen dieses Dienstes zu verwenden, der eine Abhängigkeit aufruft.
Suchen Sie unter Abhängigkeit auswählen nach der erforderlichen Abhängigkeit, für die Sie die Zuverlässigkeit messen möchten, und wählen Sie sie aus.
Nachdem Sie die Abhängigkeit ausgewählt haben, können Sie das aktualisierte Diagramm und die auf der Abhängigkeit basierenden historischen Daten anzeigen.
Wählen Sie für Wählen Sie eine Berechnungsmethode die Option Zeiträume aus.
Die Dropdown-Menüs Service auswählen und Vorgang auswählen werden mit Services und Vorgängen gefüllt, die in den letzten 24 Stunden aktiv waren.
Wählen Sie entweder Verfügbarkeit oder Latenz und legen Sie dann den Schwellenwert fest.
So legen Sie den SLO für eine beliebige CloudWatch Metrik oder einen CloudWatch metrischen mathematischen Ausdruck fest:
Wählen Sie als Typ die Option CloudWatch Metrisch aus.
Wählen Sie CloudWatch Metrik auswählen aus.
Der Bildschirm Metrik auswählen wird angezeigt. Verwenden Sie die Registerkarten Durchsuchen oder Abfragen, um die gewünschte Metrik zu finden, oder erstellen Sie einen mathematischen Ausdruck für die Metrik.
Nachdem Sie die gewünschte Metrik ausgewählt haben, wählen Sie die Registerkarte Graphische Metriken und dann die Statistik und den Zeitraum aus, die für das SLO verwendet werden sollen. Wählen Sie dann Select Metric (Metrik auswählen) aus.
Weitere Informationen zu diesen Bildschirmen finden Sie unter Grafisches Darstellen von Metriken und Fügen Sie einem CloudWatch Diagramm einen mathematischen Ausdruck hinzu.
Wählen Sie für Wählen Sie eine Berechnungsmethode die Option Zeiträume aus.
Wählen Sie unter Bedingung festlegen einen Vergleichsoperator und einen Schwellenwert aus, den das SLO als Erfolgsindikator verwenden soll.
Wenn Sie in Schritt 4 Service ausgewählt haben, legen Sie die Periodenlänge für dieses SLO fest.
Geben Sie einen Namen für das SLO ein. Wenn Sie den Namen eines Services oder Vorgangs zusammen mit entsprechenden Schlüsselwörtern wie Latenz oder Verfügbarkeit angeben, können Sie bei der Untersuchung schnell erkennen, was der SLO-Status bedeutet.
Legen Sie das Intervall und das Erreichungsziel für das SLO fest. Weitere Informationen zu Intervallen und Erreichungszielen sowie zu deren Zusammenspiel finden Sie unter SLO-Konzepte.
(Optional) Gehen Sie für SLO-Verbrauchsraten festlegen wie folgt vor:
Stellen Sie die Dauer (in Minuten) des Lookback-Fensters für die Verbrauchsrate ein. Weitere Informationen zur Auswahl dieser Dauer finden Sie unter Anleitungen für Verbrauchsratenalarme.
Um mehr Verbrauchsraten für dieses SLO zu erstellen, wählen Sie Weitere Verbrauchsraten hinzufügen und legen Sie das Lookback-Fenster für die zusätzlichen Verbrauchsraten fest.
(Optional) Erstellen Sie wie folgt Alarme für die Verbrauchsrate:
Aktivieren Sie unter Verbrauchsrate-Alarme festlegen das Kontrollkästchen für jede Verbrauchsrate, für die Sie einen Alarm erstellen möchten. Gehen Sie für jeden dieser Alarme wie folgt vor:
Geben Sie das Amazon-SNS-Thema an, das für Benachrichtigungen verwendet werden soll, wenn der Alarm in den ALARM-Status wechselt.
Legen Sie entweder einen Schwellenwert für die Verbrauchsrate fest oder geben Sie den Prozentsatz des geschätzten Gesamtbudgets an, der im letzten Lookback-Fenster verbraucht werden soll. Wenn Sie den Prozentsatz des geschätzten Gesamtbudgets angeben, das aufgebraucht wurde, wird der Schwellenwert für die Verbrauchsrate für Sie berechnet und im Alarm verwendet. Unter Ermitteln Sie den geeigneten Schwellenwert für einen Alarm für die Verbrauchsrate erfahren Sie, wie Sie entscheiden können, welcher Schwellenwert festgelegt werden soll, oder um zu erfahren, wie diese Option zur Berechnung des Schwellenwerts für die Verbrauchsrate verwendet wird.
(Optional) Legen Sie einen oder mehrere CloudWatch Alarme oder einen Warnschwellenwert für den SLO fest.
CloudWatch Alarme können Amazon SNS verwenden, um Sie proaktiv zu benachrichtigen, wenn eine Anwendung aufgrund ihrer SLI-Leistung fehlerhaft ist.
Um einen Alarm zu erstellen, wählen Sie eines der Alarm-Kontrollkästchen aus und geben Sie das Amazon-SNS-Thema ein – oder erstellen Sie eines – welches für Benachrichtigungen verwendet werden soll, wenn der Alarm in den
ALARM-Status wechselt. Weitere Informationen zu CloudWatch Alarmen finden Sie unter. CloudWatch Amazon-Alarme verwenden Für die Erstellung von Alarmen fallen Gebühren an. Weitere Informationen zur CloudWatch Preisgestaltung finden Sie unter CloudWatch Amazon-Preise. Wenn Sie einen Warnschwellenwert festlegen, wird dieser auf den Bildschirmen von Application Signals angezeigt und hilft Ihnen dabei, SLOs zu identifizieren, bei denen die Gefahr besteht, dass sie nicht erfüllt werden, auch wenn sie derzeit fehlerfrei sind.
Um einen Warnschwellenwert festzulegen, geben Sie den Schwellenwert im Feld Warnschwellenwert ein. Wenn das Fehlerbudget des SLO unter dem Warnschwellenwert liegt, wird das SLO auf mehreren Bildschirmen von Application Signals mit Warnung gekennzeichnet. Warnschwellenwerte werden auch in den Grafiken zum Fehlerbudget angezeigt. Sie können auch einen SLO-Warnalarm erstellen, der auf dem Warnschwellenwert basiert.
(Optional) Gehen Sie unter Ausschluss des SLO-Zeitfensters festlegen wie folgt vor:
Legen Sie unter Zeitfenster ausschließen das Zeitfenster fest, das von den SLO-Leistungsmetriken ausgeschlossen werden soll.
Sie können Zeitfenster festlegen wählen und das Startfenster für jede Stunde oder jeden Monat eingeben, oder Sie können Zeitfenster mit CRON festlegen wählen und den CRON-Ausdruck eingeben.
Stellen Sie unter Wiederholen ein, ob dieser Zeitfensterausschluss wiederholt wird oder nicht.
(Optional) Unter Grund hinzufügen können Sie wählen, ob Sie einen Grund für den Zeitfensterausschluss eingeben möchten. Zum Beispiel geplante Wartungsarbeiten.
Wählen Sie Zeitfenster hinzufügen, um bis zu 10 Zeitausschlussfenster hinzuzufügen.
Um diesem SLO Tags hinzuzufügen, wählen Sie die Registerkarte Tags und dann Neues Tag hinzufügen. Mit Tags können Sie Ressourcen verwalten, identifizieren, organisieren, suchen und filtern. Weitere Informationen über das Markieren finden Sie unter Markieren Ihrer AWS -Ressourcen.
Anmerkung
Wenn die Anwendung, auf die sich dieses SLO bezieht, registriert ist AWS Service Catalog AppRegistry, können Sie das
awsApplicationTag verwenden, um dieses SLO dieser Anwendung zuzuordnen AppRegistry. Weitere Informationen finden Sie unter Was ist AppRegistry?Wählen Sie SLO erstellen. Wenn Sie sich außerdem dafür entscheiden, einen oder mehrere Alarme zu erstellen, ändert sich der Name der Schaltfläche entsprechend.
Anforderungsbasiertes SLO erstellen
Gehen Sie wie folgt vor, um ein anforderungsbasiertes SLO zu erstellen.
So erstellen Sie ein anforderungsbasiertes SLO
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Wählen Sie SLO erstellen.
Führen Sie für Servicelevel-Indikator (SLI) festlegen einen der folgenden Schritte aus:
Um den SLO für einen Dienstvorgang, alle Operationen oder die Abhängigkeit eines Dienstes festzulegen, verwenden Sie eine der Standardanwendungsmetriken
LatencyoderAvailability:Wählen Sie als Typ die Option Service aus.
Wählen Sie den Service aus, den dieses SLO überwachen soll.
Wählen Sie für Typ eine der folgenden Optionen aus:
Service Operations — um ein SLO für einen Servicevorgang, alle Operationen oder eine Teilmenge von Vorgängen zu erstellen.
Serviceabhängigkeit — um ein SLO von einer Abhängigkeit des Dienstes zu erstellen.
Wenn Sie Service Operations ausgewählt haben, wählen Sie den Vorgang aus, den dieser SLO überwachen soll. Um ein SLO auf Service-Ebene zu erstellen, das den Gesamtstatus Ihres Service in allen Vorgängen überwacht, wählen Sie Alle Operationen aus. Wählen Sie andernfalls einen bestimmten Vorgang aus, der überwacht werden soll.
Informationen zum Erstellen eines SLO, das eine Teilmenge von Vorgängen überwacht, finden Sie unterErstellen Sie ein zusammengesetztes SLO für mehrere Operationen.
Wenn Sie Service Dependency ausgewählt haben, gehen Sie wie folgt vor:
Wählen Sie unter Vorgang auswählen einen bestimmten Vorgang aus, oder wählen Sie Alle Operationen aus, um die Metriken aller Operationen dieses Dienstes zu verwenden, der eine Abhängigkeit aufruft.
Suchen Sie unter Abhängigkeit auswählen nach der erforderlichen Abhängigkeit, für die Sie die Zuverlässigkeit messen möchten, und wählen Sie sie aus.
Nachdem Sie die Abhängigkeit ausgewählt haben, können Sie das aktualisierte Diagramm und die auf der Abhängigkeit basierenden historischen Daten anzeigen.
Wählen Sie für Wählen Sie eine Berechnungsmethode die Option Anforderungen aus.
-
Die Dropdown-Menüs Service auswählen und Vorgang auswählen werden mit Services und Vorgängen gefüllt, die in den letzten 24 Stunden aktiv waren.
Wählen Sie entweder Verfügbarkeit oder Latenz. Wenn Sie Latenz wählen, legen Sie den Schwellenwert fest.
So legen Sie den SLO für eine beliebige CloudWatch Metrik oder einen CloudWatch metrischen mathematischen Ausdruck fest:
Wählen Sie als Typ die Option CloudWatch Metrisch aus.
-
Gehen Sie bei Zielanforderungen definieren wie folgt vor:
Wählen Sie aus, ob Sie gute oder schlechte Anforderungen messen möchten.
-
Wählen Sie CloudWatch Metrik auswählen aus. Diese Metrik ist der Zähler für das Verhältnis der Zielanforderungen zur Gesamtzahl der Anforderungen. Wenn Sie eine Latenzmetrik verwenden, nutzen Sie die Statistik Getrimmte Anzahl (TC). Wenn der Schwellenwert 9 ms beträgt und Sie den Vergleichsoperator „Weniger als“ (<) verwenden, verwenden Sie den Schwellenwert TC (:threshold – 1). Weitere Informationen zu TC finden Sie unter Syntax.
Der Bildschirm Metrik auswählen wird angezeigt. Verwenden Sie die Registerkarten Durchsuchen oder Abfragen, um die gewünschte Metrik zu finden, oder erstellen Sie einen mathematischen Ausdruck für die Metrik.
-
Wählen Sie unter Gesamtzahl der Anfragen definieren die CloudWatch Metrik aus, die Sie für die Quelle verwenden möchten. Diese Metrik ist der Nenner für das Verhältnis von Zielanforderungen zur Gesamtzahl der Anforderungen.
Der Bildschirm Metrik auswählen wird angezeigt. Verwenden Sie die Registerkarten Durchsuchen oder Abfragen, um die gewünschte Metrik zu finden, oder erstellen Sie einen mathematischen Ausdruck für die Metrik.
Nachdem Sie die gewünschte Metrik ausgewählt haben, wählen Sie die Registerkarte Graphische Metriken und dann die Statistik und den Zeitraum aus, die für das SLO verwendet werden sollen. Wählen Sie dann Select Metric (Metrik auswählen) aus.
Wenn Sie eine Latenzmetrik verwenden, die einen Datenpunkt pro Anforderung ausgibt, verwenden Sie die Statistik zur Beispielanzahl, um die Gesamtzahl der Anforderungen zu zählen.
Weitere Informationen zu diesen Bildschirmen finden Sie unter Grafisches Darstellen von Metriken und Fügen Sie einem CloudWatch Diagramm einen mathematischen Ausdruck hinzu.
Geben Sie einen Namen für das SLO ein. Wenn Sie den Namen eines Services oder Vorgangs zusammen mit entsprechenden Schlüsselwörtern wie Latenz oder Verfügbarkeit angeben, können Sie bei der Untersuchung schnell erkennen, was der SLO-Status bedeutet.
Legen Sie das Intervall und das Erreichungsziel für das SLO fest. Weitere Informationen zu Intervallen und Erreichungszielen sowie zu deren Zusammenspiel finden Sie unter SLO-Konzepte.
(Optional) Gehen Sie für SLO-Verbrauchsraten festlegen wie folgt vor:
Stellen Sie die Dauer (in Minuten) des Lookback-Fensters für die Verbrauchsrate ein. Weitere Informationen zur Auswahl dieser Dauer finden Sie unter Anleitungen für Verbrauchsratenalarme.
Um mehr Verbrauchsraten für dieses SLO zu erstellen, wählen Sie Weitere Verbrauchsraten hinzufügen und legen Sie das Lookback-Fenster für die zusätzlichen Verbrauchsraten fest.
(Optional) Erstellen Sie wie folgt Alarme für die Verbrauchsrate:
Aktivieren Sie unter Verbrauchsrate-Alarme festlegen das Kontrollkästchen für jede Verbrauchsrate, für die Sie einen Alarm erstellen möchten. Gehen Sie für jeden dieser Alarme wie folgt vor:
Geben Sie das Amazon-SNS-Thema an, das für Benachrichtigungen verwendet werden soll, wenn der Alarm in den ALARM-Status wechselt.
Legen Sie entweder einen Schwellenwert für die Verbrauchsrate fest oder geben Sie den Prozentsatz des geschätzten Gesamtbudgets an, der im letzten Lookback-Fenster verbraucht werden soll. Wenn Sie den Prozentsatz des geschätzten Gesamtbudgets angeben, das aufgebraucht wurde, wird der Schwellenwert für die Verbrauchsrate für Sie berechnet und im Alarm verwendet. Unter Ermitteln Sie den geeigneten Schwellenwert für einen Alarm für die Verbrauchsrate erfahren Sie, wie Sie entscheiden können, welcher Schwellenwert festgelegt werden soll, oder um zu erfahren, wie diese Option zur Berechnung des Schwellenwerts für die Verbrauchsrate verwendet wird.
(Optional) Legen Sie einen oder mehrere CloudWatch Alarme oder einen Warnschwellenwert für den SLO fest.
CloudWatch Alarme können Amazon SNS verwenden, um Sie proaktiv zu benachrichtigen, wenn eine Anwendung aufgrund ihrer SLI-Leistung fehlerhaft ist.
Um einen Alarm zu erstellen, wählen Sie eines der Alarm-Kontrollkästchen aus und geben Sie das Amazon-SNS-Thema ein – oder erstellen Sie eines – welches für Benachrichtigungen verwendet werden soll, wenn der Alarm in den
ALARM-Status wechselt. Weitere Informationen zu CloudWatch Alarmen finden Sie unter. CloudWatch Amazon-Alarme verwenden Für die Erstellung von Alarmen fallen Gebühren an. Weitere Informationen zur CloudWatch Preisgestaltung finden Sie unter CloudWatch Amazon-Preise. Wenn Sie einen Warnschwellenwert festlegen, wird dieser auf den Bildschirmen von Application Signals angezeigt und hilft Ihnen dabei, SLOs zu identifizieren, bei denen die Gefahr besteht, dass sie nicht erfüllt werden, auch wenn sie derzeit fehlerfrei sind.
Um einen Warnschwellenwert festzulegen, geben Sie den Schwellenwert im Feld Warnschwellenwert ein. Wenn das Fehlerbudget des SLO unter dem Warnschwellenwert liegt, wird das SLO auf mehreren Bildschirmen von Application Signals mit Warnung gekennzeichnet. Warnschwellenwerte werden auch in den Grafiken zum Fehlerbudget angezeigt. Sie können auch einen SLO-Warnalarm erstellen, der auf dem Warnschwellenwert basiert.
(Optional) Gehen Sie unter Ausschluss des SLO-Zeitfensters festlegen wie folgt vor:
Legen Sie unter Zeitfenster ausschließen das Zeitfenster fest, das von den SLO-Leistungsmetriken ausgeschlossen werden soll.
Sie können Zeitfenster festlegen wählen und das Startfenster für jede Stunde oder jeden Monat eingeben, oder Sie können Zeitfenster mit CRON festlegen wählen und den CRON-Ausdruck eingeben.
Stellen Sie unter Wiederholen ein, ob dieser Zeitfensterausschluss wiederholt wird oder nicht.
(Optional) Unter Grund hinzufügen können Sie wählen, ob Sie einen Grund für den Zeitfensterausschluss eingeben möchten. Zum Beispiel geplante Wartungsarbeiten.
Wählen Sie Zeitfenster hinzufügen, um bis zu 10 Zeitausschlussfenster hinzuzufügen.
Um diesem SLO Tags hinzuzufügen, wählen Sie die Registerkarte Tags und dann Neues Tag hinzufügen. Mit Tags können Sie Ressourcen verwalten, identifizieren, organisieren, suchen und filtern. Weitere Informationen über das Markieren finden Sie unter Markieren Ihrer AWS -Ressourcen.
Anmerkung
Wenn die Anwendung, auf die sich dieses SLO bezieht, registriert ist AWS Service Catalog AppRegistry, können Sie das
awsApplicationTag verwenden, um dieses SLO dieser Anwendung zuzuordnen AppRegistry. Weitere Informationen finden Sie unter Was ist AppRegistry?Wählen Sie SLO erstellen. Wenn Sie sich außerdem dafür entscheiden, einen oder mehrere Alarme zu erstellen, ändert sich der Name der Schaltfläche entsprechend.
Erstellen Sie ein SLO auf einem App-Monitor
Sie können SLOs erstellen, um die Leistung Ihrer CloudWatch RUM-App-Monitore zu überwachen. Auf diese Weise können Sie echte Kennzahlen zur Benutzererfahrung verfolgen und sicherstellen, dass Ihre Web- und Mobilanwendungen die Leistungsziele erreichen. SLOs auf App-Monitoren verwenden eine anforderungsbasierte Bewertung, bei der das Verhältnis von guten Anfragen zur Gesamtzahl der Anfragen gemessen wird.
Um ein SLO auf einem App-Monitor zu erstellen
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Wählen Sie SLO erstellen.
Wählen Sie für Set Service Level Indicator (SLI) die Option RUM AppMonitor.
Wählen Sie aus der Drop-down-Liste den App-Monitor aus, den dieser SLO überwachen soll. Die Liste zeigt den Namen des App-Monitors zusammen mit der unterstützten Plattform (Web, iOS oder Android).
(Optional) Wählen Sie eine bestimmte Seite oder einen bestimmten Bildschirm zur Überwachung aus. Wenn Sie keine Seite auswählen, überwacht das SLO alle Seiten für den App-Monitor.
Wählen Sie unter Metrik auswählen die Metrik aus, die für die SLI verwendet werden soll. Die verfügbaren Metriken hängen von der Plattform ab:
Für Webanwendungen:
PerformanceNavigationDurationJSErrorCount,Http4xxCount, undHttp5xxCountFür mobile Anwendungen (iOS und Android):
ScreenLoadTimeCrashCount,Http4xxCount, undHttp5xxCount
Wählen Sie unter Bedingung festlegen einen Vergleichsoperator und einen Schwellenwert aus, den das SLO als Erfolgsindikator verwenden soll.
Geben Sie einen Namen für das SLO ein. Wenn Sie den Namen des App-Monitors und die entsprechenden Schlüsselwörter angeben, können Sie während der Triage schnell erkennen, was der SLO-Status anzeigt.
Legen Sie das Intervall und das Erreichungsziel für das SLO fest. Weitere Informationen finden Sie unter SLO-Konzepte.
(Optional) Konfigurieren Sie die Brennraten und Alarme nach Bedarf. Weitere Informationen finden Sie unter Berechnen der Verbrauchsraten und optionale Einstellung der Verbrauchsratenalarme.
(Optional) Lege bei Bedarf Ausnahmen für Zeitfenster fest.
(Optional) Fügen Sie Stichwörter hinzu, um dieses SLO besser organisieren und identifizieren zu können.
Wählen Sie SLO erstellen.
Erstelle ein SLO auf einem Kanarienvogel
Sie können SLOs erstellen, um die Leistung Ihrer CloudWatch Synthetics Canaries zu überwachen. Auf diese Weise können Sie die Ergebnisse der synthetischen Überwachung verfolgen und sicherstellen, dass Ihre Endgeräte und APIs die Verfügbarkeits- und Leistungsziele erfüllen. SLOs auf den Kanarischen Inseln verwenden eine periodenbasierte Evaluierung, bei der jeder Canary-Run als separater Evaluierungszeitraum behandelt wird.
Um ein SLO auf einem Canary zu erstellen
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Wählen Sie SLO erstellen.
Wählen Sie für Set Service Level Indicator (SLI) die Option Synthetics Canary.
Wählen Sie aus der Drop-down-Liste den Canary aus, den dieser SLO überwachen soll.
Wählen Sie unter Metrik auswählen entweder
SuccessPercentoderDuration:SuccessPercentmisst den Prozentsatz erfolgreicher Canary-RunsDurationmisst, wie lange es dauert, bis jeder Canary-Run abgeschlossen ist
Wählen Sie unter Bedingung festlegen einen Vergleichsoperator und einen Schwellenwert aus, den das SLO als Erfolgsindikator verwenden soll.
Geben Sie einen Namen für das SLO ein. Wenn Sie den Canary-Namen und die entsprechenden Stichwörter angeben, können Sie bei der Triage schnell erkennen, was der SLO-Status bedeutet.
Legen Sie das Intervall und das Erreichungsziel für das SLO fest. Weitere Informationen finden Sie unter SLO-Konzepte.
(Optional) Konfigurieren Sie die Brennraten und Alarme nach Bedarf. Weitere Informationen finden Sie unter Berechnen der Verbrauchsraten und optionale Einstellung der Verbrauchsratenalarme.
(Optional) Lege bei Bedarf Ausnahmen für Zeitfenster fest.
(Optional) Fügen Sie Stichwörter hinzu, um dieses SLO besser organisieren und identifizieren zu können.
Wählen Sie SLO erstellen.
Erstellen Sie ein zusammengesetztes SLO für mehrere Operationen
Sie können ein zusammengesetztes SLO erstellen, das die Availability Metrik für eine Teilmenge von Vorgängen für einen Service überwacht. Dies ist nützlich, wenn Sie die Zuverlässigkeit einer Gruppe verwandter Operationen gemeinsam verfolgen möchten, anstatt einen einzelnen Vorgang oder alle Operationen zu überwachen.
Zusammengesetzte SLOs unterstützen sowohl periodenbasierte als auch anforderungsbasierte Evaluierungen. Sie können zwischen 2 und 20 Operationen auswählen, die Sie einbeziehen möchten. Es gibt zwei Möglichkeiten, Operationen auszuwählen:
Explizite Auswahl — Wählen Sie einzelne Operationen manuell aus der Dropdownliste aus.
Mustervergleich — Verwenden Sie ein Präfix oder einen regulären Ausdruck, um Operationen automatisch nach Namen zuzuordnen.
Anmerkung
Zusammengesetzte SLOs unterstützen nur die Availability Metrik. Die Latency Metrik ist für zusammengesetzte SLOs nicht verfügbar.
Um ein zusammengesetztes SLO zu erstellen
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Wählen Sie SLO erstellen.
Wählen Sie für Set Service Level Indicator (SLI) als Typ die Option Service aus.
Wählen Sie den Service aus, den dieses SLO überwachen soll.
Wählen Sie für Typ die Option Service Operations aus.
Wählen Sie die Operationen aus, die in dieses zusammengesetzte SLO aufgenommen werden sollen. Führen Sie eine der folgenden Aktionen aus:
Um Operationen manuell auszuwählen, wählen Sie mehrere Operationen aus der Dropdown-Liste Operation aus. Sie können zwischen 2 und 20 Operationen wählen.
Die ausgewählten Operationen werden als Token unter dem Drop-down-Menü angezeigt. Sie können einen Vorgang entfernen, indem Sie auf dem zugehörigen Token auf das Symbol „Schließen“ klicken.
Um Operationen nach Muster auszuwählen, aktivieren Sie das Kontrollkästchen Musterabgleich verwenden. Führen Sie dann die folgenden Schritte aus:
Wählen Sie als Mustertyp entweder Präfix oder Regulärer Ausdruck.
Präfix entspricht allen Operationen, deren Namen mit dem von Ihnen eingegebenen Text beginnen. Die Eingabe
Invokeentspricht beispielsweise Operationen mit dem NamenInvokeFunctionInvokeAsync, usw.Ein regulärer Ausdruck entspricht allen Operationen, deren Namen dem von Ihnen eingegebenen Regex-Muster entsprechen. Die Eingabe
^Invoke.*entspricht beispielsweise denselben Operationen wie das Präfixbeispiel.
Geben Sie das Muster in das Feld Muster ein. Die Konsole zeigt die übereinstimmenden Operationen als Token unter dem Feld an, sodass Sie die Ergebnisse überprüfen können.
Nachdem Sie Operationen ausgewählt haben, wird die Metrik automatisch auf Verfügbarkeit gesetzt.
Wählen Sie für Wählen Sie eine Berechnungsmethode entweder Perioden oder Anfragen aus.
Wenn Sie Perioden ausgewählt haben, legen Sie die Periodenlänge und den Verfügbarkeitsschwellenwert für diesen SLO fest.
Geben Sie einen Namen für das SLO ein, oder verwenden Sie den automatisch generierten Namen. Der automatisch generierte Name enthält den Dienstnamen und das Wort „Composite“, damit Sie ihn leichter identifizieren können.
Legen Sie das Intervall und das Erreichungsziel für das SLO fest. Weitere Informationen zu Intervallen und Erreichungszielen sowie zu deren Zusammenspiel finden Sie unter SLO-Konzepte.
(Optional) Konfigurieren Sie die Brennraten und Alarme nach Bedarf. Weitere Informationen finden Sie unter Berechnen der Verbrauchsraten und optionale Einstellung der Verbrauchsratenalarme.
(Optional) Legen Sie einen oder mehrere CloudWatch Alarme oder einen Warnschwellenwert für den SLO fest.
(Optional) Legen Sie bei Bedarf Ausnahmen für Zeitfenster fest.
(Optional) Fügen Sie Stichwörter hinzu, um dieses SLO besser organisieren und identifizieren zu können.
Wählen Sie SLO erstellen.
Verwenden Sie SLO-Empfehlungen
Application Signals kann Empfehlungen für Ihre SLO-Konfiguration geben, die auf historischen Metrikdaten der letzten 30 Tage basieren. Wenn Sie grundlegende Informationen über Ihren Service und die Art von SLO angeben, die Sie erstellen möchten, analysiert Application Signals Ihre Metrikdaten und schlägt optimale Werte für die Zeitfenster Metrik-Schwellenwert, SLO-Ziel und Burn-Rate vor.
Um SLO-Empfehlungen zu erhalten, müssen Sie die folgenden Informationen angeben:
Wählen Sie entweder Service Operation oder Service Dependency aus:
Geben Sie für Service Operation den Service und den Vorgang an
Geben Sie für Service Dependency den Dienst, den Vorgang (oder alle Operationen) und die Abhängigkeit an
Der SLO-Evaluierungstyp: entweder periodenbasiert oder anforderungsbasiert
Der Typ der Standardanwendungsmetrik: entweder oder
LatencyAvailability
Basierend auf diesen Informationen und den historischen Leistungsdaten Ihres Dienstes empfiehlt Application Signals die folgenden SLO-Konfigurationsparameter:
Metrischer Schwellenwert — Der Leistungsschwellenwert für Ihr SLI, berechnet auf der Grundlage der tatsächlichen Leistung Ihres Dienstes in den letzten 30 Tagen.
SLO-Ziel — Der vorgeschlagene Prozentsatz für die Erreichung des Ziels, der der historischen Zuverlässigkeit Ihres Dienstes entspricht.
Zeitfenster für die Ausfallrate — Die empfohlene Dauer von Lookback-Fenstern dient dazu, zu überwachen, wie schnell Ihr Service sein Fehlerbudget aufgebraucht hat.
Sie können die empfohlenen Werte akzeptieren oder sie an Ihre spezifischen Geschäftsanforderungen anpassen. Die Empfehlungen bieten einen datengestützten Ausgangspunkt für die Konfiguration von SLOs, die die tatsächlichen Leistungsmerkmale Ihres Dienstes widerspiegeln.
SLO-Status anzeigen und untersuchen
Mithilfe der Service Level Objectives oder der Service-Optionen in der Konsole können Sie sich schnell einen Überblick über den Zustand Ihrer SLOs verschaffen. CloudWatch Die Services-Ansicht bietet auf einen Blick eine Übersicht über das Verhältnis fehlerhafter Services, das auf der Grundlage der von Ihnen festgelegten SLOs berechnet wird. Weitere Informationen zur Verwendung der Services-Option finden Sie unter Den Betriebsstatus Ihrer Anwendungen mit Application Signals überwachen.
Die Ansicht Servicelevel-Ziele bietet eine übergeordnete Ansicht Ihrer Organisation. Sie können die erfüllten und nicht erfüllten SLOs als Ganzes sehen. Auf diese Weise erhalten Sie einen Überblick darüber, wie viele Ihrer Services und Abläufe gemäß den von Ihnen ausgewählten SLIs über längere Zeiträume Ihren Erwartungen entsprechen.
So zeigen Sie alle SLOs in der Servicelevel-Ziele-Ansicht an
-
Öffnen Sie die CloudWatch Konsole unter. https://console.aws.amazon.com/cloudwatch/
Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Die Liste der Servicelevel-Ziele (SLO) wird angezeigt.
In der SLI-Status-Spalte können Sie schnell den aktuellen Status Ihrer SLOs einsehen. Um die SLOs so zu sortieren, dass alle fehlerhaften SLOs ganz oben in der Liste stehen, wählen Sie die SLI-Status-Spalte aus, bis alle fehlerhaften SLOs ganz oben stehen.
Die SLO-Tabelle hat die folgenden standardmäßigen Spalten. Sie können anpassen, welche Spalten angezeigt werden, indem Sie das Zahnradsymbol über der Liste auswählen. Weitere Informationen zu Zielen, SLIs, erreichten Zielen und Intervallen finden Sie unter SLO-Konzepte.
Der Name des SLO.
In der Ziel-Spalte wird der Prozentsatz der Zeiträume in jedem Intervall angezeigt, bei denen der SLI-Schwellenwert erfolgreich erreicht werden muss, damit das SLO-Ziel erreicht wird. Außerdem wird die Intervall-Länge für das SLO angezeigt.
Der SLI-Status zeigt an, ob der aktuelle Betriebsstatus der Anwendung fehlerfrei ist oder nicht. Wenn ein Zeitraum innerhalb des aktuell ausgewählten Zeitraums für das SLO fehlerhaft war, wird der SLI-Status als Fehlerhaft angezeigt.
Wenn dieser SLO für die Überwachung einer Abhängigkeit konfiguriert ist, werden in den Spalten Abhängigkeit und Remote-Vorgang die Details zu dieser Abhängigkeitsbeziehung angezeigt.
Das Endziel ist das Erreichungsniveau, das am Ende des ausgewählten Zeitraums erreicht wurde. Sortieren Sie nach dieser Spalte, um die SLOs zu finden, bei denen die Gefahr am größten ist, dass sie nicht eingehalten werden.
Das Erreichungs-Delta ist der Unterschied in der Leistungsstufe zwischen dem Beginn und dem Ende des ausgewählten Zeitraums. Ein negatives Delta bedeutet, dass die Metrik nach unten tendiert. Sortieren Sie nach dieser Spalte, um die neuesten Trends der SLOs zu sehen.
Das Budget für Endfehler (%) ist der Prozentsatz der Gesamtzeit in dem Zeitraum, in dem es zu fehlerhaften Zeiträumen kommen kann und das SLO trotzdem erfolgreich erreicht werden kann. Wenn Sie diesen Wert auf 5 % setzen und der SLI in 5 % oder weniger der verbleibenden Zeiträumen des Intervalls fehlerhaft ist, wird das SLO trotzdem erfolgreich erreicht.
Das Fehlerbudget-Delta ist die Differenz im Fehlerbudget zwischen dem Start und dem Ende des ausgewählten Zeitraums. Ein negatives Delta bedeutet, dass die Metrik nach unten tendiert.
Beim Endfehlerbudget (Zeit) handelt es sich um die tatsächliche Zeit innerhalb des Intervalls, die fehlerhaft sein kann, während das SLO trotzdem erfolgreich erreicht werden muss. Wenn dieser Wert beispielsweise 14 Minuten beträgt und der SLI während des verbleibenden Intervalls weniger als 14 Minuten fehlerhaft ist, wird das SLO trotzdem erfolgreich erreicht.
-
Beim Endfehlerbudget (Anforderungen) handelt es sich um die Anzahl der Anforderungen innerhalb des Intervalls, die fehlerhaft sein kann, während das SLO trotzdem erfolgreich erreicht werden muss. Bei anforderungsbasierten SLOs ist dieser Wert dynamisch und kann schwanken, wenn sich die Gesamtzahl der Anforderungen im Laufe der Zeit ändert.
In den Spalten Service, Vorgang und Typ werden Informationen darüber angezeigt, für welchen Service und welchen Betrieb dieses SLO eingerichtet ist.
Aktivieren Sie das Optionsfeld neben dem SLO-Namen, um die Budgets für Erreichen und Fehler für ein SLO anzuzeigen.
Die Grafiken oben auf der Seite zeigen den Budgetstatus des SLO-Erreichens und des Fehlerbudgets. Ein Diagramm über die SLI-Metrik, die diesem SLO zugeordnet ist, wird ebenfalls angezeigt.
Um ein SLO, das sein Ziel nicht erreicht, genauer zu untersuchen, wählen Sie den Service-, Vorgangs- oder Abhängigkeitsnamen, der diesem SLO zugeordnet ist. Sie werden auf die Detailseite weitergeleitet, auf der Sie eine weitere Auswahl vornehmen können. Weitere Informationen finden Sie unter Anzeigen detaillierter Serviceaktivitäten und des Betriebsstatus auf der Servicedetailseite.
Um den Zeitraum der Diagramme und Tabellen auf der Seite zu ändern, wählen Sie oben auf dem Bildschirm einen neuen Zeitraum aus.
Ein vorhandenes SLO bearbeiten
Gehen Sie folgendermaßen vor, um eine bestehende SLO zu bearbeiten. Wenn Sie ein SLO bearbeiten, können Sie nur den Schwellenwert, das Intervall, das Erreichungsziel und die Tags ändern. Um andere Aspekte wie Service, Betrieb oder Metrik zu ändern, erstellen Sie ein neues SLO, anstatt ein vorhandenes zu bearbeiten.
Wenn Sie einen Teil einer SLO-Kernkonfiguration ändern, z. B. einen Zeitraum oder einen Schwellenwert, werden alle vorherigen Datenpunkte und Bewertungen in Bezug auf Leistung und Zustand ungültig. Das SLO wird effektiv gelöscht und neu erstellt.
Anmerkung
Wenn Sie ein SLO bearbeiten, werden die mit diesem SLO verknüpften Alarme nicht automatisch aktualisiert. Möglicherweise müssen Sie die Alarme aktualisieren, damit sie mit dem SLO synchron bleiben.
So bearbeiten Sie ein vorhandenes SLO
-
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Aktivieren Sie das Optionsfeld neben dem SLO, das Sie bearbeiten möchten, und wählen Sie Aktionen, SLO bearbeiten aus.
Nehmen Sie die gewünschten Änderungen vor und wählen Sie dann Änderungen speichern.
Ein SLO löschen
Gehen Sie folgendermaßen vor, um ein bestehendes SLO zu löschen.
Anmerkung
Wenn Sie ein SLO löschen, werden die mit diesem SLO verknüpften Alarme nicht automatisch gelöscht. Sie müssen sie selbst löschen. Weitere Informationen finden Sie unter Verwalten von Alarmen.
So löschen Sie ein SLO
-
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Wählen Sie im Navigationsbereich Servicelevel-Ziele (SLO).
Aktivieren Sie das Optionsfeld neben dem SLO, das Sie bearbeiten möchten, und wählen Sie Aktionen, SLO löschen aus.
Wählen Sie Bestätigen aus.
